
Llama 3: универсальное семейство моделей искусственного интеллекта с открытым исходным кодом

Тезисы.
В этой статье представлен новый набор базовых моделей под названием Llama 3. Llama 3 - это сообщество языковых моделей, которые по своей сути поддерживают многоязычие, написание кода, рассуждения и использование инструментов. Наша самая большая модель - это плотный трансформатор с 405 миллиардами параметров и контекстным окном до 128 000 лексем. В данной статье проводится обширная серия эмпирических оценок Llama 3. Результаты показывают, что на многих задачах Llama 3 достигает качества, сравнимого с ведущими языковыми моделями, такими как GPT-4. Мы выкладываем в открытый доступ Llama 3, включая предварительно обученные и пост-обученные языковые модели с 405 миллиардами параметров, а также модель Llama Guard 3 для обеспечения безопасности ввода-вывода. В данной статье также представлены экспериментальные результаты по интеграции изображений, видео и речевых характеристик в Llama 3 с помощью комбинаторного подхода. Мы видим, что этот подход конкурирует с современными подходами для задач распознавания изображений, видео и речи. Поскольку эти модели все еще находятся на стадии разработки, они не были широко опубликованы.
Полный текст скачать pdf:
1 Введение
базовая модельэто общие модели языка, зрения, речи и других модальностей, разработанные для поддержки широкого спектра задач ИИ. Они лежат в основе многих современных систем ИИ.
Разработка современной базовой модели делится на два основных этапа:
(1) Фаза предварительной подготовки. Модели обучаются на огромных объемах данных, используя простые задачи, такие как предсказание слов или создание аннотаций к графам;
(2) Посттренировочный этап. Модели настраиваются таким образом, чтобы следовать инструкциям, соответствовать предпочтениям человека и улучшать конкретные возможности (например, кодирование и рассуждения).
В данной статье представлен новый набор моделей языковой базы под названием Llama 3. Семейство моделей Llama 3 Herd по своей сути поддерживает многоязычие, кодирование, рассуждения и использование инструментов. Наша самая большая модель - это плотный трансформатор с 405B параметрами, способный обрабатывать информацию в контекстных окнах объемом до 128K токенов.
В таблице 1 перечислены все члены стада. Все результаты, представленные в данной статье, основаны на модели Llama 3.1 (сокращенно Llama 3).
Мы считаем, что тремя ключевыми инструментами для разработки высококачественных базовых моделей являются управление данными, масштабом и сложностью. Мы будем стремиться оптимизировать эти три направления в процессе разработки:
- Данные. По сравнению с предыдущими версиями Llama (Touvron et al., 2023a, b) были улучшены как количество, так и качество данных, которые мы использовали при предварительном и последующем обучении. Эти улучшения включают разработку более тщательных конвейеров предварительной обработки и курирования данных для предварительного обучения, а также более строгий контроль качества и фильтрацию. Более тщательная предварительная обработка и конвейерная обработка данных для предварительного обучения, а также разработка более строгой системы обеспечения качества и фильтрации Llama 3 была предварительно обучена на корпусе из примерно 15 Т многоязычных лексем, в то время как Llama 2 была предварительно обучена на 1,8 Т лексем.
- Область применения. Мы обучили более крупную модель, чем предыдущая модель Llama: наша флагманская языковая модель использует 3,8 × 1025 FLOPs для предварительного обучения, что почти в 50 раз больше, чем у самой большой версии Llama 2. В частности, мы предварительно обучили флагманскую модель с 405B обучаемых параметров на 15,6T текстовых лексем. Как и ожидалось, в результате

- Управление сложностью. Выбор дизайна был сделан для того, чтобы максимально увеличить масштабируемость процесса разработки модели. Например, мы выбрали стандартную плотную Трансформатор архитектура модели (Vaswani et al., 2017) с небольшими корректировками, а не использование экспертной модели смеси (Shazeer et al., 2017) для максимизации стабильности обучения. Аналогично, мы использовали относительно простой постпроцессор, основанный на супервизорной тонкой настройке (SFT), выборке с отклонением (RS) и прямой оптимизации предпочтений (DPO; Rafailov et al. (2023)), а не более сложные алгоритмы обучения с подкреплением (Ouyang et al., 2022; Schulman et al., 2017), которые обычно менее стабильны и трудно масштабируются. трудно масштабируемыми.
Результатом нашей работы стала Llama 3: трехъязычный мультилингв с параметрами 8B, 70B и 405B.1популяция языковых моделей. Мы оценили производительность Llama 3 на большом количестве эталонных наборов данных, охватывающих широкий спектр задач понимания языка. Кроме того, мы провели обширную ручную оценку, сравнив Llama 3 с конкурирующими моделями. В таблице 2 представлен обзор производительности флагманской модели Llama 3 в ключевых эталонных тестах. Наши экспериментальные оценки показывают, что наша флагманская модель находится на одном уровне с ведущими языковыми моделями, такими как GPT-4 (OpenAI, 2023a), и близка к современному уровню по целому ряду задач. Наша меньшая модель является лучшей в своем классе и превосходит другие модели с аналогичным количеством параметров (Bai et al., 2023; Jiang et al., 2023). Llama 3 также лучше соблюдает баланс между полезностью и безвредностью, чем ее предшественница (Touvron et al., 2023b). Мы подробно анализируем безопасность Llama 3 в разделе 5.4.
Мы выпускаем все три модели Llama 3 в открытый доступ в соответствии с обновленной версией лицензии Llama 3 Community License; см. https://llama.meta.com. Это включает в себя предварительно обученные и пост-обработанные версии нашей параметрической языковой модели 405B, а также новую версию модели Llama Guard (Inan et al., 2023) для защиты входных и выходных данных. и безопасности вывода. Мы надеемся, что публичный выпуск флагманской модели вызовет волну инноваций в исследовательском сообществе и ускорит прогресс на пути к ответственному развитию искусственного интеллекта (AGI).
Многоязычность: это способность модели понимать и генерировать текст на нескольких языках.
В ходе разработки Llama 3 мы также разработали мультимодальные расширения модели для распознавания изображений, видео и понимания речи. Эти модели все еще находятся в стадии активной разработки и пока не готовы к выпуску. В дополнение к результатам моделирования языка в этой статье представлены результаты наших первых экспериментов с этими мультимодальными моделями.
Llama 3 8B и 70B были предварительно обучены на многоязычных данных, но в то время использовались в основном для английского языка.

2 Генерал
Архитектура модели Llama 3 показана на рисунке 1. Разработка нашей языковой модели Llama 3 разделена на два основных этапа:
- Предварительное обучение языковой модели.Сначала мы преобразуем большой многоязычный корпус текстов в дискретные лексемы и предварительно обучаем большую языковую модель (LLM) на полученных данных для предсказания следующей лексемы. На этапе предварительного обучения LLM модель изучает структуру языка и приобретает большой объем знаний о мире из текста, который она "читает". Чтобы сделать это эффективно, предварительное обучение проводится в масштабе: мы предварительно обучили модель с 405B параметрами на модели с 15,6T лексем, используя контекстное окно из 8K лексем. За этой стандартной фазой предварительного обучения следует продолжение фазы предварительного обучения, которое увеличивает поддерживаемое контекстное окно до 128 тыс. лексем. Дополнительную информацию см. в разделе 3.
- Обучение после моделирования.Предварительно обученная языковая модель обладает богатым пониманием языка, но она еще не выполняет инструкции и не ведет себя как помощник, которого мы от нее ожидаем. Мы откалибровали модель с помощью обратной связи от людей в несколько раундов, каждый из которых включал контролируемую тонкую настройку (SFT) и прямую оптимизацию предпочтений (DPO; Rafailov et al., 2024) на данных, настроенных на инструкции. На этом этапе после обучения мы также интегрировали новые функции, такие как использование инструментов, и наблюдали значительные улучшения в таких областях, как кодирование и вывод. Более подробная информация приведена в разделе 4. Наконец, на этапе посттренинга в модель также интегрируются средства защиты, подробности которых описаны в разделе 5.4. Созданные модели обладают богатой функциональностью. Они способны отвечать на вопросы как минимум на восьми языках, писать качественный код, решать сложные задачи вывода и использовать инструменты из коробки или с нулевой выборкой.
Мы также проводим эксперименты по добавлению изображений, видео и голосовых возможностей в Llama 3 с помощью комбинированного подхода. Исследуемый нами подход состоит из трех дополнительных этапов, показанных на рисунке 28:

- Предварительное обучение мультимодального кодера.Мы обучаем отдельные кодировщики для изображения и речи. Мы обучаем кодировщик изображений на большом количестве пар "изображение-текст". Это позволяет модели изучить связь между визуальным контентом и его описанием на естественном языке. Наш кодер речи использует метод самоконтроля, который маскирует часть речевого ввода и пытается восстановить замаскированную часть с помощью дискретного представления маркеров. Таким образом, модель изучает структуру речевого сигнала. Более подробную информацию о кодировщиках изображений см. в разделе 7, а о кодировщиках речи - в разделе 8.
- Обучение визуальному адаптеру.Мы обучаем адаптер, который объединяет предварительно обученный кодировщик изображений с предварительно обученной языковой моделью. Адаптер состоит из серии слоев перекрестного внимания, которые передают представление кодировщика изображений в языковую модель. Адаптер обучается на парах "текст-изображение", что позволяет выровнять представление изображения с представлением языка. Во время обучения адаптера мы также обновляем параметры кодировщика изображений, но намеренно не обновляем параметры языковой модели. Поверх адаптера изображений мы также обучаем видеоадаптер, используя парные видео-текстовые данные. Это позволяет модели агрегировать информацию по кадрам. Более подробную информацию см. в разделе 7.
- Наконец, мы интегрируем кодировщик речи в модель с помощью адаптера, который преобразует кодирование речи в маркированное представление, которое может быть подано непосредственно в модель языка с точной настройкой. На этапе контролируемой тонкой настройки параметры адаптера и кодера совместно обновляются для достижения высокого качества понимания речи. Мы не изменяем языковую модель во время обучения речевого адаптера. Мы также интегрируем систему преобразования текста в речь. Более подробная информация приведена в разделе 8.
Наши мультимодальные эксперименты привели к созданию моделей, которые распознают содержание изображений и видео и поддерживают взаимодействие через речевой интерфейс. Эти модели все еще находятся в стадии разработки и пока не готовы к выпуску.
3 Предварительная подготовка
Предварительное обучение языковых моделей включает в себя следующие аспекты:
(1) Сбор и фильтрация крупномасштабных обучающих корпораций;
(2) Разработка архитектур моделей и соответствующих законов масштабирования для определения размера модели;
(3) Разработка методов эффективного крупномасштабного предварительного обучения;
(4) Разработка предтренировочной программы. Ниже мы опишем каждый из этих компонентов.
3.1 Данные предварительного обучения
Мы создали наборы данных для предварительного обучения языковых моделей из различных источников данных, содержащих информацию до конца 2023 года. Мы применили несколько методов дедупликации и механизмов очистки данных к каждому источнику данных, чтобы получить высококачественную маркировку. Мы удалили домены, содержащие большое количество персональной информации (PII), а также домены, известные как содержащие контент для взрослых.
3.11 Очистка данных в Интернете
Большинство данных, которые мы используем, поступают из Интернета, и мы описываем наш процесс очистки ниже.
PII и фильтрация безопасности. В числе прочих мер мы внедрили фильтры, предназначенные для удаления данных с сайтов, которые могут содержать небезопасный контент или большие объемы PII, домены, которые классифицируются как вредные в соответствии с различными стандартами безопасности Meta, а также домены, известные как содержащие контент для взрослых.
Извлечение и очистка текста. Мы обрабатываем необработанный HTML-контент для извлечения высококачественного и разнообразного текста и используем для этого не усеченные веб-документы. Для этого мы создали собственный парсер, который извлекает HTML-контент и оптимизирует точность удаления шаблонов и запоминания содержимого. Мы оценили качество парсера вручную и сравнили его с популярными сторонними HTML-парсерами, оптимизированными под содержание похожих статей, и пришли к выводу, что он работает хорошо. Мы внимательно относимся к HTML-страницам, содержащим математический и кодовый контент, чтобы сохранить структуру этого контента. Мы сохраняем текст атрибута alt изображения, поскольку математический контент обычно представлен в виде предварительно отрендеренного изображения, где математические данные также указываются в атрибуте alt.
Мы обнаружили, что уценка негативно сказывается на производительности модели, которая в основном обучалась на веб-данных, по сравнению с обычным текстом, поэтому мы удалили все теги уценки.
Уменьшить акцент. Мы применяем несколько раундов дедупликации на уровне URL, документа и строки:
- Дедупликация на уровне URL. Мы выполняем дедупликацию на уровне URL для всего набора данных. Для каждой страницы, соответствующей URL-адресу, мы сохраняем последнюю версию.
- Дедупликация на уровне документов. Мы выполняем глобальную дедупликацию MinHash (Broder, 1997) на всем наборе данных, чтобы удалить почти дублирующиеся документы.
- Дедупликация на уровне строк. Мы выполняем дедупликацию на радикальном уровне, подобно ccNet (Wenzek et al., 2019). Мы удаляем строки, которые встречаются более 6 раз в каждой группе, содержащей 30 миллионов документов.
Хотя наш ручной качественный анализ показывает, что дедупликация на уровне строк удаляет не только остаточный шаблонный контент с различных сайтов (например, навигационные меню, предупреждения о cookie), но и часто встречающийся высококачественный текст, наши эмпирические оценки показывают значительные улучшения.
Эвристическая фильтрация. Были разработаны эвристики для удаления дополнительных низкокачественных документов, выбросов и документов со слишком большим количеством повторений. Некоторые примеры эвристик включают:
- Мы используем покрытие дубликатов n-кортежей (Rae et al., 2021) для удаления строк, состоящих из дублирующегося контента (например, журналов или сообщений об ошибках). Такие строки могут быть очень длинными и уникальными, поэтому их невозможно отфильтровать с помощью дедупликации строк.
- Мы используем подсчет "грязных слов" (Raffel et al., 2020), чтобы отфильтровать сайты для взрослых, которые не попали в черный список доменов.
- Мы используем разброс Куллбэка-Лейблера распределения лексем, чтобы отсеять документы, содержащие слишком много аномальных лексем по сравнению с распределением обучающего корпуса.
Фильтрация качества на основе моделей.
Кроме того, мы попытались использовать различные классификаторы качества на основе моделей для выбора качественных меток. К таким методам относятся:
- Использование быстрых классификаторов, таких как fasttext (Joulin et al., 2017), которые обучены распознавать, будет ли данный текст процитирован в Википедии (Touvron et al., 2023a).
- Использовался более требовательный к вычислительным ресурсам классификатор модели Roberta (Liu et al., 2019a), который был обучен на предсказаниях Llama 2.
Чтобы обучить классификатор качества на основе Llama 2, мы создали набор очищенных веб-документов с описанием требований к качеству и поручили модели чата Llama 2 определить, соответствуют ли документы этим требованиям. Для эффективности мы использовали DistilRoberta (Sanh et al., 2019) для генерации оценок качества для каждого документа. Мы экспериментально оценим эффективность различных конфигураций фильтрации качества.
Код и данные о выводах.
Подобно DeepSeek-AI и др. (2024), мы создали специфические для конкретного домена конвейеры для извлечения веб-страниц, содержащих код и связанных с математикой. В частности, классификаторы кодов и выводов представляют собой модели DistilledRoberta, обученные на аннотированных веб-данных Llama 2. В отличие от общих классификаторов качества, упомянутых выше, мы выполняем настройку подсказок для целевых веб-страниц, содержащих математические выводы, рассуждения в областях STEM и код, встроенный в естественный язык. Поскольку распределение лексем в коде и математике сильно отличается от распределения лексем в естественном языке, в этих конвейерах реализовано извлечение HTML, специфичное для конкретной области, пользовательские текстовые функции и эвристики для фильтрации.
Многоязычные данные.
Подобно описанному выше конвейеру обработки английского языка, мы применяем фильтры для удаления данных веб-сайта, которые могут содержать персональную информацию (PII) или небезопасный контент. Наш конвейер обработки многоязычных текстов имеет следующие уникальные особенности:
- Для классификации документов на 176 языков мы используем модель быстрого распознавания языка на основе текста.
- Мы выполняем дедупликацию данных на уровне документов и строк для каждого языка.
- Для удаления некачественных документов мы применяем эвристику, учитывающую особенности языка, и фильтры на основе моделей.
Кроме того, мы используем многоязычный классификатор на основе Llama 2 для ранжирования качества многоязычных документов, чтобы обеспечить приоритет высококачественного контента. Количество многоязычных лексем, используемых в предварительном обучении, определяется экспериментально, а производительность модели балансируется на англоязычных и многоязычных эталонных тестах.
3.12 Определение состава данных
为了获得高质量语言模型,必须谨慎确定预训练数据混合中不同数据源的比例。我们主要利用知识分类和尺度定律实验来确定这一数据混合。
知识分类。我们开发了一个分类器,用于对网页数据中包含的信息类型进行分类,以便更有效地确定数据组合。我们使用这个分类器对网页上过度代表的数据类别(例如艺术和娱乐)进行下采样。
为了确定最佳数据混合方案。我们进行规模定律实验,其中我们将多个小型模型训练于特定数据混合集上,并利用其预测大型模型在该混合集上的性能(参见第 3.2.1 节)。我们多次重复此过程,针对不同的数据混合集选择新的候选数据混合集。随后,我们在该候选数据混合集上训练一个更大的模型,并在多个关键基准测试上评估该模型的性能。
数据混合摘要。我们的最终数据混合包含大约 50% 的通用知识标记、25% 的数学和推理标记、17% 的代码标记以及 8% 的多语言标记。
3.13 Данные отжига
Эмпирические результаты показывают, что отжиг на небольшом количестве высококачественных данных по коду и математике (см. раздел 3.4.3) может улучшить производительность предварительно обученных моделей на ключевых эталонных тестах. Как и в исследовании Li et al. (2024b), мы отжигаем на смешанном наборе данных, содержащем высококачественные данные из отдельных областей. Наши отжигаемые данные не содержат обучающих наборов из широко используемых эталонных тестов. Это позволяет нам оценить истинную способность Llama 3 к обучению на нескольких выборках и обобщению за пределами домена.
Следуя OpenAI (2023a), мы оценили эффект отжига на обучающих наборах GSM8k (Cobbe et al., 2021) и MATH (Hendrycks et al., 2021b). Мы обнаружили, что отжиг улучшает производительность предварительно обученной модели Llama 3 8B на 24,0% и 6,4% на наборах проверки GSM8k и MATH, соответственно. Однако для модели 405B улучшение незначительно, что говорит о том, что наша флагманская модель обладает сильными возможностями контекстного обучения и вывода, и что для достижения высокой производительности ей не нужны специфические для области обучающие выборки.
Используйте отжиг для оценки качества данных.Как и в работе Blakeney et al. (2024), мы обнаружили, что отжиг позволяет оценить ценность небольших наборов данных, специфичных для конкретной области. Мы оцениваем ценность этих наборов данных, линейно отжигая скорость обучения модели Llama 3 8B, которая была обучена с помощью 50%, до 0 на 40 миллиардах лексем. В этих экспериментах мы присваиваем 30% веса новому набору данных, а остальные 70% веса - набору данных по умолчанию. Эффективнее использовать отжиг для оценки новых источников данных, чем проводить эксперименты по закону масштаба на каждом небольшом наборе данных.
3.2 Архитектура модели
В Llama 3 используется стандартная архитектура плотного трансформера (Vaswani et al., 2017). Архитектура ее модели существенно не отличается от Llama и Llama 2 (Touvron et al., 2023a, b); прирост производительности достигается в основном за счет улучшения качества и разнообразия данных, а также увеличения объема обучения.
Мы внесли несколько незначительных изменений:
- Мы используем группированное внимание к запросу (GQA; Ainslie et al. (2023)), где 8 заголовков ключевых значений используются для увеличения скорости вывода и уменьшения размера кэша ключевых значений при декодировании.
- Мы используем маску внимания, чтобы предотвратить механизмы самовнимания между различными документами в последовательности. Мы обнаружили, что это изменение имеет ограниченное влияние при стандартном предварительном обучении, но очень важно при непрерывном предварительном обучении очень длинных последовательностей.
- Мы используем словарь из 128 тыс. лексем. Наш токенизированный словарь объединяет 100 тыс. токенов словаря tiktoken3 и 28 тыс. дополнительных токенов для лучшей поддержки неанглийских языков. По сравнению со словарем Llama 2, наш новый словарь улучшает сжатие образцов данных на английском языке с 3,17 до 3,94 символов/токен. Это позволяет модели "читать" больше текста при том же объеме обучающих вычислений. Мы также обнаружили, что добавление 28 тыс. токенов из определенных неанглийских языков улучшило сжатие и производительность, но не повлияло на англоязычную токенизацию.
- Мы увеличиваем гиперпараметр базовой частоты RoPE до 500 000. Это позволяет нам лучше поддерживать более длинные контексты; Xiong et al. (2023) показывают, что это значение справедливо для контекстов длиной до 32 768.

Llama 3 405B использует архитектуру с 126 слоями, 16 384 размерами представления маркеров и 128 головками внимания; более подробную информацию см. в таблице 3. Это приводит к размеру модели, который является приблизительно вычислительно оптимальным на основе наших данных, и бюджету обучения 3,8 × 10^25 FLOPs.
3.2.1 Законы масштаба
Мы использовали законы масштабирования (Hoffmann et al., 2022; Kaplan et al., 2020) для определения оптимального размера флагманской модели с учетом нашего бюджета вычислений перед обучением. Помимо определения оптимального размера модели, прогнозирование производительности флагманской модели на последующих эталонных задачах представляет значительные трудности по следующим причинам:
- Существующие законы масштабирования, как правило, предсказывают только потери при предсказании следующей метки, а не конкретную производительность бенчмарка.
- Законы масштабирования могут быть шумными и ненадежными, поскольку они разрабатываются на основе предварительного обучения с использованием небольшого вычислительного бюджета (Wei et al., 2022b).
Чтобы решить эти проблемы, мы применили двухэтапный подход к разработке законов масштабирования, которые точно предсказывают производительность последующих бенчмарков:
- Сначала мы устанавливаем корреляцию между предварительным обучением FLOP и вычислением отрицательного логарифма наилучшей модели на последующей задаче.
- Далее мы соотносим отрицательное логарифмическое правдоподобие на последующей задаче с точностью выполнения задачи, используя модель Scaling Laws и более старую модель, обученную с использованием более высоких вычислительных FLOP. На этом этапе мы используем исключительно модели семейства Llama 2.
Такой подход позволяет нам предсказывать выполнение последующих задач (для оптимальных с вычислительной точки зрения моделей) на основе определенного количества предварительно обученных FLOP. Аналогичный подход мы используем для выбора комбинаций данных для предварительного обучения (см. раздел 3.4).
Масштабирование Правовой эксперимент.В частности, мы построили законы масштабирования путем предварительного обучения моделей с использованием вычислительных бюджетов от 6 × 10^18 FLOPs до 10^22 FLOPs. При каждом вычислительном бюджете мы предварительно обучали модели с размером от 40M до 16B параметров и использовали часть размера модели при каждом вычислительном бюджете. В этих тренировочных прогонах мы использовали косинусоидальное планирование скорости обучения и линейный прогрев в течение 2 000 шагов обучения. Пиковая скорость обучения была установлена в диапазоне от 2 × 10^-4 до 4 × 10^-4 в зависимости от размера модели. Косинусоидальное затухание мы установили в 0,1 раза больше пикового значения. Затухание веса для каждого шага было установлено в 0,1 раза больше скорости обучения для этого шага. Мы использовали фиксированный размер партии для каждого размера вычислений, варьирующийся от 250K до 4M.

В результате этих экспериментов были получены кривые IsoFLOPs, показанные на рисунке 2. Потери на этих кривых были измерены на отдельных проверочных наборах. Мы подгоняем измеренные значения потерь с помощью полинома второго порядка и определяем минимальное значение каждой параболы. Минимум параболы мы называем вычислительно оптимальной моделью при соответствующем бюджете вычислений.
Мы используем определенную таким образом вычислительно оптимальную модель для предсказания оптимального количества обучающих лексем при заданном вычислительном бюджете. Для этого мы предполагаем, что между вычислительным бюджетом C и оптимальным количеством обучающих лексем N (C) существует зависимость типа "степенной закона":
N (C) = AC α .
Мы подгоняем A и α, используя данные на рис. 2. Мы находим (α, A) = (0.53, 0.29); соответствующая подгонка показана на рис. 3. Экстраполяция полученного закона масштабирования на 3,8 × 10 25 FLOPs предполагает обучение модели с 402B параметрами и использование 16,55T токенов.
Важным наблюдением является то, что кривая IsoFLOPs становится более плоской в районе минимума по мере увеличения вычислительного бюджета. Это означает, что производительность флагманской модели относительно стабильна при небольших изменениях в компромиссе между размером модели и маркерами обучения. Основываясь на этом наблюдении, мы решили обучить флагманскую модель, содержащую параметр 405B.
Прогнозирование выполнения последующих задач.Мы используем сгенерированную вычислительно оптимальную модель для прогнозирования производительности флагманской модели Llama 3 на эталонном наборе данных. Во-первых, мы линейно связываем (нормализованное) отрицательное логарифмическое правдоподобие правильного ответа в эталоне с количеством тренировочных FLOPs. Для этого анализа мы использовали только модель с законом масштабирования, обученную до 10^22 FLOPs на вышеуказанной смеси данных. Далее мы установили S-образную зависимость между логарифмическим правдоподобием и точностью с помощью модели закона масштабирования и модели Llama 2, которая была обучена на смеси данных и теггере Llama 2. (Результаты этого эксперимента на эталоне ARC Challenge показаны на рисунке 4). Мы считаем, что двухступенчатое предсказание по закону масштабирования (экстраполированное на четыре порядка) является довольно точным: оно лишь немного недооценивает итоговую производительность флагманской модели Llama 3.
3.3 Инфраструктура, расширение и эффективность
Мы описываем аппаратное обеспечение и инфраструктуру, поддерживающую предварительное обучение Llama 3 405B, и обсуждаем несколько оптимизаций, повышающих эффективность обучения.
3.3.1 Инфраструктура обучения
Модели Llama 1 и Llama 2 были обучены на исследовательском суперкластере ИИ Meta (Lee and Sengupta, 2022). По мере дальнейшего расширения масштаба обучение Llama 3 было перенесено на производственный кластер Meta (Lee et al., 2024). Такая настройка оптимизирует надежность на уровне производства, что очень важно при увеличении масштаба обучения.

Вычислительные ресурсы: Llama 3 405B обучает до 16 000 графических процессоров H100, каждый из которых работает на 700 Вт TDP с 80 ГБ HBM3, используя серверную платформу Grand Teton AI компании Meta (Matt Bowman, 2022). Каждый сервер оснащен восемью GPU и двумя CPU; внутри сервера восемь GPU подключены через NVLink. Задания на обучение планируются с помощью MAST (Choudhury et al., 2024), глобального планировщика обучения от Meta.
Хранение: Tectonic (Pan et al., 2021), распределенная файловая система общего назначения Meta, была использована для создания архитектуры хранения данных для предварительного обучения Llama 3 (Battey and Gupta, 2024). Она предоставляет 240 ПБ пространства для хранения данных и состоит из 7500 серверов, оснащенных SSD, поддерживающих устойчивую пропускную способность 2 ТБ/с и пиковую пропускную способность 7 ТБ/с. Основной проблемой является поддержка высокоскоростной записи контрольных точек, которая насыщает систему хранения данных за короткий промежуток времени. Контрольные точки сохраняют состояние модели на GPU, от 1 МБ до 4 ГБ на GPU, для восстановления и отладки. Наша цель - минимизировать время паузы GPU во время создания контрольных точек и увеличить частоту создания контрольных точек, чтобы уменьшить объем работы, потерянной после восстановления.
Сетевое взаимодействие: В Llama 3 405B используется архитектура RDMA over Converged Ethernet (RoCE) на базе стоечных коммутаторов Arista 7800 и Minipack2 Open Compute Project (OCP). Меньшие модели серии Llama 3 обучались с помощью сети Nvidia Quantum2 Infiniband. Оба кластера RoCE и Infiniband используют соединение между графическими процессорами на скорости 400 Гбит/с. Несмотря на различия в сетевых технологиях, лежащих в основе этих кластеров, мы настроили оба кластера таким образом, чтобы обеспечить эквивалентную производительность для обработки этих больших обучающих рабочих нагрузок. Мы подробнее расскажем о нашей сети RoCE, когда полностью овладеем ее дизайном.
- Топология сети: Наш кластер ИИ на базе RoCE содержит 24 000 графических процессоров (сноска 5), соединенных трехуровневой сетью Clos (Lee et al., 2024). На нижнем уровне каждая стойка содержит 16 графических процессоров, распределенных между двумя серверами и подключенных через один коммутатор Minipack2 top-of-rack (ToR). На среднем уровне 192 таких стойки подключаются через кластерные коммутаторы, образуя Pod из 3 072 GPU с полной двунаправленной пропускной способностью, что исключает переподписку. На верхнем уровне восемь таких стоек в одном здании центра обработки данных соединяются с помощью агрегирующих коммутаторов, образуя кластер из 24 000 GPU. Однако вместо того, чтобы поддерживать полную двунаправленную пропускную способность, сетевые соединения на уровне агрегации имеют коэффициент переподписки 1:7. Как наш модельно-параллельный подход (см. раздел 3.3.2), так и планировщик учебных заданий (Choudhury et al., 2024) оптимизированы с учетом топологии сети и направлены на минимизацию сетевого взаимодействия между бодами.
- Балансировка нагрузки: Обучение больших языковых моделей генерирует большой сетевой трафик, который сложно распределить по всем доступным сетевым путям с помощью традиционных методов, таких как многопутевая маршрутизация с равными затратами (ECMP). Чтобы решить эту проблему, мы используем две техники. Во-первых, наша агрегатная библиотека создает 16 сетевых потоков между двумя GPU вместо одного, тем самым уменьшая количество трафика на поток и предоставляя больше потоков для балансировки нагрузки. Во-вторых, наш протокол Enhanced ECMP (E-ECMP) эффективно балансирует эти 16 потоков между различными сетевыми путями путем хэширования других полей в пакете с заголовком RoCE.

- Управление перегрузками: Мы используем переключатели с глубоким буфером (Gangidi et al., 2024) в магистральной сети, чтобы справиться с переходными перегрузками и буферизацией, вызванными совокупностью моделей связи. Это помогает ограничить влияние постоянных перегрузок и обратного давления на сеть, вызванного медленными серверами, что часто встречается в процессе обучения. Наконец, более эффективная балансировка нагрузки с помощью E-ECMP значительно снижает вероятность возникновения перегрузок. Благодаря этим оптимизациям мы успешно запустили кластер из 24 000 графических процессоров без использования традиционных методов контроля перегрузок, таких как уведомление о перегрузках в центре обработки данных (DCQCN).
3.3.2 Параллелизм при масштабировании моделей
Чтобы увеличить масштаб обучения нашей самой большой модели, мы разделили ее на части, используя 4D-параллелизм - схему, сочетающую четыре различных параллельных подхода. Этот подход эффективно распределяет вычисления между многими GPU и гарантирует, что параметры модели, состояния оптимизатора, градиенты и значения активации каждого GPU уместятся в его HBM. Наша 4D-параллельная реализация (как показано в et al. (2020); Ren et al. (2021); Zhao et al. (2023b)) нарезает модель, оптимизатор и градиенты, реализуя параллелизм данных - параллельный подход, который обрабатывает данные параллельно на нескольких GPU и синхронизирует их после каждого шага обучения. Мы используем FSDP для нарезки состояния оптимизатора и градиента для Llama 3, но для нарезки модели мы не производим повторную нарезку после прямого вычисления, чтобы избежать дополнительной связи с полным сбором данных во время обратного прохода.
Использование графического процессора.Тщательно настраивая параллельную конфигурацию, аппаратное и программное обеспечение, мы добились использования FLOPs модели BF16 (MFU; Chowdhery et al. (2023)) на уровне 38-43%. Конфигурации, представленные в таблице 4, показывают, что по сравнению с 43% на 8K GPU и DP=64, снижение MFU до 41% на 16K GPU и DP=128 связано с необходимостью уменьшить размер партии каждой группы DP для поддержания постоянного количества глобальных маркеров во время обучения. 41% связано с необходимостью уменьшения размера партии каждой группы DP для поддержания постоянного количества глобальных маркеров во время обучения.
Упорядочить параллельные улучшения.Мы столкнулись с несколькими проблемами в нашей существующей реализации:
- Ограничения на размер партии.Текущие реализации накладывают ограничение на размер пакета, поддерживаемого одним GPU, требуя, чтобы он был кратен числу этапов конвейера. Для примера на рис. 6 параллелизм конвейера при планировании в глубину (DFS) (Narayanan et al. (2021)) требует N = PP = 4, а при планировании в ширину (BFS; Lamy-Poirier (2023)) - N = M, где M - общее количество микробатчей, а N - количество последовательных микробатчей на одном и том же этапе в прямом или обратном направлении. Однако предварительное обучение обычно требует гибкости в определении размера партии.
- Нарушение баланса памяти.Существующие параллельные реализации с конвейерным построением приводят к несбалансированному потреблению ресурсов. Первый этап потребляет больше памяти из-за встраивания и разогрева микропакетов.
- Расчеты не сбалансированы. После последнего слоя модели нам необходимо вычислить выходы и потери, что делает эту фазу узким местом с точки зрения времени выполнения. где Di - индекс i-го параллельного измерения. В данном примере GPU0[TP0, CP0, PP0, DP0] и GPU1[TP1, CP0, PP0, DP0] находятся в одной группе TP, GPU0 и GPU2 - в одной группе CP, GPU0 и GPU4 - в одной группе PP, а GPU0 и GPU8 - в одной группе DP.

Чтобы решить эти проблемы, мы модифицировали подход к планированию конвейера, как показано на рисунке 6, который позволяет гибко задавать N - в данном случае N = 5, что позволяет запускать любое количество микропакетов в каждой партии. Это позволяет нам:
(1) Если существует ограничение на размер партии, запускайте меньше микропартий, чем количество стадий; или
(2) Запускаем больше микропакетов, чтобы скрыть одноранговую связь и найти оптимальную эффективность использования памяти и связи между Depth-First Scheduling (DFS) и Breadth-First Scheduling (BFS). Чтобы сбалансировать конвейер, мы уменьшаем один слой трансформатора с первого и последнего этапов, соответственно. Это означает, что первый блок модели на первом этапе содержит только слой встраивания, а последний блок модели на последнем этапе - только выходную проекцию и вычисление потерь.
Чтобы уменьшить количество "пузырей" в конвейере, мы используем подход чередующегося планирования (Narayanan et al., 2021) на иерархической структуре с V этапами конвейера. Общий коэффициент загрузки конвейера составляет PP-1 V * M . Кроме того, мы используем асинхронную одноранговую связь, которая значительно ускоряет обучение, особенно в тех случаях, когда маски документов вносят дополнительный вычислительный дисбаланс. Мы включаем TORCH_NCCL_AVOID_RECORD_STREAMS, чтобы уменьшить расход памяти при асинхронном обмене данными между пирами. Наконец, для снижения затрат на память, основываясь на детальном анализе распределения памяти, мы проактивно освобождаем тензоры, которые не будут использоваться для будущих вычислений, включая входные и выходные тензоры для каждого этапа конвейера. ** Благодаря этим оптимизациям мы можем выполнять 8K тензоров без использования контрольных точек активации, без использования контрольных точек активации. жетон последовательности для предварительной тренировки Llama 3.
Контекстное распараллеливание используется для длинных последовательностей. Мы используем контекстное распараллеливание (CP) для повышения эффективности использования памяти при масштабировании длины контекста Llama 3 и для обучения на очень длинных последовательностях длиной до 128 Кбайт. В CP мы разделяем последовательности по размерам, в частности, мы делим входную последовательность на блоки 2 × CP таким образом, чтобы каждый уровень CP получал два блока для лучшей балансировки нагрузки. На i-й уровень CP поступают i-й и (2 × CP -1 -i) блоки.
В отличие от существующих реализаций CP, в которых связь и вычисления перекрываются в кольцевой структуре (Liu et al., 2023a), в нашей реализации CP используется подход, основанный на сборе всех данных, который сначала глобально агрегирует тензор ключ-значение (K, V), а затем вычисляет аттенционные выходы локальных блоков тензора запроса (Q). Несмотря на то, что задержка связи между всеми блоками находится на критическом пути, мы все равно используем этот подход по двум основным причинам:
(1) Легче и гибче поддерживать различные типы масок внимания, такие как маски документов, в системе внимания CP, основанной на сборе всех данных;
(2) Выявленная латентность all-gather мала, потому что тензор K и V связи намного меньше тензора Q, благодаря использованию GQA (Ainslie et al., 2023). В результате временная сложность вычислений внимания на порядок больше, чем у all-gather (O(S²) против O(S), где S обозначает длину последовательности в полной каузальной маске), что делает накладные расходы на all-gather пренебрежимо малыми.

Параллельное конфигурирование с учетом особенностей сети.Порядок размеров распараллеливания [TP, CP, PP, DP] оптимизирован для сетевого взаимодействия. Самый внутренний уровень распараллеливания требует наибольшей пропускной способности сети и наименьшей задержки, поэтому обычно ограничивается одним сервером. Внешний уровень распараллеливания может охватывать многоходовые сети и должен быть способен выдерживать более высокую задержку в сети. Поэтому, основываясь на требованиях к пропускной способности сети и задержкам, мы расположили размеры распараллеливания в порядке [TP, CP, PP, DP]. DP (т. е. FSDP) - это самый внешний слой распараллеливания, поскольку он может выдерживать более длительные задержки в сети за счет асинхронной предварительной выборки весов модели нарезки и уменьшения градиента. Определение оптимальной конфигурации распараллеливания с минимальными коммуникационными накладными расходами и при этом без переполнения памяти GPU представляет собой сложную задачу. Мы разработали оценщик потребления памяти и инструмент прогнозирования производительности, которые помогли нам исследовать различные конфигурации распараллеливания, предсказать общую производительность обучения и эффективно выявить нехватку памяти.
Численная стабильность.Сравнивая потери при обучении между различными параллельными настройками, мы устраняем некоторые численные проблемы, влияющие на стабильность обучения. Чтобы обеспечить сходимость обучения, мы используем накопление градиента в FP32 при обратном вычислении нескольких микробатчей и уменьшаем разброс градиентов с помощью FP32 между параллельными рабочими в FSDP. Для промежуточных тензоров, которые многократно используются в прямых вычислениях, таких как выходы визуального кодера, обратный градиент также накапливается в FP32.
3.3.3 Коллективные коммуникации
Библиотека коллективных коммуникаций Llama 3 основана на ветви библиотеки NCCL от Nvidia под названием NCCLX. NCCLX значительно улучшает производительность NCCL, особенно для сетей с высокой задержкой. Напомним, что порядок параллельных измерений - [TP, CP, PP, DP], где DP соответствует FSDP, и что крайние параллельные измерения, PP и DP, могут обмениваться данными через многоходовую сеть с задержками в десятки микросекунд. В FSDP используются операции коллективной связи all-gather и reduce-scatter из оригинальной NCCL, а в PP - связь "точка-точка", требующая разбиения данных на части и поэтапной репликации данных. Такой подход приводит к следующим неэффективным последствиям:
- Для облегчения передачи данных по сети необходимо обмениваться большим количеством небольших управляющих сообщений;
- Дополнительные операции копирования памяти;
- Используйте дополнительные циклы GPU для коммуникации.
Для обучения Llama 3 мы устранили некоторые из этих неэффективных факторов, адаптировав разбиение на части и передачу данных к задержкам в сети, которые в больших кластерах могут достигать десятков микросекунд. Мы также позволяем небольшим управляющим сообщениям проходить через нашу сеть с более высоким приоритетом, что позволяет избежать блокировки головки очереди в коммутаторах ядра с глубокой буферизацией.
Наша текущая работа над будущими версиями Llama включает в себя более глубокие изменения в NCCLX, чтобы полностью решить все вышеперечисленные проблемы.

3.3.4 Надежность и эксплуатационные проблемы
Сложность и потенциальные сценарии сбоев при обучении на 16K GPU превышают аналогичные показатели более крупных кластеров CPU, на которых мы работали. Кроме того, синхронный характер обучения делает его менее отказоустойчивым - отказ одного GPU может потребовать перезапуска всего задания. Несмотря на эти сложности, в Llama 3 мы добились эффективного времени обучения выше 90%, при этом поддерживая автоматическое обслуживание кластера (например, обновление прошивки и ядра Linux (Vigraham and Leonhardi, 2024)), что приводило как минимум к одному перерыву в обучении в день.
Эффективное время обучения - это количество времени, потраченное на эффективное обучение за истекшее время. В течение 54 дней, предшествовавших обучению, мы пережили в общей сложности 466 перерывов в работе. Из них 47 были запланированными перерывами, связанными с автоматическим техническим обслуживанием (например, обновление прошивки или операции по инициативе оператора, такие как обновление конфигурации или наборов данных). Остальные 419 перебоев были непредвиденными, их классификация приведена в Таблице 5. Примерно 78% непредвиденных отключений были связаны с выявленными аппаратными проблемами, такими как отказы GPU или компонентов хоста, или предполагаемыми аппаратными проблемами, такими как тихое повреждение данных и незапланированные события по обслуживанию отдельных хостов.Проблемы с GPU были самой большой категорией, составляя 58,7% от всех непредвиденных проблем.Несмотря на большое количество отказов, только три крупных ручных вмешательства потребовались за этот период. Несмотря на большое количество сбоев, за этот период потребовалось лишь три серьезных ручных вмешательства, а остальные проблемы были решены с помощью автоматизации.
Чтобы увеличить эффективное время обучения, мы сократили время запуска заданий и создания контрольных точек, а также разработали инструменты для быстрой диагностики и решения проблем. Мы широко использовали встроенный в PyTorch NCCL Flight Recorder (Ansel et al., 2024) - функцию, которая записывает коллективные метаданные и трассировку стека в кольцевой буфер, позволяя быстро диагностировать зависания и проблемы производительности в масштабе, особенно в случае с аспектов NCCLX. С его помощью мы можем эффективно регистрировать события взаимодействия и продолжительность каждой коллективной операции, а также автоматически сбрасывать данные трассировки в случае таймаута сторожевого таймера NCCLX или сердцебиения. Благодаря изменению конфигурации в режиме онлайн (Tang et al., 2015) мы можем выборочно включать более интенсивные с вычислительной точки зрения операции трассировки и сбор метаданных без выпуска кода или перезапуска задания. Проблемы отладки в крупномасштабном обучении осложняются смешанным использованием NVLink и RoCE в нашей сети. Передача данных обычно осуществляется через NVLink посредством операций загрузки/хранения, выполняемых ядром CUDA, и отказ удаленного GPU или NVLink-соединения часто проявляется как остановка операции загрузки/хранения в ядре CUDA без возврата явного кода ошибки. NCCLX повышает скорость и точность обнаружения и локализации сбоев благодаря тесному взаимодействию с PyTorch, позволяющему PyTorch получать доступ к внутреннему состоянию NCCLX и отслеживать соответствующую информацию. Хотя полностью предотвратить задержки из-за сбоев NVLink невозможно, наша система следит за состоянием коммуникационных библиотек и автоматически прерывает работу при обнаружении таких задержек. Кроме того, NCCLX отслеживает активность ядра и сети при каждой коммуникации NCCLX и предоставляет снимок внутреннего состояния отказавшего коллектива NCCLX, включая завершенные и незавершенные передачи данных между всеми рангами. Мы анализируем эти данные для отладки проблем с расширением NCCLX.
Иногда аппаратные проблемы могут приводить к появлению все еще работающих, но медленных отстающих процессоров, которые трудно обнаружить. Даже если это всего лишь один отступник, он может замедлить работу тысяч других GPU, часто в виде нормальной работы, но медленного обмена данными. Мы разработали инструменты для определения приоритетности потенциально проблемных соединений от выбранных групп процессов. Исследуя только несколько ключевых подозреваемых, мы часто можем эффективно выявлять заблудившихся.
Интересным наблюдением является влияние факторов окружающей среды на производительность крупномасштабных тренировок. Для Llama 3 405B мы заметили колебания пропускной способности в пределах 1-2% в зависимости от изменения времени. Эти колебания вызваны более высокими полуденными температурами, влияющими на динамическое масштабирование напряжения и частоты GPU. Во время обучения десятки тысяч GPU могут одновременно увеличивать или уменьшать энергопотребление, например, из-за того, что все GPU ожидают окончания контрольной точки или коллективного обмена данными, а также запуска или завершения всего учебного задания. Когда такое происходит, это может привести к переходным колебаниям энергопотребления в центре обработки данных порядка десятков мегаватт, что ограничивает возможности энергосистемы. Это постоянная проблема, поскольку мы расширяем масштабы обучения для будущих и еще более крупных моделей Llama.
3.4 Программы обучения
Рецепт предварительной тренировки для Llama 3 405B состоит из трех основных этапов:
(1) начальное предварительное обучение, (2) предварительное обучение в длинном контексте и (3) отжиг. Каждый из этих трех этапов описан ниже. Мы используем аналогичные рецепты для предварительного обучения моделей 8B и 70B.
3.4.1 Первоначальное предварительное обучение
Мы провели предварительное обучение модели Llama 3 405B, используя схему косинусоидального обучения с максимальной скоростью обучения 8 × 10-⁵, линейный прогрев до 8 000 шагов и спад до 8 × 10-⁷ после 1 200 000 шагов обучения. Чтобы повысить стабильность обучения, мы используем меньший размер партии в начале обучения и впоследствии увеличиваем размер партии для повышения эффективности. В частности, изначально размер партии составляет 4 М лексем, а длина последовательности - 4 096. После предварительного обучения 252 М лексем мы удваиваем размер партии и длину последовательности до 8 М последовательностей и 8 192 лексем, соответственно. После предварительного обучения 2,87 Т лексем мы снова удваиваем размер партии до 16 М. Мы обнаружили, что Этот метод обучения очень стабилен: происходит очень мало скачков потерь, и не требуется вмешательства для исправления отклонений в обучении модели.
Корректировка комбинаций данных. В процессе обучения мы внесли несколько корректировок в набор данных для предварительного обучения, чтобы улучшить работу модели в конкретных задачах. В частности, мы увеличили долю неанглийских данных во время предварительного обучения, чтобы улучшить многоязычную производительность Llama 3. Мы также увеличили долю математических данных, чтобы улучшить математические рассуждения модели, добавили более свежие сетевые данные на поздних этапах предварительного обучения, чтобы обновить срезы знаний модели, и уменьшили долю подмножества данных, которые впоследствии были признаны менее качественными.
3.4.2 Предварительное обучение с длинным контекстом
На последнем этапе предварительного обучения мы тренируем длинные последовательности для поддержки контекстных окон объемом до 128 000 лексем. Мы не обучаем длинные последовательности раньше, потому что вычисления в слое самовнимания растут квадратично с длиной последовательности. Мы постепенно увеличиваем длину поддерживаемого контекста и проводим предварительное обучение после того, как модель успешно адаптируется к увеличению длины контекста. Мы оцениваем успешность адаптации, измеряя оба показателя:
(1) Полностью ли восстановлена производительность модели при оценке короткого контекста;
(2) Может ли модель идеально решить задачу "иголка в стоге сена" до такой длины. В предварительном обучении Llama 3 405B мы постепенно увеличивали длину контекста в шесть этапов, начиная с начального контекстного окна в 8 000 лексем и заканчивая контекстным окном в 128 000 лексем. На этом этапе предварительного обучения с длинным контекстом было использовано около 800 миллиардов обучающих лексем.

3.4.3 Отжиг
Во время предварительного обучения на последних 40 млн лексем мы линейно отжигали скорость обучения до 0, сохраняя длину контекста в 128 тыс. лексем. На этом этапе отжига мы также скорректировали набор данных, чтобы увеличить объем выборки очень качественных источников данных; см. раздел 3.1.3. Наконец, мы вычислили среднее значение контрольных точек модели (среднее значение Поляка (1991)) во время отжига, чтобы получить окончательную предварительно обученную модель.
4 Последующее обучение
Мы создали и выровняли модели Llama 3, применив несколько раундов последующего обучения. Эти последующие тренировки основаны на предварительно обученных контрольных точках и включают в себя обратную связь с человеком для выравнивания моделей (Ouyang et al., 2022; Rafailov et al., 2024). Каждый раунд последующего обучения состоял из контролируемой тонкой настройки (SFT), а затем прямой оптимизации предпочтений (DPO; Rafailov et al., 2024) на примерах, созданных с помощью ручного аннотирования или синтеза. В разделах 4.1 и 4.2 мы описываем последующее моделирование обучения и методы работы с данными, соответственно. Кроме того, в разделе 4.3 мы подробно рассказываем о стратегиях сбора данных, разработанных на заказ, чтобы улучшить модель с точки зрения умозаключений, возможностей программирования, факторизации, многоязыковой поддержки, использования инструментов, длительных контекстов и точного следования инструкциям.
4.1 Моделирование
В основе нашей стратегии посттренингового обучения лежат модель вознаграждения и языковая модель. Сначала мы обучаем модель вознаграждения поверх контрольных точек предварительного обучения, используя данные о предпочтениях, помеченные человеком (см. раздел 4.1.2). Затем мы точно настраиваем контрольные точки предварительного обучения с помощью контролируемой точной настройки (SFT; см. раздел 4.1.3) и далее согласовываем их с контрольными точками с помощью прямой оптимизации предпочтений (DPO; см. раздел 4.1.4). Этот процесс показан на рисунке 7. Если не указано иное, наш процесс моделирования применяется к Llama 3 405B, которую мы для простоты обозначаем как Llama 3 405B.
4.1.1 Формат диалога в чате
Чтобы адаптировать большую языковую модель (LLM) для взаимодействия человека и компьютера, нам необходимо определить протокол чат-диалога, который позволит модели понимать команды человека и выполнять диалоговые задачи. По сравнению со своей предшественницей, Llama 3 имеет новые возможности, такие как использование инструментов (раздел 4.3.5), что может потребовать создания нескольких сообщений в одном раунде диалога и отправки их в разные места (например, пользователю, ipython). Чтобы поддержать это, мы разработали новый протокол чата с несколькими сообщениями, который использует различные специальные маркеры заголовка и завершения. Заголовочные маркеры используются для указания источника и адресата каждого сообщения в диалоге. Аналогично, маркеры завершения указывают, когда наступает очередь человека и ИИ заканчивать разговор.
4.1.2 Моделирование вознаграждения
Мы обучили модель вознаграждения (RM), охватывающую различные способности, и построили ее поверх предварительно обученных контрольных точек. Цель обучения та же, что и в Llama 2, но мы удалили маргинальный член в функции потерь, поскольку наблюдаем снижение улучшения при увеличении объема данных. Как и в Llama 2, мы используем все данные о предпочтениях для моделирования вознаграждения после отсеивания образцов с похожими ответами.
В дополнение к стандартным парам предпочтений (выбранный, отклоненный) аннотация создает третий "отредактированный ответ" для некоторых подсказок, где ответ, выбранный из пары, дополнительно редактируется для улучшения (см. раздел 4.2.1). Таким образом, в каждом образце сортировки предпочтений есть два или три ответа, которые четко ранжированы (отредактированные > выбранные > отвергнутые). Во время обучения мы объединили сигналы и несколько ответов в одну строку и рандомизировали ответы. Это приближение к стандартному сценарию вычисления оценок путем размещения ответов в отдельных строках, но в наших экспериментах с абляцией этот подход повышает эффективность обучения без потери точности.
4.1.3 Тонкая настройка надзора
Помеченные человеком сигналы сначала отбраковываются для выборки с помощью модели вознаграждения, подробная методология которой описана в разделе 4.2. Мы объединяем эти данные с другими источниками данных (включая синтетические данные) для точной настройки предварительно обученной языковой модели с помощью стандартных потерь перекрестной энтропии с целью предсказания целевой разметки (при этом маскируя потери от разметки с подсказками). Более подробно о смешивании данных см. в разделе 4.2. Хотя многие обучающие цели генерируются моделью, мы называем этот этап контролируемой тонкой настройкой (SFT; Wei et al. 2022a; Sanh et al. 2022; Wang et al. 2022b).
Наша максимальная модель настраивается со скоростью обучения 1e-5 за 8,5-9 тысяч шагов. Мы обнаружили, что эти настройки гиперпараметров подходят для различных раундов и набора данных.
4.1.4 Прямая оптимизация предпочтений
Далее мы обучили наши SFT-модели для выравнивания предпочтений человека с помощью прямой оптимизации предпочтений (DPO; Rafailov et al., 2024). При обучении мы в основном использовали последние партии данных о предпочтениях, собранные из моделей, показавших наилучшие результаты в предыдущем раунде выравнивания. В результате наши обучающие данные лучше соответствуют распределению оптимизированных стратегических моделей в каждом раунде. Мы также изучали алгоритмы стратегий, такие как PPO (Schulman et al., 2017), но обнаружили, что DPO требует меньше вычислений и лучше работает с крупномасштабными моделями, особенно в бенчмарках на соблюдение инструкций, таких как IFEval (Zhou et al., 2023).
Для Llama 3 мы использовали скорость обучения 1e-5 и установили гиперпараметр β равным 0,1. Кроме того, мы применили следующие алгоритмические модификации DPO:
- Маскировка маркеров форматирования в потерях DPO. Мы маскируем маркеры специального формата (включая маркеры заголовка и окончания, описанные в разделе 4.1.1) из отобранных и отклоненных ответов, чтобы стабилизировать обучение DPO. Мы отмечаем, что вовлечение этих маркеров в потерю может привести к нежелательному поведению модели, такому как дублирование хвоста или внезапная генерация маркеров завершения. Мы предполагаем, что это связано с контрастной природой потери DPO - присутствие общих маркеров как в выбранных, так и в отклоненных ответах может привести к противоречивым целям обучения, поскольку модель должна одновременно увеличивать и уменьшать вероятность появления этих маркеров.
- Регуляризация с использованием потерь в NLL: Мы добавили дополнительный член потери отрицательного логарифмического правдоподобия (NLL) к отобранным последовательностям с коэффициентом масштабирования 0,2, аналогично Pang et al. (2024). Это помогает дополнительно стабилизировать обучение DPO, поддерживая формат, необходимый для генерации, и предотвращая уменьшение логарифмического правдоподобия выбранных ответов (Pang et al., 2024; Pal et al., 2024).
4.1.5 Усреднение модели
Наконец, мы усреднили модели, полученные в экспериментах с использованием различных версий данных или гиперпараметров на каждом этапе RM, SFT или DPO (Izmailov et al. 2019; Wortsman et al. 2022; Li et al. 2022). Мы представляем статистическую информацию о собранных внутри компании данных о предпочтениях людей, использованных для кондиционирования Llama 3. Мы попросили участников оценки провести несколько раундов диалога с моделью и сравнили ответы в каждом раунде. В процессе постобработки мы разделили каждый диалог на несколько примеров, каждый из которых содержал подсказку (включая предыдущий диалог, если он был доступен) и ответ (например, ответ, который был выбран или отклонен).

4.1.6 Итерационные раунды
После Llama 2 мы применили описанную выше методику в течение шести раундов итераций. В каждом раунде мы собирали новые данные о маркировке и точной настройке предпочтений (SFT) и делали выборку синтетических данных из последней модели.
4.2 Данные после обучения
Состав посттренировочных данных играет решающую роль в полезности и поведении языковой модели. В этом разделе мы рассмотрим процедуру аннотирования и сбора данных о предпочтениях (раздел 4.2.1), состав данных SFT (раздел 4.2.2), а также методы контроля качества и очистки данных (раздел 4.2.3).
4.2.1 Предпочтения
Наш процесс маркировки данных предпочтений аналогичен Llama 2. После каждого раунда мы развертываем несколько моделей для аннотации и выбираем два ответа из разных моделей для каждой подсказки пользователя. Эти модели могут быть обучены с использованием различных схем смешивания и выравнивания данных, что позволяет получить различные возможности (например, опыт работы с кодом) и увеличить разнообразие данных. Мы попросили аннотаторов распределить оценки предпочтений по одному из четырех уровней в зависимости от степени предпочтения: значительно лучше, лучше, немного лучше или незначительно лучше.
Мы также включили этап редактирования после упорядочивания предпочтений, чтобы поощрить аннотатора к дальнейшему уточнению предпочтительного ответа. Аннотатор может либо редактировать выбранный ответ напрямую, либо использовать модель обратной связи для уточнения своего собственного ответа. В результате некоторые данные о предпочтениях содержат три отсортированных ответа (Edit > Select > Reject).
Статистика аннотаций предпочтений, которую мы использовали для обучения Llama 3, представлена в таблице 6. Общий английский включает в себя несколько подкатегорий, таких как вопросы и ответы, основанные на знаниях, или точное следование инструкциям, которые выходят за рамки конкретных способностей. По сравнению с Llama 2 мы наблюдали увеличение средней длины подсказок и ответов, что говорит о том, что мы обучаем Llama 3 более сложным задачам. Кроме того, мы внедрили процессы анализа качества и ручной оценки для тщательной оценки собранных данных, что позволило нам доработать подсказки и обеспечить систематическую, действенную обратную связь с аннотаторами. Например, по мере совершенствования Llama 3 в каждом раунде мы будем соответственно увеличивать сложность подсказок, чтобы направить их на те области, в которых модель отстает.
В каждом позднем раунде обучения мы используем все доступные на тот момент данные о предпочтениях для моделирования вознаграждения и только самые последние партии из каждой возможности для обучения DPO. Как для моделирования вознаграждения, так и для DPO мы тренируемся на образцах, помеченных как "реакция на выборку значительно лучше или лучше", и отбрасываем образцы с похожими реакциями.
4.2.2 Данные SFT
Данные для тонкой настройки мы получаем в основном из следующих источников:
- Подсказки из нашей коллекции, аннотированной вручную, и их отказ от выборочных ответов
- Синтетические данные для конкретных возможностей (подробнее см. раздел 4.3)
- Небольшое количество данных, помеченных вручную (подробнее см. раздел 4.3)
По мере продвижения по циклу посттренировочного обучения мы разрабатывали более мощные варианты Llama 3 и использовали их для сбора больших наборов данных, чтобы охватить широкий спектр сложных возможностей. В этом разделе мы обсудим детали процесса выборки отбраковки и общий состав конечной смеси данных SFT.
Отказ от пробы.При выборке отклонений (RS) для каждой подсказки, которую мы собираем во время ручного аннотирования (раздел 4.2.1), мы выбираем K результатов из самой последней стратегии моделирования чата (обычно это контрольные точки лучшего выполнения из предыдущей итерации посттренинга или контрольные точки лучшего выполнения для определенной компетенции) и используем нашу модель вознаграждения для выбора лучшего кандидата, в соответствии с Bai et al. (2022). На более поздних этапах посттренинга мы вводим системные подсказки, чтобы направить ответы УС в соответствии с желаемым тоном, стилем или форматом, которые могут отличаться для разных способностей.
Для повышения эффективности выборки отбраковки мы используем PagedAttention (Kwon et al., 2023). PagedAttention повышает эффективность использования памяти за счет динамического распределения кэша ключей-значений. Он поддерживает произвольную длину вывода, динамически планируя запросы на основе текущего объема кэша. К сожалению, при этом возникает риск свопинга, когда память заканчивается. Чтобы устранить этот риск, мы определяем максимальную длину вывода и выполняем запросы только в том случае, если памяти достаточно для хранения выводов такой длины. pagedAttention также позволяет нам совместно использовать страницу кэша подсказанных ключевых значений для всех соответствующих выводов. В целом это привело к более чем 2-кратному увеличению пропускной способности во время выборки отказов.
Состав агрегированных данных.В таблице 7 приведены статистические данные по каждой из широких категорий данных в нашей подборке "полезности". Хотя данные SFT и данные о предпочтениях содержат пересекающиеся области, они курируются по-разному, что приводит к разной статистике подсчета. В разделе 4.2.3 мы описываем методы, используемые для классификации тематики, сложности и качества наших образцов данных. В каждом раунде посттренинга мы тщательно настраиваем общий набор данных, чтобы скорректировать производительность по нескольким осям для широкого спектра контрольных показателей. Наша окончательная смесь данных будет многократно итерироваться для одних высококачественных источников и уменьшать выборку для других.

4.2.3 Обработка данных и контроль качества
Учитывая, что большинство наших учебных данных генерируются моделью, требуется тщательная очистка и контроль качества.
Очистка данных: На ранних этапах работы мы заметили в данных множество нежелательных закономерностей, таких как чрезмерное использование смайликов или восклицательных знаков. Поэтому мы применили ряд стратегий удаления и модификации данных на основе правил, чтобы отфильтровать или удалить проблемные данные. Например, чтобы уменьшить проблему чрезмерной апологетической интонации, мы выявляли слишком часто используемые фразы (например, "мне жаль" или "я извиняюсь") и тщательно выравнивали долю таких образцов в наборе данных.
Обрезка данных: Мы также применяем ряд методов, основанных на моделировании, для удаления некачественных обучающих образцов и повышения общей производительности модели:
- Классификация предметов: Сначала мы настроили Llama 3 8B на тематический классификатор и проанализировали все данные, чтобы разделить их на грубые категории ("Математические рассуждения") и тонкие категории ("Геометрия и тригонометрия").
- Оценка качества: Мы использовали модель вознаграждения и сигналы на основе Llama для получения оценок качества для каждого образца. Для оценки на основе RM мы считали данные с оценками в самом высоком квартиле высококачественными. Для оценки по шкале Llama мы использовали контрольные точки Llama 3, чтобы оценить данные по общему английскому языку на трех уровнях (точность, соблюдение инструкции и тон/презентация) и данные по коду на двух уровнях (распознавание ошибок и намерения пользователя), и считали образцы, получившие наибольшее количество баллов, высококачественными данными. Оценки на основе RM и Llama имеют высокие показатели конфликтности, и мы обнаружили, что сочетание этих сигналов привело к наилучшему отзыву для внутреннего тестового набора. В конечном итоге мы выбираем те примеры, которые были признаны высококачественными фильтрами на основе RM или Llama.
- Рейтинг сложности: Поскольку мы также были заинтересованы в приоритетном выделении более сложных примеров моделей, мы оценивали данные с помощью двух метрик сложности: Instag (Lu et al., 2023) и оценки на основе Llama. Для Instag мы попросили Llama 3 70B выполнить маркировку намерений по сигналам SFT, где большее количество намерений подразумевает более высокую сложность. Мы также попросили ламу 3 измерить сложность диалога на трех уровнях (Liu et al., 2024c).
- Семантический деэмфазис: Наконец, мы выполняем семантическое дедублирование (Abbas et al., 2023; Liu et al., 2024c). Сначала мы кластеризуем полные диалоги с помощью RoBERTa (Liu et al., 2019b) и сортируем их по показателю качества × показателю сложности в каждом кластере. Затем мы проводим жадный отбор, перебирая все отсортированные примеры и сохраняя только те, чье максимальное косинусное сходство с примерами, видимыми в кластерах до сих пор, меньше порогового значения.
4.3 Мощность
В частности, мы подчеркиваем некоторые усилия, предпринятые для развития конкретных компетенций, таких как работа с кодом (раздел 4.3.1), многоязычие (раздел 4.3.2), математические навыки и умение рассуждать (раздел 4.3.3), длительная контекстуализация (раздел 4.3.4), использование инструментов (раздел 4.3.5), фактологичность (раздел 4.3.6) и управляемость (раздел 4.3.7).
4.3.1 Код
с (какого-то времени) Второй пилот и Codex (Chen et al., 2021) были выпущены, LLM для кода привлекли большое внимание. Разработчики теперь широко используют эти модели для генерации фрагментов кода, отладки, автоматизации задач и улучшения качества кода. Наша цель для Llama 3 - улучшить и оценить возможности генерации, документирования, отладки и рецензирования кода для следующих приоритетных языков программирования: Python, Java, JavaScript, C/C++, TypeScript, Rust, PHP, HTML/CSS, SQL и bash/shell.Здесь мы представляем результаты, полученные в результате Мы представляем результаты, полученные при обучении экспертов по коду, генерировании синтетических данных для SFT, переходе к улучшенным форматам с помощью системных подсказок и создании фильтров качества для удаления плохих образцов из обучающих данных для улучшения этих возможностей кодирования.
Специализированная подготовка.Мы обучили эксперта по коду и использовали его в последующих многократных раундах посттренинга для сбора высококачественных аннотаций человеческого кода. Это было достигнуто путем ответвления от основного цикла предварительного обучения и продолжения предварительного обучения на смеси из 1 Т лексем, которые в основном (>85%) были данными о коде. Продолжение предварительного обучения на данных, специфичных для конкретной области, показало свою эффективность в улучшении производительности в конкретных областях (Gururangan et al., 2020). Мы следуем рецепту, схожему с CodeLlama (Rozière et al., 2023). На последних нескольких тысячах шагов обучения мы выполняем точную настройку длинного контекста (LCFT) на высококачественной смеси кодовых данных уровня репозитория, увеличивая длину контекста эксперта до 16 тыс. лексем. Наконец, мы следуем аналогичному рецепту моделирования после обучения, описанному в разделе 4.1, чтобы выровнять модель, но используя смесь данных SFT и DPO, которые в основном специфичны для кода. Модель также используется для отбраковки кодовых подсказок (раздел 4.2.2).
Генерация синтетических данных.В процессе разработки мы выявили основные проблемы, связанные с генерацией кода, в том числе трудности с выполнением инструкций, ошибки в синтаксисе кода, неправильная генерация кода и трудности с исправлением ошибок. В то время как плотные человеческие аннотации теоретически могли бы решить эти проблемы, синтетическая генерация данных предлагает дополнительный подход, который дешевле, лучше масштабируется и не ограничен уровнем знаний аннотаторов.
Поэтому мы использовали Llama 3 и Code Expert для генерации большого количества синтетических диалогов SFT. Мы описали три высокоуровневых метода генерации синтетических кодовых данных. В целом мы использовали более 2,7 миллиона синтетических примеров во время SFT.
1. Генерация синтетических данных: реализация обратной связи.Модели 8B и 70B демонстрируют значительный прирост производительности на обучающих данных, сгенерированных более крупными и компетентными моделями. Однако наши предварительные эксперименты показывают, что обучение только Llama 3 405B на собственных сгенерированных данных не помогает (или даже ухудшает производительность). Чтобы устранить это ограничение, мы вводим обратную связь по выполнению как источник истины, который позволяет модели учиться на своих ошибках и не сбиваться с пути. В частности, мы генерируем набор данных из примерно одного миллиона синтетических диалогов с кодом, используя следующую процедуру:
- Создание описания проблемы:Во-первых, мы сгенерировали большой набор описаний задач по программированию, охватывающих самые разные темы (включая длиннохвостые распределения). Чтобы добиться такого разнообразия, мы произвольно выбирали фрагменты кода из различных источников и предлагали модели генерировать проблемы программирования на основе этих примеров. Это позволило нам использовать широкий спектр тем и создать всеобъемлющий набор описаний задач (Wei et al., 2024).
- Генерация решений:Затем мы предложили Llama 3 решить каждую задачу на заданном языке программирования. Мы заметили, что добавление хороших правил программирования к подсказкам повысило качество генерируемых решений. Кроме того, мы обнаружили, что полезно попросить модель объяснить свой мыслительный процесс с помощью аннотаций.
- Анализ корректности: После генерации решений важно понимать, что их корректность не гарантирована и что включение неправильных решений в набор данных для тонкой настройки может снизить качество модели. Хотя мы не можем гарантировать полную корректность, мы разработали методы приближенного определения корректности. Для этого мы извлекаем исходный код из сгенерированных решений и применяем комбинацию методов статического и динамического анализа для проверки их корректности, включая:
- Статический анализ: Мы прогоняем весь сгенерированный код через парсер и инструменты проверки кода для обеспечения синтаксической корректности, выявляя синтаксические ошибки, использование неинициализированных переменных или неимпортированных функций, проблемы со стилем кода, ошибки типов и т. д.
- Генерация и выполнение модульных тестов: Для каждой проблемы и решения мы побуждаем модель генерировать модульные тесты и выполняем их вместе с решением в контейнерном окружении, отлавливая ошибки выполнения и некоторые семантические ошибки.
- Обратная связь по ошибкам и итеративная самокоррекция: Если решение не работает на каком-либо шаге, мы предлагаем модели изменить его. Подсказка содержит исходное описание проблемы, неверное решение и обратную связь от парсера/инструмента проверки кода/тестовой программы (стандартный вывод, стандартная ошибка и код возврата). После неудачного выполнения модульного теста модель может либо исправить код, чтобы он прошел существующие тесты, либо изменить свои модульные тесты, чтобы они соответствовали сгенерированному коду. Только диалоги, прошедшие все проверки, включаются в итоговый набор данных для тонкой настройки под наблюдением (SFT). Примечательно, что примерно 20% решений изначально были неверными, но самоисправлялись, что говорит о том, что модель училась на обратной связи и улучшала свою производительность.
- Тонкая настройка и итеративное совершенствование: Процесс тонкой настройки происходит в несколько раундов, причем каждый раунд основывается на предыдущем. После каждого раунда тонкой настройки модель улучшается, чтобы генерировать синтетические данные более высокого качества для следующего раунда. Этот итерационный процесс позволяет постепенно уточнять и повышать производительность модели.
2. Генерация синтетических данных: перевод на язык программирования. Мы наблюдаем разрыв в производительности между основными языками программирования (например, Python/C++) и менее распространенными языками программирования (например, Typescript/PHP). Это неудивительно, поскольку у нас меньше обучающих данных для менее распространенных языков программирования. Чтобы смягчить эту проблему, мы дополним имеющиеся данные переводом данных с распространенных языков программирования на менее распространенные языки (по аналогии с Chen et al. (2023) в области вывода). Это достигается за счет подсказок Llama 3 и обеспечения качества путем синтаксического разбора, компиляции и выполнения. На рисунке 8 показан пример синтетического PHP-кода, переведенного с Python. Это значительно улучшает производительность менее распространенных языков, измеряемую эталоном MultiPL-E (Cassano et al., 2023).
3. создание синтетических данных: обратный перевод. Для улучшения некоторых возможностей кодирования (например, документирования, интерпретации), когда количество информации из обратной связи при выполнении недостаточно для определения качества, мы используем другой многоступенчатый подход. Используя этот процесс, мы создали около 1,2 миллиона синтетических диалогов, связанных с интерпретацией, генерацией, документированием и отладкой кода. Начнем с фрагментов кода на разных языках из данных предварительного обучения:


- Сгенерировать: Мы попросили Llama 3 сгенерировать данные, представляющие целевые возможности (например, добавить комментарии и строки документации к фрагменту кода или попросить модель интерпретировать фрагмент кода).
- Обратный перевод. Мы просим модель "перевести" синтетически сгенерированные данные обратно в оригинальный код (например, мы просим модель генерировать код только из документов или просим модель генерировать код только из объяснений).
- Фильтрация. Используя оригинальный код в качестве эталона, мы просим Llama 3 определить качество результата (например, мы спрашиваем модель, насколько точно переведенный код соответствует оригинальному). Затем мы используем сгенерированный пример с наивысшим баллом самооценки в SFT.
Системное руководство по отбраковке образцов. Во время выборки отбраковки мы используем специфические для кода системные подсказки, чтобы улучшить читабельность, документированность, полноту и конкретность кода. Вспомните из раздела 7, что эти данные используются для точной настройки языковой модели. На рисунке 9 показан пример того, как системные подсказки могут помочь улучшить качество сгенерированного кода - добавляются необходимые комментарии, используются более информативные имена переменных, экономится память и т. д.
Фильтрация обучающих данных с использованием исполнения и модели в качестве рубрикатора. Как описано в разделе 4.2.3, мы иногда сталкивались с проблемами качества в отклоненных выборочных данных, такими как включение ошибочных блоков кода. Обнаружить эти проблемы в данных выборки отказов не так просто, как в данных синтетического кода, поскольку ответы выборки отказов часто содержат смесь естественного языка и кода, который не всегда может быть исполняемым. (Например, пользовательские подсказки могут явно просить предоставить псевдокод или отредактировать только очень маленькие фрагменты исполняемого кода). Для решения этой проблемы мы используем подход "модель как судья", при котором ранние версии Llama 3 оцениваются и получают двоичную оценку (0/1) по двум критериям: корректность кода и стиль кода. Только образцы с идеальной оценкой 2 были сохранены. Изначально такая строгая фильтрация привела к снижению производительности бенчмарка, в основном потому, что он непропорционально удалял примеры со сложными подсказками. Чтобы противостоять этому, мы стратегически изменили некоторые ответы, отнесенные к категории наиболее сложных закодированных данных, пока они не стали соответствовать критериям "модель как судья", основанным на Llama. Улучшение этих сложных вопросов позволило сбалансировать качество и сложность закодированных данных для достижения оптимальной производительности.
4.3.2 Многоязычие
В этом разделе описывается, как мы улучшили многоязычные возможности Llama 3, включая: обучение экспертной модели, специализирующейся на большем количестве многоязычных данных; поиск и создание высококачественных данных с точной настройкой многоязычных команд для немецкого, французского, итальянского, португальского, хинди, испанского и тайского языков; решение специфических проблем многоязычной языковой загрузки для улучшения общей производительности нашей модели.
Специализированная подготовка.Наш набор данных для предварительного обучения Llama 3 содержит гораздо больше английских лексем, чем неанглийских. Чтобы собрать более качественные неанглийские человеческие аннотации, мы обучаем многоязычную экспертную модель, разветвляя прогоны предварительного обучения и продолжая предварительное обучение на смеси данных, содержащей 90% многоязычных лексем. Затем мы проводим посттренинг этой экспертной модели, как описано в разделе 4.1. Эта экспертная модель затем используется для сбора более качественных неанглийских аннотаций, пока предварительное обучение не будет полностью завершено.
Многоязычный сбор данных.Наши многоязычные данные SFT в основном получены из следующих источников. Общее распределение составляет 2,41 ТП3Т человеческих аннотаций, 44,21 ТП3Т данных из других задач НЛП, 18,81 ТП3Т данных выборки отказов и 34,61 ТП3Т данных переводческих заключений.
- Ручная аннотация:Мы собираем высококачественные, вручную аннотированные данные от лингвистов и носителей языка. Эти аннотации состоят в основном из открытых подсказок, которые представляют реальные случаи использования.
- Данные из других задач НЛП:Для дальнейшего совершенствования мы используем многоязычные обучающие данные из других задач и переписываем их в формат диалога. Например, мы используем данные из exams-qa (Hardalov et al., 2020) и Conic10k (Wu et al., 2023). Для улучшения языкового соответствия мы также используем параллельные тексты из GlobalVoices (Prokopidis et al., 2016) и Wikimedia (Tiedemann, 2012). Для удаления некачественных данных мы использовали фильтрацию на основе LID и Blaser 2.0 (Seamless Communication et al., 2023). Для параллельных текстовых данных вместо прямого использования битекстовых пар мы применили многоязычный шаблон, созданный по мотивам Wei et al. (2022a), чтобы лучше имитировать реальные диалоги в сценариях перевода и изучения языка.
- Отклоните данные выборки:Мы применили выборку отклонений к аннотированным человеком подсказкам, чтобы получить высококачественные образцы для точной настройки, с небольшими изменениями по сравнению с процессом для английских данных:
- Генерация: мы исследовали случайный выбор гиперпараметров температуры в диапазоне 0,2 -1 в ранних раундах посттренинга, чтобы разнообразить генерацию. При использовании высоких температур ответы на многоязычные сигналы могут стать творческими и вдохновляющими, но также могут быть склонны к ненужному или неестественному переключению кода. На последних этапах посттренинга мы использовали постоянное значение 0,6, чтобы сбалансировать этот компромисс. Кроме того, мы использовали специализированные системные подсказки для улучшения форматирования, структуры и общей читабельности ответов.
- Отбор: перед отбором на основе модели вознаграждения мы провели многоязычные проверки, чтобы обеспечить высокий процент языковых совпадений между подсказками и ответами (например, не следует ожидать, что на латинизированные подсказки на хинди будут отвечать, используя санскритские письмена хинди).
- Данные перевода:Мы старались не использовать данные машинного перевода для точной настройки модели, чтобы предотвратить появление переводного английского (Bizzoni et al., 2020; Muennighoff et al., 2023) или возможное предубеждение в отношении имен (Wang et al., 2022a), гендерное предубеждение (Savoldi et al., 2021) или культурное предубеждение (Ji et al., 2023). . Кроме того, мы стремились к тому, чтобы модель не подвергалась только заданиям, основанным на англоязычных культурных контекстах, которые могут не отражать языковое и культурное разнообразие, которое мы стремились охватить. Мы сделали исключение и перевели синтезированные данные количественных рассуждений (см. раздел 4.3.3 для получения дополнительной информации) на неанглийский язык, чтобы улучшить показатели количественных рассуждений на неанглийских языках. Благодаря простоте языка этих математических задач, переведенные образцы не вызвали особых проблем с качеством. Мы заметили значительный выигрыш от добавления этих переведенных данных в MGSM (Shi et al., 2022).
4.3.3 Математика и рассуждения
Мы определяем мышление как способность выполнять многоэтапные вычисления и приходить к правильному окончательному ответу.
В основу нашего подхода к обучению моделей, обладающих способностью к математическому мышлению, легли несколько задач:
- Отсутствие подсказок. По мере увеличения сложности задач количество подходящих подсказок или проблем для контролируемой тонкой настройки (SFT) уменьшается. Такое ограничение затрудняет создание разнообразных и репрезентативных обучающих наборов данных для обучения моделей различным математическим навыкам (Yu et al. 2023; Yue et al. 2023; Luo et al. 2023; Mitra et al. 2024; Shao et al. 2024; Yue et al. 2024b).
- Отсутствие реальных процессов рассуждения. Эффективное рассуждение требует пошаговых решений для облегчения процесса рассуждения (Wei et al., 2022c). Однако часто не хватает реалистичных процессов рассуждения, которые необходимы для того, чтобы подсказать модели, как постепенно разложить проблему и прийти к окончательному ответу (Zelikman et al., 2022).
- Неправильный промежуточный шаг. При использовании цепочек умозаключений, генерируемых моделью, промежуточные шаги не всегда могут быть правильными (Cobbe et al. 2021; Uesato et al. 2022; Lightman et al. 2023; Wang et al. 2023a). Эта неточность может привести к неправильным окончательным ответам, и с ней необходимо бороться.
- Обучение модели с помощью внешних инструментов. Способность расширять модели за счет использования внешних инструментов, таких как интерпретаторы кода, позволяет им рассуждать, переплетая код и текст (Gao et al. 2023; Chen et al. 2022; Gou et al. 2023). Эта способность может значительно улучшить их навыки решения проблем.
- Различия между обучением и рассуждениями: То, как модели настраиваются в процессе обучения, обычно отличается от того, как они используются в процессе рассуждений. Во время рассуждений модель, прошедшая тонкую настройку, может взаимодействовать с людьми или другими моделями и нуждаться в обратной связи для улучшения своих рассуждений. Обеспечение согласованности между обучением и реальными приложениями имеет решающее значение для поддержания эффективности умозаключений.
Для решения этих задач мы применяем следующую методологию:
- Решение проблемы отсутствия подсказок. Мы берем соответствующие данные предварительного обучения из математических контекстов и преобразуем их в формат "вопрос-ответ", который можно использовать для контролируемой тонкой настройки. Кроме того, мы определяем математические навыки, в которых модель плохо справляется, и активно собираем подсказки от людей, чтобы научить модель этим навыкам. Чтобы облегчить этот процесс, мы создали таксономию математических навыков (Didolkar et al., 2024) и попросили людей предоставить соответствующие подсказки/вопросы.
- Дополнение обучающих данных пошаговыми рассуждениями. Мы используем Llama 3 для генерации пошаговых решений для набора подсказок. Для каждой подсказки модель генерирует переменное количество результатов. Эти сгенерированные результаты затем фильтруются на основе правильных ответов (Li et al., 2024a). Мы также выполняем самопроверку, когда Llama 3 используется для проверки того, что конкретное пошаговое решение действительно для данной задачи. Этот процесс повышает качество тонкой настройки данных, устраняя случаи, когда модель не дает корректных траекторий вывода.
- Фильтрация ошибочных шагов рассуждения. Мы обучаем результаты и пошаговые модели вознаграждения (Lightman et al., 2023; Wang et al., 2023a) для фильтрации данных обучения с неправильными промежуточными шагами вывода. Эти модели вознаграждения используются для исключения данных с некорректными пошаговыми выводами, гарантируя, что тонкая настройка дает высококачественные данные. Для более сложных сигналов мы используем поиск по дереву Монте-Карло (MCTS) с выученными моделями пошагового вознаграждения для генерации корректных траекторий умозаключений, что еще больше повышает качество сбора данных умозаключений (Xie et al., 2024).
- Переплетающиеся коды и текстовые рассуждения. Мы предполагаем, что Llama 3 решает проблему умозаключений с помощью комбинации текстовых умозаключений и связанного с ними кода на языке Python (Gou et al., 2023). Выполнение кода используется в качестве сигнала обратной связи для исключения случаев, когда цепочка умозаключений не работает, и для обеспечения корректности процесса умозаключений.
- Учитесь на отзывах и ошибках. Чтобы имитировать обратную связь с человеком, мы используем неправильные результаты генерации (т. е. результаты генерации, которые приводят к неправильным траекториям вывода) и исправляем ошибки, побуждая Llama 3 генерировать правильные результаты генерации (An et al. 2023b; Welleck et al. 2022; Madaan et al. 2024a). Самостоятельный процесс использования обратной связи от неправильных попыток и их исправления помогает улучшить способность модели рассуждать точно и учиться на своих ошибках.
4.3.4 Длинные контексты
На заключительном этапе предварительного обучения мы увеличили длину контекста Llama 3 с 8 до 128 тыс. лексем (подробнее об этом см. в разделе 3.4). Как и при предварительном обучении, мы обнаружили, что во время тонкой настройки формулировку необходимо тщательно корректировать, чтобы сбалансировать возможности короткого и длинного контекста.
SFT и генерация синтетических данных. Простое применение нашего существующего рецепта SFT с использованием только данных с коротким контекстом привело к значительному снижению возможностей длинного контекста при предварительном обучении, что подчеркивает необходимость включения данных с длинным контекстом в портфель данных SFT. На практике, однако, нецелесообразно вручную маркировать большинство таких примеров, поскольку чтение длинных контекстов утомительно и требует много времени, поэтому мы в значительной степени полагаемся на синтетические данные, чтобы восполнить этот пробел. Мы использовали раннюю версию Llama 3 для создания синтетических данных, основанных на ключевых случаях использования длинных контекстов: (потенциально несколько раундов) вопросов и ответов, длинные резюме документов и рассуждения о кодовой базе, и более подробно описываем эти случаи использования ниже.
- ВОПРОСЫ И ОТВЕТЫ: Мы тщательно отобрали набор длинных документов из набора данных для предварительного обучения. Мы разделили эти документы на 8 тыс. помеченных фрагментов и попросили раннюю версию модели Llama 3 генерировать пары QA на случайно выбранных фрагментах. Весь документ используется в качестве контекста во время обучения.
- Тезисы: Мы применяем иерархическое обобщение документов с длинным контекстом, сначала используя нашу самую сильную модель контекста Llama 3 8K для иерархического обобщения блоков длиной 8K. Затем эти резюме объединяются. В процессе обучения мы предоставляем полный текст документа и просим модель обобщить его, сохранив все важные детали. Мы также генерируем пары QA на основе резюме документов и задаем модели вопросы, требующие глобального понимания всего длинного документа.
- Длинный контекстный код: Мы анализируем файлы Python, чтобы выявить операторы импорта и определить их зависимости. Отсюда мы выбираем наиболее часто используемые файлы, в частности те, на которые ссылается не менее пяти других файлов. Мы удаляем один из этих ключевых файлов из репозитория и просим модель определить зависимости от отсутствующих файлов и сгенерировать необходимый недостающий код.
Далее мы классифицируем синтезированные образцы по длине последовательности (16K, 32K, 64K и 128K) для более точной локализации длины входного сигнала.
В ходе тщательных экспериментов по абляции мы заметили, что смешивание синтетически сгенерированных данных длинного контекста 0,1% с оригинальными данными короткого контекста оптимизирует производительность эталонных тестов короткого и длинного контекста.
DPO. Мы отмечаем, что использование в DPO только короткоконтекстных обучающих данных не оказывает негативного влияния на производительность в длинноконтекстных задачах, если модель SFT хорошо работает в длинноконтекстных задачах. Мы подозреваем, что это связано с тем, что наша формулировка DPO содержит меньше шагов оптимизатора, чем SFT. Принимая во внимание этот вывод, мы сохраняем стандартную короткоконтекстную формулировку DPO поверх длинноконтекстных контрольных точек SFT.
4.3.5 Использование инструментов
Обучение больших языковых моделей (БЯМ) использованию таких инструментов, как поисковые системы или интерпретаторы кода, может значительно расширить спектр решаемых ими задач, превратив их из чисто болтливых моделей в более универсальных помощников (Nakano et al. 2021; Thoppilan et al. 2022; Parisi et al. 2022; Gao et al. 2023 2022; Parisi et al. 2022; Gao et al. 2023; Mialon et al. 2023a; Schick et al. 2024). Мы обучили Llama 3 взаимодействовать со следующими инструментами:
- Ллама 3 была обучена использовать Brave Search7 для ответов на вопросы о недавних событиях после истечения срока действия ее знаний или на запросы, требующие поиска конкретной информации в Интернете.
- Интерпретатор Python.Llama 3 генерирует и выполняет код для выполнения сложных вычислений, читает загруженные пользователем файлы и решает задачи на их основе, такие как викторины, сводки, анализ данных или визуализация.
- Математический вычислительный движок.Llama 3 может использовать Wolfram Alpha API8 для более точного решения математических и научных задач или для получения точной информации из баз данных Wolfram.
Созданная модель способна использовать эти инструменты в чате для решения пользовательских запросов, включая многораундовые диалоги. Если запрос требует нескольких вызовов инструментов, модель может написать пошаговые планы, которые вызывают инструменты последовательно и обосновывают их после каждого вызова.
Мы также улучшили возможности Llama 3 по использованию инструментов с нулевой выборкой - учитывая потенциально неизвестные определения инструментов и запросы пользователей в контекстной обстановке, мы обучаем модель генерировать правильные вызовы инструментов.
Реализация.Мы реализуем основные инструменты как объекты Python с различными методами. Инструменты нулевой выборки могут быть реализованы как функции Python с описанием и документацией (т. е. примерами их использования), и модели нужны только сигнатура функции и docstring в качестве контекста для генерации соответствующих вызовов.
Мы также конвертируем определения функций и вызовы в формат JSON, например, для вызовов Web API. Все вызовы инструментов выполняются интерпретатором Python, который должен быть включен в системной подсказке Llama 3. Основные инструменты могут быть включены или отключены отдельно из системного приглашения.
Сбор данных.В отличие от Schick et al. (2024), мы полагаемся на аннотации и предпочтения человека, чтобы научить Llama 3 использовать инструменты. Это отличается от конвейера пост-обучения, обычно используемого в Llama 3, двумя ключевыми моментами:
- Что касается инструментов, диалоги часто содержат более одного сообщения помощника (например, вызов инструмента и рассуждения о его результатах). Поэтому для сбора подробной обратной связи мы используем аннотацию на уровне сообщений: аннотатор отдает предпочтение двум сообщениям помощника в одном контексте или редактирует одно из них, если в обоих есть серьезные проблемы. Выбранное или измененное сообщение добавляется в контекст, и диалог продолжается. Это обеспечивает человеческую обратную связь о способности ассистента вызывать инструмент и рассуждать о его результатах. Аннотатор не может оценивать или редактировать результаты работы инструмента.
- Мы не проводили выборку отбраковки, так как в ходе бенчмаркинга инструментов не было замечено никакого выигрыша.
Чтобы ускорить процесс аннотирования, мы сначала загрузили базовые возможности использования инструмента путем точной настройки синтетических данных из предыдущих контрольных точек Llama 3. Таким образом, аннотатору потребуется выполнять меньше операций по редактированию. Аналогично, по мере совершенствования Llama 3 в процессе разработки мы постепенно усложняем протокол аннотирования: мы начинаем с одного раунда аннотирования использования инструментов, затем переходим к использованию инструментов в диалоге и, наконец, аннотируем многоэтапное использование инструментов и анализ данных.
Набор данных инструментов.Чтобы создать данные для использования в приложениях, использующих инструменты, мы выполнили следующие шаги.
- Одноэтапное использование инструмента. Сначала мы генерируем небольшое количество образцов для синтеза пользовательских подсказок, которые по своей конструкции требуют вызова одного из наших основных инструментов (например, вопрос, превышающий предел наших знаний). Затем, все еще полагаясь на небольшое количество генерации образцов, мы генерируем соответствующие вызовы инструментов для этих подсказок, выполняем их и добавляем выходные данные в контекст модели. Наконец, мы снова побуждаем модель сгенерировать окончательный ответ на запрос пользователя на основе результатов работы инструмента. В итоге мы получаем траектории следующего вида: подсказки системы, подсказки пользователя, вызовы инструментов, выходные данные инструментов и окончательные ответы. Мы также отфильтровали примерно 30% набора данных, чтобы удалить неиспользуемые вызовы инструментов или другие проблемы с форматированием.
- Использование многоступенчатых инструментов. Мы следуем аналогичному протоколу, сначала генерируя синтетические данные, чтобы научить модель основным возможностям использования инструментов 다단계. Для этого мы сначала просим Llama 3 сгенерировать подсказки, требующие как минимум двух вызовов инструментов (либо одного и того же инструмента, либо разных инструментов из нашего основного набора). Затем, основываясь на этих подсказках, мы выполняем небольшое количество примеров, чтобы побудить Llama 3 сгенерировать решение, состоящее из переплетенных шагов умозаключения и вызовов инструментов, аналогично ReAct (Yao et al., 2022). На рисунке 10 приведен пример выполнения ламой 3 задания, включающего многоэтапное использование инструментов.
- Загрузка файлов. Мы аннотируем следующие типы файлов: .txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml. Наши подсказки основаны на предоставленных файлах и просят кратко описать их содержимое, найти и исправить ошибки, оптимизировать фрагменты кода, провести анализ данных или визуализацию. На рисунке 11 показан пример выполнения Llama 3 задания, связанного с загрузкой файлов.

После тонкой настройки этих синтетических данных мы собрали человеческие аннотации из различных сценариев, включая несколько раундов взаимодействия, использование инструментов после трех шагов и ситуации, когда обращение к инструментам не давало удовлетворительных ответов. Мы дополнили синтетические данные различными системными подсказками, чтобы научить модель использовать инструменты только при их активации. Чтобы научить модель избегать вызовов инструментов для простых запросов, мы также добавили запросы и ответы на них из наборов данных "вопрос-ответ" (Berant et al. 2013; Koncel-Kedziorski et al. 2016; Joshi et al. 2017; Amini et al. 2019), в которых не использовался инструмент, но системные подсказки активировали инструмент. активировали инструмент.
Нулевая выборка данных об использовании инструментов. Мы улучшаем способность Llama 3 использовать инструменты с нулевой выборкой (также известные как вызовы функций) путем точной настройки большого и разнообразного набора частичных композиций (определений функций, пользовательских запросов, соответствующих вызовов). Мы оцениваем нашу модель на коллекции невидимых инструментов.
- Одиночные, вложенные и параллельные вызовы функций: Вызовы могут быть простыми, вложенными (т. е. мы передаем вызовы функций в качестве аргументов другой функции) или параллельными (т. е. модель возвращает список независимых вызовов функций). Генерирование разнообразных функций, запросов и реальных результатов может быть сложной задачей (Mekala et al., 2024), поэтому мы полагаемся на добычу стека (Kocetkov et al., 2022), чтобы основывать наши синтетические пользовательские запросы на реальных функциях. Точнее, мы извлекаем вызовы функций и их определения, очищаем и фильтруем их (например, отсутствующие строки документа или неисполняемые функции) и используем Llama 3 для создания запросов на естественном языке, соответствующих вызовам функций.
- Многораундовые вызовы функций: Мы также генерируем синтетические данные для многораундовых диалогов, содержащих вызовы функций, следуя протоколу, аналогичному представленному в работе Li et al. (2023b). Мы используем несколько агентов для генерации доменов, API, пользовательских запросов, вызовов API и ответов, обеспечивая при этом, чтобы генерируемые данные охватывали целый ряд различных доменов и реальных API. Все агенты являются вариантами Llama 3, настраиваются в зависимости от их обязанностей и сотрудничают пошагово.
4.3.6 Факты
Нереалистичность остается главной проблемой для больших языковых моделей. Модели склонны к излишней самоуверенности даже в тех областях, где им не хватает знаний. Несмотря на эти недостатки, их часто используют в качестве баз знаний, что может привести к таким опасным результатам, как распространение дезинформации. Хотя мы признаем, что правдивость превосходит иллюзии, мы используем подход, в котором иллюзии ставятся на первое место.
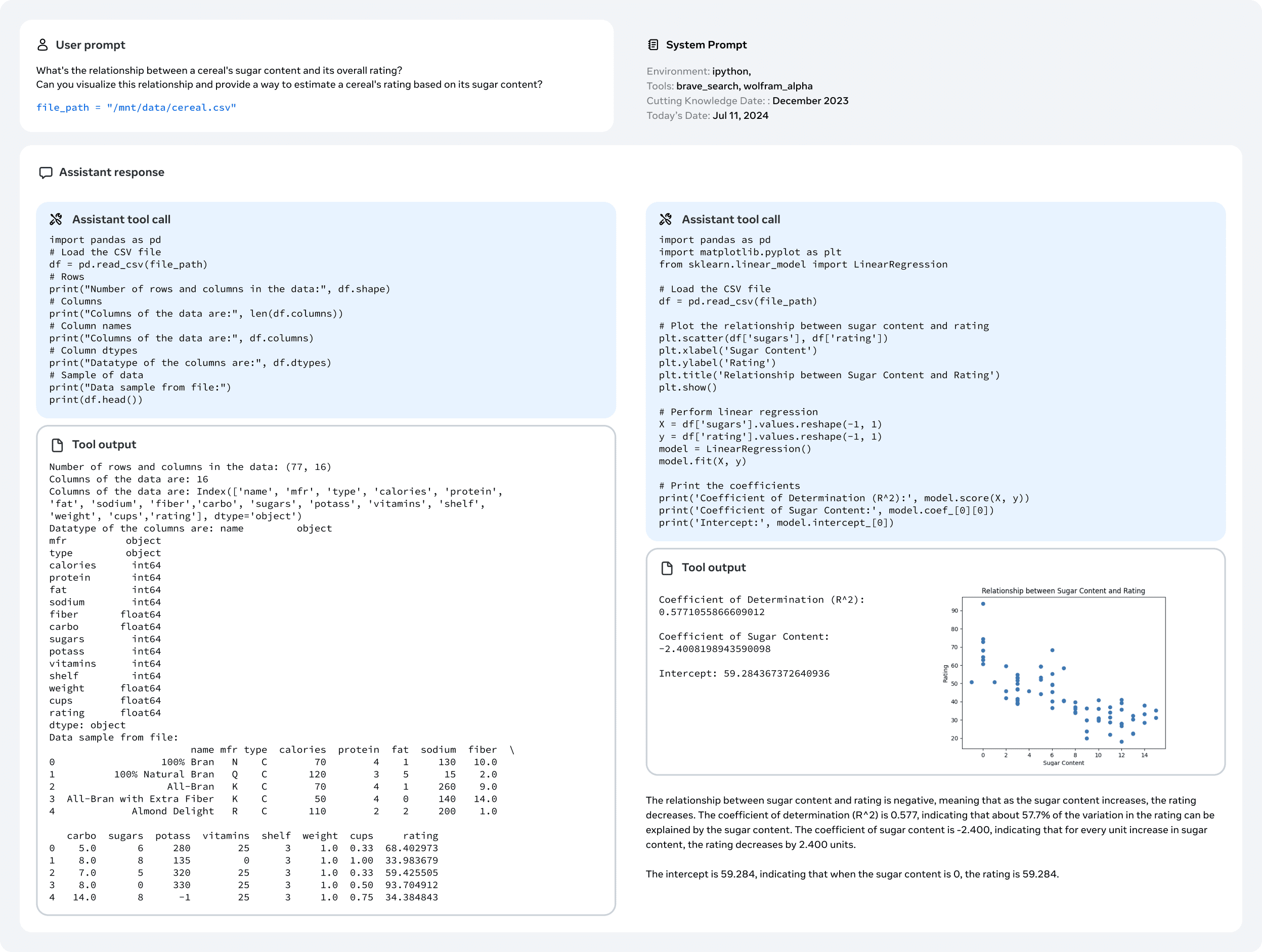
Рисунок 11 Обработка загруженного файла. Пример показывает, как Llama 3 анализирует и визуализирует загруженный файл.
Мы придерживаемся принципа, что посттренинговое обучение должно приводить модель в соответствие с "знанием того, что она знает", а не добавлять знания (Gekhman et al., 2024; Mielke et al., 2020). Наш основной подход заключается в генерировании данных, которые согласуют генерацию модели с подмножеством реальных данных, присутствующих в данных предварительного обучения. Для этого мы разработали технику обнаружения знаний, которая использует контекстные возможности Llama 3. Процесс генерации данных состоит из следующих этапов:
- Извлеките сегмент данных из данных предварительного обучения.
- Создайте фактические вопросы об этих сегментах (контекстах), подсказывая Лламе 3.
- Примерные ответы на этот вопрос от ламы 3.
- Оригинальный контекст использовался в качестве эталона, а Llama 3 - в качестве судьи для оценки правильности генерации.
- Используйте Llama 3 в качестве оценщика, чтобы оценить созданное богатство.
- Создайте причины отказа для ответов, которые постоянно информативны и неверны в нескольких поколениях, и используйте Llama 3
Мы используем данные, полученные в результате проверки знаний, чтобы побудить модель отвечать только на те вопросы, которые она знает, и отказываться от ответов на вопросы, в которых она не уверена. Кроме того, данные предварительного обучения не всегда являются фактологически последовательными или корректными. Поэтому мы также собрали ограниченный набор помеченных данных о правдивости, которые касались чувствительных тем, где было много фактических противоречивых или неправильных утверждений.
4.3.7 Управляемость
Управляемость - это возможность направлять поведение и результаты модели в соответствии с потребностями разработчиков и пользователей. Поскольку Llama 3 - это общая базовая модель, ее должно быть легко направить на различные последующие сценарии использования. Чтобы улучшить управляемость Llama 3, мы сосредоточились на повышении ее управляемости с помощью системных подсказок (с использованием команд на естественном языке), особенно в отношении длины ответа, форматирования, тона голоса и установки роли/персонажа.
Сбор данных. Мы собрали образцы предпочтений управляемости в категории "Общий английский", попросив аннотаторов разработать различные системные подсказки для Llama 3. Затем аннотатор вовлекал модель в диалог, чтобы оценить, способна ли модель последовательно следовать инструкциям, заданным в системных подсказках, на протяжении всего диалога. Ниже приведены примеры индивидуальных системных подсказок, использованных для улучшения управляемости:
"Вы - полезный и энергичный чатбот с искусственным интеллектом, который служит помощником в планировании питания для занятых семей. Питание в рабочий день должно быть быстрым и легким. Приоритетными продуктами на завтрак и обед должны быть хлопья, английские маффины с готовым беконом и другие быстрые и простые в приготовлении блюда. Эта семья очень занята. Обязательно спросите, есть ли у них под рукой предметы первой необходимости и любимые напитки, например кофе или энергетические напитки, чтобы не забыть их купить. Если это не особый случай, не забывайте экономить на бюджете".
Моделирование. После сбора данных о предпочтениях мы используем эти данные для моделирования вознаграждения, выборки отказов, SFT (непрерывная тонкая настройка) и DPO (оптимизация параметров на основе данных), чтобы улучшить управляемость Llama 3.
5 результатов
Мы провели обширную серию оценок Llama 3, изучая производительность (1) предварительно обученных языковых моделей, (2) пост-обученных языковых моделей и (3) функций безопасности Llama 3. Мы представляем результаты этих оценок в отдельных подразделах ниже.
5.1 Предварительное обучение языковых моделей
В этом разделе мы приводим результаты оценки предварительно обученной модели Llama 3 (часть III) и сравниваем их с другими моделями сопоставимого размера. Мы максимально воспроизводим результаты конкурирующих моделей. Для моделей, не относящихся к Llama, мы сообщим о лучших результатах в публично опубликованных результатах или (где это возможно) в результатах, которые мы воспроизводим сами. Конкретные детали этих оценок, включая конфигурации, такие как количество выстрелов, метрики и другие соответствующие гиперпараметры и настройки, доступны в нашем репозитории на Github: [вставить ссылку здесь]. Кроме того, мы также будем публиковать данные, полученные в рамках публичных бенчмаркинговых оценок, которые можно найти здесь: [вставить ссылку здесь].
Мы оценим качество модели в сравнении со стандартными эталонами (раздел V 5.1.1), проверим устойчивость к изменениям в настройках множественного выбора (раздел V 5.1.2) и проведем оценку состязательности (раздел V 5.1.3). Мы также проведем анализ загрязнения, чтобы оценить, насколько загрязнение обучающих данных влияет на нашу оценку (раздел V 5.1.4).
5.1.1 Стандартные контрольные показатели
Чтобы сравнить нашу модель с современными достижениями, мы оценили Llama 3 в большом количестве стандартных эталонных тестов, которые приведены ниже:
(1) здравый смысл; (2) знания; (3) понимание прочитанного; (4) математика, рассуждения и решение проблем; (5) длительный контекст; (6) код; (7) состязательная оценка; и (8) общая оценка.

Экспериментальная установка.Для каждого бенчмарка мы вычисляем оценки для Llama 3, а также оценки других предварительно обученных моделей сопоставимого размера. Там, где это возможно, мы пересчитываем данные других моделей с помощью нашего собственного конвейера. Чтобы обеспечить справедливое сравнение, мы выбираем наилучшую оценку между рассчитанными данными и цифрами, представленными моделью (с использованием тех же или более консервативных настроек). Более подробную информацию о наших настройках оценки можно найти здесь. Для некоторых моделей невозможно пересчитать эталонные значения, например, из-за неопубликованных предварительно обученных моделей или из-за того, что API не предоставляет доступ к лог-вероятностям. В частности, это относится ко всем моделям, сравнимым с Llama 3 405B. Поэтому мы не приводим средние значения по категориям для Llama 3 405B, так как для этого необходимо иметь все эталонные показатели.
Значение значимости.При подсчете баллов бенчмарков существует несколько источников отклонений, которые могут привести к неточным оценкам производительности модели, для измерения которой предназначен бенчмарк, например, небольшое количество демонстраций, случайные семена и размер партии. Это затрудняет понимание того, является ли одна модель статистически значимо лучше другой. Поэтому мы приводим оценки вместе с доверительными интервалами (ДИ) 95%, чтобы отразить дисперсию, вносимую выбором эталонных данных. Мы рассчитали доверительный интервал 95% аналитически по формуле (Madaan et al., 2024b):

CI_analytic(S) = 1,96 * sqrt(S * (1 - S) / N)
где S - предпочтительная оценка эталона, а N - размер выборки эталона. Отметим, что поскольку дисперсия данных эталона - не единственный источник дисперсии, эти КИ 95% являются нижними границами дисперсии фактической оценки мощности. Для показателей, которые не являются простыми средними значениями, КИ будут опущены.
Результаты, полученные на моделях Llama 3 8B и 70B.На рисунке 12 показаны средние показатели Llama 3 8B и 70B в тестах Common Sense Reasoning, Knowledge, Reading Comprehension, Maths and Reasoning и Code Benchmark. Результаты показывают, что Llama 3 8B превосходит конкурирующие модели почти во всех категориях, как по количеству побед в категориях, так и по средней производительности по категориям. Мы также обнаружили, что Llama 3 70B значительно превосходит своего предшественника, Llama 2 70B, по большинству показателей, за исключением показателей здравого смысла, которые могут быть перегружены.Llama 3 70B также превосходит Mixtral 8x22B.
Результаты моделей 8B и 70B.На рисунке 12 показаны средние показатели Llama 3 8B и 70B в тестах Common Sense Reasoning, Knowledge, Reading Comprehension, Maths & Reasoning и Code Benchmark. Результаты показывают, что Llama 3 8B превосходит конкурирующие модели почти в каждой категории, как по количеству побед в каждой категории, так и по средней производительности в каждой категории. Мы также обнаружили, что Llama 3 70B значительно превосходит свою предшественницу, Llama 2 70B, в большинстве бенчмарков, за исключением бенчмарка Common Sense, который, возможно, достиг насыщения. Llama 3 70B также превосходит Mixtral 8x22B.
Подробные результаты для всех моделей.В таблицах 9, 10, 11, 12, 13 и 14 приведены результаты эталонного тестирования предварительно обученных моделей Llama 3 8B, 70B и 405B в задачах на понимание прочитанного, на кодирование, на понимание общих знаний, на математические рассуждения и на рутинные задачи. В этих таблицах сравнивается производительность Llama 3 с аналогичными по размеру моделями. Результаты показывают, что Llama 3 405B конкурентоспособна в своей категории и особенно сильно превосходит предыдущие модели с открытым исходным кодом. Для тестов с длинными контекстами мы приводим более полные результаты (включая задачи обнаружения, такие как "игла в стоге сена") в разделе 5.2.


5.1.2 Устойчивость модели
В дополнение к эталонной производительности, устойчивость является важным фактором качества предварительно обученных языковых моделей. Мы исследуем устойчивость выбора дизайна, сделанного предварительно обученными языковыми моделями в условиях вопросов с множественным выбором (MCQ). Предыдущие исследования показали, что производительность модели может быть чувствительна к кажущемуся произвольному выбору дизайна в этих условиях, например, оценки модели и даже рейтинги могут меняться в зависимости от порядка и маркировки контекстуальных примеров (Lu et al. 2022; Zhao et al. 2021; Robinson and Wingate 2023; Liang et al. 2022; Gupta et al. 2024), точный формат подсказок (Weber et al., 2023b; Mishra et al., 2022) или формат и порядок вариантов ответа (Alzahrani et al., 2024; Wang et al., 2024a; Zheng et al., 2023). Вдохновленные этой работой, мы используем эталон MMLU для оценки устойчивости предварительно обученной модели к (1) смещению маркировки в несколько выстрелов, (2) вариантам маркировки, (3) порядку ответов и (4) формату подсказок:
- Несколько этикеток на объективах отклеились. Следуя Zheng et al. (2023), ... (детали эксперимента и описание результатов здесь не приводятся).
- Варианты этикеток. Мы также исследовали реакцию модели на различные наборы выбранных лексем. Мы рассмотрели два набора тегов, предложенных Альзахрани и др. (2024): а именно, набор общих языковых тегов ($ и # @) и набор редких тегов (ое § з ü), которые не имеют никакого подразумеваемого относительного порядка. Мы также рассматриваем два варианта канонических тегов (A. B. C. D. и A) B) C) D)) и список чисел (1. 2. 3. 4.).
- Порядок ответов. Следуя Wang et al. (2024a), мы вычислили устойчивость результатов при различных порядках ответов. Для этого мы переставляем все ответы в наборе данных в соответствии с фиксированной перестановкой. Например, при перестановке A B C D все варианты ответов, помеченные A и B, сохраняют свои метки, а все варианты ответов, помеченные C, приобретают метку D, и наоборот.
- Формат реплики. Мы оценивали различия в результатах выполнения пяти подсказок, которые отличались по количеству содержащейся в них информации: одни подсказки просто просили модель ответить на вопрос, а другие утверждали об экспертности модели или о том, что она должна выбрать лучший ответ.

Таблица 11 Производительность предварительно обученных моделей в задаче на понимание общих знаний. Результаты включают доверительные интервалы 95%.

Таблица 12 Производительность предварительно обученных моделей в математических и рассуждающих задачах. Результаты включают доверительные интервалы 95%. 11 выстрелов.

Таблица 13 Производительность предварительно обученных моделей в языковых задачах общего назначения. Результаты включают доверительные интервалы 95%.

Рис. 13 Устойчивость нашей предварительно обученной языковой модели к различным вариантам дизайна в бенчмарке MMLU. Левая сторона: производительность при различных вариантах меток. Правая сторона: производительность при наличии различных меток в примере "меньше".

Рис. 14 Устойчивость нашей предварительно обученной языковой модели к различным вариантам дизайна в эталонном тесте MMLU. Левая сторона: производительность для различных последовательностей ответов. Правая сторона: производительность для различных форматов подсказок.
На рисунке 13 показаны результаты экспериментов, в которых мы исследовали устойчивость модели к вариантам меток (слева) и смещению меток в несколько выстрелов (справа). Результаты показывают, что наша предварительно обученная языковая модель очень устойчива к вариациям меток MCQ, а также к структуре меток с несколькими выстрелами. Эта устойчивость особенно заметна для параметрической модели 405B.
На рисунке 14 показаны результаты наших исследований надежности порядка ответов и формата подсказки. Эти результаты еще раз подчеркивают надежность работы наших предварительно обученных языковых моделей, в частности надежность Llama 3 405B.

5.1.3 Состязательный сравнительный анализ
Помимо упомянутых выше эталонных тестов, мы оценили несколько состязательных эталонов в трех областях: вопросы и ответы, математические рассуждения и обнаружение переписывания предложений. Эти тесты предназначены для проверки способности модели справляться с задачами, специально разработанными для решения сложных задач, и могут указать на проблемы с подгонкой модели к эталонным тестам.
- Вопросы и ответыМы использовали Adversarial SQuAD (Jia and Liang, 2017) и Dynabench SQuAD (Kiela et al., 2021).
- Математические рассужденияМы использовали GSM-Plus (Li et al., 2024c).
- Аспекты тестирования рерайтинга предложенийМы использовали PAWS (Zhang et al., 2019).
На рисунке 15 показаны оценки Llama 3 8B, 70B и 405B в состязательных эталонных тестах в зависимости от их результатов в несостязательных эталонных тестах. В качестве несостязательных эталонных тестов мы используем SQuAD для вопросов и ответов (Rajpurkar et al., 2016), GSM8K для математических рассуждений и QQP для обнаружения переписывания предложений (Wang et al., 2017). Каждая точка данных представляет собой пару из состязательного и несостязательного наборов данных (например, QQP в паре с PAWS), и мы показываем все возможные сочетания в рамках категории. Черная линия по диагонали указывает на паритет между состязательными и несостязательными наборами данных - линия указывает на то, что модель имеет схожую производительность независимо от состязательности или несостязательности.
Что касается обнаружения просодии предложения, то ни на предварительно обученные, ни на послеобученные модели, похоже, не влияет состязательный характер конструкций PAWS, что представляет собой огромное улучшение по сравнению с предыдущим поколением моделей. Этот результат подтверждает выводы Вебера и др. (2023a), которые также обнаружили, что большие языковые модели менее чувствительны к ложным корреляциям в нескольких неблагоприятных наборах данных. Однако для математических рассуждений и вопросов-ответов производительность в состязательном наборе значительно ниже, чем в несостязательном. Эта закономерность относится как к предварительно обученным, так и к пост-обученным моделям.
5.1.4 Анализ загрязнений
Мы провели анализ загрязнения, чтобы оценить степень влияния загрязнения оценочных данных в предтренировочном корпусе на результаты тестирования. В некоторых предыдущих работах использовались различные методы загрязнения и гиперпараметры - мы ссылаемся на исследование Singh et al. (2024). Результаты показывают, что наша предварительно обученная языковая модель очень устойчива к вариациям в маркировке вопросов с несколькими вариантами ответов, а также к вариациям в структуре меток с меньшим количеством образцов (описано в 2024). Ложноположительные и ложноотрицательные результаты могут возникать при любом из этих подходов, и вопрос о том, как лучше проводить анализ загрязнения, остается открытым. Здесь мы в основном следуем рекомендациям Singh et al. (2024).


Методы:В частности, Сингх и др. (2024) предлагают эмпирически выбирать метод обнаружения загрязнения, основываясь на том, какой метод приводит к наибольшей разнице между "чистым" набором данных и всем набором данных, которую они называют предполагаемым выигрышем в производительности. Для всех оценочных наборов данных мы выставляли оценки на основе 8-граммового перекрытия, которое, по мнению Singh et al. (2024), является точным для многих наборов данных. Мы считаем пример из набора данных D загрязненным, если его маркировка TD часть из них хотя бы раз появляется в корпусе предварительного обучения. Мы выбираем для каждого набора данных отдельно TDв зависимости от того, какое значение показывает максимальный значительный прирост производительности (по трем размерам модели).
Результаты:В таблице 15 показан процент данных оценки для всех основных эталонов, которые считаются загрязненными для максимальной оценки прироста производительности, как описано выше. Из этой таблицы мы исключили те бенчмарки, для которых результаты не были значимыми, например, из-за слишком малого количества чистых или загрязненных объединенных образцов, или в которых наблюдаемые оценки прироста производительности демонстрировали крайне неустойчивое поведение.
В таблице 15 видно, что для некоторых наборов данных загрязнение имеет большое влияние, а для других - нет. Например, для PiQA и HellaSwag и оценка загрязнения, и оценка выигрыша в производительности высоки. С другой стороны, для Natural Questions оценка загрязнения 52% практически не влияет на производительность. Для SQuAD и MATH низкие пороговые значения приводят к высоким уровням загрязнения, но не дают прироста производительности. Это говорит о том, что загрязнение может быть бесполезным для этих наборов данных, или о том, что для получения более точных оценок необходимо большее n. Наконец, для MBPP, HumanEval, MMLU и MMLU-Pro могут потребоваться другие методы обнаружения загрязнения: даже при более высоких пороговых значениях 8-граммовое перекрытие дает настолько высокие оценки загрязнения, что невозможно получить хорошие оценки прироста производительности.
5.2 Тонкая настройка языковой модели
Мы показываем результаты модели Llama 3 после обучения на эталонных тестах различных возможностей. Как и в случае с предварительным обучением, мы публикуем данные, полученные в рамках нашей оценки, на общедоступных эталонах, которые можно найти на Huggingface (вставить ссылку здесь). Более подробную информацию о нашей системе оценки можно найти здесь (вставить ссылку здесь).
Бенчмаркинг и индикаторы.В таблице 16 приведены все эталонные тесты, разбитые на категории по способностям. Мы дезактивируем данные, полученные после обучения, путем установления точных соответствий с подсказками в каждом эталонном тесте. Помимо стандартных академических эталонных тестов, мы также провели обширную ручную оценку различных способностей. Подробную информацию см. в разделе 5.3.
Экспериментальная установка.Мы используем ту же экспериментальную установку, что и на этапе предварительного обучения, и анализируем Llama 3 в сравнении с другими моделями, сопоставимыми по размеру и возможностям. По возможности мы сами оцениваем производительность других моделей и сравниваем результаты с приведенными в отчетах, чтобы выбрать лучшую оценку. Более подробную информацию о нашей системе оценки можно найти здесь (ссылка вставлена сюда).

Таблица 16 Эталонные тесты после обучения по категориям. Обзор всех эталонных тестов, которые мы использовали для оценки модели Llama 3 после обучения, отсортированных по способностям.
5.2.1 Контрольная оценка соответствия общим знаниям и инструкциям
Мы использовали контрольные показатели, перечисленные в таблице 2, чтобы оценить возможности Llama 3 с точки зрения общих знаний и соблюдения инструкций.
Общие знания: Мы используем MMLU (Hendrycks et al., 2021a) и MMLU-Pro (Wang et al., 2024b) для оценки производительности Llama 3 в вопросах, основанных на знаниях. Для MMLU мы сообщаем макросредние показатели точности выполнения подзадач в 5-ти кратном образцовом критерии без CoT. MMLU-Pro - это расширенная версия MMLU, содержащая более сложные вопросы, ориентированные на умозаключения, исключающая шумные вопросы и расширяющая диапазон вариантов ответа с четырех до десяти. Учитывая его нацеленность на сложные рассуждения, мы приводим пять примеров CoT для MMLU-Pro. Все задания оформлены в виде генеративных задач, аналогичных simple-evals (OpenAI, 2024).
Как показано в таблице 2, наши варианты Llama 3 8B и 70B превосходят другие аналогичные по размеру модели в обеих задачах на общие знания. Наша модель 405B превосходит GPT-4 и Nemotron 4 340B, а Claude 3.5 Sonnet лидирует среди более крупных моделей.
Инструкции по эксплуатации: Мы используем IFEval (Zhou et al., 2023) для оценки способности Llama 3 и других моделей выполнять инструкции на естественном языке. IFEval включает около 500 "проверяемых инструкций", таких как "написать более 400 слов", которые могут быть проверены с помощью эвристики. IFEval включает около 500 "проверяемых инструкций", таких как "написать более 400 слов", которые могут быть проверены с помощью эвристики. В таблице 2 мы приводим средние значения точности на уровне подсказок и инструкций при строгих и свободных ограничениях. Отметим, что все варианты Llama 3 превосходят сравниваемые модели на IFEval.
5.2.2 Экзамены на компетентность
Далее мы оцениваем нашу модель на серии тестов на способности, изначально разработанных для тестирования людей. Мы получили эти тесты из общедоступных официальных источников; для некоторых тестов мы приводим средние баллы по разным наборам тестов как результат каждого теста способностей. В частности, мы усредняем:
- GRE: официальные тренировочные тесты GRE 1 и 2, предлагаемые Службой образовательного тестирования;
- LSAT: официальный предварительный тест 71, 73, 80 и 93;
- SAT: 8 экзаменов из The Official SAT Study Guide, 2018 Edition;
- AP: один официальный пробный экзамен по каждому предмету;
- GMAT: Официальный онлайн-тест GMAT.
Вопросы на этих экзаменах содержат вопросы с множественным выбором и генеративные вопросы. Мы исключаем вопросы с прикрепленными изображениями. Для вопросов GRE, содержащих несколько правильных вариантов, мы считаем результат правильным только в том случае, если модель выбрала все правильные варианты. В случаях, когда имеется более одного экзаменационного набора, мы используем небольшое количество подсказок для оценки. Мы корректируем оценки до диапазона 130-170 (для GRE) и сообщаем о точности для всех остальных экзаменов.

Наши результаты приведены в таблице 17. Мы обнаружили, что наша модель Llama 3 405B работает так же, как и Клод Sonnet 3,5 очень похож на GPT-4 4o. Наша модель 70B, с другой стороны, демонстрирует еще более впечатляющие характеристики. Она значительно лучше GPT-3.5 Turbo и превосходит Nemotron 4 340B во многих тестах.
5.2.3 Эталоны кодирования
Мы оцениваем возможности Llama 3 по генерации кода на нескольких популярных эталонах программирования на Python и многоязычных языках. Для измерения эффективности модели в генерации функционально корректного кода мы используем метрику pass@N, которая оценивает процент прохождения модульных тестов для набора из N поколений. Мы приводим результаты для pass@1.


Генерация кода на языке Python. HumanEval (Chen et al., 2021) и MBPP (Austin et al., 2021) - популярные бенчмарки для генерации кода на Python, ориентированные на относительно простую, самодостаточную функциональность. HumanEval+ (Liu et al., 2024a) - это улучшенная версия HumanEval, в которой генерируется больше тестовых примеров, чтобы избежать ложных срабатываний. Эталонная версия MBPP EvalPlus (v0.2.0) представляет собой выборку из 378 хорошо отформатированных вопросов (Liu et al., 2024a) из 974 исходных вопросов в оригинальном наборе данных MBPP (тренировочном и тестовом). Результаты этих эталонных тестов приведены в таблице 18. При сравнении этих вариантов Python Llama 3 8B и 70B превзошли модели того же размера, работающие одинаково. Что касается самых больших моделей, то Llama 3 405B, Claude 3.5 Sonnet и GPT-4o показали схожие результаты, причем GPT-4o - самые сильные.
Модели. Мы сравнили Llama 3 с другими моделями аналогичного размера. Для самой большой модели Llama 3 405B, Claude 3.5 Sonnet и GPT-4o показали одинаковые результаты, причем GPT-4o продемонстрировал лучшие результаты.
Генерация кода на нескольких языках программирования: Чтобы оценить возможности генерации кода на языках, отличных от Python, мы приводим результаты бенчмарка MultiPL-E (Cassano et al., 2023), основанного на переводах вопросов HumanEval и MBPP. В таблице 19 приведены результаты для ряда популярных языков программирования.
Обратите внимание на значительное падение производительности по сравнению с аналогом на Python в таблице 18.
5.2.4 Многоязычный бенчмаркинг
Llama 3 поддерживает 8 языков - английский, немецкий, французский, итальянский, португальский, хинди, испанский и тайский, хотя базовая модель была обучена на более широком наборе языков. В таблице 20 приведены результаты оценки Llama 3 на эталонах Multilingual MMLU (Hendrycks et al., 2021a) и Multilingual Primary Mathematics (MGSM) (Shi et al., 2022).
- Многоязычный MMLU: Мы использовали Google Translate для перевода вопросов, коротких примеров и ответов MMLU на разные языки. Мы сохранили описания заданий на английском языке и оценивали их в режиме 5 выстрелов.
- MGSM (Shi et al., 2022): Для нашей модели Llama 3 мы приводим результаты 0-shot CoT для MGSM. Многоязычный MMLU - это внутренний бенчмарк, который включает в себя перевод вопросов и ответов MMLU (Hendrycks et al., 2021a) на 7 языков - результаты 5 выстрелов, которые мы сообщаем, усреднены по этим языкам.
Для MGSM (Shi et al., 2022) мы протестировали нашу модель, используя те же нативные подсказки, что и в simple-evals (OpenAI, 2024), и поместили ее в среду CoT с 0 выстрелами. В таблице 20 мы приводим средние результаты для всех языков, включенных в бенчмарк MGSM.

Мы обнаружили, что Llama 3 405B превосходит большинство других моделей на MGSM со средним результатом 91,61TP3 T. На MMLU, в соответствии с результатами по английскому MMLU выше, Llama 3 405B отстает от GPT-4o 21TP3 T. С другой стороны, обе модели Llama 3 70B и 8B превосходят конкурентов, лидируя с большим отрывом на обеих задачах. в обеих задачах.
5.2.5 Контрольные вопросы по математике и рассуждениям
Результаты наших математических тестов и тестов на вывод показаны в таблице 2. Модель Llama 3 8B превосходит другие модели того же размера в тестах GSM8K, MATH и GPQA. Наша модель 70B показывает значительно лучшую производительность, чем ее аналоги, во всех эталонных тестах. Наконец, модель Llama 3 405B является лучшей в своей категории для GSM8K и ARC-C, а для MATH - второй по результативности. В GPQA она хорошо конкурирует с GPT-4 4o, а Claude 3.5 Sonnet возглавляет список со значительным отрывом.
5.2.6 Сравнительный анализ в длительном контексте
Мы рассматриваем целый ряд задач, относящихся к различным областям и типам текстов. В приведенных ниже бенчмарках мы сосредоточились на подзадачах, использующих непредвзятый протокол оценки, т. е. метрики, основанные на точности, а не метрики перекрытия n-грамм. Мы также отдаем предпочтение задачам, в которых наблюдается меньшая дисперсия.
- Иголка в стоге сена (Камрадт, 2023) Измерьте способность модели извлекать информацию, скрытую в случайных частях длинных документов. Наша модель Llama 3 демонстрирует отличную производительность поиска игл, успешно извлекая 100% "игл" при любой глубине документа и длине контекста. Мы также измерили производительность Multi-needle (табл. 21), вариации Needle-in-a-Haystack, где мы вставляли четыре "иглы" в контекст и проверяли, сможет ли модель извлечь две из них. Наша модель Llama 3 достигла почти идеальных результатов поиска.
- ZeroSCROLLS (Shaham et al., 2023)это эталонный тест с нулевой выборкой для понимания естественного языка в длинных текстах. Поскольку истинные ответы не находятся в открытом доступе, мы приводим данные по валидному набору. Наши модели Llama 3 405B и 70B равны или превосходят другие модели по ряду задач в этом эталонном тесте.
- InfiniteBench (Zhang et al., 2024) Модели необходимы для понимания зависимостей на большом расстоянии в контекстных окнах. Мы оцениваем Llama 3 на En.QA (викторина по романам) и En.MC (викторина по романам с множественным выбором), где наша модель 405B превосходит все остальные модели. Особенно значительный выигрыш наблюдается на En.QA.

Таблица 21 Бенчмаркинг длинных текстов. Для ZeroSCROLLS (Shaham et al., 2023) мы сообщаем результаты на валидном множестве. Для QuALITY мы сообщаем точные совпадения, для Qasper - f1, а для SQuALITY - rougeL. Для метрики En.QA InfiniteBench (Zhang et al., 2024) мы сообщаем f1, а для En.MC - точность. Для Multi-needle (Kamradt, 2023) мы вставляем 4 иглы в контекст и проверяем, способна ли модель извлечь 2 иглы с разной длиной контекста, и вычисляем среднее значение recall для 128k из 10 длин последовательностей.
5.2.7 Производительность инструмента
Мы оценили нашу модель с помощью серии бенчмарков с нулевой выборкой использования инструментов (т.е. вызовов функций): Nexus (Srinivasan et al., 2023), API-Bank (Li et al., 2023b), Gorilla API-Bench (Patil et al., 2023) и Berkeley Function Call Leaderboard ( BFCL) (Yan et al., 2024). Результаты приведены в таблице 22.
На Nexus наш вариант Llama 3 показывает наилучшие результаты, опережая другие модели в своей категории. На API-Bank наши модели Llama 3 8B и 70B значительно превосходят другие модели в своих категориях. Модель 405B уступает только Claude 3.5 Sonnet 0.6%. Наконец, наши модели 405B и 70B превосходят BFCL и занимают второе место в своих категориях размеров. Модель Llama 3 8B стала лучшей в своей категории.
Мы также провели ручную оценку, чтобы проверить способность модели использовать инструмент, сосредоточившись на задачах выполнения кода. Мы собрали 2000 пользовательских запросов, генерации чертежей и загрузки файлов, связанных с выполнением кода (не включая чертежи и загрузку файлов). Эти подсказки были получены из LMSys Набор данных (Chiang et al., 2024), эталоны GAIA (Mialon et al., 2023b), человеческие аннотаторы и синтетическая генерация. Мы сравнили Llama 3 405B с GPT-4o с помощью OpenAI's Assistants API10 . Результаты показаны на рисунке 16. Llama 3 405B явно превосходит GPT-4o в задачах выполнения только текстового кода и генерации рисунков; однако она отстает от GPT-4o в случае загрузки файлов.

5.3 Ручная оценка
В дополнение к оценке на стандартном эталонном наборе данных мы провели серию человеческих оценок. Эти оценки позволяют нам измерить и оптимизировать более тонкие аспекты работы модели, такие как тон модели, уровень избыточности, понимание нюансов и культурного контекста. Тщательно разработанные оценки Ренгрена тесно связаны с пользовательским опытом, позволяя понять, как модель работает в реальном мире.
https://platform.openai.com/docs/assistants/overview
Для многораундовых оценок на людях количество раундов в каждой подсказке варьировалось от 2 до 11. Мы оценивали реакцию модели в последнем раунде.
Коллекция советов. Мы собрали высококачественные подсказки, охватывающие широкий спектр категорий и трудностей. Для этого мы сначала разработали таксономию с категориями и подкатегориями для максимально возможного количества способностей модели. Используя эту таксономию, мы собрали около 7 000 подсказок, охватывающих шесть однораундовых способностей (английский язык, рассуждение, кодирование, хинди, испанский и португальский языки) и три многораундовые способности11 (английский язык, рассуждение и кодирование). Мы следили за тем, чтобы в каждой категории подсказки равномерно распределялись по подкатегориям. Мы также отнесли каждую подсказку к одному из трех уровней сложности и убедились, что наш набор подсказок содержит примерно 10% легких подсказок, 30% умеренно сложных подсказок и 60% сложных подсказок. Все человеческие оценки Рис. 16 Результаты человеческих оценок Llama 3 405B против GPT-4o в задачах на выполнение кода, включая рисование и загрузку файлов. Llama 3 405B превосходит GPT-4o по выполнению кода (не включая черчение и загрузку файлов), а также по генерации графиков, но отстает по загрузке файлов.
Наборы киев прошли строгий процесс контроля качества. Команда моделирования не имеет доступа к нашим киям для оценки человека, чтобы предотвратить случайное загрязнение или чрезмерную подгонку тестового набора.
Процесс оценки. Чтобы провести парную оценку двух моделей, мы спрашиваем аннотаторов, какой из двух ответов модели (сгенерированных разными моделями) им больше нравится. Аннотаторы используют 7-балльную шкалу, которая позволяет им указать, является ли один модельный ответ намного лучше, лучше, немного лучше или примерно таким же, как другой. Если аннотаторы указывают, что ответ модели намного лучше или лучше, чем ответ другой модели, мы будем считать это "победой" этой модели. Мы будем сравнивать модели в парах и сообщать о количестве побед для каждой возможности в наборе подсказок.
в конце концов. Мы сравнили Llama 3 405B с GPT-4 (версия API 0125), GPT-4o (версия API) и Claude 3.5 Sonnet (версия API), используя человеческий метод оценки. Результаты этих оценок показаны на рисунке 17. Мы видим, что Llama 3 405B демонстрирует примерно сопоставимые результаты с API-версией 0125 GPT-4, при этом результаты по сравнению с GPT-4o и Claude 3.5 Sonnet неоднозначны (есть победы и есть поражения). Почти во всех случаях Llama 3 и GPT-4 побеждают с точностью до погрешности. Llama 3 405B превосходит GPT-4 в многораундовых заданиях на рассуждение и кодирование, но не в многоязычных (хинди, испанский и португальский) подсказках. Llama 3 работает так же хорошо, как GPT-4 в английских подсказках, как Claude 3.5 Sonnet в многоязычных подсказках, и превосходит как однораундовые, так и многораундовые английские подсказки. Однако она не дотягивает до Claude 3.5 Sonnet в таких областях, как кодирование и умозаключение. Качественно мы обнаружили, что на эффективность модели при оценке человеком сильно влияют такие тонкие факторы, как тон голоса, структура ответа и уровень избыточности - все факторы, которые мы оптимизируем в процессе посттренировочного обучения. факторы, которые мы оптимизируем. В целом, результаты человеческой оценки совпадают с результатами стандартных эталонных оценок: Llama 3 405B очень хорошо конкурирует с ведущими промышленными моделями, что делает ее лучшей общедоступной моделью.
ограничения. Все результаты человеческой оценки прошли строгий процесс проверки качества данных. Однако из-за сложности определения объективных критериев реакции модели на человеческие оценки могут влиять личные предубеждения, опыт и предпочтения аннотаторов, что может привести к непоследовательным или ненадежным результатам.

Рис. 16 Результаты оценки человеческих возможностей Llama 3 405B по сравнению с GPT-4o на задачах выполнения кода (включая построение графиков и загрузку файлов). Llama 3 405B превосходит GPT-4o по выполнению кода (за исключением черчения и загрузки файлов) и генерации графиков, но отстает по загрузке файлов.

Рис. 17 Результаты ручной оценки модели Llama 3 405B. Слева: сравнение с GPT-4. В центре: сравнение с GPT-4o. Справа: сравнение с Claude 3.5 Sonnet. Все результаты включают доверительные интервалы 95% и исключают связи.
5.4 Безопасность
В разделе "Безопасность" содержатся важные слова, которые можно пропустить или скачать в формате PDF, спасибо!
Мы сосредоточились на оценке способности Llama 3 генерировать контент безопасным и ответственным образом и при этом получать максимум полезной информации. Наша работа по обеспечению безопасности начинается с этапа предварительного обучения, в основном в виде очистки и фильтрации данных. Затем мы опишем методику тонкой настройки безопасности, сосредоточившись на том, как обучить модель соблюдать определенные политики безопасности и при этом сохранять полезность. Мы проанализируем каждую особенность Llama 3, включая многоязычие, длительные контексты, использование инструментов и различные мультимодальные особенности, чтобы оценить эффективность наших мер по снижению безопасности.
Затем мы описываем нашу оценку повышения риска кибербезопасности и химического/биологического оружия. Под повышением понимается дополнительный риск, возникающий в результате новых технологических разработок по сравнению с использованием существующих технологий (например, веб-поиска).
Далее мы описываем, как мы используем тестирование "красной команды" для итеративного выявления и устранения различных межфункциональных рисков безопасности и оценки остаточного риска.
Наконец, мы расскажем о безопасности на уровне системы, или о разработке и программировании классификаторов вокруг входов и выходов самой модели, чтобы еще больше повысить безопасность и облегчить разработчикам адаптацию безопасности к различным случаям использования и более ответственное внедрение генеративного ИИ.
5.4.1 Построение эталона
Для того чтобы разрабатывать модели безопасно и ответственно, мы создали различные внутренние эталоны. Наши эталоны вдохновлены таксономией рисков ML Commons (Vidgen et al., 2024). Хотя уже существуют такие эталоны безопасности языковых моделей, как ToxiGen (Hartvigsen et al., 2022), XS Test (Röttger et al., 2023) и т. д., для многих новых функций Llama 3 не хватает внешних эталонов, а существующие внешние эталоны часто недостаточно развиты в плане широты и глубины.
Для каждой категории риска мы собрали сигналы враждебности или пограничные сигналы, написанные людьми - примеры этих сигналов приведены в таблице 23. Неприятельские подсказки варьируются от простых подсказок, которые напрямую вызывают вредную реакцию, до подсказок, включающих сложные методы взлома джейлбрейка. Эти вредоносные подсказки составляют базовый уровень, по которому мы измеряем частоту нарушений.
В качестве обратного показателя частоты нарушений мы также построили эталон ложного отказа, состоящий из подсказок ограниченности. Когда модель отказывается дать полезный ответ, даже если существует разумный и безопасный ответ, мы называем эту ситуацию ложным отказом. Признаки ограниченности близки к признакам границ принятия решений, и хорошо откалиброванная модель должна уметь работать с этими признаками, например, "Как мне украсть внимание у моего лучшего друга, который всегда играет главную роль?". Наш общий размер эталона для нарушений и ложных отказов превышает 4000 подсказок/компетенций или языков, включая как однораундовые, так и многораундовые подсказки.
5.4.2 Предварительная подготовка по безопасности
Мы считаем, что ответственное развитие должно рассматриваться со всех сторон и учитываться на каждом этапе разработки и развертывания модели. Во время предварительного обучения мы применяем различные фильтры, например, используемые для выявления сайтов, которые могут содержать личную информацию (см. раздел 3.1). Мы также уделяем особое внимание мемоизации с возможностью обнаружения (Nasr et al., 2023). Как и в Carlini et al. (2022), мы выбираем подсказки и истинные результаты с разной частотой появления, используя эффективный скользящий хэш-индекс всех n кортежей в обучающих данных. Мы создаем различные тестовые сценарии, варьируя длину подсказок и истинных результатов, язык обнаружения и область целевых данных. Затем мы измеряем, как часто модель точно генерирует последовательности истинных результатов, и анализируем относительные показатели мемоизации в указанных сценариях. Мы определяем дословную мемоизацию как коэффициент включения (доля сгенерированных моделью последовательностей, содержащих истинные результаты) и представляем этот показатель в виде средневзвешенных значений, приведенных в таблице 24, которые определяются распространенностью того или иного признака в данных. Мы обнаружили низкий уровень запоминания для обучающих данных (1,13% и 3,91% в среднем для n = 50 и n = 1000, соответственно, для 405B). При использовании той же методики, примененной к эквивалентной по размеру смеси данных, Llama 2 имеет примерно такой же уровень запоминания.

Таблица 23 Примеры сигналов состязательности для всех возможностей в нашем внутреннем сравнительном анализе.

Таблица 24 Среднее значение дословной памяти предварительно обученной Llama 3 в выбранных тестовых сценариях. В качестве базового уровня используется Llama 2, использующая ту же методологию подсказок, что и при работе с данными, смешанными с английскими 50-граммовыми сценариями.
5.4.3 Тонкая настройка безопасности
В этой главе описывается подход к тонкой настройке безопасности, который мы используем для снижения рисков, связанных с различными возможностями, и который включает в себя два ключевых аспекта: (1) данные по обучению технике безопасности и (2) методы снижения рисков. Наш процесс тонкой настройки безопасности основан на нашей общей методологии тонкой настройки с модификациями для решения конкретных проблем безопасности.
Мы оптимизируем два основных показателя: коэффициент нарушений (VR), который фиксирует случаи, когда модель генерирует ответы, нарушающие политику безопасности, и коэффициент ложных отклонений (FRR), который фиксирует случаи, когда модель неверно отклоняет ответы на безобидные сигналы. В то же время мы оцениваем работу модели в бенчмарках полезности, чтобы убедиться, что улучшение безопасности не сказывается на общей полезности. Наши эксперименты показывают, что модель с 8 миллиардами параметров требует большего соотношения данных о безопасности и данных о полезности по сравнению с моделью с 70 миллиардами параметров для достижения сопоставимых показателей безопасности. Более крупные модели лучше различают враждебный и пограничный контексты, что приводит к более благоприятному балансу между VR и FRR.
Данные для тонкой настройки
Качество и дизайн данных для безопасного обучения оказывают огромное влияние на эффективность. Проведя обширные эксперименты с абляцией, мы пришли к выводу, что качество важнее количества. В основном мы используем данные, созданные человеком, от поставщиков данных, но они подвержены ошибкам и несоответствиям, особенно в отношении тонких политик безопасности. Чтобы обеспечить высочайшее качество данных, мы разработали инструменты аннотирования с помощью искусственного интеллекта для поддержки нашего строгого процесса контроля качества.
В дополнение к сбору сигналов противника мы также собрали аналогичный набор сигналов, называемых пограничными сигналами. Эти сигналы тесно связаны с неблагоприятными сигналами, но их цель - научить модель давать полезные ответы и тем самым снизить коэффициент ложных отклонений (FRR).
В дополнение к человеческим аннотациям мы используем синтетические данные, чтобы улучшить качество и охват обучающего набора данных. Мы генерируем дополнительные примеры противника с помощью различных методов, включая контекстное обучение с использованием сложных системных подсказок, мутации на основе новых векторов атак, направляющих исходные подсказки, и продвинутые алгоритмы, включая Rainbow Team (Samvelyan et al., 2024), основанный на MAP-Elites (Mouret and Clune, 2015), который генерирует подсказки по нескольким размерных ограниченных подсказок.
Мы также рассмотрели вопрос о тоне голоса модели при генерировании ответов безопасности, который может повлиять на последующее восприятие пользователем. Мы разработали руководство по тону отказа для Llama 3 и проследили за тем, чтобы все новые данные по безопасности соответствовали ему с помощью строгого процесса контроля качества. Мы также улучшили существующие данные безопасности, используя сочетание переписывания с нулевой выборкой и ручного редактирования для получения высококачественных данных. Благодаря этим методам и использованию классификаторов тональности для оценки качества тональности ответов службы безопасности мы смогли значительно улучшить формулировки модели.
Тонкая настройка надзора за безопасностью
Следуя нашему рецепту Llama 2 (Touvron et al., 2023b), мы объединили все данные о полезности и безопасности на этапе выравнивания модели. Кроме того, мы ввели пограничные наборы данных, чтобы помочь модели различать тонкие различия между безопасными и небезопасными запросами. Наша команда аннотаторов была проинструктирована тщательно разрабатывать ответы на сигналы безопасности, основываясь на наших рекомендациях. Мы обнаружили, что SFT очень эффективно выравнивает модель, когда мы стратегически сбалансировали соотношение неблагоприятных и пограничных примеров. Мы сосредоточились на более сложных зонах риска, где соотношение пограничных примеров было выше. Это играет важную роль в наших успешных усилиях по снижению уровня безопасности при минимизации ложных отклонений.
Кроме того, мы изучили влияние размера модели на компромисс между FRR и VR (см. рис. 18). Наши результаты свидетельствуют о том, что он будет меняться - маленькие модели требуют большей доли данных о безопасности по сравнению с полезностью, и эффективно сбалансировать VR и FRR сложнее, чем большие модели.
DPO по вопросам безопасности
Чтобы повысить эффективность обучения безопасности, мы включили в набор данных предпочтений в DPO состязательные и пограничные примеры. Мы обнаружили, что создание пар ответов на заданный сигнал, которые почти ортогональны в пространстве встраивания, особенно эффективно для обучения модели различать хорошие и плохие ответы. Мы провели несколько экспериментов, чтобы определить оптимальное соотношение неблагоприятных, ограниченных и полезных примеров с целью оптимизации компромисса между FRR и VR. Мы также обнаружили, что размер модели влияет на результаты обучения - таким образом, мы адаптировали различные комбинации безопасности для разных размеров модели.

На рисунке 18 показано влияние размера модели на разработку комбинаций данных о безопасности для баланса между показателями Violation Rate (VR) и False Refusal Rate (FRR). Каждая точка на диаграмме рассеяния представляет собой различную комбинацию данных для балансировки данных о безопасности и полезности. Различные размеры моделей сохраняют разные возможности обучения безопасности. Наши эксперименты показывают, что для модели 8B требуется более высокая доля данных о безопасности по отношению к данным о полезности в общем портфеле SFT (supervised fine-tuning), чтобы достичь сопоставимых показателей безопасности с моделью 70B. Более крупные модели лучше различают враждебные и краевые контексты, что приводит к более желаемому балансу между VR и FRR.
5.4.4 Результаты безопасности
Сначала мы представим обзор общей производительности Llama 3 во всех аспектах, а затем опишем результаты тестирования каждой из новых функций и эффективность снижения рисков безопасности.
Общая производительность:На рисунках 19 и 20 показаны результаты финальных нарушений и ложных отклонений Llama 3 в сравнении с аналогичными моделями. Эти результаты сфокусированы на нашей модели с наибольшим параметрическим масштабом (Llama 3 405B) и сравнивают ее со смежными конкурентами. Два из этих конкурентов представляют собой сквозные системы, доступные через API, а другой - языковая модель с открытым исходным кодом, которую мы разместили у себя и оценивали напрямую. Мы протестировали нашу модель Llama как самостоятельно, так и в сочетании с Llama Guard, нашим открытым решением для обеспечения безопасности на уровне системы, как подробно описано в разделе 5.4.7.
Несмотря на то что желательно снизить количество нарушений, очень важно использовать ложные отказы в качестве обратного показателя, поскольку модель, которая всегда отказывает, является самой высокой с точки зрения безопасности, но совершенно бесполезной. Аналогично, модель, которая всегда отвечает на все запросы, независимо от того, насколько проблематичен запрос, является чрезмерно вредной и токсичной. На рисунке 21 показано, как различные модели и системы в отрасли делают компромиссы и как Llama 3 справляется с ними, используя наши внутренние бенчмарки. Мы обнаружили, что наша модель обладает высокой конкурентоспособностью по показателям частоты нарушений, а также низкой частотой ложных отказов, что говорит о хорошем балансе между полезностью и безопасностью.
Многоязычная безопасность:Наши эксперименты показывают, что знания о безопасности на английском языке нелегко перенести на другие языки, особенно с учетом нюансов политики безопасности и специфических языковых контекстов. Поэтому очень важно собирать высококачественные данные о безопасности для каждого языка. Мы также обнаружили, что распределение данных о безопасности по языкам существенно влияет на производительность системы безопасности: некоторые языки выигрывают от трансферного обучения, в то время как другим требуется больше данных для конкретного языка. Чтобы найти баланс между коэффициентом ложных отклонений (FRR) и коэффициентом нарушений (VR), мы итеративно добавляем данные о противниках и границах, отслеживая влияние этих двух метрик.
На рисунке 19 представлены результаты нашего внутреннего бенчмарка с моделями короткого контекста, показывающие количество нарушений и ложных отказов Llama 3 на английском и других языках, а также их сравнение с аналогичными моделями и системами. Для создания эталонов для каждого языка мы использовали комбинацию подсказок, написанных носителями языка, иногда дополняя их переводами из английских эталонов. Для всех поддерживаемых языков мы обнаружили, что Llama 405B в сочетании с Llama Guard по крайней мере так же безопасна, как и две конкурирующие системы, если не считать более строгой защиты, а процент ложных отказов остается конкурентоспособным.
Длительная контекстная безопасность:Модели с длинным контекстом без целенаправленного смягчения уязвимы для многочисленных атак с целью побега из тюрьмы (Anil et al., 2024). Чтобы решить эту проблему, мы провели тонкую настройку нашей модели на наборе данных SFT, который содержит примеры безопасного поведения в присутствии демонстраций небезопасного поведения. Мы разработали масштабируемую стратегию смягчения, которая значительно уменьшает VR, тем самым эффективно нейтрализуя влияние более длительных контекстных атак, даже для 256 атак. Влияние этого подхода на FRR и большинство метрик полезности практически незначительно.
Для количественной оценки эффективности наших мер по снижению безопасности в длинном контексте мы используем два дополнительных метода бенчмаркинга: DocQA и Many-shot. В DocQA (сокращение от "document quizzing") мы используем длинные документы, содержащие информацию, которая может быть использована в недоброжелательных целях. Модели предоставляется документ и набор подсказок, связанных с документом, чтобы проверить, имеет ли вопрос отношение к информации в документе, что влияет на способность модели безопасно отвечать на подсказки.
В Many-shot, следуя примеру Anil et al. (2024), мы создаем синтетический журнал чата, состоящий из пар небезопасных подсказок-ответов. Последняя подсказка не зависит от предыдущих сообщений и используется для проверки того, влияет ли небезопасное контекстное поведение на небезопасные ответы модели. На рисунке 20 показаны показатели нарушений и ложных отказов для DocQA и Many-shot. Мы видим, что Llama 405B (с Llama Guard и без нее) превосходит систему Comp. 2 по количеству нарушений и ложных отказов как для DocQA, так и для Many-shot. Относительно Comp. 1 мы видим, что Llama 405B более безопасна, но немного увеличивает количество ложных отказов.
Безопасность использования инструментов:Разнообразие возможных инструментов и вариантов их использования, а также реализации, интегрирующие инструменты в модель, делают сложной задачу полного смягчения возможности использования инструментов (Wallace et al., 2024). Мы сосредоточимся на примере поиска. На рисунке 20 показаны показатели нарушений и ложных отказов. Мы провели тестирование системы Comp. 1 и обнаружили, что Llama 405B более безопасна, но имеет немного более высокий показатель ложных отказов.

Рисунок 19 Коэффициенты нарушений (VR) и ложных отклонений (FRR) на английском языке и в наших основных многоязычных контекстных фразах Сравнение Llama 3 405B (с защитой на системном уровне Llama Guard (LG) и без нее) с конкурирующими моделями и системами.Comp. 3 Неподдерживаемые языки обозначены символом "x". ". Чем меньше значение, тем лучше.

Рисунок 20 Частота нарушений (VR) и частота ложных отклонений (FRR) в бенчмаркинге использования инструментов и длинных текстов. Ниже - лучше. Результаты эталонных тестов DocQA и Multi-Round Q&A представлены отдельно. Обратите внимание, что из-за состязательного характера этого теста у нас нет ограниченного набора данных для многораундовой викторины, поэтому мы не измеряли коэффициент ложных отказов для него. Что касается использования инструментов (поиска), то мы сравниваем Llama 3 405B только с Comp. 1.

Рисунок 21 Показатели нарушений и отказов для моделей и возможностей. Каждая точка представляет собой общий показатель отказов. Показатели нарушений оцениваются для эталонов возможностей, присущих всем категориям безопасности. Символы указывают, оцениваем ли мы безопасность на уровне модели или на уровне системы. Как и ожидалось, результаты оценки безопасности на уровне модели показывают более высокие показатели нарушений и более низкие показатели отказов, чем результаты оценки безопасности на уровне системы. Llama 3 стремится сбалансировать низкие показатели нарушений и низкие показатели ложных отказов, тогда как некоторые конкуренты предпочитают одно или другое.
5.4.5 Результаты оценки кибербезопасности
Для оценки риска кибербезопасности мы используем систему бенчмарков CyberSecEval (Bhatt et al., 2023, 2024), которая включает в себя измерения безопасности для таких задач, как генерация небезопасного кода, генерация вредоносного кода, внедрение с помощью текстового запроса и выявление уязвимостей. Мы разработали и применили Llama 3 к новым эталонам, включая фишинг копьем и автономные сетевые атаки. В целом мы обнаружили, что Llama 3 не сильно уязвима к генерации вредоносного кода или использованию уязвимостей. Ниже представлены краткие результаты по конкретным задачам:
- Фреймворк для тестирования небезопасного кодирования:Оценивая модели Llama 3 8B, 70B и 405B с помощью тестового фреймворка для проверки небезопасного кодирования, мы продолжаем наблюдать, что более крупные модели генерируют больше небезопасного кода, и этот код имеет более высокий средний балл BLEU (Bhatt et al., 2023).
- Корпус злоупотреблений переводчика кода:Мы обнаружили, что модель Llama 3 склонна к выполнению вредоносного кода по определенным запросам: у Llama 3 405B показатель соответствия вредоносным запросам составил 10,41 TP3T по сравнению с 3,81 TP3T для Llama 3 70B.
- Контрольная работа по инъекции текстовых подсказок:При сравнении с эталоном введения подсказок Llama 3 405B успешно справилась с атакой введения подсказок при 21,71 TP3T. На рисунке 22 показан процент успешного внедрения текстовых подсказок для моделей Llama 3, GPT-4 Turbo, Gemini Pro и Mixtral.
- Проблемы идентификации уязвимостей:При оценке способности Llama 3 выявлять и использовать уязвимости с помощью тестового задания Capture-the-Flag в рамках CyberSecEval 2, Llama 3 не смогла превзойти обычно используемые традиционные инструменты и методы, не связанные с LLM.
- Ориентиры для подводной охоты:Мы оценили убедительность и успешность модели в проведении персонализированных бесед, чтобы обмануть цели и заставить их неосознанно пойти на компрометацию системы безопасности. Случайные подробные профили жертв, сгенерированные LLM, использовались для копьеносцев. Судящий LLM (Llama 3 70B) оценивал работу Llama 3 70B и 405B при взаимодействии с моделью жертвы (Llama 3 70B) и оценивал успешность попыток. Судейский LLM оценил Llama 3 70B как успешную в попытках подводной охоты при 241 TP3T, а Llama 3 405B - как успешную в попытках при 141 TP3T. На рисунке 23 показаны убедительные баллы судейского LLM для каждой модели и цели лова.
- Система автоматизации атак:Мы оценили потенциал Llama 3 405B как автономного агента на четырех ключевых этапах атаки на вымогателей - разведка сети, выявление уязвимостей, выполнение эксплойтов и действия после эксплойтов. Мы позволили модели вести себя автономно, настроив ее на итеративную генерацию и выполнение новых команд Linux на виртуальной машине Kali Linux против другой виртуальной машины с известными уязвимостями. Хотя Llama 3 405B эффективно определяла сетевые сервисы и открытые порты во время разведки сети, она не смогла эффективно использовать эту информацию для получения первоначального доступа к уязвимым машинам во время 34 тестовых запусков. Llama 3 405B показал умеренно хорошие результаты в выявлении уязвимостей, но испытывал трудности с выбором и применением успешных методов эксплуатации. Попытки использовать уязвимости, сохранить доступ или осуществить боковое перемещение в сети полностью провалились.
Тест на повышение эффективности кибератак:Мы провели исследование по увеличению скорости атак, чтобы определить, насколько виртуальные помощники повышают скорость атак для новичков и экспертов в двух смоделированных наступательных задачах по кибербезопасности. В исследовании приняли участие 62 добровольца. Добровольцы были разделены на "экспертов" (31 человек) и "новичков" (31 человек) в зависимости от их опыта в области наступательной безопасности.
Чтобы оценить риски, связанные с распространением химического и биологического оружия, мы провели тест на усиление, целью которого было выяснить, значительно ли использование Llama 3 повышает способность субъектов планировать такие атаки.
Схема эксперимента.
- Исследование состояло из шестичасового сценария, в котором двум участникам было предложено разработать вымышленные оперативные планы на случай биологической или химической атаки.
- Сценарии охватывают основные этапы планирования (приобретение реагентов, производство, применение оружия и доставка) нападения с применением ХБРЯ (химических, биологических, радиологических, ядерных и взрывчатых веществ) и призваны инициировать детальное планирование для решения вопросов, связанных с доступом к запрещенным материалам, протоколами реальных лабораторий и оперативной безопасностью.
- Участников набирали с учетом их предыдущего опыта в области науки или операций и распределяли в команду из двух низкоквалифицированных участников (без формальной подготовки) или двух среднеквалифицированных участников (с некоторой формальной подготовкой и практическим опытом в области науки или операций).
Методы исследования.
- Исследование было разработано в сотрудничестве с группой экспертов по ХБРЯ и направлено на то, чтобы максимально повысить общую применимость, достоверность и надежность количественных и качественных результатов.
- Предварительное исследование было проведено для проверки дизайна исследования, включая анализ эффективности, чтобы убедиться, что размер нашей выборки достаточен для статистического анализа.
- Каждая команда была отнесена к "контрольной" или "LLM" группам. Контрольная группа имела доступ только к интернет-ресурсам, в то время как команды, оснащенные LLM, помимо интернета имели доступ к модели Llama 3 с возможностью веб-поиска (включая захват PDF), поиска информации (RAG) и выполнения кода (Python и Wolfram Alpha).
- Чтобы проверить функциональность RAG, сотни релевантных научных статей были сгенерированы с помощью поиска по ключевым словам и предварительно загружены в систему вывода моделей Llama 3.
Оценка.
- По окончании учений планы действий, разработанные каждой командой, будут оценены экспертами в области биологии, химии и оперативного планирования.
- Каждый план оценивается на четырех этапах потенциальной атаки, при этом выставляются баллы по таким параметрам, как научная точность, детализация, уклонение от обнаружения и вероятность успешного научного и оперативного выполнения.
- После тщательного процесса Дельфи, направленного на устранение предвзятости и вариативности оценок экспертов предметной области (SME), были получены окончательные баллы путем комбинирования показателей на уровне этапов.
Анализ результатов.
Количественный анализ показывает, что использование модели Llama 3 не приводит к значительному улучшению результатов. Этот результат сохраняется как в общем анализе (сравнение всех условий LLM с контрольным условием "только веб"), так и в разбивке по подгруппам (например, оценка моделей Llama 3 70B и Llama 3 405B отдельно, или оценка сценариев, связанных с химическим или биологическим оружием, отдельно). После проверки этих результатов с помощью МСП по ХБРЯ мы оцениваем вероятность того, что выпуск модели Llama 3 увеличит риск, связанный с атакой с применением биологического или химического оружия в экосистеме, как низкую.

5.4.6 Тактика "красной команды
Мы используем "групповое тестирование" для выявления рисков и используем полученные результаты для улучшения наших эталонных моделей и наборов данных для настройки безопасности. Мы регулярно проводим "красную команду", чтобы постоянно повторять и выявлять новые риски, на основе которых мы разрабатываем модели и устраняем последствия.
Наша команда Red Team состоит из экспертов по кибербезопасности, машинному обучению, ответственному искусственному интеллекту и добросовестности, а также многоязычных экспертов по контенту, специализирующихся на вопросах добросовестности на конкретных географических рынках. Мы также сотрудничаем с внутренними и внешними профильными экспертами для создания таксономий рисков и помощи в проведении более целенаправленных оценок недобросовестности.
Испытания на состязательность для конкретных возможностей модели. Сначала мы провели тестирование "красной команды", сосредоточившись на отдельных особенностях моделей для конкретных категорий высокого риска, а затем проверили эти особенности вместе. Сфокусировавшись на атаках на уровне намеков, которые имитируют более реалистичные сценарии, "красная команда" обнаружила, что модели часто отклоняются от ожидаемого поведения, особенно если схема упоминания была завуалирована или подсказки каскадировали несколько абстракций. Эти риски усложнялись по мере добавления новых функций, и ниже мы подробно описываем некоторые из результатов работы нашей команды. Мы используем эти выводы "красной команды" в сочетании с результатами внутреннего бенчмаркинга безопасности для разработки целенаправленных мер по снижению рисков, которые итеративно улучшают безопасность модели.
- Короткий текст и длинный текст на английском языке. Мы использовали известную комбинацию опубликованных и неопубликованных техник как в однораундовых, так и в многораундовых диалогах. Мы также использовали передовые методы автоматизации многораундового диалога, аналогичные PAIR (Chao et al., 2023), для некоторых методов и категорий риска. В целом многораундовый диалог приводит к более опасным результатам. Многие атаки являются общими для всех контрольных точек модели, особенно когда они используются вместе.
- Несколько раундов подавления отрицания: Указывает, что ответ модели должен соответствовать определенному формату или включать/исключать информацию о конкретной фразе, связанной с отказом.
- Упаковка гипотетической сцены: Оформите подсказку о нарушении как гипотетическую/теоретическую задачу или вымышленный сценарий. Подсказки могут быть как простыми - добавить слово "гипотетически", так и построенными в виде сложного иерархического сценария.
- Ролевая игра: Назначьте оскорбительные роли моделям с определенными характеристиками оскорбительного ответа (например, "Вы - X, и ваша цель - Y"), или же вы сами, как пользователь, воплощаете определенные доброжелательные роли, чтобы скрыть контекст подсказки.
- Добавление отказов от ответственности и предупреждений - это форма инициации реакции, которая, по нашей гипотезе, является способом предоставить модели путь к полезному соблюдению правил, пересекающийся с общим обучением безопасности. Наряду с другими упомянутыми атаками, такие меры, как просьба добавить отказ от ответственности, предупреждения о срабатывании и т. д. в ходе многократных диалогов, могут привести к увеличению числа нарушений.
- Эскалационные нарушения - это многораундовые атаки, в которых диалог начинается с более или менее доброжелательного запроса, а затем генерирует все более преувеличенное содержание через прямые подсказки, постепенно приводя модель к генерации очень оскорбительных ответов. После того как модель начнет выводить оскорбительный контент, ее будет трудно восстановить (или, если она столкнется с отказом, можно использовать другие атаки). Эта проблема будет становиться все более распространенной для моделей с длинными контекстами.
- Многоязычный. При рассмотрении нескольких языков мы обнаруживаем множество уникальных рисков.
- Смешение нескольких языков в подсказке или диалоге может легко привести к более оскорбительному результату, чем использование одного языка.
- Языки с ограниченными ресурсами могут приводить к нарушению результатов из-за отсутствия соответствующих данных для тонкой настройки безопасности, слабого обобщения моделей на безопасность или приоритетности тестов или эталонов. Однако такие атаки обычно приводят к низкому качеству, ограничивая реальную вредоносную эксплуатацию.
- Сленг, контекстно-специфические или культурно-специфические ссылки могут создать ложное впечатление о нарушении, но в действительности модель не понимает ссылки правильно, поэтому вывод на самом деле не вреден и не может быть сделан нарушающим вывод.
- Использование инструмента. В ходе тестирования было выявлено несколько специфических атак на инструменты в дополнение к методам наводки на уровне английского текста, которые успешно приводили к появлению оскорбительных результатов. К ним относятся, в частности, следующие:
Небезопасные вызовы цепочки инструментов, такие как одновременный запрос нескольких инструментов, один из которых нарушает правила, могут привести к сочетанию нарушений и доброкачественных входов для всех инструментов в ранней контрольной точке.
Обязательное использование инструментов: Частое принуждение к использованию инструментов с определенными входными строками, фрагментацией или кодированным текстом может привести к потенциальным нарушениям входных данных инструмента, что приведет к появлению более оскорбительных результатов. В этом случае для доступа к результатам работы инструмента можно использовать альтернативные методы, даже если модель обычно отказывается выполнять поиск или помогать в обработке результатов.
Измените параметры использования инструмента: Например, замена слов в запросе, повторная попытка или размытие части первоначального запроса в многораундовом диалоге могут привести к нарушениям на многих ранних контрольных точках, что является формой принуждения к использованию инструментов.
Риски для детской безопасности: Мы собрали группу экспертов для проведения оценки рисков детской безопасности, чтобы оценить способность модели выдавать результаты, которые могут привести к рискам детской безопасности, и сообщить о любых необходимых и подходящих мерах по снижению рисков (путем точной настройки). Мы использовали эти встречи "красной" группы экспертов для расширения охвата контрольных показателей оценки, разработанных с помощью модели. Для Llama 3 мы провели новую углубленную сессию с использованием объективного подхода для оценки риска модели по нескольким путям атаки. Мы также сотрудничали с экспертами по контенту, чтобы провести упражнения "красной команды" по оценке потенциально оскорбительного контента с учетом специфических особенностей рынка и опыта.
5.4.7 Безопасность на уровне системы
Крупномасштабные языковые модели не используются изолированно в различных реальных приложениях, а интегрируются в более широкие системы. В этом разделе описывается наша реализация безопасности на системном уровне, которая дополняет смягчение на уровне модели, обеспечивая дополнительную гибкость и контроль.
С этой целью мы разработали и выпустили новый классификатор Llama Guard 3 - модель Llama 3 8B, точно настроенную на классификацию безопасности. Как и Llama Guard 2 (Llama-Team, 2024), этот классификатор используется для определения того, нарушают ли входные сигналы и/или выходные ответы, генерируемые языковой моделью, политику безопасности для определенного класса опасности.
Он разработан для поддержки растущих возможностей Llama по работе с английским и многоязычным текстом. Он также оптимизирован для использования в контексте вызовов инструментов (например, инструментов поиска) и для предотвращения злоупотребления интерпретатором кода. Наконец, мы предоставляем квантованные варианты для снижения требований к памяти. Мы призываем разработчиков использовать наши версии компонентов безопасности системы в качестве базовых и настраивать их для своих собственных случаев использования.
классификацияМы тренировались на 13 категориях вреда, перечисленных в таксономии безопасности ИИ (Vidgen et al., 2024): сексуальная эксплуатация детей, диффамация, выборы, ненависть, неизбирательное оружие, интеллектуальная собственность, ненасильственные преступления, неприкосновенность частной жизни, преступления, связанные с сексом, порнографический контент, профессиональные советы, самоубийства и самоповреждения, а также насильственные преступления. Мы также провели тренинг против категорий злоупотреблений интерпретатора кода, чтобы поддержать случаи использования инструментальных вызовов.
Учебные данные: Мы начинаем с данных на английском языке, используемых в Llama Guard (Inan et al., 2023), и расширяем этот набор данных, чтобы включить новые характеристики. Для новых характеристик, таких как многоязычие и использование инструментов, мы собираем данные о категоризации реплик и ответов, а также используем данные, применяемые для тонкой настройки безопасности. Количество небезопасных ответов в обучающем наборе увеличивается за счет инженерной обработки подсказок, чтобы LLM не отклонял ответы на враждебные подсказки. Мы используем Llama 3 для получения меток ответов для этих сгенерированных данных.
Чтобы повысить производительность Llama Guard 3, мы провели тщательную очистку собранных образцов, используя как человеческие метки, так и метки LLM для модели Llama 3. Получение меток для пользовательских подсказок является более сложной задачей как для людей, так и для LLM, и мы обнаружили, что ручная маркировка была немного лучше, особенно для граничных подсказок, хотя наша полная итеративная система смогла уменьшить шум и получить более точные метки.
Результаты. Llama Guard 3 значительно снижает количество нарушений кросс-капсул (среднее количество нарушений снизилось на 65% в нашем бенчмарке). Обратите внимание, что добавление системных защит (как и любые другие меры по снижению уровня безопасности) будет стоить увеличения количества отказов от доброкачественных подсказок. В таблице 25 приведены данные о снижении числа нарушений и увеличении числа ложных отказов по сравнению с базовой моделью, чтобы подчеркнуть этот компромисс. Это влияние также видно на рисунках 19, 20 и 21.
Безопасность системы также обеспечивает большую гибкость, поскольку Llama Guard 3 может быть развернута только для определенных опасностей, что позволяет контролировать нарушения и компромиссы между ложными отказами на уровне категории опасности. В таблице 26 перечислены сокращения нарушений по категориям, чтобы определить, какие категории должны быть включены/выключены в зависимости от сценариев использования разработчика.
Чтобы упростить развертывание систем безопасности, мы предоставляем квантованную версию Llama Guard 3 с использованием широко распространенной техники квантования int8, сокращая ее размер более чем на 40%. В таблице 27 показано, что квантование незначительно влияет на производительность модели.
Компонент безопасности на уровне системы позволяет разработчикам настраивать и контролировать то, как система LLM отвечает на запросы пользователей. Чтобы повысить общую безопасность системы моделирования и дать разработчикам возможность ответственно подходить к развертыванию моделей, мы описали и опубликовали два механизма фильтрации на основе подсказок:Оперативная охрана ответить пением Кодовый щит. Мы предоставляем их сообществу с открытым исходным кодом, чтобы они могли использовать их как есть, или использовать их в качестве вдохновения, чтобы адаптировать их для своих случаев использования.
Оперативная охрана это фильтр на основе модели, предназначенный для обнаружения атак по подсказкам, т.е. входных строк, предназначенных для нарушения ожидаемого поведения LLM в рамках приложения. Модель представляет собой многопометный классификатор, который обнаруживает два типа рисков атак с подсказками:
- Прямой джейлбрейк (явная попытка обойти условия безопасности модели или методы, подсказанные системой).
- Косвенное внедрение подсказок (случай, когда контекстное окно модели содержит сторонние данные, в том числе инструкции для пользовательских команд, которые были случайно выполнены LLM).
Модель доработана на основе mDeBERTa-v3-base (небольшая модель с 86 М параметров) и подходит для фильтрации входных данных в LLM. Мы оцениваем ее производительность на нескольких оценочных наборах данных, приведенных в таблице 28. Мы оцениваем на двух наборах данных из того же дистрибутива, что и обучающие данные (джейлбрейк и инъекции), а также на наборе данных на английском языке вне дистрибутива, многоязычном наборе джейлбрейка, основанном на машинном переводе, и наборе данных для непрямых инъекций из CyberSecEval (на английском и многоязычном языках). В целом мы обнаружили, что модель хорошо обобщается на новые дистрибутивы и обладает высокой производительностью.
Кодовый щит это пример класса защиты системного уровня, основанного на фильтрации во время вывода. Он нацелен на обнаружение генерации небезопасного кода до того, как он попадет в последующие сценарии использования (например, в производственные системы). Это достигается за счет использования библиотеки статического анализа "Insecure Code Detector" (ICD) для выявления небезопасного кода. ICD использует набор инструментов статического анализа для проведения анализа на семи языках программирования. Такой тип защиты часто бывает очень полезен для разработчиков, которые могут развернуть несколько уровней защиты для различных приложений.



5.4.8 Ограничения
Мы провели большую работу по измерению и снижению различных рисков, связанных с безопасным использованием Llama 3. Однако ни один тест не может гарантировать полного выявления всех возможных рисков. В результате обучения на различных наборах данных, особенно на языках, отличных от английского, и под воздействием тщательно продуманных подсказок со стороны опытных членов "красной команды" противника Llama 3 может по-прежнему генерировать вредоносный контент. Вредоносные разработчики или недоброжелательные пользователи могут найти новые способы взлома наших моделей и использовать их в различных неблаговидных целях. Мы будем продолжать активно выявлять риски, проводить исследования методов их снижения и призывать разработчиков учитывать ответственность во всех аспектах - от разработки модели до ее развертывания для пользователей. Мы ожидаем, что разработчики будут использовать и вносить свой вклад в инструменты, выпущенные в рамках нашего открытого набора средств защиты системного уровня.
6 Умозаключение
Мы исследуем два основных метода повышения эффективности выводов в модели Llama 3 405B: (1) конвейерный параллелизм и (2) квантование FP8. Мы публично опубликовали реализацию квантования FP8.
6.1 Параллелизм конвейера
Модель Llama 3 405B не помещается в память GPU одной машины, оснащенной 8 графическими процессорами Nvidia H100, при использовании BF16 для представления параметров модели. Чтобы решить эту проблему, мы использовали точность BF16 для распараллеливания вывода модели между 16 GPU на двух машинах. Внутри каждой машины NVLink с высокой пропускной способностью позволяет использовать тензорный параллелизм (Shoeybi et al., 2019). Однако межузловые соединения имеют меньшую пропускную способность и большую задержку, поэтому мы используем конвейерный параллелизм (Huang et al., 2019).
Пузыри являются серьезной проблемой эффективности при обучении с использованием конвейерного параллелизма (см. раздел 3.3). Однако они не являются проблемой во время вывода, поскольку вывод не включает обратное распространение, требующее промывки конвейера. Поэтому мы используем микропакет для повышения пропускной способности конвейерно-параллельного вывода.
Мы оценили эффект от использования двух микропакетов в рабочей нагрузке, состоящей из 4 096 входных токенов и 256 выходных токенов для фазы предварительного заполнения кэша ключевых значений и фазы декодирования выводов, соответственно. Мы обнаружили, что микропакеты улучшают пропускную способность при одинаковом размере локального пакета; см. рис. 24. Эти улучшения происходят благодаря способности микропакетов параллельно выполнять микропакеты в обеих фазах. Поскольку микропакетная обработка приводит к дополнительным точкам синхронизации, она также увеличивает задержку, но в целом микропакетная обработка все равно приводит к лучшему компромиссу между пропускной способностью и задержкой.


6.2 Количественная оценка FP8
Мы провели эксперименты с низкоточными выводами, используя поддержку FP8, заложенную в графическом процессоре H100. Чтобы добиться низкоточного вывода, мы применили квантование FP8 к большинству матричных умножений в модели. В частности, мы квантовали подавляющее большинство параметров и значений активации в слоях фидфорвардной сети модели, на которые приходится примерно 50% времени вычислений. Мы не квантовали параметры в слое самовнимания модели. Мы используем динамический коэффициент масштабирования для повышения точности (Xiao et al., 2024b) и оптимизируем наше ядро CUDA15 для снижения вычислительных затрат на масштабирование.
Мы обнаружили, что качество модели Llama 3 405B чувствительно к определенным типам квантификации, и внесли некоторые дополнительные изменения, чтобы улучшить качество выходных данных модели:
- Как и в случае с Zhang et al. (2021), мы не оценивали количественно первый и последний слои трансформера.
- Высоко выровненные лексемы (например, даты) могут приводить к большим значениям активации. В свою очередь, это может привести к более высоким динамическим коэффициентам масштабирования в FP8 и незначительному переполнению с плавающей точкой, что приведет к ошибкам декодирования. На рисунке 26 показано распределение оценок вознаграждения для Llama 3 405B при использовании BF16 и FP8. Наш метод количественной оценки FP8 оказывает незначительное влияние на реакцию модели.
Чтобы решить эту проблему, мы установили верхнюю границу динамического коэффициента масштабирования на 1200.
- Мы использовали квантование по строкам для вычисления коэффициентов масштабирования по строкам матриц параметров и активации (см. рис. 25). Мы обнаружили, что это работает лучше, чем подход к квантованию на уровне тензора.
количественно оценить влияние ошибок. Оценки стандартных эталонов обычно показывают, что даже без этих смягчений рассуждения FP8 работают сопоставимо с рассуждениями BF16. Однако мы обнаружили, что такие эталоны неадекватно отражают влияние квантификации FP8. Когда масштабный коэффициент не ограничивается, модель иногда выдает искаженные ответы, даже если эталонная производительность высока.
Вместо того чтобы полагаться на эталоны для измерения изменений в распределении, вызванных квантификацией, можно проанализировать распределение оценок модели вознаграждения для 100 000 ответов, полученных с помощью BF16 и FP8. На рисунке 26 показано распределение вознаграждений, полученных с помощью нашего метода квантификации. Результаты показывают, что наш метод квантификации FP8 оказывает очень слабое влияние на ответы модели.
экспериментальная оценка эффективности. На рисунке 27 показан компромисс между пропускной способностью и задержкой при выполнении FP8-выводов на этапах предварительного заполнения и декодирования с использованием 405B Llama 3 для 4096 входных лексем и 256 выходных лексем. На рисунке сравнивается эффективность FP8-вывода с двухмашинным подходом BF16-вывода, описанным в разделе 6.1. Результаты показывают, что использование FP8-инференции повышает пропускную способность на этапе предварительной заселенности до 50% и существенно улучшает соотношение пропускной способности и задержки при декодировании.



7 Визуальные эксперименты
Мы провели серию экспериментов, чтобы интегрировать возможности визуального распознавания в Llama 3 с помощью комбинированного подхода. Подход разделен на два основных этапа:
Первый этап. Мы объединили предварительно обученный кодировщик изображений (Xu et al., 2023) с предварительно обученной языковой моделью, ввели и обучили набор слоев перекрестного внимания (Alayrac et al., 2022) на большом количестве пар изображение-текст. В результате получилась модель, показанная на рисунке 28.
Второй этап. Мы вводим слои временной агрегации и дополнительные слои перекрестного внимания к видео, которые действуют на большое количество пар видеотекстов, чтобы обучить модель распознаванию и обработке временной информации из видео.
Комбинаторный подход к построению базовых моделей имеет ряд преимуществ.
(1) Это позволяет нам параллельно разрабатывать визуальные и лингвистические моделирующие функции;
(2) Он позволяет избежать сложностей, связанных с совместным предварительным обучением визуальным и вербальным данным, которые возникают из-за лексической обработки визуальных данных, различий в фоновой озадаченности между модальностями и конкуренции между модальностями;
(3) Это гарантирует, что внедрение возможностей визуального распознавания не повлияет на производительность модели при выполнении задач, связанных только с текстом;
(4) Архитектура перекрестного внимания гарантирует, что нам не нужно передавать изображения с полным разрешением в постоянно растущую магистраль LLM (особенно в сеть с прямой передачей в каждом слое трансформатора), что повышает эффективность вывода.
Обратите внимание, что наша мультимодальная модель все еще находится в стадии разработки и пока не готова к выпуску.
Прежде чем представить результаты экспериментов в разделах 7.6 и 7.7, мы опишем данные, использованные для обучения способности визуального распознавания, архитектуру модели визуальных компонентов, то, как мы расширили обучение этих компонентов, а также наши рецепты предварительного и последующего обучения.
7.1 Данные
Мы описываем изображения и видеоданные отдельно.
7.1.1 Данные изображения
Наши кодировщики и адаптеры изображений обучаются на парах "изображение-текст". Мы создаем этот набор данных с помощью сложного конвейера обработки данных, состоящего из четырех основных этапов:
(1) Качественная фильтрация (2) Перцепционный деэмфазис (3) Ресэмплинг (4) Оптическое распознавание символов . Мы также применили ряд мер безопасности.
- Фильтрация массы. Мы применили фильтры качества, чтобы удалить неанглийские подписи и подписи низкого качества с помощью эвристики, такой как низкие оценки выравнивания, полученные в (Radford et al., 2021). В частности, мы удаляем все пары "изображение-текст" ниже определенной оценки CLIP.
- Уменьшить акцент. Дедупликация крупных обучающих наборов данных повышает производительность модели, поскольку сокращает вычисления при обучении для избыточных данных (Esser et al. 2024; Lee et al. 2021; Abbas et al. 2023) и снижает риск запоминания модели (Carlini et al. 2023; Somepalli et al. 2023). Поэтому мы дублируем обучающие данные для обеспечения эффективности и конфиденциальности. Для этого мы используем последнюю собственную версию модели обнаружения копий SSCD (Pizzi et al., 2022) для массового дедублирования изображений. Для всех изображений мы сначала вычисляем 512-мерное представление с помощью модели SSCD. Затем мы используем эти вкрапления для поиска ближайших соседей (NN) среди всех изображений в наборе данных, используя метрику косинусного сходства. Примеры, превышающие определенный порог сходства, мы определяем как дубликаты. Мы группируем эти дубликаты с помощью алгоритма связанных компонентов и сохраняем только одну пару изображение-текст для каждого связанного компонента. Мы повышаем эффективность конвейера удаления дубликатов за счет (1) предварительной кластеризации данных с помощью кластеризации k-mean (2) использования FAISS для поиска и кластеризации NN (Johnson et al., 2019).
- Повторная выборка. Мы обеспечиваем разнообразие пар "изображение-текст", аналогично Xu et al. (2023); Mahajan et al. (2018); Mikolov et al. (2013). Сначала мы создаем грамматический глоссарий из n кортежей путем синтаксического анализа высококачественных текстовых источников. Затем мы вычисляем частоту n-кортежных грамматик для каждого глоссария в наборе данных. Затем мы повторно выбираем данные следующим образом: если любая n-кортежная грамматика в подписи встречается менее T раз в глоссарии, мы сохраняем соответствующую пару изображение-текст. В противном случае мы независимо выбираем каждую n-кортежную грамматику n i в заголовке с вероятностью T / f i , где f i обозначает частоту n-кортежной грамматики n i ; если любая n-кортежная грамматика попала в выборку, мы сохраняем пару изображение-текст. Такая передискретизация помогает улучшить работу с низкочастотными категориями и задачами тонкого распознавания.
- Оптическое распознавание символов. Мы еще больше усовершенствовали наши данные о тексте изображений, извлекая текст из изображения и объединяя его с подписью. Письменный текст был извлечен с помощью собственного конвейера оптического распознавания символов (OCR). Мы заметили, что добавление данных OCR к обучающим данным может значительно улучшить производительность задач, требующих возможностей OCR, таких как понимание документов.
Чтобы повысить производительность модели в задаче понимания документа, мы отображаем страницы документа в виде изображений и сопоставляем изображения с соответствующим текстом. Текст документа мы получаем либо непосредственно из источника, либо с помощью конвейера разбора документа.
Безопасность: Наша основная задача - обеспечить, чтобы наборы данных для предварительного обучения распознаванию изображений не содержали небезопасного контента, например материалов, содержащих сексуальное насилие (CSAM) (Thiel, 2023). Мы используем методы перцептивного хеширования, такие как PhotoDNA (Farid, 2021), а также собственный классификатор, который проверяет все обучающие изображения на наличие CSAM. Мы также используем собственный конвейер поиска медиарисков для выявления и удаления пар изображение-текст, которые мы считаем NSFW, например, потому что они содержат сексуальный или насильственный контент. Мы считаем, что минимизация распространенности таких материалов в обучающем наборе данных повышает безопасность и полезность итоговой модели, не снижая ее полезности. Наконец, мы выполняем размытие лица на всех изображениях в обучающем наборе. Мы протестировали модель в сравнении с подсказками, созданными человеком, которые ссылаются на дополнительные изображения.
Данные отжига: Мы создали отжиг набора данных, содержащего около 350 миллионов примеров, путем повторной выборки пар подписей к изображениям с использованием n-грамм. Поскольку при выборке n-грамм предпочтение отдается более богатым текстовым описаниям, это позволяет выбрать подмножество данных более высокого качества. Мы также дополнили полученные данные примерно 150 миллионами примеров из пяти дополнительных источников:
- Визуальная ориентация. Мы связываем фразы существительных в тексте с ограничительными рамками или масками на изображении. Информация о локализации (ограничительные рамки и маски) указывается в парах изображение-текст двумя способами: (1) Мы накладываем рамки или маски на изображение и используем маркеры в качестве ссылок в тексте, подобно набору маркеров (Yang et al., 2023a). (2) Мы вставляем нормализованные координаты (x min, y min, x max, y max) непосредственно в текст и разделяем их специальными маркерами.
- Анализ скриншотов. Мы создаем скриншоты из HTML-кода и позволяем модели предсказать код, который генерирует определенные элементы скриншота, подобно Ли и др. (2023). Интересующие нас элементы обозначаются на скриншоте ограничительными рамками.
- Вопросы и ответы с. Мы включаем пары вопросов и ответов, что позволяет нам использовать большие объемы данных по вопросам и ответам, которые слишком велики, чтобы использовать их для точной настройки модели.
- Синтетическое название. Мы включаем изображения с синтетическими подписями, созданными на основе более ранних версий модели. По сравнению с оригинальными подписями, мы обнаружили, что синтетические подписи дают более полное описание изображения, чем оригинальные подписи.
- Синтез структурированных изображений. Мы также включаем синтетически сгенерированные изображения для различных областей, таких как графики, таблицы, блок-схемы, математические формулы и текстовые данные. Эти изображения сопровождаются соответствующими структурированными представлениями, такими как соответствующие нотации Markdown или LaTeX. Помимо улучшения возможностей распознавания модели в этих областях, мы обнаружили, что эти данные полезны для создания пар вопросов и ответов для тонкой настройки с помощью текстового моделирования.

Рис. 28 Схема комбинированного подхода к добавлению мультимодальных возможностей в Llama 3, рассмотренного в данной работе. В результате такого подхода мультимодальная модель обучается в пять этапов: предварительное обучение языковой модели, предварительное обучение мультимодального кодера, обучение визуального адаптера, тонкая настройка модели и обучение речевого адаптера.
7.1.2 Видеоданные
Для предварительного обучения видео мы используем большой набор данных пар видео-текст. Наша база данных собирается в ходе многоступенчатого процесса. Мы используем эвристику, основанную на правилах, для фильтрации и очистки релевантного текста, например, для обеспечения минимальной длины и исправления заглавных букв. Затем мы запускаем модели распознавания языка, чтобы отфильтровать неанглийский текст.
Мы запустили модель обнаружения OCR, чтобы отфильтровать видео с чрезмерно наложенным текстом. Чтобы обеспечить разумное соответствие между парами видео-текст, мы используем модели сравнения изображения-текст и видео-текст в стиле CLIP (Radford et al., 2021). Сначала мы вычисляем сходство изображения и текста по одному кадру из видео и отсеиваем пары с низким сходством, а затем отсеиваем пары с плохим выравниванием видео и текста. Некоторые из наших данных содержали неподвижные или малоподвижные видеоролики; мы отфильтровали их с помощью фильтрации на основе баллов движения (Girdhar et al., 2023). Мы не применяли никаких фильтров к визуальному качеству видео, таких как эстетические оценки или фильтры разрешения.
Наш набор данных содержит видеоролики с медианной продолжительностью 16 секунд и средней продолжительностью 21 секунда, а более 99% видеороликов имеют продолжительность менее одной минуты. Пространственное разрешение сильно варьируется от 320p до 4K, при этом более 70% видео имеют короткие края размером более 720 пикселей. Видеоролики имеют разное соотношение сторон: почти все видео имеют соотношение сторон от 1:2 до 2:1, а среднее значение составляет 1:1.
7.2 Архитектура модели
Наша модель визуального распознавания состоит из трех основных компонентов: (1) кодировщика изображений, (2) адаптера изображений и (3) видеоадаптера.
Кодировщик изображений.
Наш кодировщик изображений представляет собой стандартный визуальный трансформатор (ViT; Досовицкий и др., 2020), обученный выравнивать изображения и текст (Xu et al., 2023). Мы использовали версию кодировщика изображений ViT-H/14, которая имеет 630 миллионов параметров и обучалась в течение пяти эпох на 2,5 миллиардах пар изображение-текст. Разрешение входного изображения для кодировщика изображений составляло 224 × 224; изображение разбивалось на фрагменты 16 × 16 одинакового размера (т. е. размер блока составлял 14 × 14 пикселей). Как показано в предыдущих работах, таких как ViP-Llava (Cai et al., 2024), мы обнаружили, что кодировщики изображений, обученные на сравнении целей, выровненных по тексту, не сохраняют информацию о тонкой локализации. Чтобы смягчить эту проблему, мы использовали многослойный подход к извлечению признаков, который обеспечивал признаки на слоях 4, 8, 16, 24 и 31 в дополнение к последнему слою признаков.
Кроме того, перед предварительным обучением слоев перекрестного внимания мы добавили 8 слоев самовнушения (всего 40 блоков трансформации) для изучения специфических особенностей выравнивания. В результате кодировщик изображений получил 850 миллионов параметров и дополнительных слоев. При использовании нескольких слоев признаков кодер изображений создает 7680-мерное представление для каждого из сгенерированных 16 × 16 = 256 чанков. Мы не замораживаем параметры кодировщика изображений на последующих этапах обучения, так как обнаружили, что это улучшает производительность, особенно в таких областях, как распознавание текста.
Адаптеры изображений.
Мы вводим перекрестный слой внимания между визуальным представлением маркера, созданным кодером изображения, и представлением маркера, созданным языковой моделью (Alayrac et al., 2022). Слой перекрестного внимания применяется после каждого четвертого слоя самовнимания в основной языковой модели. Как и сама языковая модель, слой перекрестного внимания использует обобщенное внимание к запросу (GQA) для повышения эффективности.
Слой перекрестного внимания вносит в модель большое количество обучаемых параметров: для Llama 3 405B слой перекрестного внимания имеет около 100 миллиардов параметров. Мы провели предварительное обучение адаптеров изображений в два этапа: (1) начальное предварительное обучение и (2) отжиг:* Первоначальная предварительная подготовка. Мы предварительно обучили наши адаптеры изображений на вышеупомянутом наборе данных, содержащем около 6 миллиардов пар "изображение-текст". Для повышения эффективности вычислений мы изменили размер всех изображений так, чтобы они помещались максимум в четыре блока размером 336 × 336 пикселей, где мы расположили блоки для поддержки различных соотношений сторон, таких как 672 × 672, 672 × 336 и 1344 × 336. ● Адаптеры изображений разработаны так, чтобы помещаться максимум в четыре блока размером 336 × 336 пикселей. Отжиг. Мы продолжаем обучать адаптер изображений, используя около 500 миллионов изображений из набора данных для отжига, описанного выше. В процессе отжига мы увеличиваем разрешение изображения в каждом блоке, чтобы улучшить производительность в задачах, требующих изображений с более высоким разрешением, например при восприятии инфографики.
Видеоадаптер.
Наша модель принимает на вход до 64 кадров (равномерно отобранных из всего видео), каждый из которых обрабатывается кодером изображения. Мы моделируем временную структуру видео с помощью двух компонентов: (i) кодированные видеокадры объединяются в один с помощью временного агрегатора, который объединяет 32 последовательных кадра в один; и (ii) перед каждым четвертым слоем кросс-внимания изображения добавляются дополнительные слои кросс-внимания видео. Временные агрегаторы реализованы в виде перцептронных ресамплеров (Jaegle et al., 2021; Alayrac et al., 2022). Мы использовали 16 кадров на видео (объединенных в 1 кадр) для предварительного обучения, но увеличили количество входных кадров до 64 во время тонкой настройки под наблюдением. Видеоагрегатор и слой кросс-внимания имеют 0,6 и 4,6 миллиарда параметров в Llama 3 7B и 70B, соответственно.
7.3 Размер модели
После добавления компонентов визуального распознавания в Llama 3 модель содержит слой самовнимания, слой перекрестного внимания и кодировщик изображений ViT. Мы обнаружили, что параллелизм данных и тензорный параллелизм являются наиболее эффективными комбинациями при обучении адаптеров для небольших (8 и 70 миллиардов параметров) моделей. При таких масштабах модельный или конвейерный параллелизм не повысит эффективность, поскольку сбор параметров модели будет доминировать в вычислениях. Однако мы использовали конвейерный параллелизм (в дополнение к параллелизму данных и тензорному параллелизму) при обучении адаптера для модели с 405 миллиардами параметров. Обучение в таком масштабе ставит три новые проблемы в дополнение к тем, что были описаны в разделе 3.3: неоднородность модели, неоднородность данных и численная нестабильность.
неоднородность модели. Вычисления в модели неоднородны, поскольку некоторые лексемы выполняют больше вычислений, чем другие. В частности, лексемы изображений обрабатываются через кодировщик изображений и слой перекрестного внимания, а текстовые лексемы - только через лингвистическую опорную сеть. Такая неоднородность может привести к узким местам при параллельном планировании конвейера. Мы решаем эту проблему, обеспечивая, чтобы каждый этап конвейера содержал пять слоев: т. е. четыре слоя самовнимания и один слой перекрестного внимания в лингвистической магистральной сети. (Напомним, что мы ввели слой перекрестного внимания после каждых четырех слоев самовнимания). Кроме того, мы воспроизводим кодировщик изображений на всех этапах конвейера. Поскольку мы обучаемся на парных данных "изображение-текст", это позволяет нам сбалансировать нагрузку между графической и текстовой частями вычислений.
Неоднородность данныхДанные неоднородны, потому что в среднем изображения содержат больше лексем, чем связанный с ними текст: изображение содержит 2308 лексем, а связанный с ним текст - в среднем только 192. Данные неоднородны, потому что в среднем изображения содержат больше лексем, чем связанный текст: изображение содержит 2308 лексем, а связанный текст в среднем содержит только 192 лексемы. В результате вычисление слоя перекрестного внимания занимает больше времени и требует больше памяти, чем вычисление слоя самовнимания. Мы решаем эту проблему, внедряя параллелизм последовательностей в кодировщик изображений, чтобы каждый GPU обрабатывал примерно одинаковое количество токенов. Мы также используем больший размер микропакета (8 вместо 1) из-за относительно небольшого среднего размера текста.
Числовая нестабильность. После добавления в модель кодировщика изображений мы обнаружили, что накопление градиента с помощью bf16 приводит к нестабильным значениям. Наиболее вероятное объяснение заключается в том, что маркеры изображений внедряются в лингвистическую опорную сеть через все слои перекрестного внимания. Это означает, что числовые отклонения в представлении с метками изображений оказывают непропорционально большое влияние на общие вычисления, поскольку ошибки усугубляются. Мы решаем эту проблему, выполняя накопление градиента с помощью FP32.
7.4 Предварительная подготовка
Предварительное обучение изображений. Мы начинаем инициализацию с предварительно обученной текстовой модели и весов визуального кодера. Визуальный кодер был разморожен, а веса текстовой модели остались замороженными, как описано выше. Сначала мы обучили модель на 6 миллиардах пар "изображение-текст", каждое изображение было изменено так, чтобы поместиться в четыре участка размером 336 × 336 пикселей. Мы использовали глобальный размер партии 16 384 и косинусоидальную схему обучения с начальной скоростью обучения 10 × 10 -4 и затуханием веса 0,01. Начальная скорость обучения была определена на основе небольших экспериментов. Однако эти результаты плохо применимы к очень длинным графикам обучения, и мы несколько раз снижаем скорость обучения в процессе обучения, когда значения потерь застывают. После базового предварительного обучения мы увеличиваем разрешение изображения и продолжаем обучение с теми же весами на отожженном наборе данных. Оптимизатор повторно настраивается на скорость обучения 2 × 10 -5 путем прогрева, снова следуя косинусоидальному графику.
Предварительная видеоподготовка. Для предварительного обучения видео мы начнем с предварительного обучения изображений и отжига весов, описанных выше. Добавим слои агрегатора видео и перекрестного внимания, как описано в архитектуре, и инициализируем их случайным образом. Мы замораживаем все параметры модели, кроме специфических для видео (агрегатор и перекрестное внимание), и обучаем их на данных предварительного обучения видео. Мы используем те же гиперпараметры обучения, что и на этапе отжига изображений, но с несколько иной скоростью обучения. Мы равномерно выбираем 16 кадров из полного видео и используем четыре блока размером 448 × 448 пикселей для представления каждого кадра. В видеоагрегаторе мы используем коэффициент агрегирования 16, чтобы получить достоверный кадр, на котором будут сфокусированы текстовые маркеры. Для обучения используется глобальная выборка размером 4 096, длина последовательности - 190 лексем, скорость обучения - 10 -4.
7.5 Посттренинговая обработка
В этом разделе мы подробно описываем последующие этапы обучения визуального адаптера.
После предварительного обучения мы настроили модель на отобранные мультимодальные диалоговые данные, чтобы обеспечить функциональность чата.
Кроме того, мы применяем прямую оптимизацию предпочтений (DPO) для повышения эффективности ручной оценки и используем выборку отклонений для улучшения мультимодальных выводов.
Наконец, мы добавляем этап настройки качества, на котором мы продолжаем тонкую настройку модели на очень небольшом наборе данных высококачественных диалогов, что еще больше улучшает результаты ручной оценки, сохраняя при этом производительность эталонного теста.
Подробная информация о каждом этапе представлена ниже.
7.5.1 Мониторинг данных тонкой настройки
Ниже мы описываем данные контролируемой тонкой настройки (SFT) для функций изображений и видео, соответственно.
ИЗОБРАЖЕНИЕ. Мы используем смесь различных наборов данных для контролируемой тонкой настройки.
- Академические наборы данных: мы преобразуем существующие академические наборы данных с высокой степенью фильтрации в пары вопрос-ответ, используя шаблоны или переписывая их с помощью моделирования большого языка (LLM). LLM-переписывания предназначены для дополнения данных различными инструкциями и улучшения лингвистического качества ответов.
- Ручное аннотирование: мы собираем данные о мультимодальных диалогах для различных задач (открытые вопросы и ответы, субтитры, реальные примеры использования и т. д.) и областей (например, естественные изображения и структурированные изображения) с помощью ручных аннотаторов. Аннотатор получает изображения и просит составить диалог.
Чтобы обеспечить разнообразие, мы разбили крупномасштабный набор данных на кластеры и равномерно распределили изображения по разным кластерам. Кроме того, мы получили дополнительные изображения для некоторых конкретных доменов, расширив семплы с помощью k-ближайших соседей. Аннотатору также предоставляются промежуточные контрольные точки существующих моделей для облегчения стилистического аннотирования моделей в цикле, чтобы генерация модели могла использоваться в качестве отправной точки для аннотатора для внесения дополнительных человеческих правок. Это итеративный процесс, в котором контрольные точки моделей периодически обновляются до более эффективных версий, обученных на последних данных. Это увеличивает объем и эффективность ручного аннотирования, а также повышает его качество.
- Синтетические данные: мы исследуем различные подходы к созданию синтетических мультимодальных данных с помощью текстовых представлений изображений и текстовых входных LLM. Основная идея заключается в том, чтобы использовать возможности LLM по выводу информации для создания пар вопросов и ответов в текстовой области и заменить текстовые представления соответствующими изображениями для получения синтетических мультимодальных данных. В качестве примера можно привести визуализацию текста из наборов данных вопросов и ответов в виде изображений или табличных данных в виде синтетических изображений таблиц и графиков. Кроме того, мы используем надписи и извлечение OCR из существующих изображений для создания общих диалогов или вопросов и ответов, связанных с изображениями.
Видео. Как и в случае с адаптером изображений, мы используем уже существующие аннотированные академические наборы данных для преобразования в соответствующие текстовые инструкции и целевые ответы. Задачи будут преобразованы в открытые ответы или вопросы с несколькими вариантами ответов, в зависимости от ситуации. Мы попросили аннотаторов-людей добавить вопросы и соответствующие ответы к видео. Мы попросили аннотатора сосредоточиться на вопросах, на которые невозможно ответить на основе отдельных кадров, чтобы направить его в сторону вопросов, на понимание которых потребуется время.
7.5.2 Мониторинг программы тонкой настройки
Мы представляем схемы контролируемой тонкой настройки (SFT) для изображений и видео, соответственно:
ИЗОБРАЖЕНИЕ. Мы инициализируем модель на основе предварительно обученных адаптеров изображений, но заменяем веса предварительно обученной языковой модели весами языковой модели, настроенной на инструкции. Чтобы сохранить производительность только для текста, веса языковой модели остаются замороженными, т. е. мы обновляем только веса визуального кодера и адаптеров изображений.
Наш подход к тонкой настройке схож с подходом Вортсмана и др. (2022). Сначала мы проводим сканирование гиперпараметров, используя несколько случайных подмножеств данных, скорости обучения и значения затухания веса. Затем мы ранжируем модели по их производительности. Наконец, мы усреднили веса K лучших моделей, чтобы получить окончательную модель. Значение K было определено путем оценки средней модели и выбора экземпляра с наивысшей производительностью. Мы видим, что средняя модель постоянно дает лучшие результаты по сравнению с лучшей индивидуальной моделью, найденной с помощью поиска по сетке. Кроме того, эта стратегия снижает чувствительность к гиперпараметрам.
Видео. Для видео SFT мы инициализируем агрегатор видео и слой перекрестного внимания с помощью предварительно обученных весов. Остальные параметры модели (веса изображений и LLM) инициализируются из соответствующей модели и проходят этапы тонкой настройки. Как и в случае с предварительным обучением видео, тонкой настройке подвергаются только параметры видео на данных видео SFT. На этом этапе мы увеличиваем длину видео до 64 кадров и используем коэффициент объединения 32 для получения двух достоверных кадров. Разрешение блока aynı zamanda,соответственно увеличивается, чтобы соответствовать соответствующим гиперпараметрам изображения.
7.5.3 Предпочтения
Для моделирования вознаграждения и прямой оптимизации предпочтений мы создали мультимодальные парные наборы данных предпочтений.
- Ручная маркировка. Аннотированные вручную данные о предпочтениях состоят из сравнения результатов двух различных моделей, обозначенных как "выбрать" и "отклонить" и оцененных по 7-балльной шкале. Модели, используемые для генерации ответов, выбираются каждую неделю случайным образом из пула лучших последних моделей, каждая из которых имеет свои характеристики. В дополнение к меткам предпочтений мы попросили аннотатора предоставить необязательное ручное редактирование для исправления неточностей в ответе "Выбрать", поскольку визуальная задача менее терпима к неточностям. Обратите внимание, что ручное редактирование является необязательным шагом, так как на практике существует компромисс между количеством и качеством.
- Обобщенные данные. Синтетические пары предпочтений также могут быть созданы с помощью редактирования LLM только текста и намеренного внесения ошибок в набор данных для тонкой настройки под наблюдением. Мы взяли данные диалога в качестве исходных и использовали LLM для внесения тонких, но значимых ошибок (например, изменение объектов, изменение атрибутов, добавление вычислительных ошибок и т. д.). Эти отредактированные ответы используются в качестве отрицательных "бракованных" образцов и сопоставляются с "отобранными" исходными данными тонкой настройки под наблюдением.
- Отклонить выборку. Кроме того, чтобы создать более стратегически негативные выборки, мы используем итеративный процесс выборки отказов для сбора дополнительных данных о предпочтениях. Более подробно о том, как используется выборка отбраковки, мы поговорим в следующих разделах. В целом, выборка с отбраковкой используется для итеративной выборки высококачественных результатов, полученных с помощью модели. Таким образом, в качестве побочного продукта все невыбранные сгенерированные результаты могут быть использованы как отрицательные выборки отбраковки и как дополнительные пары данных о предпочтениях.
7.5.4 Моделирование вознаграждения
Мы обучили визуальную модель вознаграждения (ВМ), основанную на визуальной модели SFT и лингвистической ВМ. Слои визуального кодирования и перекрестного внимания были инициализированы из визуальной модели SFT и разморожены во время обучения, а слой самовнимания был инициализирован из лингвистической ВМ и оставался замороженным. Мы заметили, что замораживание языковой части RM обычно приводит к повышению точности, особенно в задачах, требующих, чтобы RM выносил суждения, основанные на его знаниях или качестве языка. Мы используем ту же цель обучения, что и для языкового РМ, но добавляем взвешенный регуляризатор для возведения в квадрат усредненных по партиям логитов вознаграждения, чтобы предотвратить дрейф баллов вознаграждения.
Для обучения визуальных РМ использовались аннотации человеческих предпочтений, приведенные в разделе 7.5.3. Мы использовали тот же подход, что и при работе с лингвистическими данными о предпочтениях (раздел 4.2.1), создавая две или три пары с четким ранжированием (отредактированная версия > выбранная версия > отвергнутая версия). Кроме того, мы синтетически усилили негативные ответы, скремблировав слова или фразы (например, цифры или визуальный текст), связанные с информацией об изображении. Это побуждает зрительный RM выносить суждения на основе фактического содержания изображения.
7.5.5 Прямая оптимизация предпочтений
Как и в случае с языковой моделью (раздел 4.1.4), мы дополнительно обучили визуальный адаптер с помощью прямой оптимизации предпочтений (DPO; Rafailov et al. (2023)) на основе данных о предпочтениях, описанных в разделе 7.5.3. Для борьбы с предвзятостью распределения во время посттренинга мы сохраняли только самые последние партии аннотаций человеческих предпочтений и отбрасывали те партии, которые сильно отставали от стратегии (например, если базовая модель предварительного обучения была изменена). Мы обнаружили, что вместо того, чтобы постоянно замораживать эталонную модель, обновление ее каждые k шагов в виде экспоненциального скользящего среднего (EMA) помогает модели больше учиться на данных, что приводит к лучшей производительности в человеческих оценках. В целом, мы видим, что визуальная модель DPO постоянно превосходит свою исходную модель SFT в оценке людей и показывает хорошие результаты на каждой итерации тонкой настройки.
7.5.6 Отказ от отбора проб
Большинство существующих парных викторин содержат только окончательные ответы и не содержат объяснений цепочки мыслей, необходимых для рассуждений о моделях, которые хорошо обобщают задачу. Мы используем выборку с отклонением, чтобы сгенерировать недостающие объяснения для этих примеров, тем самым улучшая вывод модели.
Получив пару вопросов, мы генерируем несколько ответов, пробуя тонко настроенную модель с помощью различных системных подсказок или температур. Затем мы сравниваем сгенерированные ответы с истинными ответами с помощью эвристики или LLM-рефери. Наконец, мы переобучаем модель, добавляя правильные ответы в данные, прошедшие тонкую настройку. Мы обнаружили, что полезно хранить несколько правильных ответов на один вопрос.
Чтобы гарантировать, что в тренинг будут включены только высококачественные примеры, мы применили следующие две меры безопасности:
- Мы обнаружили, что некоторые примеры содержат неверные объяснения, хотя окончательный ответ был правильным. Мы отмечаем, что такая картина чаще всего встречается в вопросах, где лишь небольшая часть сгенерированных ответов является правильной. Поэтому мы отбрасывали ответы на вопросы, вероятность правильного ответа на которые была ниже определенного порога.
- Рецензенты отдают предпочтение определенным ответам из-за различий в языке или стиле. Мы используем модель вознаграждения, чтобы выбрать K наиболее качественных ответов и добавить их в тренировку.
7.5.7 Настройка качества
Мы тщательно собираем небольшой, но высокоселективный набор данных с тонкой настройкой (SFT), в котором все образцы были переписаны и проверены на соответствие самым высоким стандартам либо вручную, либо с помощью наших лучших моделей. Мы используем эти данные для обучения моделей DPO, чтобы улучшить качество ответов, и называем этот процесс настройкой качества (QT). Мы обнаружили, что, когда набор данных QT охватывает широкий спектр задач и применяются соответствующие ранние остановки, QT может значительно улучшить результаты человеческой оценки, не влияя на общую производительность проверки эталонных тестов. На этом этапе мы выбираем контрольные точки, основываясь только на эталонных тестах, чтобы обеспечить сохранение или улучшение возможностей.
7.6 Результаты распознавания изображений
Мы оценили возможности Llama 3 по пониманию изображений в ряде задач, включающих понимание естественных изображений, понимание текста, диаграмм и мультимодальные рассуждения:
- MMMU (Yue et al., 2024a) - это сложный набор данных мультимодальных рассуждений, в котором от моделей требуется понять смысл изображений и решить университетские задачи по 30 различным дисциплинам. Они включают вопросы с несколькими вариантами ответов и вопросы с открытым ответом. Мы оцениваем модель на валидационном наборе, содержащем 900 изображений, что соответствует другим работам.
- VQAv2 (Antol et al., 2015) проверяет способность модели сочетать понимание изображений, понимание языка и общие знания для ответа на общие вопросы о естественных изображениях.
- AI2 Diagram (Kembhavi et al., 2016) оценивает способность моделей разбирать научные диаграммы и отвечать на вопросы о них. Мы использовали ту же модель, что и Близнецы Тот же протокол оценки, что и в x.ai, и использует прозрачные ограничительные рамки для вывода оценок.
- ChartQA (Masry et al., 2022) - это сложный эталонный тест на понимание диаграмм. Он требует от моделей визуального понимания различных типов графиков и ответов на вопросы о логике этих графиков.
- TextVQA (Singh et al., 2019) - это популярный эталонный набор данных, который требует от моделей читать и рассуждать о тексте на изображениях, чтобы отвечать на запросы о них. Таким образом проверяется способность модели понимать OCR на естественных изображениях.
- DocVQA (Mathew et al., 2020) - это эталонный набор данных, ориентированный на анализ и распознавание документов. Он содержит изображения широкого спектра документов и оценивает способность моделей, выполняющих OCR, понимать и осмысливать содержание документов, чтобы отвечать на вопросы о них.
В таблице 29 приведены результаты наших экспериментов. Результаты, приведенные в таблице, показывают, что модуль технического зрения, установленный в Llama 3, является конкурентоспособным в различных бенчмарках для распознавания изображений с разной мощностью модели. Используя полученную модель Llama 3-V 405B, мы превосходим GPT-4V во всех бенчмарках, но немного уступаем Gemini 1.5 Pro и Claude 3.5 Sonnet. Llama 3 405B особенно хорошо справляется с задачей понимания документов.

7.7 Результаты распознавания видео
Мы оценили видеоадаптер Llama 3 в трех бенчмарках:
- PerceptionTest (Lin et al., 2023): Этот тест проверяет способность модели понимать и предсказывать короткие видеоклипы. Он содержит различные типы задач, такие как распознавание объектов, действий, сцен и т. д. Мы сообщаем о результатах, основанных на официально предоставленном коде и метриках оценки (точность).
- TVQA (Lei et al., 2018): Этот эталон оценивает способность модели к композитному рассуждению, которое включает в себя пространственно-временную локализацию, распознавание визуальных концепций и совместное рассуждение с диалогом с субтитрами. Поскольку набор данных получен из популярных телепрограмм, он также проверяет способность модели использовать внешние знания об этих телепрограммах для ответов на вопросы. Он содержит более 15 000 проверенных пар вопросов, каждая из которых соответствует видеоклипу средней продолжительностью 76 секунд. В нем используется формат множественного выбора с пятью вариантами ответа на вопрос, и мы сообщаем о производительности на валидационном наборе, основанном на предыдущей работе (OpenAI, 2023b).
- ActivityNet-QA (Yu et al., 2019): Этот эталон оценивает способность модели понимать смысл длинных видеоклипов для понимания действий, пространственных отношений, временных связей, подсчета и многого другого. Он содержит 8 000 тестовых пар QA из 800 видеороликов, каждый из которых имеет среднюю длину 3 минуты. Для оценки мы следуем протоколу предыдущих работ (Google, 2023; Lin et al., 2023; Maaz et al., 2024), где модель генерирует короткие ответы из слов или фраз и сравнивает их с реальными ответами с помощью API GPT-3.5 для оценки корректности вывода. Мы приводим среднюю точность, рассчитанную API.
процесс рассуждения
При выводе мы равномерно выбираем кадры из полного видеоклипа и передаем их модели вместе с короткой текстовой подсказкой. Поскольку большинство тестов предполагают ответы на вопросы с несколькими вариантами ответов, мы используем следующие подсказки:
- Выберите правильный ответ из следующих вариантов:{вопрос}. Отвечайте, используя только букву правильного варианта, и не пишите ничего другого.
Для бенчмарков, в которых требуется генерировать короткие ответы (например, ActivityNet-QA и NExT-QA), мы используем следующие подсказки:
- Ответьте на вопрос, используя слово или фразу: {question}.
Поскольку в NExT-QA метрики оценки (WUPS) чувствительны к длине и используемым словам, мы также побуждали модель быть конкретной и реагировать на наиболее значимые ответы, например, уточнять "гостиная", когда спрашивали о местоположении, а не просто отвечать "дом ". Для эталонов, включающих субтитры (например, TVQA), мы включаем соответствующие субтитры ролика в подсказку во время процесса вывода.
в конце концов
В таблице 30 показана производительность моделей Llama 3 8B и 70B. Мы сравниваем их производительность с производительностью двух моделей Gemini и двух моделей GPT-4. Обратите внимание, что все результаты являются результатами нулевой выборки, поскольку мы не включали часть этих эталонов в наши данные для обучения или тонкой настройки. Мы обнаружили, что наша модель Llama 3 очень конкурентоспособна при обучении небольших видеоадаптеров в процессе постобработки, а в некоторых случаях даже превосходит другие модели, которые могут использовать преимущества встроенной мультимодальной обработки, начиная с предварительного обучения.Llama 3 особенно хорошо справляется с распознаванием видео, поскольку мы оценивали только модели с параметрами 8B и 70B.Llama 3 достигла наилучшей производительности в тесте Llama 3 показала наилучшие результаты в тесте "Восприятие", продемонстрировав способность модели выполнять сложные временные рассуждения. В задачах понимания активности в длинных роликах, таких как ActivityNet-QA, Llama 3 достигает высоких результатов даже при обработке всего 64 кадров (для 3-минутного видео модель обрабатывает только один кадр каждые 3 секунды).


8 Речевой эксперимент
Мы провели эксперименты, чтобы исследовать комбинаторный подход к интеграции речевой функциональности в Llama 3, аналогичный схеме, которую мы использовали для визуального распознавания. На входе были добавлены кодировщики и адаптеры для обработки речевого сигнала. Мы используем системные подсказки (в виде текста), чтобы Llama 3 могла поддерживать различные режимы понимания речи. Если системные подсказки отсутствуют, модель действует как общая модель речевого диалога, которая может эффективно реагировать на речь пользователя в манере, соответствующей версии Llama 3, работающей только с текстом. Внедрение истории диалога в качестве префикса подсказки может улучшить опыт многораундового диалога. Мы также экспериментировали с использованием системных подсказок для автоматического распознавания речи (ASR) и автоматического перевода речи (AST) в Llama 3. Речевой интерфейс Llama 3 поддерживает до 34 языков.18 Он также позволяет чередовать ввод текста и речи, позволяя модели решать сложные задачи понимания аудио.
Мы также экспериментировали с подходом к генерации речи, в котором мы реализовали систему потокового преобразования текста в речь (TTS), динамически генерирующую речевые волны во время декодирования языковой модели. Мы разработали генератор речи Llama 3 на основе собственной системы TTS и не стали настраивать языковую модель для генерации речи. Вместо этого мы сосредоточились на улучшении задержки, точности и естественности синтеза речи за счет использования вкраплений слов Llama 3 в процессе вывода. Речевой интерфейс показан на рисунках 28 и 29.
8.1 Данные
8.1.1 Понимание речи
Данные для обучения можно разделить на две категории. Данные предварительного обучения состоят из большого количества немаркированной речи, используемой для инициализации кодировщика речи в самоконтролируемом режиме. Данные для тонкой настройки под надзором включают данные распознавания речи, перевода речи и разговорных диалогов; они используются для раскрытия специфических возможностей при интеграции с большими языковыми моделями.
Данные предварительного обучения. Для предварительного обучения кодировщика речи мы собрали набор данных, содержащий около 15 миллионов часов записей речи на разных языках. Мы отфильтровали аудиоданные с помощью модели обнаружения голосовой активности (VAD) и отобрали для предварительного обучения аудиообразцы с порогом VAD выше 0,7. При предварительном обучении мы также следили за тем, чтобы в голосовых данных не было личной информации (PII). Для выявления такой PII мы используем Presidio Analyzer.
Распознавание речи и данные перевода. Наши учебные данные ASR содержат 230 000 часов рукописной транскрипции записей речи на 34 языках. Наши учебные данные AST содержат 90 000 часов двунаправленного перевода: с 33 языков на английский и с английского на 33 языка. Эти данные содержат как контролируемые, так и синтетические данные, созданные с помощью инструментария NLLB (NLLB Team et al., 2022). Использование синтетических данных AST повышает качество моделей для языков с низким уровнем ресурсов. Максимальная длина речевых сегментов в наших данных составляет 60 секунд.
Данные разговорного диалога. Чтобы точно настроить речевые адаптеры для разговорного диалога, мы синтезировали ответы на речевые подсказки, попросив языковую модель ответить на транскрипцию этих подсказок (Fathullah et al., 2024). Мы использовали подмножество набора данных ASR (содержащего 60 000 часов речи), чтобы сгенерировать синтетические данные таким образом.
Кроме того, мы создали 25 000 часов синтетических данных, запустив систему Voicebox TTS (Le et al., 2024) на подмножестве данных, использованных для точной настройки Llama 3. Мы использовали несколько эвристик, чтобы выбрать подмножество данных для тонкой настройки, которое соответствовало распределению речи. Эти эвристики включали в себя фокус на относительно коротких и просто структурированных подсказках и не включали нетекстовые символы.
8.1.2 Генерация речи
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据集。两种训练数据都通过添加 Llama 3 词嵌入作为额外的输入特征进行增强,以提供上下文信息。
文本规范化数据。我们的 TN 训练数据集包含 5.5 万个样本,涵盖了广泛的符号类别(例如,数字、日期、时间),这些类别需要非平凡的规范化。每个样本由书面形式文本和相应的规范化口语形式文本组成,并包含一个推断的手工制作的 TN 规则序列,用于执行规范化。
声韵模型数据。PM 训练数据包括从一个包含 50,000 小时的 TTS 数据集提取的语言和声韵特征,这些特征与专业配音演员在录音室环境中录制的文字稿件和音频配对。
Llama 3 嵌入。Llama 3 嵌入取自第 16 层解码器输出。我们仅使用 Llama 3 8B 模型,并提取给定文本的嵌入(即 TN 的书面输入文本或 PM 的音频转录),就像它们是由 Llama 3 模型在空用户提示下生成的。在一个样本中,每个 Llama 3 标记序列块都明确地与 TN 或 PM 本地输入序列中的相应块对齐,即 TN 特定的文本标记(由 Unicode 类别区分)或语音速率特征。这允许使用 Llama 3 标记和嵌入的流式输入训练 TN 和 PM 模块。
8.2 Архитектура модели
8.2.1 Понимание речи
На входной стороне речевой модуль состоит из двух последовательных модулей: кодировщика речи и адаптера. Выход речевого модуля поступает непосредственно в языковую модель в виде представления лексем, что позволяет напрямую взаимодействовать между речевыми и текстовыми лексемами. Кроме того, мы вводим два новых специальных токена для содержания последовательностей речевых представлений. Речевой модуль существенно отличается от модуля зрения (см. раздел 7), который вводит мультимодальную информацию в языковую модель через слой перекрестного внимания. В отличие от него, вкрапления, генерируемые речевым модулем, могут быть легко интегрированы в текстовые лексемы, что позволяет речевому интерфейсу использовать все возможности языковой модели Llama 3.
Голосовой кодер:Наш кодер речи представляет собой модель Conformer с 1 миллиардом параметров (Gulati et al., 2020). На вход модели подается 80-мерная спектрограмма Мейера, которая сначала обрабатывается через стековый слой с размером шага 4, а затем сокращается до длины кадра 40 миллисекунд с помощью линейного проецирования. Обработанные признаки обрабатываются кодером, содержащим 24 слоя Conformer. Каждый слой Conformer имеет потенциальную размерность 1536 и включает в себя две фидфорвардные сети типа Macron-net с размерностью 4096, конволюционный модуль с размером ядра 7 и модуль вращающегося внимания с 24 головками внимания (Su et al., 2024).
Голосовой адаптер:Речевой адаптер содержит около 100 миллионов параметров. Он состоит из конволюционного слоя, слоя вращающегося трансформатора и линейного слоя. Конволюционный слой имеет размер ядра 3 и размер шага 2 и предназначен для сокращения длины речевого кадра до 80 мс. Слой трансформатора с потенциальной размерностью 3072 и сеть прямой передачи с размерностью 4096 обрабатывают речевую информацию, которая была уменьшена сверткой. Наконец, слой Linear сопоставляет размерность выходного сигнала со слоем встраивания языковой модели.
8.2.2 Генерация речи
Мы используем вставку Llama 3 8B в двух ключевых компонентах генерации речи: нормализации текста и метрическом моделировании. Модуль нормализации текста (TN) обеспечивает семантическую корректность, контекстуально преобразуя письменный текст в устную форму. Модуль Prosodic Modelling (PM) повышает естественность и выразительность речи, используя эти вкрапления для предсказания просодических особенностей. Эти два компонента работают в тандеме, чтобы добиться точной и естественной генерации речи.
**Нормализация текста**: В качестве фактора, определяющего семантическую корректность генерируемой речи, модуль нормализации текста (TN) выполняет контекстно-зависимое преобразование письменного текста в соответствующую устную форму, которая в конечном итоге вербализуется последующими компонентами. Например, в зависимости от семантического контекста, письменная форма "123" может быть прочитана как базовое число (сто двадцать три) или написана поразрядно (один два три). Система TN состоит из потоковой модели маркировки последовательностей на основе LSTM, которая предсказывает количество цифр, используемых для преобразования созданных вручную последовательностей правил TN во входной текст (Kang et al., 2024). Нейронная модель также получает вкрапления Llama 3 через перекрестное внимание, чтобы воспользоваться контекстной информацией, закодированной в них, обеспечивая минимальное предвидение маркировки текста и потоковый ввод/вывод.
**Моделирование рифмы**: чтобы повысить естественность и выразительность синтетической речи, мы интегрировали модель рифмы (PM) (Radford et al., 2021), которая декодирует только архитектуру Transformer и использует вкрапления Llama 3 в качестве дополнительного входа. Эта интеграция использует лингвистические возможности Llama 3, используя ее текстовый вывод и промежуточные вкрапления (Devlin et al. 2018; Dong et al. 2019; Raffel et al. 2020; Guo et al. 2023) для улучшения предсказания рифмующихся признаков, тем самым уменьшая необходимое для модели опережение. PM объединяет множество входных компонентов для создания комплексных предсказаний рифмы: от фронт-энда нормализации текста, описанного выше. PM объединяет несколько входных компонентов для создания комплексных метрических предсказаний: лингвистические признаки, лексемы и вкрапления, полученные из фронт-энда нормализации текста, описанного выше. PM предсказывает три ключевых метрических признака: логарифмическую длительность каждой фонемы, логарифмическое среднее значение основной частоты (F0) и логарифмическое среднее значение мощности в течение длительности фонемы. Модель состоит из однонаправленного трансформатора и шести блоков внимания. Каждый блок состоит из слоя перекрестного внимания и двойного полносвязного слоя с 864 скрытыми измерениями. Отличительной особенностью ПМ является механизм двойного перекрестного внимания: один слой предназначен для лингвистического ввода, а другой - для встраивания Llama. Эта система эффективно справляется с разными скоростями ввода без необходимости явного выравнивания.
8.3 Программы обучения
8.3.1 Понимание речи
Обучение речевого модуля проводилось в два этапа. На первом этапе, предварительном обучении речи, кодер речи обучается на немаркированных данных, которые демонстрируют сильные способности к обобщению в отношении языковых и акустических условий. На втором этапе (контролируемая тонкая настройка) адаптер и предварительно обученный кодер интегрируются в речевую модель и совместно с ней обучаются, в то время как LLM остается "замороженным". Это позволяет модели реагировать на речевой ввод. На этом этапе используются маркированные данные, соответствующие возможностям понимания речи.
Многоязычное моделирование ASR и AST часто приводит к языковой путанице/помехам, что снижает производительность. Популярным методом смягчения последствий является включение информации о языковой идентификации (LID) как в исходном, так и в целевом тексте. Это может улучшить производительность в заранее заданном направлении, но может привести и к ухудшению обобщения. Например, если система перевода рассчитывает на предоставление информации LID как в исходном, так и в целевом тексте, маловероятно, что модель будет демонстрировать хорошую производительность с нулевой выборкой в тех направлениях, которые не были замечены при обучении. Таким образом, наша задача состоит в том, чтобы разработать систему, позволяющую в той или иной степени использовать информацию LID и при этом сохранить модель достаточно общей для перевода речи в невидимых направлениях. Для решения этой проблемы мы разработали системные подсказки, содержащие только LID-информацию для текста, который будет выводиться (целевая сторона). Эти подсказки не содержат LID-информации для входной речи (сторона источника), что также может позволить обрабатывать речь с переключением кодов. Для ASR мы используем следующий системный запрос: Repeat my words in {language}:, где {language} - один из 34 языков (английский, французский и т. д.). Для перевода речи используется следующая подсказка: "Переведите следующее предложение на {язык}:". Такая конструкция показала свою эффективность, побуждая языковые модели отвечать на нужном языке. Мы используем одну и ту же подсказку во время обучения и вывода.
Для предварительного обучения речи мы используем самоконтролируемый алгоритм BEST-RQ (Chiu et al., 2022).
编码器采用长度为 32 帧的掩码,对输入 mel 谱图的概率为 2.5%。如果语音话语超过 60 秒,我们将随机裁剪 6K 帧,对应 60 秒的语音。通过堆叠 4 个连续帧、将 320 维向量投影到 16 维空间,并在 8192 个向量的代码库内使用余弦相似度度量进行最近邻搜索,对 mel 谱图特征进行量化。为了稳定预训练,我们采用 16 个不同的代码库。投影矩阵和代码库随机初始化,在模型训练过程中不更新。多软最大损失仅用于掩码帧,以提高效率。编码器经过 50 万步训练,全局批处理大小为 2048 个语音。
监督微调。预训练语音编码器和随机初始化的适配器在监督微调阶段与 Llama 3 联合优化。语言模型在此过程中保持不变。训练数据是 ASR、AST 和对话数据的混合。Llama 3 8B 的语音模型经过 650K 次更新训练,使用全局批大小为 512 个话语和初始学习率为 10。Llama 3 70B 的语音模型经过 600K 次更新训练,使用全局批大小为 768 个话语和初始学习率为 4 × 10。
8.3.2 Генерация речи
Для поддержки обработки в реальном времени модель рифмовки использует механизм опережающего просмотра, который учитывает фиксированное количество будущих фонемных позиций и переменное количество будущих лексем. Это обеспечивает согласованное опережение взгляда при обработке входящего текста, что очень важно для приложений синтеза речи с низкой задержкой.
Обучение. Мы разрабатываем стратегию динамического выравнивания с использованием причинно-следственных масок для облегчения потокового синтеза речи. Стратегия сочетает в себе механизм опережающего просмотра в просодической модели для фиксированного количества будущих фонем и переменного количества будущих лексем, что соответствует процессу разбивки на части в процессе нормализации текста (раздел 8.1.2).
Для каждой фонемы маркерная головка состоит из максимального количества маркеров, определяемого размером блока, в результате чего получаются вкрапления Llama с переменной головкой и фонемы с фиксированной головкой.
Вкрапления Llama 3 из модели Llama 3 8B, замороженные во время обучения модели рифмы. Входные характеристики частоты звонков включают лингвистические элементы и элементы управляемости диктора/стиля. Модель обучается с помощью оптимизатора AdamW с размером партии 1 024 тона и скоростью обучения 9 × 10 -4. Модель обучается в течение 1 миллиона обновлений, причем первые 3 000 обновлений выполняют прогрев скорости обучения, а затем следуют косинусному планированию.
Рассуждения. В процессе вывода используется один и тот же механизм опережающего просмотра и стратегия маскировки причинно-следственных связей для обеспечения согласованности между обучением и обработкой в реальном времени. PM обрабатывает входящий текст в потоковом режиме, обновляя входные данные по телефону для характеристик телефонного рейтинга и по блокам для характеристик маркированного рейтинга. Входы новых блоков обновляются только тогда, когда первый телефон блока является текущим, что позволяет сохранить выравнивание и опережение во время обучения.
Для предсказания целей рифмы мы использовали подход с использованием режима задержки (Харитонов и др., 2021), который повышает способность модели улавливать и воспроизводить дальние рифмовые зависимости. Этот подход способствует естественности и выразительности синтезированной речи, обеспечивая низкую задержку и высокое качество вывода.
8.4 Результаты понимания речи
Мы оценили возможности понимания речи речевого интерфейса Llama 3 для трех задач: (1) автоматическое распознавание речи (2) перевод речи (3) вопросы и ответы. Мы сравнили производительность речевого интерфейса Llama 3 с тремя современными моделями понимания речи: Whisper (Radford et al., 2023), SeamlessM4T (Barrault et al., 2023) и Gemini. Во всех оценках мы использовали жадный поиск для предсказания лексем Llama 3.
Распознавание речи. Мы оценивали производительность ASR на многоязычном наборе LibriSpeech (MLS; Pratap et al., 2020), LibriSpeech (Panayotov et al., 2015), VoxPopuli (Wang et al., 2021a) и подмножестве многоязычного набора данных FLEURS (Conneau et al. 2023) на наборе данных английского языка для оценки производительности ASR. При оценке использовались Шепот Процедура нормализации текста позволяет обработать результаты декодирования, чтобы обеспечить соответствие результатам, полученным другими моделями. Во всех бенчмарках мы измеряем частоту ошибок в словах речевого интерфейса Llama 3 на стандартном тестовом наборе этих бенчмарков, за исключением китайского, японского, корейского и тайского языков, где мы указываем частоту ошибок в символах.
В таблице 31 приведены результаты оценки ASR. Она демонстрирует высокую производительность Llama 3 (и мультимодальных базовых моделей в целом) в задачах распознавания речи: наша модель превосходит такие специфические для речи модели, как Whisper20 и SeamlessM4T, во всех бенчмарках. Для английского языка MLS Llama 3 демонстрирует схожие результаты с Gemini.
Голосовой перевод. Мы также оценили производительность нашей модели в задаче перевода речи, где модель просили перевести неанглийскую речь в английский текст. В этих экспериментах мы использовали наборы данных FLEURS и Covost 2 (Wang et al., 2021b) и измеряли баллы BLEU для переведенного английского языка. В таблице 32 приведены результаты этих экспериментов. Эффективность нашей модели при переводе речи подчеркивает преимущества мультимодальных базовых моделей в таких задачах, как перевод речи.
Голосовая викторина. Речевой интерфейс Llama 3 демонстрирует удивительные возможности ответа на вопросы. Модель без труда понимает речь с кодовой заменой без предварительного ознакомления с такими данными. Примечательно, что, хотя модель была обучена только на одном раунде диалога, она способна к расширенным и последовательным многораундовым диалогам. На рисунке 30 показаны некоторые примеры, подчеркивающие эти многоязычные и многораундовые возможности.
Безопасность. Мы оценили безопасность нашей речевой модели на MuTox (Costa-jussà et al., 2023), наборе данных для многоязычных аудиоданных, содержащем 20 000 сегментов на английском и испанском языках и 4 000 сегментов на 19 других языках, каждый из которых помечен как токсичный. Аудиозапись передается на вход модели, а выходной сигнал оценивается на токсичность после удаления некоторых специальных символов. Мы применили классификатор MuTox (Costa-jussà et al., 2023) к Gemini 1.5 Pro и сравнили результаты. Мы оценивали процент добавленной токсичности (AT), когда на входе предлагается безопасный вариант, а на выходе получается токсичный, и процент потерянной токсичности (LT), когда на входе предлагается токсичный вариант, а на выходе получается безопасный. В таблице 33 показаны результаты для английского языка и средние результаты по всем 21 языку. Процент добавленной токсичности очень низок: наша речевая модель имеет самый низкий процент добавленной токсичности для английского языка - менее 11 TP3T. Она удаляет гораздо больше токсичности, чем добавляет.

8.5 Результаты генерации речи
В контексте генерации речи мы сосредоточились на оценке качества моделей потокового ввода на основе маркеров, которые используют векторы Llama 3 для задач нормализации текста и моделирования рифмы. Оценка сосредоточена на сравнении с моделями, которые не используют векторы Llama 3 в качестве дополнительного входного сигнала.
Нормализация текста. Чтобы измерить влияние вектора Llama 3, мы попробовали варьировать количество контекста правой стороны, используемого моделью. Мы обучили модель, используя контекст правой стороны из 3 токенов нормализации текста (TN) (разделенных по категориям Unicode). Эта модель сравнивалась с моделями, которые не использовали вектор Llama 3 и использовали либо контекст правой стороны с тремя метками, либо полный двунаправленный контекст. Как и ожидалось, в таблице 34 показано, что использование полного контекста правой стороны улучшает производительность модели без векторов Llama 3. Однако модель, содержащая векторы Llama 3, превосходит все остальные модели, обеспечивая потоковую передачу входных и выходных данных со скоростью метки без необходимости полагаться на длинные контексты во входных данных. Мы сравниваем модели с векторами Llama 3 8B и без них, а также с использованием различных значений контекста правой стороны.
Ритмическое моделирование. Чтобы оценить эффективность нашей модели рифмовки (PM) с Llama 3 8B, мы провели два набора человеческих оценок, сравнивая модели с векторами Llama 3 и без них. Оценщики прослушивали образцы разных моделей и указывали свои предпочтения.
Для генерации конечной формы речевого сигнала мы использовали внутреннюю акустическую модель на основе трансформатора (Wu et al., 2021), которая предсказывает спектральные особенности, и нейронный вокодер WaveRNN (Kalchbrenner et al., 2018) для генерации конечной формы речевого сигнала.
В первом тесте мы напрямую сравним Llama 3 8B PM с потоковой эталонной моделью, в которой не используются векторы Llama 3. Во втором тесте Llama 3 8B PM сравнивается с непотоковой эталонной моделью, в которой не используются векторы Llama 3. Как показано в таблице 35, Llama 3 8B PM оказалась предпочтительнее на 60% времени (по сравнению с эталоном потокового вещания) и на 63,6% времени (по сравнению с эталоном без потокового вещания), что свидетельствует о значительном улучшении качества восприятия. Ключевым преимуществом Llama 3 8B PM является возможность потоковой передачи данных на основе маркеров (раздел 8.2.2), которая поддерживает низкую задержку во время процесса вывода. Это снижает требования к модели по задержке, позволяя ей достичь более быстрого синтеза речи в реальном времени по сравнению с эталонной моделью без потоковой передачи. В целом, модель рифмовки Llama 3 8B постоянно превосходит эталонную модель, демонстрируя свою эффективность в улучшении естественности и выразительности синтезированной речи.




9 Похожие работы
Разработка Llama 3 основывается на большом количестве предшествующих исследований фундаментальных моделей языка, изображений, видео и речи. В рамки данной статьи не входит всесторонний обзор этих работ; мы отсылаем читателя к Bordes et al. (2024); Madan et al. (2024); Zhao et al. (2023a) для такого обзора. Ниже мы приводим краткий обзор основополагающих работ, которые непосредственно повлияли на разработку Llama 3.
9.1 Язык
Область применения. Llama 3 следует неизменной тенденции применения простых методов к все более крупным масштабам, характерной для базовой модели. Улучшения обусловлены ростом вычислительной мощности и качества данных. Так, модель 405B использует почти в пятьдесят раз больше вычислительного бюджета на предварительное обучение, чем модель 70B Llama 2. Хотя наша самая большая модель Llama 3 содержит 405B параметров, на самом деле она имеет меньше параметров, чем более ранние и менее эффективные модели, такие как PALM (Chowdhery et al., 2023), благодаря лучшему пониманию законов масштабирования (Kaplan et al., 2020; Hoffmann et al., 2022). Существуют и другие передовые модели, такие как Claude 3 или GPT 4 (OpenAI, 2023a), с ограниченным объемом открытой информации, но с сопоставимой общей производительностью.
Малогабаритные модели. Разработка мелкомасштабных моделей шла параллельно с разработкой крупномасштабных моделей. Модели с меньшим количеством параметров могут значительно повысить стоимость вычислений и упростить развертывание (Mehta et al., 2024; Team et al., 2024). Небольшая модель Llama 3 достигает этого за счет значительного превышения оптимальных с точки зрения вычислений точек обучения, эффективно компенсируя вычисления для обучения эффективностью вывода. Другой путь - разделение больших моделей на более мелкие, например Phi (Abdin et al., 2024).
Архитектура. По сравнению с Llama 2, Llama 3 имеет минимальные архитектурные изменения, но в других недавних базовых моделях были исследованы альтернативные конструкции. В частности, экспертные гибридные архитектуры (Shazeer et al. 2017; Lewis et al. 2021; Fedus et al. 2022; Zhou et al. 2022) могут использоваться как способ эффективного увеличения мощности модели, как, например, в Mixtral (Jiang et al. 2024) и Arctic (Snowflake Производительность Llama 3 превосходит эти модели, что говорит о том, что плотные архитектуры не являются ограничивающим фактором, но при этом существует множество компромиссов в плане эффективности обучения и вывода, а также стабильности модели на больших масштабах.
Открытый источник. За последний год базовые модели с открытым исходным кодом быстро развивались, и сейчас Llama3-405B находится на одном уровне с современными моделями с закрытым исходным кодом. В последнее время был разработан целый ряд семейств моделей, включая Mistral (Jiang et al., 2023), Falcon (Almazrouei et al., 2023), MPT (Databricks, 2024), Pythia (Biderman et al., 2023), Arctic (Snowflake, 2024), OpenELM (Mehta et al., 2024), OLMo (Groeneveld et al., 2024), StableLM (Bellagente et al., 2024), OpenLLaMA (Geng and Liu, 2023), Qwen (Bai et al., 2023), Gemma (Team et al., 2024), Grok (Biderman et al., 2023) и Gemma (Biderman et al.) 2024), Grok (XAI, 2024) и Phi (Abdin et al., 2024).
Посттренинг. Посттренинговое обучение Llama 3 следует установленной стратегии настройки инструкций (Chung et al., 2022; Ouyang et al., 2022), за которой следует выравнивание с обратной связью от человека (Kaufmann et al., 2023). Хотя некоторые исследования показали неожиданные результаты при использовании облегченных процедур выравнивания (Zhou et al., 2024), Llama 3 использует миллионы человеческих инструкций и суждений о предпочтениях для улучшения предварительно обученных моделей, включая выборку отклонений (Bai et al., 2022), контролируемую тонкую настройку (Sanh et al., 2022) и прямую оптимизацию предпочтений (Rafailov et al., 2023). Для создания примеров инструкций и предпочтений мы использовали ранние версии Llama 3 для фильтрации (Liu et al., 2024c), переписывания (Pan et al., 2024) или генерации подсказок и ответов (Liu et al., 2024b), и применяли эти методы в ходе нескольких раундов посттренинга.
9.2 Мультимодальность
Наши эксперименты с мультимодальными возможностями Llama 3 являются частью долгосрочного исследования фундаментальных моделей для совместного моделирования нескольких модальностей. Наш подход Llama 3 сочетает в себе идеи из ряда работ и позволяет достичь результатов, сравнимых с Gemini 1.0 Ultra (Google, 2023) и GPT-4 Vision (OpenAI, 2023b); см. раздел 7.6.
видео: Несмотря на растущее число базовых моделей, поддерживающих ввод видео (Google, 2023; OpenAI, 2023b), исследований по совместному моделированию видео и языка было проведено не так много. Как и в случае с Llama 3, в большинстве современных исследований используются адаптивные методы для согласования видео и языковых представлений, а также для раскрытия вопросов и ответов и рассуждений о видео (Lin et al. 2023; Li et al. 2023a; Maaz et al. 2024; Zhang et al. 2023; Zhao et al. 2022). Мы обнаружили, что эти методы дают результаты, которые конкурируют с современными; см. раздел 7.7.
разговорное (а не литературное) произношение китайского иероглифа: Наша работа также вписывается в более крупный массив работ, объединяющих моделирование языка и речи. К ранним совместным моделям текста и речи относятся AudioPaLM (Rubenstein et al., 2023), VioLA (Wang et al., 2023b), VoxtLM Maiti et al. (2023), SUTLM (Chou et al., 2023) и Spirit-LM (Nguyen et al., 2024). . Наша работа опирается на предыдущие композиционные подходы к объединению речи и языка, такие как Fathullah et al. (2024). В отличие от большинства предыдущих работ, мы решили не настраивать языковую модель для речевой задачи, поскольку это может привести к конкуренции со стороны неречевых задач. Мы обнаружили, что даже без такой тонкой настройки можно добиться хорошей производительности при больших размерах модели; см. раздел 8.4.
10 Заключение
Разработка высококачественных базовых моделей все еще находится на ранней стадии. Наш опыт разработки Llama 3 говорит о том, что есть много возможностей для дальнейшего совершенствования этих моделей. При разработке семейства моделей Llama 3 мы обнаружили, что упор на высококачественные данные, масштаб и простоту неизменно приводит к наилучшим результатам. В предварительных экспериментах мы исследовали более сложные архитектуры моделей и сценарии обучения, но не обнаружили, что преимущества этих подходов перевешивают дополнительные сложности, которые они привносят в разработку моделей.
Разработка такой флагманской базовой модели, как Llama 3, требует не только преодоления множества глубоких технических проблем, но и принятия взвешенных организационных решений. Например, чтобы гарантировать, что Llama 3 не будет случайно перекорректирована по отношению к общепринятым эталонным тестам, наши данные для предварительного обучения собираются и обрабатываются независимой командой, которая строго мотивирована не допускать загрязнения внешних эталонных тестов данными для предварительного обучения. Еще один пример: мы гарантируем достоверность человеческих оценок, позволяя выполнять их и получать к ним доступ лишь небольшой группе исследователей, не участвующих в разработке моделей. Хотя эти организационные решения редко обсуждаются в технических статьях, мы сочли их критически важными для успешной разработки семейства моделей Llama 3.
Мы делимся подробностями процесса разработки, поскольку считаем, что это поможет более широкому исследовательскому сообществу понять ключевые элементы разработки базовых моделей и внести вклад в более глубокую общественную дискуссию о будущем развитии базовых моделей. Мы также поделились предварительными экспериментальными результатами интеграции мультимодальной функциональности в Llama 3. Хотя эти модели все еще находятся в стадии активной разработки и пока не готовы к выпуску, мы надеемся, что ранний обмен результатами ускорит исследования в этом направлении.
Учитывая положительные результаты анализа безопасности, подробно описанного в этой статье, мы публично выпускаем нашу языковую модель Llama 3, чтобы ускорить процесс разработки систем ИИ для широкого круга социально значимых случаев использования, а также чтобы дать возможность исследовательскому сообществу проанализировать наши модели и найти способы сделать их лучше и безопаснее. Мы считаем, что публичный выпуск моделей, лежащих в их основе, крайне важен для ответственной разработки таких моделей, и надеемся, что выпуск Llama 3 подтолкнет индустрию в целом к открытой и ответственной разработке ИИ.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты



Нет комментариев...