
KAG: профессиональная система вопросов и ответов по базам знаний для гибридного поиска по графу знаний и вектору

Общее введение
KAG (Knowledge Augmented Generation) - это логическая система рассуждений и поиска, основанная на движке OpenSPG и больших языковых моделях (LLM). Фреймворк специально разработан для построения логических рассуждений и решений по задаванию вопросов о фактах для баз знаний профессиональных областей, эффективно преодолевая недостатки традиционной модели вычисления векторного сходства RAG (Retrieval Augmented Generation). KAG улучшает LLM и графы знаний за счет взаимодополняющих преимуществ графов знаний и векторного поиска по четырем направлениям в обоих направлениях: представления знаний, дружественные LLM, взаимоиндексация между графами знаний и фрагментами сырого текста, гибридный решатель рассуждений, и гибридный решатель рассуждений. Индексирование, гибридные решатели умозаключений и механизмы оценки правдоподобности. Фреймворк особенно хорошо подходит для решения сложных задач логики знаний, таких как числовые вычисления, временные отношения и экспертные правила, обеспечивая более точные и надежные возможности ответа на вопросы для профессиональных приложений.

Список функций
- Способность поддерживать сложные логические формы рассуждений
- Предоставьте гибридный механизм поиска по графу знаний и векторному поиску
- Реализация удобного для LLM преобразования представления знаний
- Поддерживает двунаправленное индексирование структур знаний и текстовых блоков
- Интеграция LLM-рассуждений, интеллектуальных рассуждений и математико-логических рассуждений
- Обеспечить механизмы для оценки и подтверждения достоверности
- Поддержка многоходовых вопросов и ответов и сложной обработки запросов
- Предоставление индивидуальных решений для специализированных баз знаний.
Использование помощи
1. Подготовка окружающей среды
Прежде всего, необходимо убедиться, что ваша система соответствует следующим требованиям:
- Python 3.8 или выше
- Среда движка OpenSPG
- Поддерживаемые интерфейсы API для больших языковых моделей
2. Этапы установки
- Хранилище проектов клонирования:
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- Установите пакеты зависимостей:
pip install -r requirements.txt
3. Процесс использования рамок
3.1 Подготовка базы знаний
- Импорт специализированных данных о знаниях в области
- Настройка модели графа знаний
- Создание системы индексирования текстов
3.2 Обработка запросов
- Ввод вопросов: система получает от пользователя вопросы на естественном языке
- Преобразование логических форм: преобразование проблем в стандартные логические выражения
- Смешанный поиск:
- Выполняйте поиск по графу знаний
- Выполните поиск векторного сходства
- Интеграция результатов поиска
3.3 Процесс рассуждения
- Логические рассуждения: многоступенчатые рассуждения со смешанными решателями
- Объединение знаний: объединение результатов рассуждений на основе LLM и графов знаний
- Генерация ответа: формирование окончательного ответа
3.4 Гарантия достоверности
- Проверка ответов
- Рассуждения Трассировка пути
- оценка уверенности (математика)
4. Использование расширенных функций
4.1 Индивидуальное представление знаний
Формат представления знаний может быть настроен в соответствии с потребностями вашей области знаний, что обеспечивает совместимость с LLM:
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 Конфигурация правила рассуждения
Специализированные правила вывода могут быть настроены для работы с логикой, специфичной для конкретной области:
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5. лучшие практики
- Обеспечение качества и целостности данных базы знаний
- Оптимизация стратегий поиска для повышения эффективности
- Регулярное обновление и поддержание базы знаний
- Контролируйте производительность и точность системы
- Собирайте отзывы пользователей для постоянного совершенствования
6. решение общих проблем
- Если у вас возникли проблемы с эффективностью поиска, вы можете настроить параметры индекса соответствующим образом
- Для сложных запросов можно использовать пошаговую стратегию рассуждений
- Проверьте представление знаний и конфигурацию правил, если результаты выводов неточны
Презентация проекта KAG
1. Введение
Несколько дней назад компания Ant официально выпустила профессиональную платформу для обслуживания знаний в доменах под названием Knowledge Augmented Generation (KAG: Knowledge Augmented Generation), которая призвана полностью использовать преимущества Knowledge Graph и Vector Retrieval для решения проблемы существующих RAG Некоторые проблемы с технологическим стеком.
Из муравьиной разминки этой структуры, я был более заинтересован в некоторых из основных функций KAG, особенно логические символические рассуждения и выравнивание знаний, в существующей основной системы RAG, эти два пункта обсуждения не кажется слишком много, воспользоваться этим открытым источником, и поспешить изучить волну.
- Адрес для диссертаций KAG: https://arxiv.org/pdf/2409.13731
- Адрес проекта KAG: https://github.com/OpenSPG/KAG
2. Обзор системы
Прежде чем читать код, давайте вкратце рассмотрим цели и позиционирование фреймворка.
2.1 Что и почему?
На самом деле, когда я вижу фреймворк KAG, мне кажется, что первый вопрос, который приходит на ум многим людям, - почему он называется не RAG, а KAG. Согласно соответствующим статьям и документам, фреймворк KAG в основном предназначен для решения некоторых текущих проблем, с которыми сталкиваются крупные модели в профессиональных службах знаний:
- LLM не обладает способностью критически мыслить и не имеет навыков аргументации
- Ошибки фактов, логики, точности, неспособность использовать предопределенные структуры знаний о предметной области для ограничения поведения модели
- Типовые RAG также не справляются с иллюзиями LLM, особенно со скрытой вводящей в заблуждение информацией
- Проблемы и требования к экспертным услугам, отсутствие строгого и контролируемого процесса принятия решений
Поэтому команда Ant считает, что профессиональная система обслуживания знаний должна обладать следующими характеристиками:
- Важно обеспечить точность знаний, включая целостность границ знаний и четкость структуры и семантики знаний;
- Необходимы логическая строгость, чувствительность к времени и числам;
- Полная контекстная информация также необходима для облегчения доступа к полной вспомогательной информации при принятии решений на основе знаний;
Ant официально позиционирует KAG так: Professional Domain Knowledge Augmentation Service Framework, специально для текущего сочетания больших языковых моделей и графов знаний для улучшения следующих пяти областей
- Расширенные знания о дружественных LLM
- Структура взаимоиндексирования между графами знаний и фрагментами оригинального текста
- Гибридная система рассуждений, управляемая логическими символами
- Механизм выравнивания знаний на основе семантических рассуждений
- Модель KAG
Этот выпуск с открытым исходным кодом полностью охватывает первые четыре основные функции.
Возвращаясь к вопросу об именовании KAG, я лично предполагаю, что, возможно, необходимо усилить концепцию онтологии знаний. Судя по официальному описанию и фактической реализации кода, фреймворк KAG, будь то на этапе построения или рассуждений, постоянно делает акцент на самих знаниях, на построении полной и строгой логической связи, чтобы максимально улучшить некоторые из известных проблем стека технологий RAG.
2.2 Что (как) достигается?
Фреймворк KAG состоит из трех частей: KAG-Builder, KAG-Solver и KAG-Model:
- KAG-Builder используется для автономного индексирования и включает в себя вышеупомянутые функции 1 и 2: расширение представления знаний, структуру взаимного индексирования.
- Модуль KAG-Solver охватывает функции 3 и 4: логико-символьный гибридный механизм рассуждений, механизм выравнивания знаний.
- KAG-Model, с другой стороны, пытается построить сквозную модель KAG.
3. анализ исходного кода
Этот открытый исходный код включает в себя два модуля KAG-Builder и KAG-Solver, непосредственно соответствующие исходному коду двух подкаталогов builder и solver.
При изучении кода рекомендуется начать с examples Первое, что вам нужно сделать, - это начать с каталога, чтобы понять принцип работы всего фреймворка, а затем углубиться в конкретные модули. Пути к входным файлам нескольких демо-версий похожи, например kag/examples/medicine/builder/indexer.py слишком kag/examples/medicine/solver/evaForMedicine.pyОчевидно, что конструктор объединяет различные модули, в то время как реальная точка входа для решателя находится в kag/solver/logic/solver_pipeline.py.
3.1 KAG-Builder
Давайте сначала опубликуем полную структуру каталога
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
Раздел Builder охватывает широкий спектр функций, поэтому мы рассмотрим только один из наиболее важных компонентов. KAGExtractor Основная схема показана ниже:

Главное, что здесь делается, - это автоматическое создание графа знаний из неструктурированного текста в структурированные знания с помощью большой модели, с кратким описанием некоторых важных шагов, связанных с этим.
- Во-первых, это модуль распознавания сущностей, в котором сначала выполняется распознавание специфических сущностей для предопределенных типов графов знаний, а затем распознавание общих именованных сущностей. Этот двухуровневый механизм идентификации должен гарантировать, что будут захвачены как специфические для области сущности, так и общие сущности, которые не будут пропущены.
- Процесс построения карты фактически осуществляется
assemble_sub_graph_with_spg_recordsМетод сделан, и его особенность в том, что система преобразует атрибуты небазовых типов в узлы и ребра графа, а не продолжает хранить их в качестве исходных атрибутов сущности. Это изменение, честно говоря, не очень хорошо понятно, и в какой-то степени оно должно упростить сложность сущности, но на практике не совсем ясно, насколько велика польза от этой стратегии, сложность сборки определенно возросла. - Стандартизация предприятий
named_entity_standardizationответить пениемappend_official_nameЭти два подхода применяются совместно. Сначала имена сущностей нормализуются, а затем эти нормализованные имена связываются с исходной информацией о сущности. Этот процесс похож на разрешение сущностей.
В целом, функциональность модуля Builder довольно близка к текущему общему стеку технологий построения графов, а соответствующие статьи и код не слишком сложны для понимания, поэтому я не буду повторять их здесь.
3.2 KAG-Solver
Решающая часть фреймворка включает в себя множество основных функциональных моментов, особенно логику символических рассуждений, связанных с содержанием, сначала посмотрите на общую структуру:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
Я уже упоминал о входном файле решателя, поэтому размещу соответствующий код здесь:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
всего SolverPipeline.run() Методология включает в себя 3 основных модуля:Reasoner, Reflector ответить пением GeneratorОбщая логика по-прежнему предельно ясна: сначала попытайтесь ответить на вопрос, затем подумайте, удалось ли решить проблему, а если нет, продолжайте глубоко размышлять, пока не получите удовлетворительный ответ или не достигнете максимального количества попыток. По сути, это имитирует общий образ мышления человека при решении сложных задач.
В следующем разделе проводится дальнейший анализ трех вышеупомянутых модулей.
3.3 Разумник
Модуль выводов - это, пожалуй, самая сложная часть всего фреймворка, и его ключевой код выглядит следующим образом:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
В результате получается общая блок-схема модуля рассуждений: (логика, такая как обработка ошибок, опущена)

Легко заметить, чтоDefaultReasoner.reason() Методология в целом состоит из трех этапов:
- Планирование логической формы (LFP): в основном включает в себя
LFPlanner.lf_planing - Выполнение логической формы (LFE): в основном включает в себя
LFSolver.solve - Рерайтинг документов: в основном включает в себя
LFSolver.chunk_retriever.rerank_docs
Ниже подробно анализируется каждый из трех этапов.
3.3.1 Планирование логической формы
DefaultLFPlanner.lf_planing() Метод используется в основном для декомпозиции запроса на ряд независимых логических форм (lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
Логику реализации можно найти в kag/solver/implementation/default_lf_planner.pyОсновное внимание уделяется llm_output Выполните регулярный разбор или вызовите LLM для генерации новой логической формы, если она не предоставлена.
Вот за чем стоит следить kag/solver/prompt/default/logic_form_plan.py соответствующие вопросы LogicFormPlanPrompt Детальная разработка проекта посвящена тому, как разложить сложную проблему на множество подзапросов и соответствующих им логических форм.
3.3.2 Выполнение логической формы
LFSolver.solve() Методы используются для решения конкретных задач логической формы, возвращая ответы, пары ответов на подзадачи, связанные с ними документы и историю вызовов и т.д.
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
подробная информацияkag/solver/logic/core_modules/lf_solver.pyРаздел исходного кода, который можно найти LFSolver Класс (Logical Form Solver) является основным классом всего процесса рассуждений и отвечает за выполнение логической формы (LF) и генерацию ответа:
- Основными методами являются
solveкоторый получает запрос и набор узлов логической формы (List[LFPlanResult]). - пользоваться
LogicExecutorдля выполнения логических форм, генерации ответов, путей графа знаний и истории. - Обработка подзапросов и пар ответов, а также сопутствующей документации.
- Обработка ошибок и стратегия отступления: если ответ или соответствующая документация не найдены, предпринимается попытка использовать
chunk_retrieverОтозвать соответствующие документы.
Основные процессы заключаются в следующем:

среди них LogicExecutor это один из наиболее важных классов, основной код которого опубликован здесь:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- логика реализации
LogicExecutorСоответствующий код класса находится в файлеkag/solver/logic/core_modules/lf_executor.py. егоexecuteОсновной поток выполнения метода показан ниже.
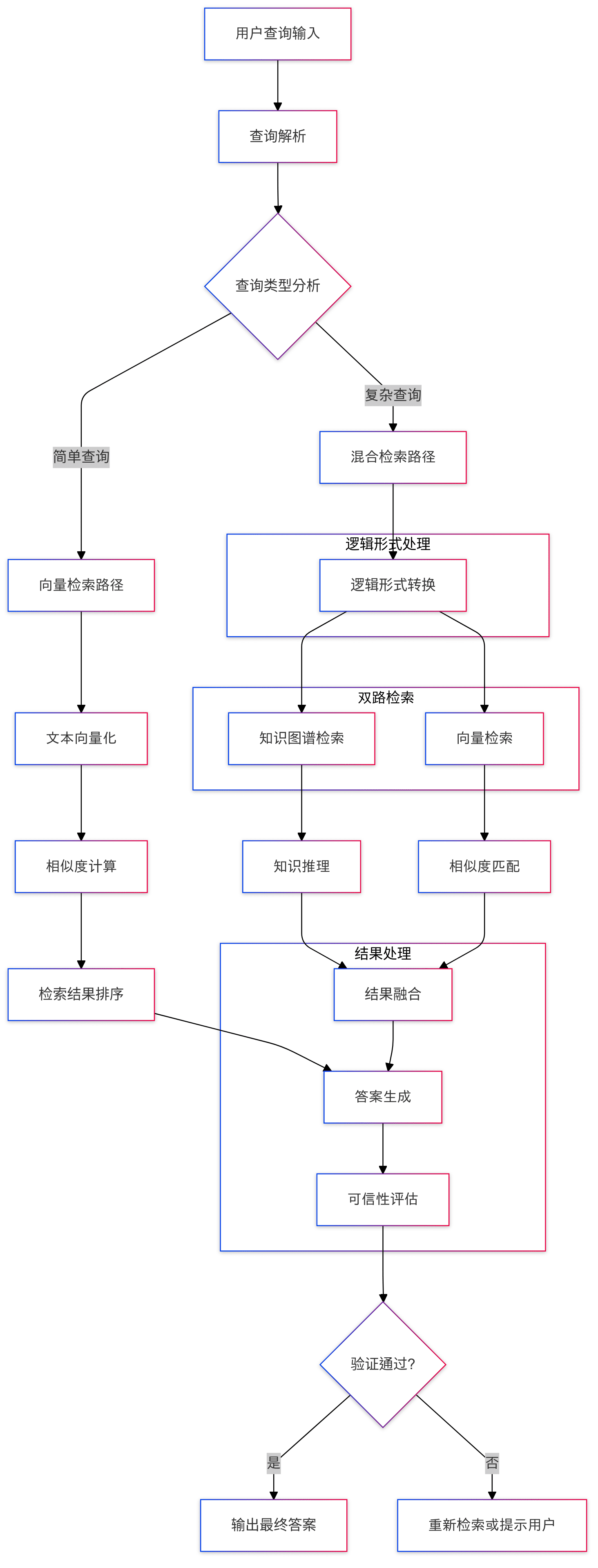
Этот поток выполнения демонстрирует двойную стратегию поиска: приоритетное использование структурированных данных графа для поиска и выводов и возврат к поиску неструктурированной текстовой информации, когда граф не дает ответа.
Сначала система пытается ответить на вопрос через граф знаний, для каждого узла логического выражения, с помощью различных исполнительных механизмов (с участиемdeduce, иmath, иsort, иretrieval, иoutputи т.д.) обрабатываются, и процесс поиска собирает тройки SPO (субъект-предикат-объект) для последующей генерации ответа; когда граф не может дать удовлетворительный ответ (возвращая "Я не знаю"), система возвращается к поиску текстовых блоков: используя ранее полученные результаты по именованным сущностям (NER) в качестве опорной точки поиска и комбинируя их с историческими записями вопросов и ответов для создания расширенного контекста запроса, который затем проходит черезchunk_retrieverСгенерируйте ответ на основе полученного документа.
Весь процесс можно рассматривать как элегантную стратегию деградации, и благодаря сочетанию структурированных графов знаний с неструктурированными текстовыми данными этот гибридный поиск способен предоставить максимально полные и контекстуально связные ответы, сохраняя при этом точность. - основной компонент
В дополнение к конкретной логике реализации, описанной выше, обратите внимание, чтоLogicExecutorИнициализация требует передачи нескольких компонентов. Ограниченный пространством, здесь приведено лишь краткое описание основных функций каждого компонента, за конкретной реализацией можно обратиться к исходному коду.- kg_retriever: Knowledge Graph Retriever
консультацияkag/solver/implementation/default_kg_retrieval.pyсерединаKGRetrieverByLlm(KGRetrieverABC), который реализует поиск сущностей и отношений, используя несколько методов сопоставления, таких как точный/нечеткий и одноходовые подграфы. - chunk_retriever: ретривер текстовых фрагментов
консультацияkag/common/retriever/kag_retriever.pyсерединаDefaultRetriever(ChunkRetrieverABC)Код здесь заслуживает изучения, во-первых, он стандартизирован с точки зрения обработки сущностей, и, кроме того, поиск здесь относится к HippoRAG, принимая гибридную стратегию поиска, сочетающую DPR (Dense Passage Retrieval) и PPR (Personalized PageRank), а затем далее основанную на слиянии DPR и PPR Score. Кроме того, здесь используется гибридная стратегия поиска, сочетающая DPR (Dense Passage Retrieval) и PPR (Personalised PageRank), а последующее слияние оценок, основанных на DPR и PPR, позволяет добиться динамического распределения веса между двумя методами поиска. - entity_linker (el): компоновщик сущностей
консультацияkag/solver/logic/core_modules/retriver/entity_linker.pyсерединаDefaultEntityLinker(EntityLinkerBase)Здесь используется идея построения признаков до параллельной обработки связей между сущностями. - dsl_runner: запрос базы данных графов
консультацияkag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.pyсерединаDslRunnerOnGraphStore(DslRunner)Отвечает за структурированный запрос информации в конкретный запрос к базе данных графов, эта часть будет включать в себя базовую конкретную базу данных графов, детали относительно сложны, но не слишком сильно задействованы.
- kg_retriever: Knowledge Graph Retriever
Просматривая приведенный выше код и блок-схему, можно заметить, что весь цикл выполнения логической формы имеет иерархическую архитектуру обработки:
- верхняя часть здания
LFSolverОтвечает за общий процесс - мезосфера
LogicExecutorОтвечает за реализацию конкретных логических форм (LF) - дно (кучи)
DSL RunnerОтвечает за взаимодействие с базой данных графов
3.3.3 Рерайтинг документов
Если вы включите chunk_retrieverТакже будет изменен порядок вызванных документов.
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 Отражатель
Reflector класс в первую очередь реализует _can_answer вместе с _refine_query Два метода, первый из которых позволяет определить, можно ли ответить на вопрос, а второй - оптимизировать промежуточные результаты многоходового запроса для получения окончательного ответа.
Ссылки по реализации kag/solver/prompt/default/resp_judge.py вместе с kag/solver/prompt/default/resp_reflector.py Эти два файла Prompt легче понять.
3.5 Генератор
скоба LFGenerator класс, динамически выбирает шаблоны слов подсказок на основе различных сценариев (с графами знаний или без них, с документами или без них и т.д.) и генерирует ответы на соответствующие вопросы.
Соответствующие реализации находятся в kag/solver/logic/core_modules/lf_generator.pyКод относительно интуитивно понятен и не будет повторяться.
4. Некоторые размышления
Ant этот открытый источник KAG рамки, сосредоточив внимание на профессиональных услуг расширения знаний домена, охватывающих символические рассуждения, выравнивание знаний и ряд инновационных моментов, всестороннее изучение, я чувствую, что рамки особенно подходит для необходимости строгих ограничений на схему профессиональных знаний сценария, будь то на этапе индексирования или запроса, весь рабочий процесс многократно усиливается точка зрения: вы должны быть от ограничений базы знаний, чтобы построить графы или проводить логические рассуждения. Такой образ мышления должен в некоторой степени смягчить проблему отсутствия знаний о домене, а также иллюзию больших моделей.
С тех пор как фреймворк GraphRAG от Microsoft был открыт, сообщество стало больше думать об интеграции графов знаний и технологического стека RAG, например, недавние работы LightRAG, StructRAG и т.д., которые сделали много полезных исследований. KAG, несмотря на некоторые различия между техническим маршрутом и GraphRAG, можно рассматривать в определенной степени как практику в направлении услуг по расширению знаний в профессиональной области GraphRAG, особенно для восполнения недостатков в выравнивании знаний и рассуждениях. Несмотря на некоторые различия между KAG и GraphRAG с точки зрения технологии, KAG можно рассматривать как практику GraphRAG в направлении услуг по расширению знаний в профессиональных областях, особенно для восполнения недостатков в выравнивании знаний и рассуждениях. С этой точки зрения я лично предпочитаю называть его Knowledge constrained GraphRAG.
Родной GraphRAG с иерархическим обобщением на основе различных сообществ может отвечать на относительно абстрактные вопросы высокого уровня, но из-за чрезмерной ориентации на обобщение, ориентированное на запросы (QFS), фреймворк может плохо справляться с мелкоструктурными фактологическими вопросами, а учитывая проблему стоимости, родной GraphRAG имеет много проблем в области кулонов. GraphRAG имеет много проблем в области подвесок, в то время как фреймворк KAG сделал больше оптимизаций на этапе построения графа, таких как выравнивание сущностей и операции стандартизации на основе конкретной схемы, а на этапе запросов он также вводит рассуждения графа знаний на основе символической логики, хотя символические рассуждения исследуются в области графов уже довольно давно, но они еще не были действительно применены к сценариям RAG. Усиление способности RAG к рассуждениям - это направление исследований, на которое автор смотрит с большим оптимизмом, и некоторое время назад Microsoft обобщила четыре уровня способности к рассуждениям в технологическом стеке RAG:
- Уровень-1 Явные факты, Явные факты
- Уровень-2 Неявные факты, скрытые факты
- Уровень-3 Интерпретируемые обоснования, интерпретируемые (подвесные) обоснования
- Уровень-4 Скрытые рационализации, невидимые (кулонный домен) рационализации
В настоящее время способность к рассуждениям большинства фреймворков RAG все еще ограничена уровнем Level-1, а уровни выше Level-3 и Level-4 подчеркивают важность вертикальных рассуждений, и трудность заключается в отсутствии знаний о больших моделях в вертикальной области, и введение символьных рассуждений на этапе запроса в фреймворке KAG можно рассматривать как исследование этого направления в определенной степени, и можно предвидеть, что в последующие годы будет проведена волна новых исследований в области рассуждений RAG. Можно предположить, что RAG-рассуждения могут вызвать новую волну исследований, таких как дальнейшее объединение собственных способностей модели к рассуждениям, таких как RL или CoT, и т.д. На данном этапе были предприняты некоторые попытки приземления, которые все еще имеют больше или меньше ограничений.
В дополнение к сессии по рассуждениям, ссылки KAG в разделе "Извлечение информации HippoRAG Применение гибридной стратегии поиска DPR и PPR и эффективное использование PageRank демонстрируют преимущества графов знаний по сравнению с традиционным векторным поиском, и можно предположить, что в будущем в технологический стек RAG будет интегрировано больше алгоритмов поиска по графам.
Конечно, по оценкам специалистов, фреймворк KAG все еще находится на ранней и быстрой стадии итераций, и еще должно быть место для обсуждения конкретной реализации функций, например, имеют ли существующие логические формы планирования и логические формы исполнения полную теоретическую поддержку на уровне проектирования, и не будет ли недостаточной декомпозиции и сбоя в исполнении перед лицом сложных проблем. Будет ли недостаточная декомпозиция, сбой исполнения, но это определение границ и вопросы надежности, как правило, очень трудно справиться с, но и требует много проб и ошибок расходы, если вся цепочка рассуждений слишком сложна, конечный процент неудач может быть выше, в конце концов, различные деградации обратно в стратегию только определенная степень облегчения проблемы. Кроме того, я заметил, что GraphStore в нижней части фреймворка фактически зарезервировал интерфейс инкрементного обновления, но приложение верхнего уровня не показало соответствующих возможностей, что также является особенностью, которую, как я лично понимаю, сообщество GraphRAG требует более активно использовать.
В целом, фреймворк KAG считается очень серьезной работой последнего времени, содержащей множество инновационных моментов, а код действительно подвергся детальной полировке, что, как считается, послужило важным толчком для процесса приземления технологического стека RAG.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты



Нет комментариев...