LongBench v2: оценка длинного текста +o1?


Оценка больших моделей для "глубокого понимания и рассуждения" в реальном мире, при работе с длинными текстами и многозадачными заданиями
В последние годы был достигнут значительный прогресс в изучении больших языковых моделей для длинных текстов, причем длина контекстного окна моделей была увеличена с первоначальных 8 тыс. до 128 тыс. или даже 1 млн лексем. Однако по-прежнему остается ключевой вопрос: действительно ли эти модели понимают длинные тексты, с которыми они имеют дело? Другими словами, способны ли они понимать, обучаться и глубоко рассуждать на основе информации, содержащейся в длинных текстах?
Чтобы ответить на этот вопрос и продвинуть развитие моделей глубокого понимания и рассуждения при работе с длинными текстами, команда исследователей из Университета Цинхуа и Smart Spectrum запустила LongBench v2, эталонный тест, предназначенный для оценки возможностей глубокого понимания и рассуждения LLM в реальной многозадачной работе с длинными текстами.
Мы считаем, что LongBench v2 позволит продвинуться в изучении того, как масштабирование вычислений в режиме вывода (например, модель o1) может помочь в решении проблем глубокого понимания и вывода в сценариях с длинными текстами.
особенности
LongBench v2 имеет ряд существенных особенностей по сравнению с существующими бенчмарками для понимания длинных текстов:
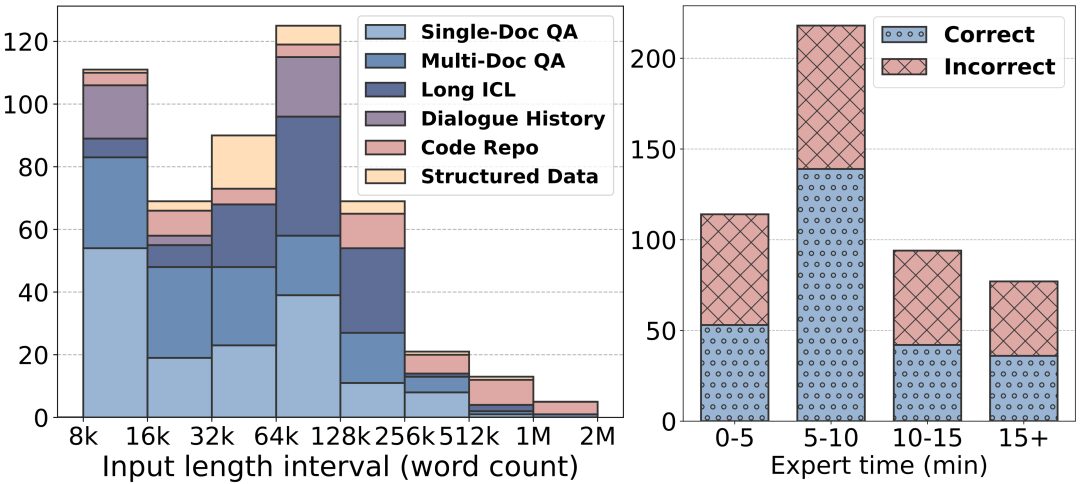
Большая длина текста: длина текста в LongBench v2 варьируется от 8 тыс. до 2 млн слов, при этом длина большинства текстов не превышает 128 тыс.
Повышенная сложность: LongBench v2 содержит 503 сложных вопроса с четырьмя вариантами выбора - вопросы, на которые даже эксперты-люди, использующие инструмент поиска в документах, с трудом смогли бы ответить правильно за короткий промежуток времени. Эксперты-люди в среднем достигли лишь 53,71 TP3T точности (251 TP3T в случайном порядке) за 15-минутный лимит времени.
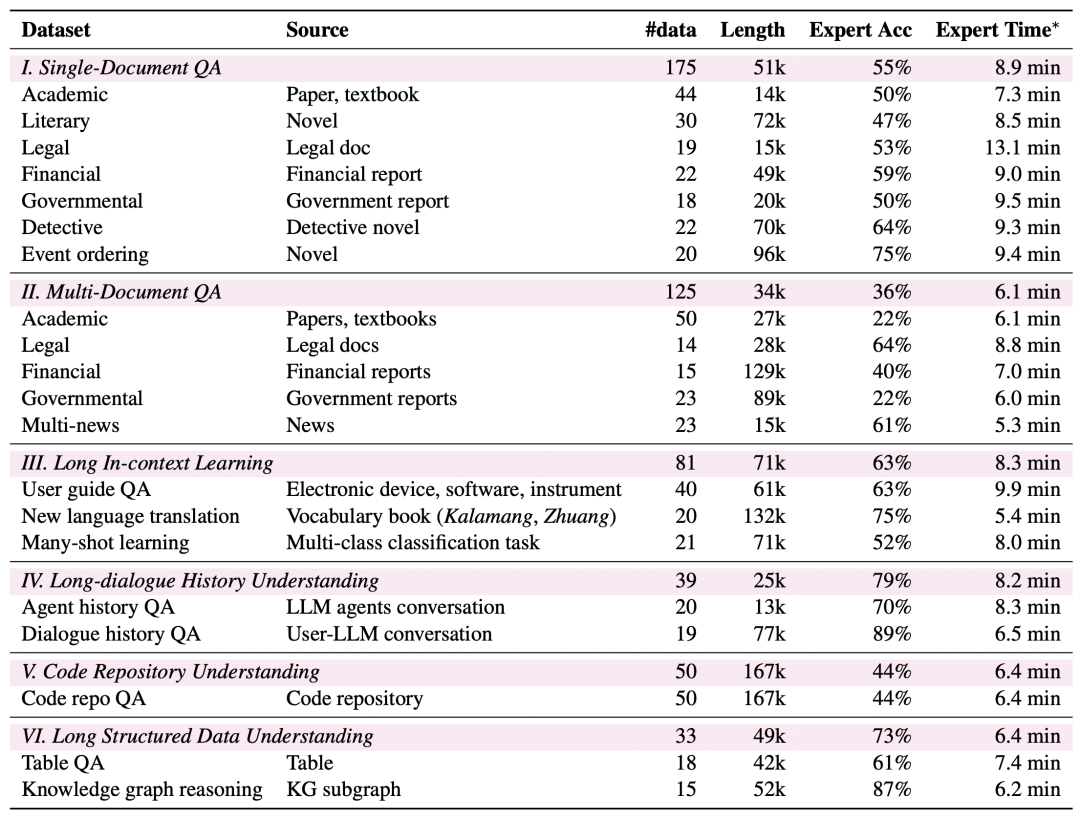
Более широкий охват задач: LongBench v2 охватывает шесть основных категорий задач, включая тестирование по одному документу, тестирование по нескольким документам, изучение контекста длинного текста, понимание истории длинного диалога, понимание репозитория кода и понимание длинных структурированных данных, а также 20 подзадач, охватывающих различные сценарии реального мира.
Повышенная надежность: Для обеспечения надежности оценки все вопросы в LongBench v2 представлены в формате множественного выбора и проходят строгий процесс ручной маркировки и проверки для обеспечения высокого качества данных.
Процесс сбора данных
Для обеспечения качества и сложности данных в LongBench v2 используется строгий процесс сбора данных, состоящий из следующих этапов:
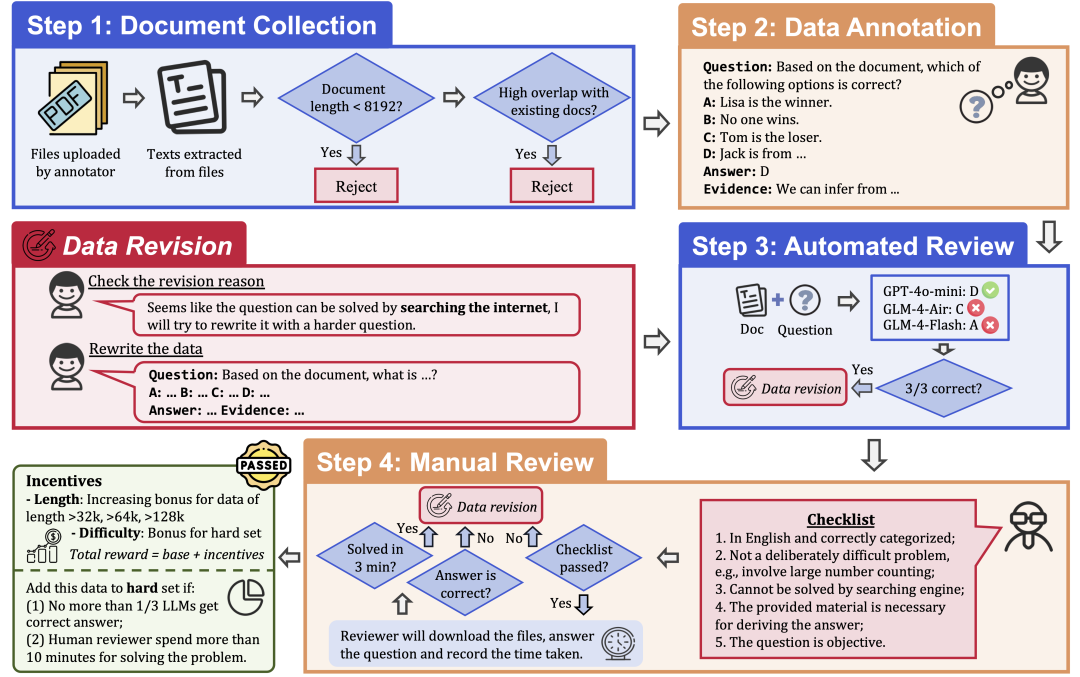
Сбор документов: наймите 97 аннотаторов из лучших университетов с разным уровнем образования и оценками, чтобы собрать длинные документы, которые они лично читали или использовали, такие как научные работы, учебники, романы и так далее.
Маркировка данных: на основе собранных документов специалист по маркировке задает вопрос с несколькими вариантами ответа, включающий четыре варианта, правильный ответ и соответствующие доказательства.
Автоматический просмотр: аннотированные данные были автоматически просмотрены с помощью трех LLM (GPT-4o-mini, GLM-4-Air и GLM-4-Flash) с контекстным окном 128k, и если все три модели отвечали на вопрос правильно, он считался слишком простым и нуждался в перемаркировке.
Человеческая проверка: данные, прошедшие автоматизированную проверку, передаются 24 профессиональным экспертам для человеческой проверки, которые пытаются ответить на вопрос и определить, уместен ли вопрос и правилен ли ответ. Если эксперт не может ответить на вопрос правильно в течение 3 минут, вопрос считается слишком простым и нуждается в перемаркировке. Кроме того, если эксперт считает, что сам вопрос не подходит или ответ на него неверен, он возвращается для повторной маркировки.
Пересмотр данных: данные, не прошедшие аудит, будут возвращены аннотатору на доработку до тех пор, пока они не пройдут все этапы аудита.
Результаты оценки
Команда оценила 10 открытых и 6 закрытых LLM с помощью LongBench v2. В ходе оценки рассматривались два сценария: "нулевой выстрел" и "нулевой выстрел+CoT" (т.е. сначала модель выводит цепочку мыслей, а затем - выбранный ответ).
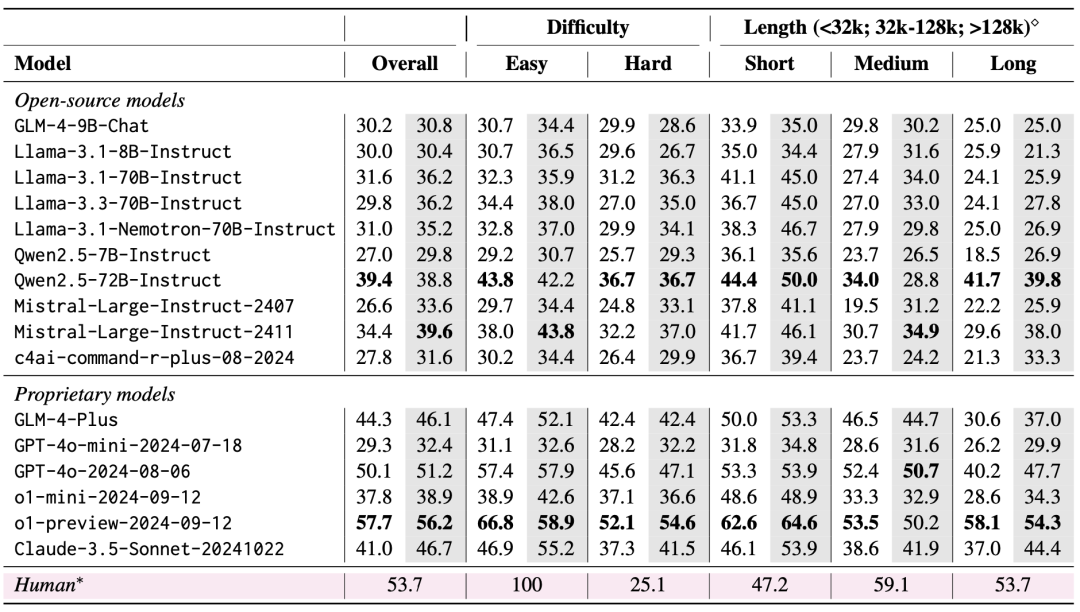
Результаты оценки показывают, что LongBench v2 является серьезным вызовом для существующих LLM: даже самая эффективная модель достигает точности всего 50,1% при прямом выводе ответа, в то время как модель o1-preview, которая вводит более длинную цепочку вывода, достигает точности 57,7%, что превосходит человеческий эксперт на 4%.
1. Важность масштабирования вычислений по времени вывода
Очень важным результатом оценки является то, что производительность моделей в LongBench v2 может быть значительно улучшена за счет масштабирования вычислений по времени вывода. Например, модель o1-preview достигает значительного улучшения в таких задачах, как викторина по нескольким документам, обучение контексту длинного текста и понимание репозитория кода, благодаря интеграции большего количества шагов вычисления по сравнению с GPT-4o.
Это говорит о том, что LongBench v2 предъявляет более высокие требования к возможностям рассуждений текущих моделей, и что увеличение времени, затрачиваемого на размышления и рассуждения о рассуждениях, является естественным и важным шагом на пути к решению таких длинных текстовых задач рассуждений.
2. RAG + эксперименты с длинным контекстом

Выяснилось, что обе модели, Qwen2.5 и GLM-4-Plus, не показывают значительного улучшения или даже ухудшения производительности после того, как количество извлекаемых блоков превышает определенный порог (32 тыс. токенов, около 64 блоков длиной 512).
Это говорит о том, что простое увеличение объема извлекаемой информации не всегда приводит к улучшению производительности. Напротив, GPT-4o способен эффективно использовать более длинные контексты поиска с оптимальным RAG Производительность достигается при длине поиска 128k.
Подводя итог, можно сказать, что RAG имеет ограниченное применение при решении задач с длинными текстовыми вопросами и ответами, требующими глубокого понимания и осмысления, особенно когда количество найденных блоков превышает определенный порог. Для эффективного решения сложных задач в LongBench v2 модель должна обладать более сильными способностями к рассуждениям, а не просто полагаться на полученную информацию.
Из этого также следует, что в будущем необходимо сосредоточиться на том, как улучшить собственные возможности модели по пониманию и осмыслению длинных текстов, а не просто полагаться на внешний поиск.
Мы ожидаем, что LongBench v2 расширит границы понимания длинных текстов и методов рассуждения. Не стесняйтесь читать нашу статью, использовать наши данные и узнавать больше!
Главная страница: https://longbench2.github.io
Диссертация: https://arxiv.org/abs/2412.15204
Данные и коды: https://github.com/THUDM/LongBench
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты


Нет комментариев...