Илья Суцкевер взорвался на NeurIPS и заявил: предварительное обучение закончится, а выжимка данных - нет!

Разум непредсказуем, поэтому мы должны начать с невероятных, непредсказуемых систем искусственного интеллекта.
Илья наконец-то появился, и ему сразу же есть что сказать. В пятницу Илья Суцкевер, бывший главный научный сотрудник OpenAI, заявил на Global AI Summit, что "мы достигли конца данных, которые можем получить, и больше их не будет". 
Илья Суцкевер, соучредитель и бывший главный научный сотрудник OpenAI, попал в заголовки газет, когда в мае этого года покинул компанию и основал свою собственную лабораторию искусственного интеллекта Safe Superintelligence. После ухода из OpenAI он держался в стороне от СМИ, но в эту пятницу он сделал редкое публичное появление на NeurIPS 2024, конференции по нейронным системам обработки информации в Ванкувере.
"Предварительная подготовка в том виде, в котором мы ее знаем, несомненно, закончится", - заявил Суцкевер со сцены.
В области искусственного интеллекта крупномасштабные модели предварительного обучения, такие как BERT и GPT, достигли больших успехов в последние годы и стали важной вехой на пути технологического прогресса.
Благодаря сложным целям предварительного обучения и огромным параметрам модели, крупномасштабное предварительное обучение может эффективно извлекать знания из больших объемов меченых и немеченых данных. Благодаря хранению знаний в огромных параметрах и их тонкой настройке для конкретной задачи, богатые знания, неявно закодированные в огромных параметрах, могут принести пользу множеству последующих задач. В настоящее время в сообществе ИИ сложилось мнение, что предварительное обучение является основой для последующих задач, а не для обучения моделей с нуля. 
Однако в своем докладе на NeurIPS Илья Суцкевер заявил, что, хотя существующие данные все еще могут служить движущей силой ИИ, отрасль близка к тому, чтобы исчерпать запас новых данных, которые можно было бы назвать пригодными для использования. Он отметил, что эта тенденция в конечном итоге заставит индустрию изменить существующие способы обучения моделей.
Суцкевер сравнивает ситуацию с истощением запасов ископаемого топлива: как нефть является конечным ресурсом, так и контент, создаваемый людьми в Интернете.
"Мы достигли пика объема данных, и больше их не будет", - говорит Суцкевер. "Мы должны использовать те данные, которые есть, потому что существует только один Интернет".
Суцкевер предсказывает, что следующее поколение моделей будет "демонстрировать автономию в реальном виде". С другой стороны, "агент" стал одним из самых популярных слов в искусственном интеллекте.
Помимо "автономности", он также упомянул, что будущие системы будут обладать способностью рассуждать. В отличие от современного ИИ, который в значительной степени полагается на сопоставление шаблонов (на основе того, что модель видела раньше), будущие системы ИИ смогут решать проблемы шаг за шагом, подобно "мышлению".
Суцкевер утверждает, что чем больше система может рассуждать, тем более "непредсказуемым" становится ее поведение. Он сравнивает непредсказуемость "систем с реальной способностью к рассуждениям" с игрой продвинутого ИИ в шахматы - "даже лучшие игроки не могут предсказать их ходы".
Эти системы смогут понять суть вещей на основе ограниченных данных и не запутаться", - сказал он.
В своем выступлении он сравнил масштабирование в системах ИИ с эволюционной биологией, приведя в пример соотношение между весом мозга и тела у разных видов в исследовании. Он отметил, что большинство млекопитающих следуют определенной модели масштабирования, в то время как представители семейства человеческих (предки человека) демонстрируют совершенно иную тенденцию роста соотношения мозга и тела в логарифмическом масштабе.
Суцкевер считает, что подобно тому, как эволюция нашла новую парадигму масштабирования для научного мозга человека, ИИ может выйти за рамки существующих методов предварительного обучения и открыть совершенно новые пути масштабирования. Ниже представлен полный текст выступления Ильи Суцкевера: 
Я хотел бы поблагодарить организаторов конференции за выбор доклада для этой награды (доклад Ильи Суцкевера и др. Seq2Seq был выбран для награды NeurIPS 2024 Time Check Award). Это здорово. Я также хотел бы поблагодарить моих замечательных соавторов Ориола Виньялса и Куока В. Ле, которые стоят прямо перед вами. 

У вас есть картинка, скриншот. 10 лет назад на NIPS 2014 в Монреале был похожий доклад. Это было гораздо более невинное время. Вот мы появляемся на фотографии. Кстати, это было в прошлый раз, а то, что ниже, - в этот.
Теперь у нас больше опыта, и мы, надеюсь, стали немного мудрее. Но здесь я хотел бы немного рассказать о самих учениях и, возможно, сделать 10-летний обзор, потому что многое из того, что происходило в ходе учений, было правильным, а кое-что - не очень. Мы можем оглянуться на них и посмотреть, что произошло и как это привело нас к тому, что мы делаем сегодня. Итак, давайте начнем рассказывать о том, что мы сделали. Первое, что мы сделаем, - это покажем слайды из той же презентации 10-летней давности. Вкратце они сводятся к трем основным пунктам. Модель авторегрессии, обученная на тексте, это большая нейронная сеть, это большой набор данных, и это все.
Итак, давайте начнем рассказывать о том, что мы сделали. Первое, что мы сделаем, - это покажем слайды из той же презентации 10-летней давности. Вкратце они сводятся к трем основным пунктам. Модель авторегрессии, обученная на тексте, это большая нейронная сеть, это большой набор данных, и это все.
Теперь давайте рассмотрим некоторые подробности. 
Вот слайд 10-летней давности, который выглядит неплохо: "Гипотеза глубокого обучения". Здесь мы говорим о том, что если у вас есть большая нейронная сеть с 10 слоями, но она может сделать все, что может сделать человек, за долю секунды. Почему мы подчеркиваем "то, что человек может сделать за долю секунды"? Почему именно эта вещь?
Почему мы подчеркиваем "то, что человек может сделать за долю секунды"? Почему именно эта вещь?
Ну, если вы верите в догму глубокого обучения о том, что искусственные нейроны похожи на биологические или, по крайней мере, не слишком отличаются от них, и считаете, что три настоящих нейрона работают медленно, то человек может обрабатывать все быстро. Я даже имею в виду, если бы в мире был только один человек. Если один человек в мире может сделать что-то за долю секунды, значит, это может сделать и 10-слойная нейронная сеть, верно?
Далее вы просто встраиваете их связи в искусственную нейронную сеть.
Все дело в мотивации. Все, что человек может сделать за долю секунды, может сделать и 10-слойная нейронная сеть.
Мы сосредоточились на 10-слойных нейронных сетях, потому что тогда мы знали, как их обучать, и если бы можно было как-то выйти за пределы этого количества слоев, то можно было бы сделать больше. Но тогда мы могли делать только 10 слоев, поэтому мы делали упор на то, что человек может сделать за долю секунды.
Другой слайд того же года иллюстрирует нашу главную идею о том, что вы можете определить две вещи или, по крайней мере, одну вещь, вы можете определить, что здесь имеет место авторегрессия. 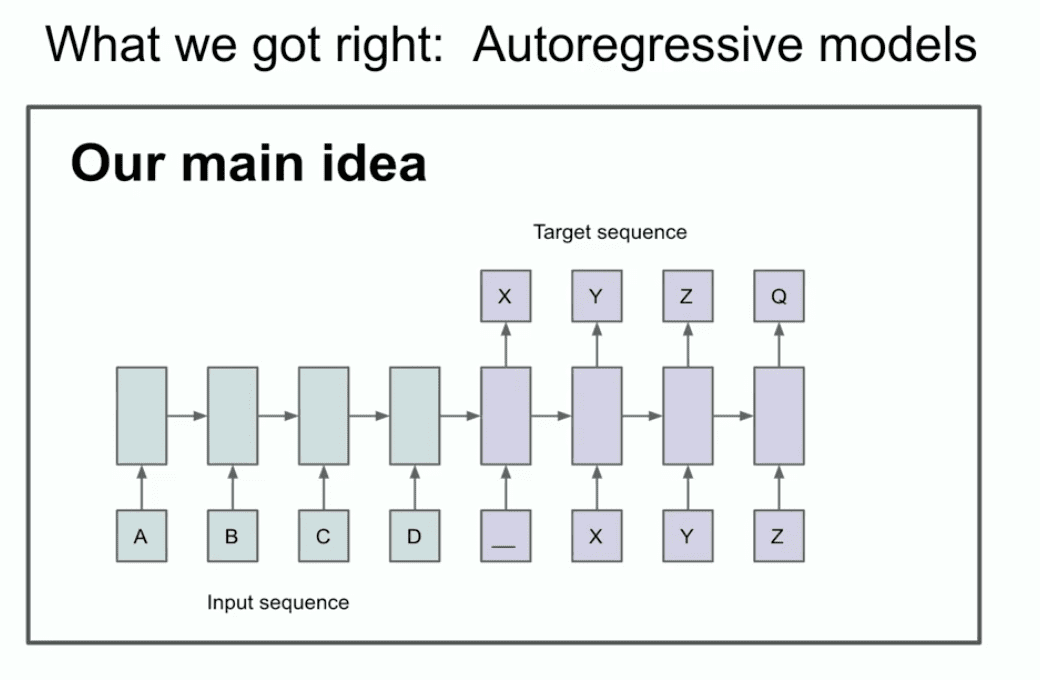
Что, черт возьми, здесь написано? Что на самом деле говорит этот слайд? На этом слайде говорится, что если у вас есть модель авторегрессии и она предсказывает следующее жетон достаточно хороша, то она действительно будет захватывать, фиксировать и удерживать правильное распределение любой последовательности, которая появится следующей.
Это относительно новая вещь, это не первая сеть с авторегрессией, но я думаю, что это первая нейронная сеть с авторегрессией. Мы действительно верили, что если ее хорошо обучить, то можно получить все, что захочешь. В нашем случае это была задача машинного перевода, которая сейчас кажется консервативной, а в то время казалась очень смелой. Сейчас я покажу вам древнюю историю, которую многие из вас, вероятно, никогда не видели, и называется она LSTM.
Для тех, кто не знаком, LSTM - это бедный исследователь глубокого обучения в Трансформатор Что было сделано раньше.
По сути, это ResNet, но повернутый на 90 градусов, так что это LSTM. Итак, это LSTM. LSTM - это как немного более сложный ResNet. Вы можете видеть интегратор, который теперь называется остаточным потоком. но у вас происходит некоторое умножение. Это немного сложно, но это то, что мы делаем. Это сеть ResNet, повернутая на 90 градусов. 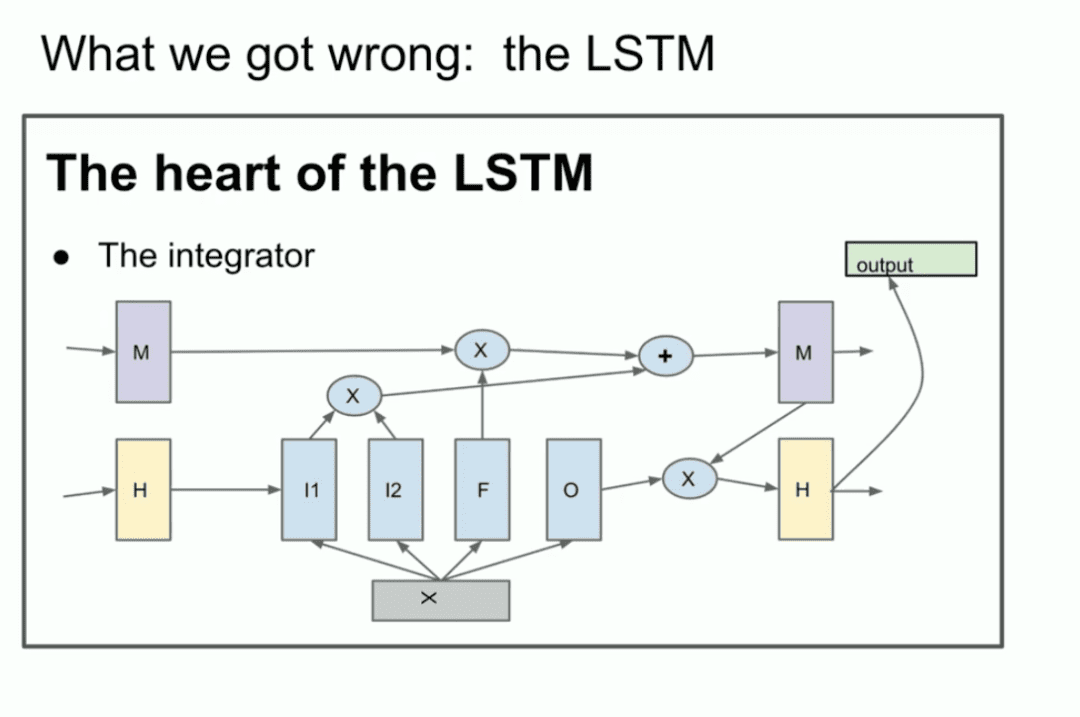
Еще один ключевой момент, который я хотел подчеркнуть в том старом выступлении, - это то, что мы использовали параллелизацию, но не просто параллелизацию.
Мы использовали конвейеризацию, выделяя по одному GPU на каждый слой нейронной сети, что, как мы знаем сейчас, не является разумной стратегией, но в то время мы были не очень умны. Поэтому мы использовали ее и получили 3,5 раза быстрее с 8 GPU. 
Заключительный вывод - самый важный слайд. Он освещает то, что может быть началом законов масштабирования. Если у вас есть очень большой набор данных и вы обучаете очень большую нейронную сеть, успех гарантирован. Можно утверждать, что если быть щедрым, то именно так все и происходит. 
Теперь я хочу упомянуть еще одну идею, которая, на мой взгляд, действительно выдержала испытание временем. Это основная идея глубокого обучения как такового. Это идея коннекционизма. Идея заключается в том, что если вы верите, что искусственные нейроны похожи на биологические нейроны. Если вы верите, что одно немного похоже на другое, то это дает вам уверенность в том, что вы верите в гипермасштабные нейронные сети. Они не обязательно должны быть масштабом с человеческий мозг, они могут быть немного меньше, но вы можете настроить их на выполнение практически всего того, что делаем мы.
Но разница между ним и человеком все равно есть, потому что человеческий мозг сам решает, как перенастроить себя, а мы используем лучшие из имеющихся у нас алгоритмов обучения, которые требуют как можно больше точек данных, так и параметров. Люди справляются с этой задачей гораздо лучше. Все это направлено на то, что можно назвать предтренировочной эрой.
Все это направлено на то, что можно назвать предтренировочной эрой.
А затем у нас есть то, что мы называем моделью GPT-2, моделью GPT-3, законами масштабирования, и я хотел бы особо отметить моего бывшего сотрудника Алека Рэдфорда, а также Джареда Каплана и Дарио Амодея, благодаря усилиям которых вся эта работа стала возможной. 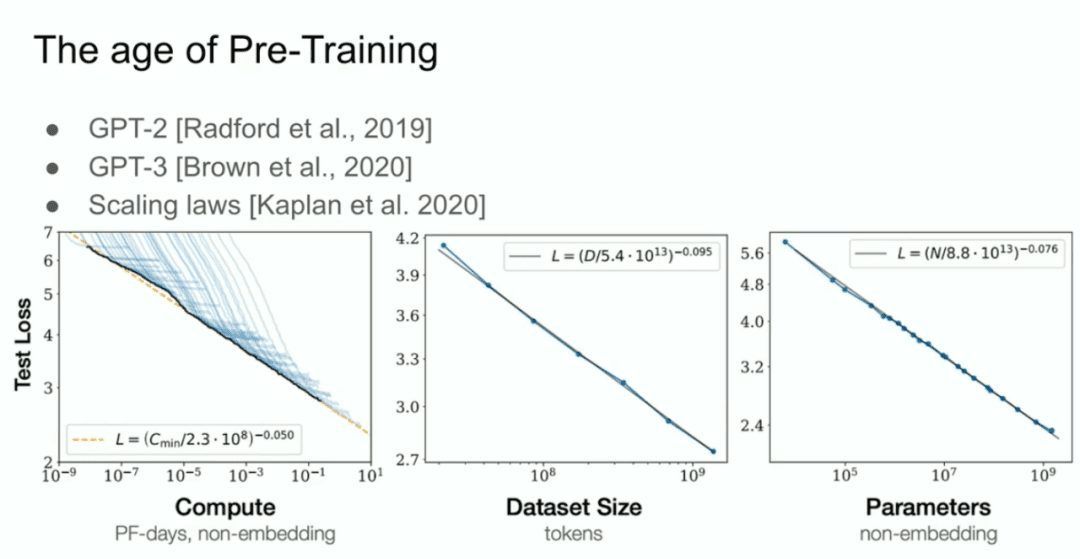 Это эра предварительного обучения, и именно она является движущей силой всех достижений, всех достижений, которые мы наблюдаем сегодня: меганейронные сети, меганейронные сети, обученные на огромных массивах данных.
Это эра предварительного обучения, и именно она является движущей силой всех достижений, всех достижений, которые мы наблюдаем сегодня: меганейронные сети, меганейронные сети, обученные на огромных массивах данных.
Но предтренировочный маршрут в том виде, в котором мы его знаем, несомненно, закончится. Почему он закончится? Потому что компьютеры продолжают развиваться благодаря более совершенному оборудованию, лучшим алгоритмам и кластерам логики, и все эти вещи увеличивают вашу вычислительную мощность, а данные не растут, потому что все, что у нас есть, - это Интернет. 
Можно даже сказать, что данные - это ископаемое топливо для ИИ. Как будто они были созданы определенным образом, и теперь, когда мы их используем, мы максимально используем данные, и лучше уже быть не может. Мы выясняем, что нужно делать с теми данными, которые у нас есть. Я все еще собираюсь работать над этим, и это все еще заводит нас довольно далеко, но проблема в том, что существует только один интернет.
Поэтому здесь я рискну предположить, что будет дальше. На самом деле, мне даже не нужно рассуждать, потому что многие другие тоже рассуждают, и я упомяну их предположения.
- Возможно, вы слышали фразу "Агент интеллектуального тела", она довольно распространена, и я уверен, что в конце концов произойдет нечто такое, что люди почувствуют, что интеллектуальные тела - это будущее.
- Более конкретно, но и несколько расплывчато, - синтетические данные. Но что значит синтетические данные? Выяснить это - огромная задача, и я уверен, что разные люди добиваются в этом деле самых разных успехов.
- Есть также вычисления во время вывода, или, возможно, совсем недавно (OpenAI) o1 - модель o1, которая наиболее ярко демонстрирует, как люди пытаются понять, что делать после предварительного обучения.
Все это очень хорошие вещи. 
Я хочу привести еще один пример из биологии, который мне кажется очень интересным. Много лет назад на этой конференции я также видел презентацию, где кто-то показал этот график, демонстрирующий связь между размером тела и размером мозга у млекопитающих. В данном случае он был огромным. В том докладе, я его четко помню, говорили, что в биологии все запутано, но здесь у вас есть редкий пример очень сильной связи между размером тела животного и его мозга.
Совершенно случайно я заинтересовался этой картиной.  Поэтому я зашел в Google и поискал по картинке.
Поэтому я зашел в Google и поискал по картинке.
На этой картинке перечислены разнообразные млекопитающие, а также не приматы, но в основном те же самые, и примитивы. Насколько я могу судить, примитивы были близкими родственниками людей в их эволюции, например неандертальцев. Например, "Энергичный человек". Интересно, что у них разные наклоны индекса соотношения мозга и тела. Очень интересно.
Это означает, что есть случай, когда биология выводит какую-то другую шкалу. Очевидно, что-то изменилось. Кстати, я хочу подчеркнуть, что эта ось х - логарифмическая шкала. Это 100, 1 000, 10 000, 100 000, опять же в граммах, 1 грамм, 10 грамм, 100 грамм, килограмм. Так что все может быть по-разному.
То, что мы делаем, то, что мы делали до сих пор в плане масштабирования, мы на самом деле обнаружили, что то, как мы масштабируемся, становится приоритетом номер один. Нет никаких сомнений в том, что все, кто здесь работает, разберутся, что к чему. Но я хочу поговорить об этом здесь. Я хочу потратить несколько минут на то, чтобы сделать прогноз на долгосрочную перспективу, с чем сталкиваются все мы, верно?  Весь прогресс, которого мы добиваемся, - это удивительный прогресс. Я имею в виду, что люди, которые работали в этой области 10 лет назад, помнят, насколько все было бессильно. Если вы пришли в область глубокого обучения в последние два года, вы, вероятно, даже не можете с этим сравниться.
Весь прогресс, которого мы добиваемся, - это удивительный прогресс. Я имею в виду, что люди, которые работали в этой области 10 лет назад, помнят, насколько все было бессильно. Если вы пришли в область глубокого обучения в последние два года, вы, вероятно, даже не можете с этим сравниться.
Я хочу немного поговорить о "суперинтеллекте", потому что это явно то, к чему идет область и что она пытается построить.
Хотя сейчас языковые модели обладают невероятными возможностями, они также немного ненадежны. Пока неясно, как это совместить, но в конце концов, рано или поздно, цель будет достигнута: эти системы станут настоящими интеллектами. Сейчас же эти системы не являются мощными перцептивными интеллектами; по сути, они только начинают рассуждать. Кстати, чем больше система рассуждает, тем более непредсказуемой она становится.
Мы привыкли к тому, что все глубокое обучение очень предсказуемо. Ведь если вы работали над воспроизведением человеческой интуиции, возвращаясь к времени реакции 0,1 секунды, то какую обработку выполняет наш мозг? Это интуиция, и мы передали AIS часть этой интуиции.
Но, рассуждая, вы видите некоторые ранние признаки того, что рассуждения непредсказуемы. Шахматы, например, непредсказуемы для лучших человеческих игроков. Так что нам придется иметь дело с очень непредсказуемыми системами ИИ. Они будут понимать вещи на основе ограниченных данных и не будут сбиваться с толку.
Все это очень ограничивает. Кстати, я не сказал, как и когда все эти вещи произойдут с "самосознанием", потому что почему бы "самосознанию" не быть полезным? Мы сами являемся частью модели нашего собственного мира.
Когда все это объединится, мы получим системы с качествами и атрибутами, совершенно отличными от тех, что существуют сегодня. Конечно, они будут обладать невероятными и удивительными возможностями. Но проблема с подобной системой заключается в том, что, как я подозреваю, она будет совсем другой.
Я бы сказал, что предсказать будущее тоже невозможно. На самом деле, возможны самые разные вещи. Спасибо всем.
После аплодисментов на конференции Neurlps Илья ответил на несколько коротких вопросов нескольких участников.
Вопрос: Есть ли в 2024 году другие биологические структуры, имеющие отношение к человеческому познанию, которые, по вашему мнению, стоит исследовать подобным образом, или есть другие области, представляющие для вас интерес?
Илья:Я бы ответил на этот вопрос так: если у вас или у кого-то есть понимание конкретной проблемы, например "эй, мы явно игнорируем то, что мозг что-то делает, а мы этого не делаем", и это достижимо, то им стоит углубиться в это направление. Лично у меня нет таких идей. Конечно, это также зависит от уровня абстракции исследования, на котором вы фокусируетесь. Многие люди стремятся разработать биологически вдохновленный ИИ. В каком-то смысле можно утверждать, что биологически вдохновленный ИИ достиг огромного успеха - в конце концов, вся основа глубокого обучения - это биологически вдохновленный ИИ. но с другой стороны, это биологическое вдохновение на самом деле очень, очень ограничено. По сути, это просто "давайте использовать нейроны" - вот и все биовдохновение. Более детальные, глубокие уровни биовдохновения сложнее достичь, но я бы не исключал их. Я думаю, что это может быть очень ценно, если кто-то с особым пониманием сможет открыть какой-то новый ракурс. В: Я хотел бы задать вопрос об автокоррекции.
Вы упомянули, что вывод может быть одним из основных направлений развития моделей в будущем и может стать отличительной особенностью. На некоторых стендовых докладах мы увидели, что существует "иллюзия" текущих моделей. Наш текущий метод анализа того, являются ли модели галлюцинациями (пожалуйста, поправьте меня, если я неправильно понял, вы являетесь экспертом в этой области), в основном основан на статистическом анализе, например, на определении того, есть ли отклонение от среднего значения на некоторое отклонение от стандартного отклонения. Как вы думаете, в будущем, если у модели появится способность рассуждать, она сможет самокорректироваться, как автокоррекция, и таким образом станет основной особенностью будущих моделей? Тогда у модели не будет так много галлюцинаций, потому что она сможет распознавать ситуации, в которых она сама генерирует галлюцинации. Возможно, это более сложный вопрос, но как вы думаете, смогут ли будущие модели понимать и определять возникновение галлюцинаций с помощью рассуждений?
Илья:Ответ: Да.
Я думаю, что описанная вами ситуация очень вероятна. Хотя я не уверен, я бы предложил вам проверить это, и, возможно, такой сценарий уже имел место в некоторых ранних моделях рассуждений. Но в конечном счете, почему бы этому не быть возможным?
В: Я имею в виду, это как функция автокоррекции в Microsoft Word, это основная функция.
Илья:Да, я считаю, что называть его "автокоррекцией" - это преуменьшение. При упоминании слова "автокоррекция" возникают образы относительно простых функций, но концепция выходит далеко за рамки автокоррекции. В целом, однако, ответ положительный.
Спасибо. Следующий - второй вопрошающий.
Вопрос: Привет, Илья. Мне очень понравилась концовка с загадочным белым пятном. Заменят ли ИИ нас, или они превосходят нас? Нужны ли им права? Это совершенно новый вид. Гомо сапиенс (Homo sapiens) породил этот интеллект, и я думаю, что люди из Reinforcement Learning могут подумать, что нам нужны права для этих существ.
У меня есть вопрос, не связанный с этим: как создать правильные стимулы для людей, чтобы они могли пользоваться теми же свободами, что и мы, Homo sapiens?
Илья:Я думаю, что это вопросы, над которыми люди должны больше думать и размышлять. Но на ваш вопрос о том, какие стимулы мы должны создать, я не думаю, что смогу с уверенностью ответить на подобный вопрос. Похоже, речь идет о создании какой-то структуры или модели управления сверху вниз, но я в этом не очень уверен.
Далее следует последний вопрошающий.
В: Здравствуйте, Илья, спасибо за отличную презентацию. Я из Университета Торонто. Спасибо за всю проделанную вами работу. Я хотел бы спросить, как вы думаете, способны ли LLM обобщить многоходовые выводы за пределами распределения?
Илья:Ладно, этот вопрос предполагает, что ответ будет либо "да", либо "нет", но на самом деле так отвечать не стоит. Потому что сначала нам нужно выяснить: что на самом деле означает внераспределительное обобщение? Что такое внутрираспределительное? Что такое внераспределительное? Потому что речь идет о "проверке временем". Я бы сказал, что очень, очень давно, еще до глубокого обучения, люди использовали для машинного перевода сопоставление строк и n-граммы. Тогда люди полагались на статистические таблицы фраз. Представляете? Сложность этих методов составляла десятки тысяч строк кода, просто невообразимая сложность. И в то время обобщение определялось как то, что результат перевода не был буквально идентичен представлению фразы в наборе данных. Теперь мы можем сказать: "Моя модель получила высокие баллы на математическом конкурсе, но, возможно, некоторые идеи для этих математических вопросов когда-то обсуждались на каком-то форуме в Интернете, поэтому модель могла просто их запомнить". Вы можете возразить, что это может быть в пределах распределения, а может быть результатом запоминания. Но я считаю, что наши стандарты обобщения значительно выросли - можно даже сказать, значительно и немыслимо.
Итак, мой ответ: в какой-то степени модели, вероятно, не так хороши в обобщении, как люди. Я считаю, что люди гораздо лучше справляются с обобщением. Но в то же время верно и то, что модели ИИ в некоторой степени способны к обобщению за пределами распределения. Надеюсь, этот ответ будет вам полезен, даже если он звучит немного избыточно.
В: Спасибо.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...