KAG: отечественный фреймворк баз знаний ИИ с открытым исходным кодом Глубинный анализ и учебники по установке

Недавно я обнаружил привлекательный отечественный фреймворк базы знаний ИИ с открытым исходным кодом: KAG (Knowledge Augmented Generation).
KAG Совместно запущенный Ant Group, Чжэцзянским университетом и многими другими организациями, он нацелен на создание баз знаний в вертикальных областях. Данные, приведенные в статье, показывают, что KAG в области электронного правительства достигает Впечатляющий показатель точности 91.6%Кроме того, он отлично подходит для таких сценариев, как электронное здравоохранение Q&A.
В этой статье вы подробно рассмотрите KAG принцип, сценарии применения, сравнение RAG В статье также приведены локальные руководства по установке и демонстрационные примеры, которые позволят вам погрузиться в работу с фреймворком KAG, открытым компанией Ant. Если вы планируете использовать искусственный интеллект для создания собственной базы знаний, эту статью нельзя пропустить!
Что такое KAG? Основные концепции для нового поколения баз знаний
KAG (Knowledge Augmented Generation) - это система вопросов и ответов, основанная на движке OpenSPG и больших языковых моделях (LLM). Его основными концепциями являютсяСочетая двойные преимущества графа знаний и векторного поиска, он призван обеспечить пользователям более строгую поддержку принятия решений и более точные информационно-поисковые услуги.

KAG обеспечивает глубокое слияние и расширение LLM и Knowledge Graph с помощью следующих четырех ключевых технологий:
- Знание представительства, ориентированного на LLM: Оптимизация структуры графов знаний для облегчения их понимания и использования большими языковыми моделями.
- Перекрестное индексирование между графами знаний и фрагментами оригинального текста: Установление двунаправленных связей между сущностями и отношениями в графе знаний и фрагментами оригинального текста для повышения эффективности и точности поиска.
- Гибридная система рассуждений, управляемая логическими формами: Объедините возможности логических рассуждений Графа знаний с возможностями семантического понимания LLM, чтобы получить более сложные тесты для рассуждений.
- Выравнивание знаний с помощью семантического обоснования: Убедитесь, что знания в графе знаний согласованы с семантическим пространством языковой модели, чтобы повысить эффективность использования знаний.
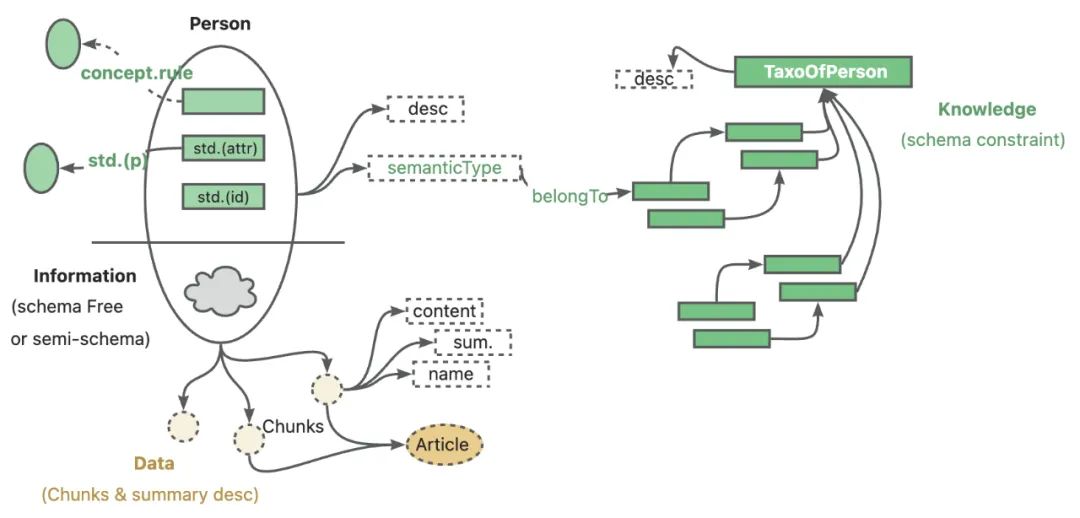
Одним словом, KAG инновационно сочетает преимущества графа знаний и векторного поиска для создания мощной базы знаний. Он может не только использовать возможности логических рассуждений LLM, но и объединять их с графом знаний для более глубоких рассуждений, чтобы выполнять сложные задачи поиска информации. Более того, когда информации из графа знаний недостаточно, KAG может использовать технологию векторного поиска для дополнения соответствующих фрагментов текста, чтобы обеспечить полноту и точность ответов.
Обзор общей архитектуры KAG
Фреймворк KAG состоит из двух основных модулей: формирование знаний (kg-builder) и решение проблем (kg-solver).
- kg-builder Модуль фокусируется на эффективном построении знаний, оптимизации представления знаний для LLM, поддержке гибкого моделирования знаний и двунаправленного индексирования.
- kg-solver Затем модуль отвечает за эффективное решение проблем, что достигается с помощью гибридного механизма рассуждений, который объединяет множество возможностей, таких как поиск, графические рассуждения, лингвистические рассуждения и численные вычисления для решения сложных проблем.
- Третий модуль, kag-model, будет выпущен с открытым исходным кодом для дальнейшего совершенствования фреймворка KAG.

KAG в сравнении с традиционным RAG: различия и преимущества
RAG (Retrieval-Augmented Generation) широко используется в качестве общей технологии баз знаний. В чем же заключаются различия и преимущества KAG по сравнению с RAG? Мы сравниваем и анализируем их по следующим параметрам:
1. представление знаний:
- RAG. В основном для поиска используется векторное сходство, а представление знаний относительно простое, что затрудняет решение сложных задач, требующих многоходовых рассуждений.
- КАГ. Принятие представления знаний, более дружественного к LLM, совместимого со знаниями без схем и со знаниями, ограниченными схемами, поддерживающего взаимоиндексированную структуру знаний, структурированных графами, и текстовых знаний, а также более богатое и структурированное представление знаний.
2. Умение рассуждать:
- RAG. Невосприимчивость к логическим связям знаний и отсутствие навыков логического мышления для решения проблем в специализированных областях, требующих сложных рассуждений.
- КАГ. Представляет логико-символический гибридный механизм рассуждений с мощными логическими рассуждениями и возможностями многоцелевой проверки фактов для решения более сложных профессиональных задач.
3. Производительность:
- RAG. Плохо справляется с многоходовыми заданиями и заданиями на перекрестное прохождение, генерируя текст с относительно слабой связностью и логикой.
- КАГ. Он отлично справляется с многоходовыми и перекрестными задачами, значительно повышая точность рассуждений и информационный охват, а также генерируя более точные и полные ответы.
4. Применимые сценарии:
- RAG. Он больше подходит для решения общих задач по созданию и поиску текстов, но его производительность будет ограничена в таких специализированных областях, как юриспруденция, медицина и наука, где требуются сложные рассуждения.
- КАГ. Особенно подходит для приложений, требующих сложных рассуждений, и многоходовых фактологических викторин. Область экспертизыКомпания может предоставлять более профессиональные и точные услуги в области знаний, таких как финансовые, медицинские, юридические и правительственные вопросы.
В целом, объединив Knowledge Graph и Vector Retrieval, а также глубоко оптимизировав возможности представления знаний и рассуждений, KAG демонстрирует потенциал, превосходящий традиционную технологию RAG в решении сложных задач и опросе знаний, специфичных для конкретной области.
Локальное развертывание учебников "уровня корма": установка KAG, использование, эффект от демонстрации
Теоретический анализ необходимо проверять на практике! Далее я покажу вам, как установить, развернуть и использовать KAG локально вручную, а также продемонстрирую результаты.
Связанные с KAG ресурсы:
- Адрес Github.https://github.com/OpenSPG/KAG
- Официальный сайт.https://spg.openkg.cn/
Рекомендации по конфигурации оборудования:
- Процессор ≥ 8 ядер
- Оперативная память ≥ 32 ГБ
- Жесткий диск ≥ 100 ГБ
Официальная рекомендуемая конфигурация высока, но, согласно моим реальным тестам, он может работать практически без проблем на ПК под управлением Windows с 16 ГБ ОЗУ. Поэтому в этом руководстве будет показана установка и использование KAG в среде Windows.
Шаг 1: Установите рабочий стол Docker
Установка и развертывание KAG зависят от среды Docker, поэтому убедитесь, что на вашем компьютере установлен Docker Desktop.
Шаг 2: Создайте файл docker-compose.yml
- Создайте папку с именем KAG в корневом каталоге диска D (или другого диска).
- В папке KAG создайте новый файл docker-compose.yml.
- Скопируйте и вставьте следующий код YAML в файл docker-compose.yml и сохраните его.
version: "3.7"
services:
server:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latest
container_name: release-openspg-server
ports:
- "8887:8887"
depends_on:
- mysql
- neo4j
- minio
# volumes:
# - /etc/localtime:/etc/localtime:ro
environment:
TZ: Asia/Shanghai
LANG: C.UTF-8
command: [
"java",
"-Dfile.encoding=UTF-8",
"-Xms2048m",
"-Xmx8192m",
"-jar",
"arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",
'--server.repository.impl.jdbc.host=mysql',
'--server.repository.impl.jdbc.password=openspg',
'--builder.model.execute.num=5',
'--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j',
'--cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j'
]
mysql:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latest
container_name: release-openspg-mysql
volumes:
- mysql_data:/var/lib/mysql
environment:
TZ: Asia/Shanghai
LANG: C.UTF-8
MYSQL_ROOT_PASSWORD: openspg
MYSQL_DATABASE: openspg
ports:
- "3306:3306"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci'
]
neo4j:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latest
container_name: release-openspg-neo4j
ports:
- "7474:7474"
- "7687:7687"
environment:
- TZ=Asia/Shanghai
- NEO4J_AUTH=neo4j/neo4j@openspg
- NEO4J_PLUGINS=["apoc"]
- NEO4J_server_memory_heap_initial__size=1G
- NEO4J_server_memory_heap_max__size=4G
- NEO4J_server_memory_pagecache_size=1G
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=*
- NEO4J_dbms_security_procedures_allowlist=*
volumes:
- neo4j_logs:/logs
- neo4j_data:/data
minio:
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latest
container_name: release-openspg-minio
command: server --console-address ":9001" /data
restart: always
environment:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio@openspg
TZ: Asia/Shanghai
ports:
- 9000:9000
- 9001:9001
volumes:
- minio_data:/data
volumes:
mysql_data:
neo4j_logs:
neo4j_data:
minio_data:
Шаг 3: Запустите службу KAG
- Откройте командную строку и перейдите в каталог папки KAG (введите cmd в поле адреса папки KAG и введите).
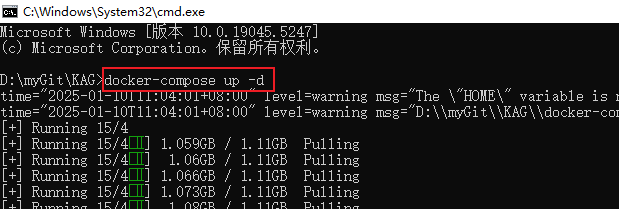
- Введите docker-compose up -d в командной строке и введите enter, чтобы начать автоматическую установку и развертывание KAG.
- Подождите некоторое время, когда вы увидите, что mysql, neo4j, openspg-server, minio четыре службы отображаются в состоянии Created или Started, это означает, что служба KAG была успешно запущена.

Шаг 4: Перейдите на страницу администрирования бэкэнда KAG
- Откройте браузер и введите адрес 127.0.0.1:8887, чтобы перейти на страницу фоновой работы KAG.
- Войдите в систему, используя стандартное имя пользователя openspg и стандартный пароль openspg@kag.

Шаг 5: Настройте систему KAG
- После входа в систему сначала выберите меню Глобальная конфигурация.

- Общая конфигурация: Выполните следующую настройку
- Рисунок Конфигурация хранилища
- база данных:neo4j
- пароль: neo4j@openspg
- uri:neo4j://release-openspg-neo4j:7687
- пользователь:neo4j
- Подсказки на английском и китайском языках
- biz_scene: default
- Язык: zh
- конфигурация вектора (вычисления) (с помощью бесплатного API векторного моделирования)
- тип: openai
- модель: BAAI/bge-large-zh-v1.5
- base_url:https://api.siliconflow.cn/v1
- api_key: перейти к Поток на основе кремния платформу, чтобы получить бесплатный ключ API.

- Поток на основе кремния После регистрации и входа на платформу вы можете найти бесплатную векторную модель и создать API-ключ, следуя инструкциям на изображении ниже.


- Конфигурация модели: Нажмите Добавьте модель maas (совместимую с интерфейсом openai).Настройте большую языковую модель, которую вы хотите использовать.
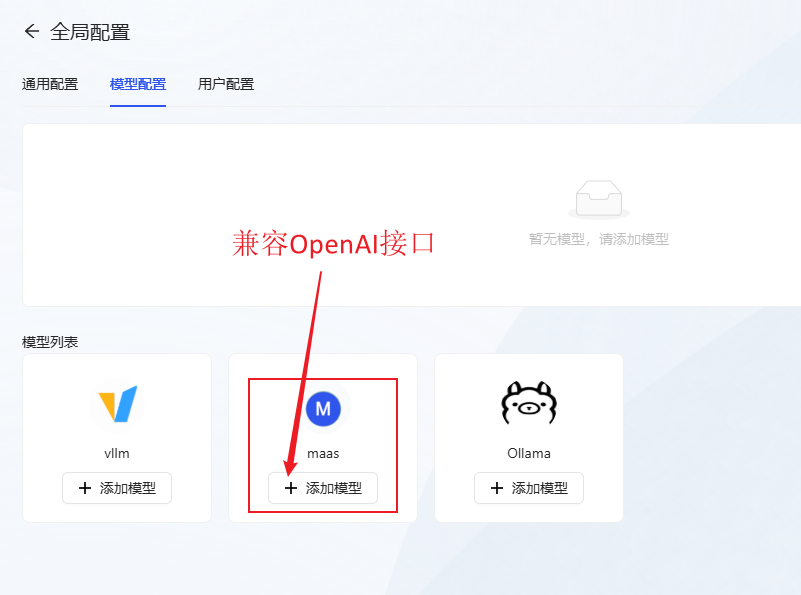
- Возьмите в качестве примера gpt-4o, заполните информацию о модели и нажмите OK для сохранения.
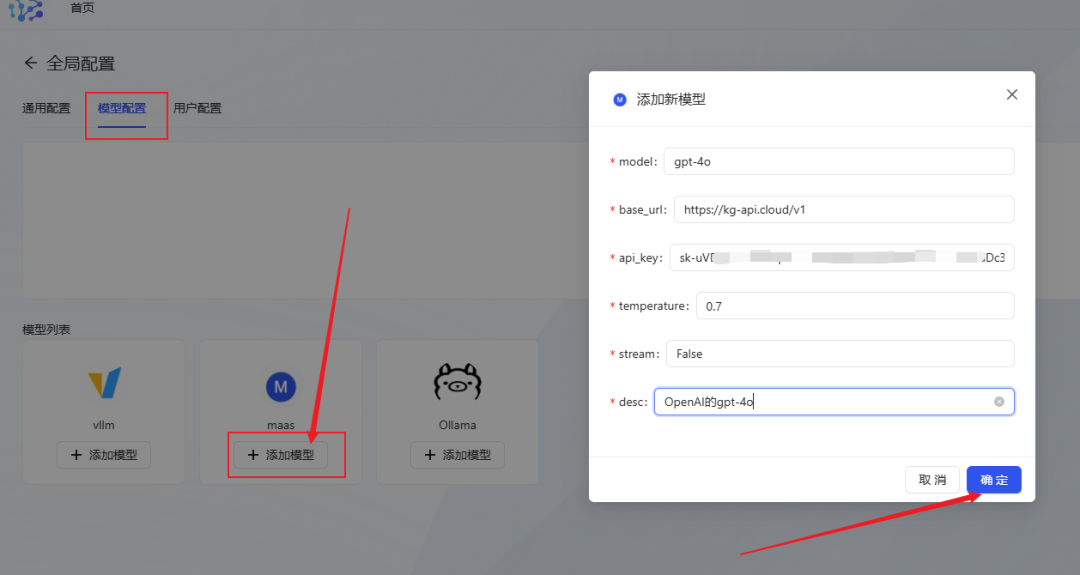
- Рекомендация по модели релейной станции APIЕсли у вас есть потребности в API-вызове различных больших моделей, вы можете рассмотреть возможность использования транзитного сервиса API, который совместим с интерфейсом OpenAI, поддерживает переключение в один клик между отечественными и зарубежными основными большими моделями, а также предоставляет MJ, SD и Suno и другие интерфейсы для рисования и создания музыки. Цена также более выгодна.
Шаг 6: Создание базы знаний и импорт документов
- Вернитесь на главную страницу и нажмите кнопку Создать базу знаний.

- Назовите базу знаний и нажмите кнопку Сохранить.
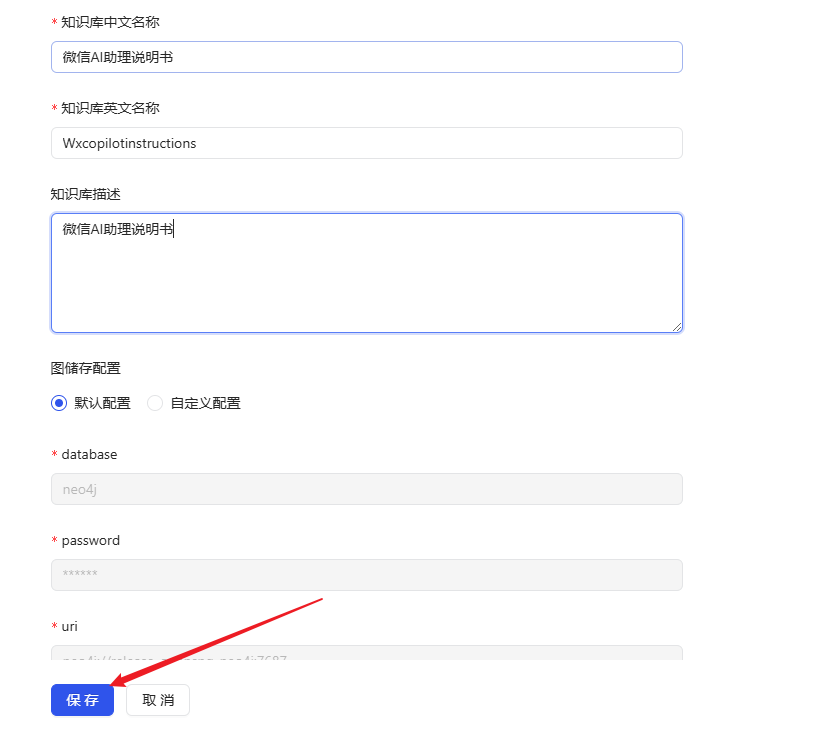
- После успешного создания найдите только что созданную базу знаний на главной странице и нажмите Knowledge Base Build.

- Нажмите кнопку Создать задачу, чтобы начать импорт документов.

- Загрузите документы базы знаний (в настоящее время KAG поддерживает загрузку только одного документа за раз, если у вас несколько документов, вам нужно загружать их партиями). Здесь я загрузил документы, связанные с моим последним продуктом, WeChat AI Assistant.
- Призыв к обмену инструментами для слияния файлов: Если у вас есть хороший бесплатный инструмент для объединения файлов, поделитесь им в разделе комментариев, чтобы упростить пакетную обработку документов.

- На следующем этапе настройки рекомендуется установить флажок Разделять абзацы в соответствии с семантикой документа, чтобы сохранить контекстную связность абзацев.
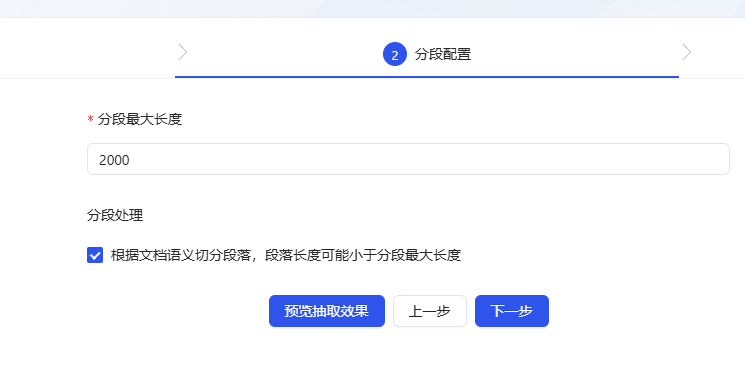
- модель извлечения опция по умолчанию (конфигурация по умолчанию подходит). подсказка Его можно настроить по своему усмотрению, здесь я просто установил значение "Q&A Split" (понимание не всегда точное, поправьте меня).

- Нажмите Готово, и KAG начнет извлекать и разбирать документы - этот процесс может занять некоторое время.
- Процесс разбора документа делится на 6 этапов, как показано на следующем рисунке:

- Дождитесь, пока статус задачи изменится на "Завершено", что означает, что документ был успешно импортирован в базу знаний. (Если статус не обновлялся в течение длительного времени, попробуйте обновить страницу).

Шаг 7: Демонстрация
- Диаграмма корреляции извлечения знаний: Это визуализация ассоциаций знаний, извлеченных KAG из документа.

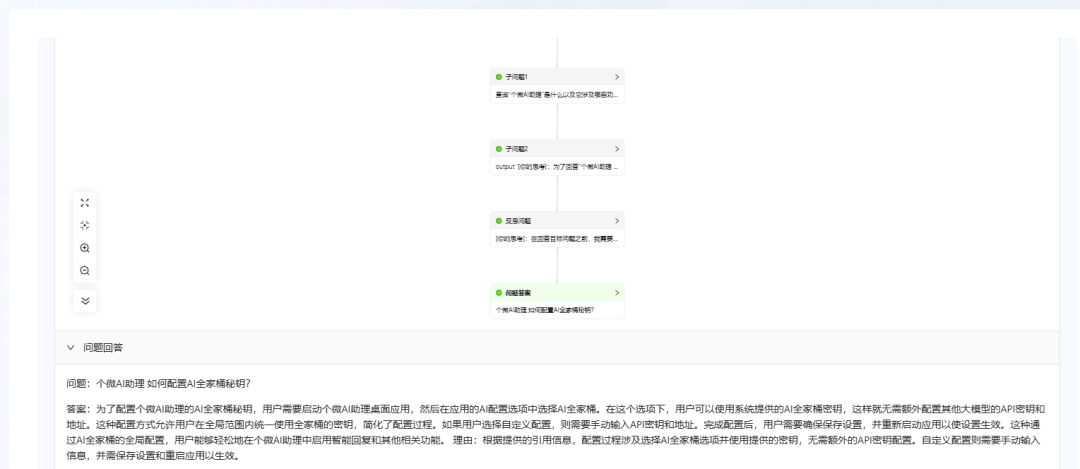
- Тест на эффективность вопросов и ответов::
- Вопрос 1: "Кратко расскажите о персональном микропомощнике ИИ".
Перед тем как найти и дать ответ, KAG проводит процесс обдумывания и рассуждения. Видно, что ответы, выдаваемые KAG, относительно точны и полны. Однако время ответа медленное, около 40 секунд (поэтому KAG может не подойти для простых сценариев вопросов и ответов).


- Вопрос 2: "Как настроить секретный ключ AI Family Bucket для Personal Micro AI Assistant?"
KAG также может дать ответ, но это займет больше времени.
Резюме и перспективы
Из приведенного выше опыта видно, что муравьиная база знаний с открытым исходным кодом KAG все еще находится на стадии быстрого развития, некоторые функции и пользовательский опыт еще предстоит улучшить (например, настройка параметров базы знаний, редактирование и модификация базы знаний не являются идеальными, при использовании также могут возникнуть некоторые ошибки). Однако, судя по записям обновлений на Github, команда KAG активно проводит итерации кода и оптимизирует функционал.
Техническое направление KAG, объединяющее Knowledge Graph и Vector Retrieval, является очень перспективным. Так же как технология RAG требует высококачественных данных базы знаний, расширения модели и настройки параметров для достижения оптимальных результатов, развитие KAG также требует постоянного совершенствования и оптимизации.
Как уже упоминалось в начале статьи, KAG лучше подходит для специализированных областей, таких как здравоохранение, финансы, юриспруденция, государственное управление и т. д., где требуются сложные рассуждения, а не простые повседневные сценарии вопросов и ответов (где быстрота реакции является недостатком).
В настоящее время KAG еще не открыл API, но ожидается, что после открытия API в будущем он может быть интегрирован в приложение Agent, и через механизм идентификации проблем простые и сложные проблемы могут быть разделены, чтобы использовать преимущества KAG в обработке сложных проблем.
В целом, цель этой статьи - дать вам представление о передовой технологии, которой является KAG. Хотя KAG, возможно, еще не совершенен, он продемонстрировал большой потенциал в качестве фреймворка базы знаний с открытым исходным кодом. Мы верим, что благодаря совместным усилиям сообщества и постоянному совершенствованию технологии KAG откроет новые возможности в области баз знаний ИИ.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

![[转]从零拆解一款火爆的浏览器自动化智能体,4步学会设计自主决策Agent](https://aisharenet.com/wp-content/uploads/2025/01/e0a98a1365d61a3.png)

Нет комментариев...