Глубокий анализ и сравнение девяти основных основ безопасности больших моделей

С быстрым развитием и широким применением крупномасштабных технологий языкового моделирования их потенциальные риски безопасности все чаще оказываются в центре внимания индустрии. Для решения этих проблем многие ведущие технологические компании, организации по стандартизации и исследовательские институты по всему миру разработали и выпустили свои собственные системы безопасности. В этой статье мы рассмотрим и проанализируем девять репрезентативных систем безопасности крупных моделей, чтобы предоставить четкое руководство для практиков в смежных областях.

Рисунок: Обзор структуры безопасности Большой модели
Secure AI Framework (SAIF) от Google (выпуск 2025.04)
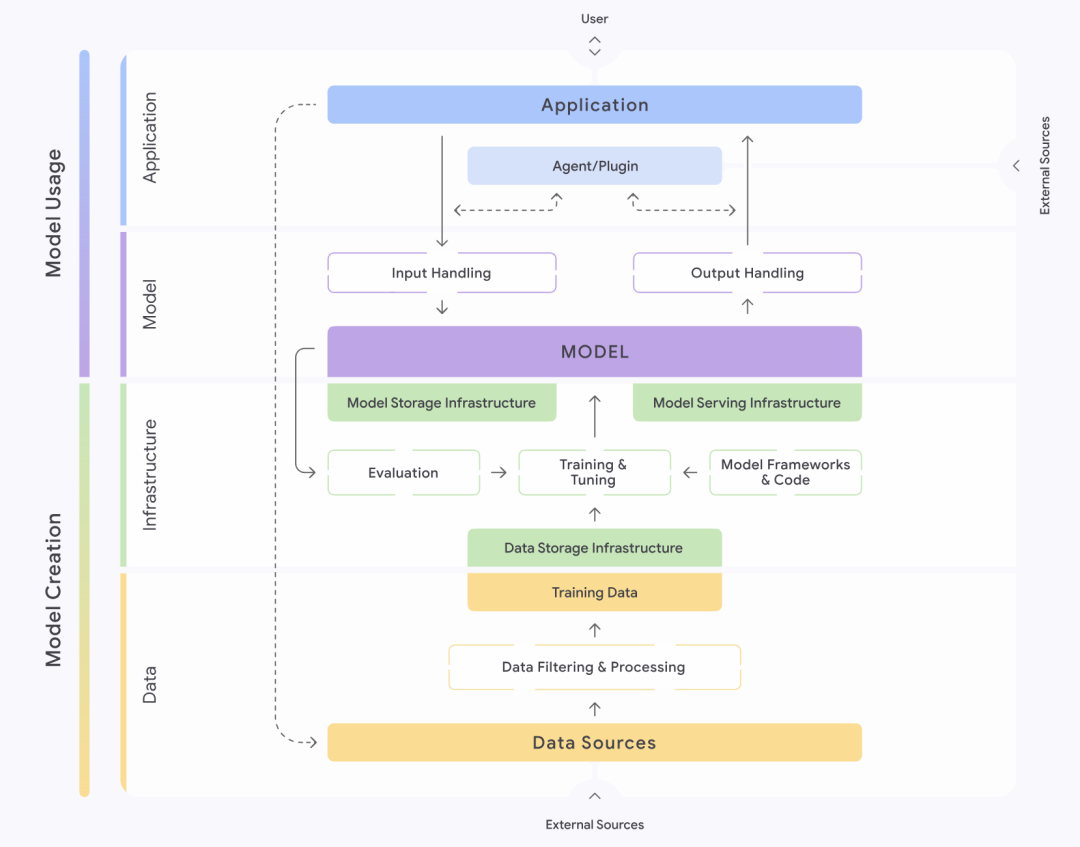
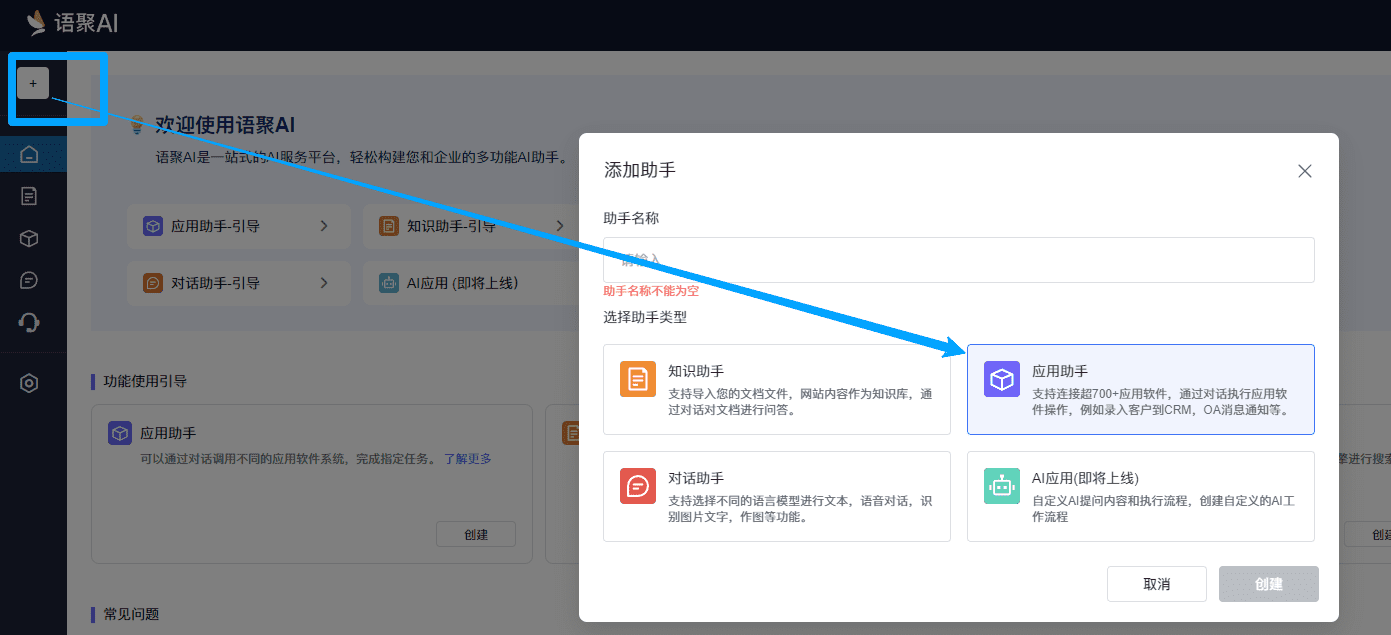
Рисунок: Структура системы Google SAIF
Концепция Secure AI Framework, или SAIF, представленная компанией Google (Google), предлагает структурированный подход к пониманию и управлению безопасностью систем искусственного интеллекта. В рамках этой концепции системы искусственного интеллекта тщательно разделены на четыре уровня: данные, инфраструктура, модель и приложение. Каждый слой далее разбивается на различные компоненты, например, слой данных, который содержит такие ключевые части, как источники данных, фильтрация и обработка данных, данные для обучения и т. д. SAIF подчеркивает, что каждая из этих частей таит в себе определенные риски и опасности.
Основываясь на полном жизненном цикле системы искусственного интеллекта, SAIF определяет и сортирует пятнадцать основных рисков, которые включают отравление данных, несанкционированный доступ к обучающим данным, фальсификацию источника модели, чрезмерную обработку данных, утечку модели, фальсификацию развертывания модели, отказ в обслуживании модели, обратную разработку модели, небезопасные компоненты, инъекции слов реплики, скремблирование модели, утечку конфиденциальных данных, доступ к конфиденциальным данным через экстраполяцию, небезопасный вывод модели и злонамеренное поведение. В ответ на эти пятнадцать рисков SAIF также предлагает пятнадцать профилактических и контрольных мер, которые составляют его основное руководство по безопасности.
Топ-10 угроз безопасности приложений для больших моделей по версии OWASP (выпущено 2025.03)

Рисунок : Топ-10 угроз безопасности для приложений больших моделей OWASP
Проект Open World Application Security Project (OWASP), одна из крупнейших организаций в области кибербезопасности, также выпустил свой фирменный список Top 10 угроз безопасности для приложений больших моделей. OWASP деконструирует приложения больших моделей на несколько ключевых "доменов доверия", включая сам сервис большой модели, сторонние функции плагины, частные базы данных и внешние данные для обучения. Организация выявляет ряд угроз безопасности, как во взаимодействии между этими доменами доверия, так и внутри них.
Десять наиболее значимых угроз безопасности, по мнению OWASP, расположены в порядке убывания их влияния: инъекция в систему, раскрытие конфиденциальной информации, риски цепочки поставок, отравление данных и моделей, неправильная обработка выходных данных, избыточная авторизация, утечка системных данных, уязвимости векторов и встраивания, вводящая в заблуждение информация и неограниченное потребление ресурсов. Для каждой из этих угроз OWASP предлагает рекомендации по предотвращению и борьбе с ними, предоставляя практическое руководство для разработчиков и сотрудников служб безопасности.
OpenAI's Model Safety Framework (постоянно обновляется)
Рисунок : Размеры структуры безопасности модели OpenAI
Являясь лидером в области технологий больших моделей, OpenAI придает большое значение безопасности своих моделей. Система безопасности моделей основана на четырех измерениях: риск оружия массового поражения (CBRN), возможность кибератак, сила убеждения (способность моделей влиять на мнения и поведение людей) и автономность моделей, которые классифицируются как низкий, средний, высокий или серьезный уровень в зависимости от степени потенциального вреда. Перед выпуском каждой модели на основе этой системы должна быть представлена подробная оценка безопасности, известная как Системная карта.
Кроме того, OpenAI предлагает схему управления, включающую согласование ценностей, состязательную оценку и контрольную итерацию. На этапе согласования ценностей OpenAI обязуется сформулировать набор моделей поведения, которые соответствуют универсальным человеческим ценностям, и направлять работу по очистке данных на всех этапах обучения модели. На этапе оценки состязательности OpenAI создаст профессиональные тестовые примеры для полной проверки модели до и после принятия защитных мер и, наконец, подготовит системные карты. На этапе контрольных итераций OpenAI примет стратегию пакетного запуска уже развернутых моделей и продолжит добавлять и оптимизировать меры защиты.
Рамки управления безопасностью ИИ для Комитета по стандартам кибербезопасности (опубликовано 2024.09)
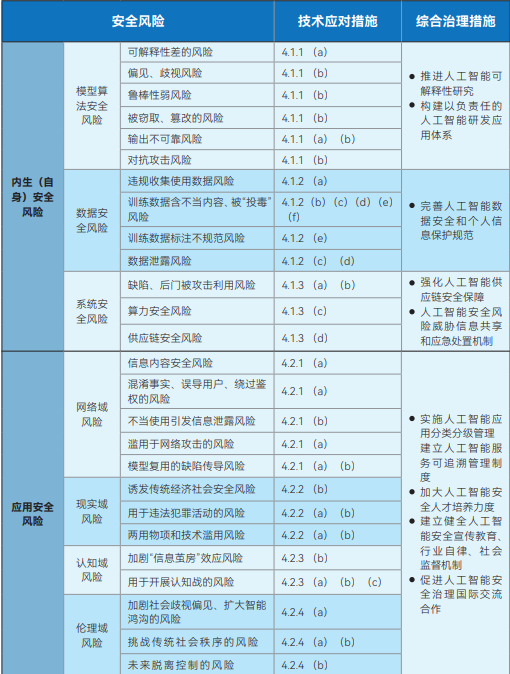
Рисунок : Структура управления безопасностью ИИ Комитета по стандарту Net Security
Документ Artificial Intelligence Safety Governance Framework, выпущенный Национальным техническим комитетом по стандартизации кибербезопасности (NCSSTC), призван стать макроруководством для безопасного развития ИИ. Концепция разделяет риски безопасности ИИ на две основные категории: эндогенные (собственные) риски безопасности и риски безопасности приложений. Эндогенные риски безопасности относятся к рискам, присущим самой модели, которые в основном включают риски безопасности алгоритмов модели, риски безопасности данных и риски безопасности системы. Риски безопасности приложений, с другой стороны, относятся к рискам, с которыми модель может столкнуться в процессе применения, и подразделяются на четыре аспекта: сетевой домен, домен реальности, когнитивный домен и этический домен.
В ответ на эти выявленные риски в документе четко указано, что разработчики моделей и алгоритмов, поставщики услуг, пользователи систем и другие соответствующие стороны должны активно принимать технические меры для их предотвращения по целому ряду аспектов, таких как обучающие данные, арифметические средства, модели и алгоритмы, продукты и услуги, а также сценарии применения. В то же время рамочная программа выступает за создание и совершенствование комплексной системы управления рисками безопасности ИИ, в которой участвуют учреждения, занимающиеся исследованиями и разработками в области технологий, поставщики услуг, пользователи, государственные ведомства, отраслевые ассоциации и общественные организации.
Система стандартов безопасности искусственного интеллекта Комитета по стандартам кибербезопасности V1.0 (выпущена 2025.01)
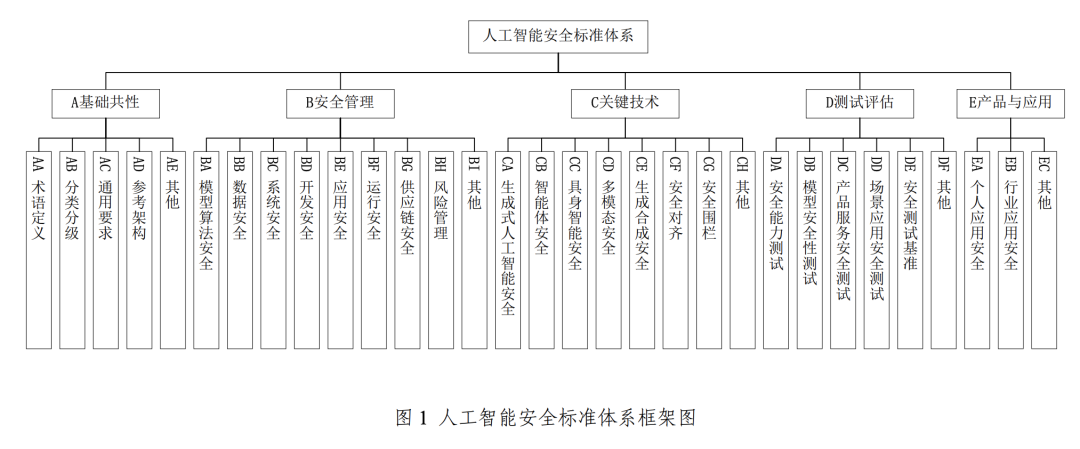
Рисунок: Система стандартов безопасности искусственного интеллекта комитета Net Security Standard V1.0
Для поддержки и реализации вышеупомянутой системы управления безопасностью искусственного интеллекта CNSC запустила систему стандартов безопасности искусственного интеллекта V1.0, в которой систематически отбираются ключевые стандарты, способные помочь предотвратить и устранить соответствующие риски безопасности искусственного интеллекта, и уделяется особое внимание эффективному взаимодействию с существующей национальной системой стандартов в области кибербезопасности.
Эта система стандартов состоит из пяти основных частей: базовая общность, управление безопасностью, ключевые технологии, тестирование и оценка, продукты и приложения. Среди них ключевая часть управления безопасностью охватывает безопасность алгоритмов моделирования, безопасность данных, безопасность системы, безопасность разработки, безопасность приложений, безопасность эксплуатации и безопасность цепочки поставок. Раздел ключевых технологий, с другой стороны, посвящен таким передовым областям, как безопасность генеративного ИИ, безопасность интеллектуального тела, безопасность воплощенного интеллекта (имеется в виду ИИ с физическими объектами, такими как роботы, безопасность которых связана с взаимодействием с физическим миром), мультимодальная безопасность, безопасность генеративного синтеза, безопасность выравнивания и безопасность ограждения.
Big Model Security Practices 2024 от Университета Цинхуа, Лаборатории Чжунгуаньцунь и Ant Group (выпущено 2024.11)
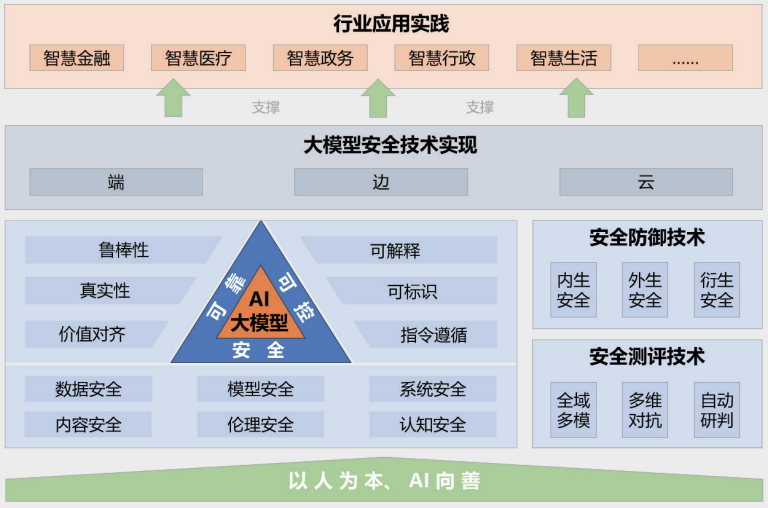
Рисунок : Концепция безопасности большой модели на 2024 год
В докладе "Практика безопасности больших моделей 2024", совместно выпущенном Университетом Цинхуа, лабораторией Zhongguancun и компанией Ant Group, дается представление о безопасности больших моделей с точки зрения объединения промышленности, научных кругов и исследований. Предложенная в докладе система безопасности большой модели состоит из пяти основных частей: руководящий принцип "ориентированность на людей, ИИ во благо"; безопасная, надежная и контролируемая система технологий безопасности большой модели; технологии измерения и защиты безопасности; сквозные, краевые и облачные совместные реализации технологий безопасности; практические примеры применения в различных отраслях.
В докладе подробно описываются многочисленные риски и проблемы, с которыми сталкиваются большие модели в настоящее время, такие как утечка данных, кража данных, отравление данных, атаки противников, командные атаки (вызывающие непреднамеренное поведение моделей с помощью хорошо продуманных команд), атаки с целью кражи моделей, уязвимости в безопасности оборудования, уязвимости в безопасности программного обеспечения, проблемы безопасности в самой системе, риски безопасности, создаваемые внешними инструментами, генерация токсичного контента, распространение необъективного контента, генерация фальшивой информации, идеологические риски, нарушение интеллектуальной собственности и авторских прав, кризис целостности в сфере образования и проблемы справедливости, вызванные предубеждением. идеологические риски, телекоммуникационное мошенничество и кража личных данных, нарушение интеллектуальной собственности и авторских прав, кризис честности в образовательной индустрии и проблемы справедливости, вызванные предубеждениями. В отчете также предлагаются соответствующие методы защиты от этих сложных рисков.
Отчет об исследовании безопасности больших моделей от Aliyun и ICTA (опубликовано 2024.09)
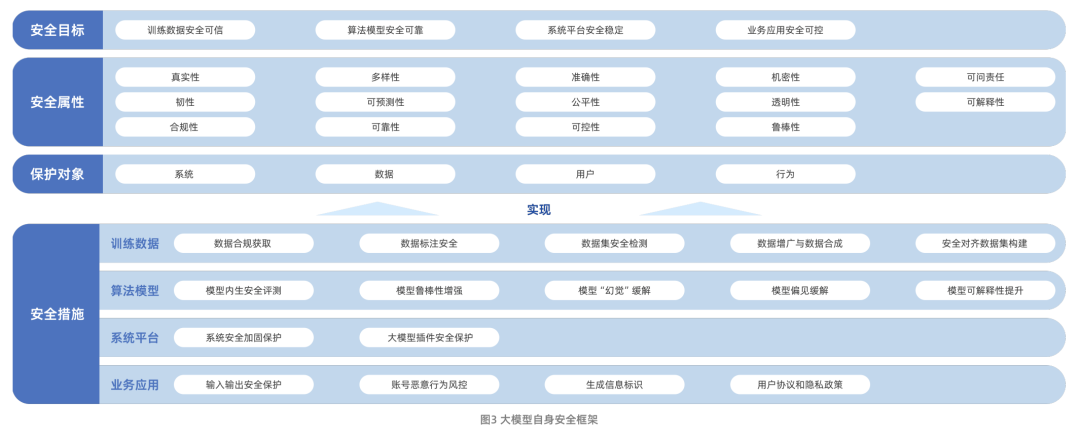
Рисунок: Структура отчета Aliyun & ICTA Big Model Security Research Report
Отчет об исследовании безопасности больших моделей, выпущенный совместно компанией Aliyun и Китайской академией информационно-коммуникационных технологий (CAICT), систематически описывает путь развития технологии больших моделей и проблемы безопасности, с которыми она сталкивается в настоящее время. Эти проблемы в основном включают риски безопасности данных, риски безопасности алгоритмических моделей, риски безопасности системных платформ и риски безопасности бизнес-приложений. Стоит отметить, что в докладе расширены рамки исследования безопасности больших моделей: от безопасности самой модели до использования технологии больших моделей для расширения и усиления традиционных возможностей защиты сетевой безопасности.
Что касается безопасности самой модели, то в отчете построена структура, включающая четыре измерения: цели безопасности, атрибуты безопасности, объекты защиты и меры безопасности. Среди них меры безопасности сосредоточены вокруг четырех основных аспектов: учебных данных, алгоритмов модели, системных платформ и бизнес-приложений, что отражает идею всесторонней защиты.
Исследование Tencent Research Institute's Big Model Security and Ethics Study 2024 (выпущено 2024.01)
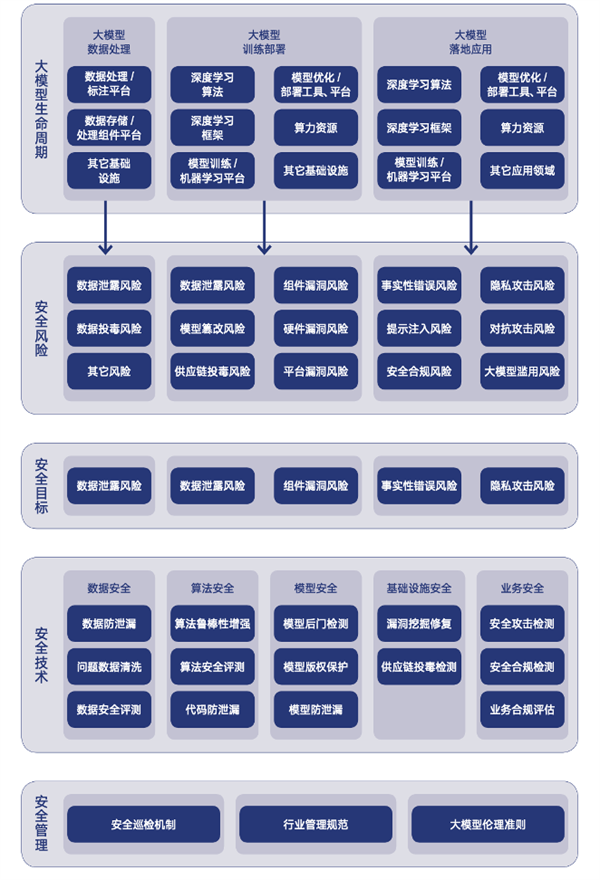
Рисунок: Исследовательский институт Tencent по вопросам безопасности и этики исследований Большой модели
В отчете "Исследование безопасности и этики больших моделей до 2024 года", опубликованном исследовательским институтом Tencent, представлен глубокий анализ тенденций развития технологии больших моделей, а также возможностей и проблем, которые эти тенденции представляют для индустрии безопасности. В отчете перечислены пятнадцать основных рисков, включая утечку данных, отравление данных, фальсификацию моделей, отравление цепочки поставок, уязвимость оборудования, уязвимость компонентов и уязвимость платформы. В то же время в отчете приводятся четыре лучших практики обеспечения безопасности больших моделей: оперативная оценка безопасности, учения по атаке и защите "голубой армии" больших моделей, практика защиты исходного кода больших моделей и схема защиты уязвимостей инфраструктуры больших моделей.
В отчете также освещаются прогресс и будущие тенденции в области согласования ценностей больших моделей. В докладе отмечается, что обеспечение соответствия возможностей и поведения больших моделей человеческим ценностям, истинным намерениям и этическим принципам, чтобы гарантировать безопасность и доверие в процессе сотрудничества между людьми и ИИ, стало одной из основных тем управления большими моделями.
Решение 360 для обеспечения безопасности в виде большой модели (постоянно обновляется)
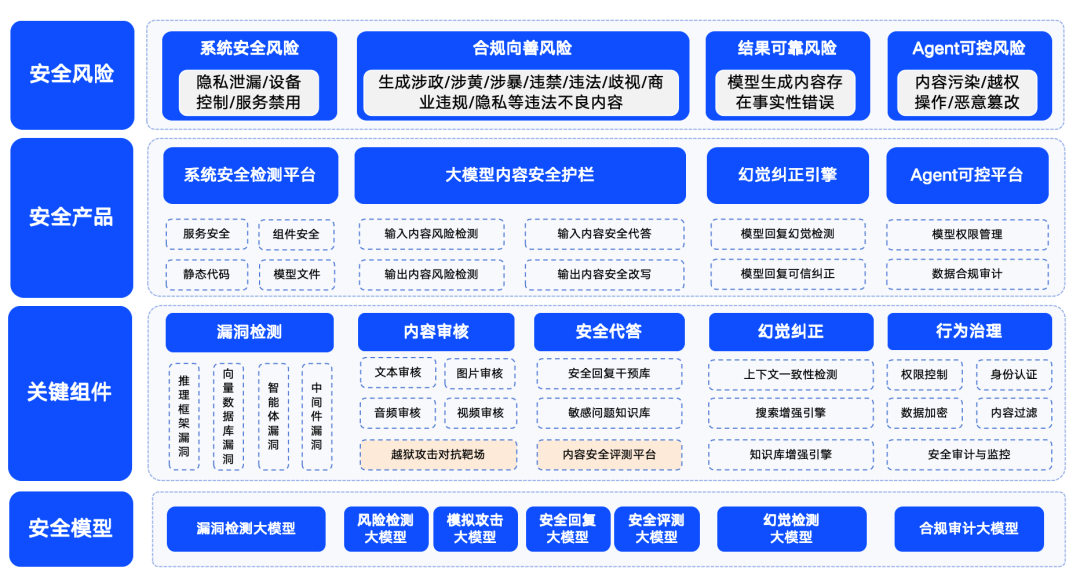
Рисунок: Схема 360 Big Model Security Solution
Qihoo 360 также активно прокладывает поле безопасности больших моделей, и выдвигает свои решения безопасности.360 обобщает риски безопасности больших моделей в четыре категории: системные риски безопасности, риски безопасности контента, доверенные риски безопасности и контролируемые риски безопасности. Среди них системная безопасность в основном относится к безопасности различных типов программного обеспечения в экосистеме большой модели; безопасность контента сосредоточена на риске соответствия входного и выходного контента; доверенная безопасность сосредоточена на решении проблемы "иллюзии" модели (т. е. модель генерирует информацию, которая кажется разумной, но не является реальной); а контролируемая безопасность имеет дело с более сложной проблемой безопасности процесса агента. Контролируемая безопасность решает более сложную проблему безопасности агентских процессов.
Чтобы обеспечить безопасность, качество, надежность и контролируемость больших моделей для применения в различных отраслях, компания 360 создала серию продуктов для обеспечения безопасности больших моделей на основе накопленного ею опыта в области больших моделей. В число этих продуктов входят "360 Smart Forensics", который в основном направлен на обнаружение уязвимостей в экосистеме LLM, "360 Smart Shield", который фокусируется на безопасности контента больших моделей, и "360 Smart Search", который гарантирует надежную безопасность. 360SmartSearch". Благодаря сочетанию этих продуктов, 360 сформировала набор относительно зрелых решений для обеспечения безопасности больших моделей.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты




Нет комментариев...