
Jina AI представляет Reader-LM, революционную модель малого языка для эффективного извлечения основного содержания веб-страниц HTML

Компания Jina AI выпустила Reader-LM-0.5B и Reader-LM-1.5B, две небольшие языковые модели, предназначенные для преобразования сырого, шумного HTML из открытого интернета в чистый формат Markdown. Они поддерживают контекст длиной до 256 тыс. лексем и показывают сравнимую или даже лучшую производительность по сравнению с большими языковыми моделями в задачах преобразования. производительность в задаче преобразования.
предисловие
В апреле 2024 года компания Jina AI выпустила Jina Reader - простой API, который преобразует любой URL в разметку, удобную для LLM. API использует безголовый браузер Chrome для получения исходного кода веб-страницы, извлекает основное содержимое с помощью пакета Readability от Mozilla и преобразует очищенный HTML в разметку, используя regex и библиотеки Turndown для преобразования HTML в разметку. Библиотеки Turndown для преобразования очищенного HTML в markdown.
После релиза отзывы пользователей указывали на проблемы с качеством контента, которые Jina AI решила путем внесения исправлений в существующий конвейер.
С тех пор мы размышляем над вопросом: вместо того чтобы возиться с эвристиками и регулярными выражениями (которые становится все сложнее поддерживать и которые не способствуют многоязычию), можем ли мы решить эту проблему с помощью языковой модели?

Иллюстрация, иллюстрирующая работу reader-lm, заменяющего конвейер эвристик "читабельность+завершение+регекс" небольшой языковой моделью.
О компании Reader-LM
11 сентября 2024 года -- Продолжая внедрять инновации в области искусственного интеллекта для обработки контента и преобразования текстов, компания Jina AI объявила о выпуске своих последних технологических достижений - Reader-LM-0.5B и Reader-LM-1.5B, двух небольших языковых моделей. Эти модели знаменуют собой новую эру обработки необработанного HTML-контента в открытом Интернете, эффективно преобразуя сложный HTML в структурированный формат Markdown, обеспечивая мощную поддержку приложений для управления контентом и машинного обучения в эпоху больших данных.
Прорывная производительность и эффективность
Модели Reader-LM-0.5B и Reader-LM-1.5B достигают производительности, сравнимой или даже превосходящей более крупные языковые модели, сохраняя при этом компактный размер параметров. Поддерживая контекст длиной до 256 тыс. лексем, эти модели справляются с такими шумными элементами современного HTML, как встроенный CSS, скрипты и т. д., создавая чистые, хорошо структурированные файлы Markdown. Это очень удобно для пользователей, которым необходимо извлекать и преобразовывать текст из необработанного веб-контента.

Удобный практический опыт
ИИ Jina предлагает решение этой проблемы в Google Colab (0.5Bответить пением1.5BМодель Reader-LM была разработана таким образом, чтобы пользователи могли легко оценить возможности модели Reader-LM с помощью заметок Reader-LM. Будь то загрузка различных версий модели, изменение URL-адреса обрабатываемого сайта или изучение результатов, пользователи могут делать это в бесплатной облачной среде. Кроме того, Reader-LM скоро будет доступен на рынках Azure и AWS, предоставляя корпоративным пользователям больше возможностей для интеграции и развертывания.
Производительность выше традиционных моделей
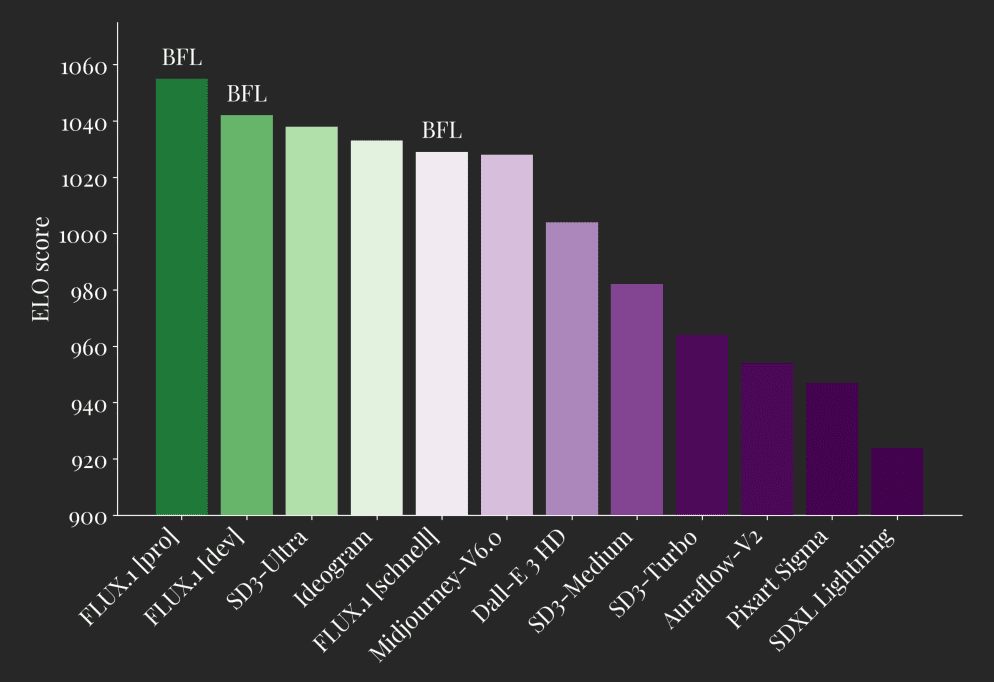
В ходе сравнительных тестов с такими крупными языковыми моделями, как GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B и Qwen2-7B-Instruct, Reader-LM показал хорошие результаты по показателям ROUGE-L, коэффициенту ошибок в словах (WER) и Токен Коэффициент ошибок (TER), а также другие ключевые показатели. Эти оценки демонстрируют лидерство Reader-LM в точности, запоминаемости и способности генерировать чистый Markdown.

Качественные исследования подтверждают его преимущества
Помимо количественной оценки, Jina AI подтвердила превосходство Reader-LM в извлечении заголовков, извлечении основного содержания, сохранении структуры и использовании синтаксиса Markdown с помощью качественных исследований визуального контроля выходного Markdown. Эти результаты подчеркивают эффективность и надежность Reader-LM в реальных приложениях.
Инновационный подход к двухэтапному обучению
Компания Jina AI подробно рассказала о процессе обучения Reader-LM, включая подготовку данных, двухэтапное обучение, а также о том, как они преодолевали проблемы деградации и цикличности модели. Они подчеркнули важность качества обучающих данных и обеспечили стабильность модели и качество генерации с помощью таких технических средств, как сравнительный поиск и повторяющиеся критерии остановки.
окончательный
Reader-LM от Jina AI - это не только большой прорыв в области моделирования малых языков, но и значительное расширение возможностей обработки открытого веб-контента. Выпуск этих двух моделей не только предоставляет разработчикам и специалистам по исследованию данных эффективный и простой в использовании инструмент, но и открывает новые возможности для применения ИИ в области извлечения, очистки и преобразования контента.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты


Нет комментариев...