Компания DeepSeek выпустила первую версию модели v3 с открытым исходным кодом, теперь с самой сильной кодовой способностью (в Китае)

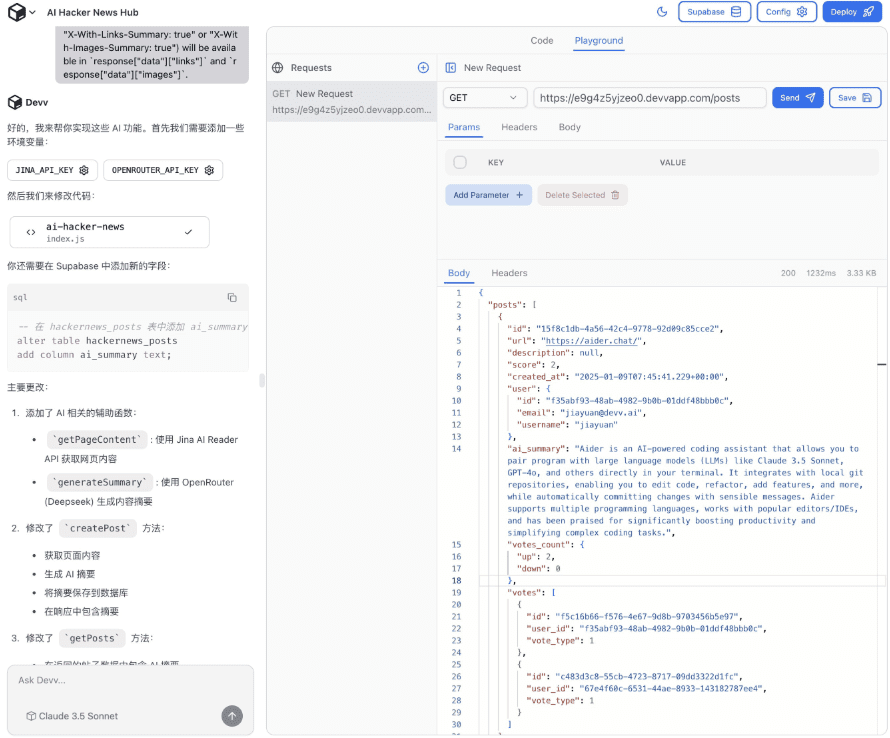
DeepSeek-V3 - это мощная языковая модель Mixture-of-Experts (MoE) с 671 миллиардом общих параметров и 3,7 миллиарда параметров, активируемых для каждой лексемы. В модели используется инновационная архитектура Multi-head Latent Attention (MLA) наряду с хорошо зарекомендовавшей себя архитектурой DeepSeekMoE. CogAgent реализует стратегию балансировки нагрузки без вспомогательных потерь и предлагает цель обучения с предсказанием нескольких токенов для значительного повышения производительности модели. Модель предварительно обучена на 14,8 миллионах разнообразных и высококачественных лексем и проходит этапы тонкой настройки и обучения с усилением под надзором, чтобы полностью раскрыть свой потенциал.
DeepSeek-V3 демонстрирует отличные результаты во многих стандартных бенчмарках, особенно в задачах по математике и коду, что делает его самой сильной базовой моделью с открытым исходным кодом, доступной в настоящее время, с низкой стоимостью обучения, а его стабильность в процессе обучения получила высокую оценку.
Вчера была выпущена первая версия новой серии моделей DeepSeek - DeepSeek-V3, которая одновременно стала частью открытого ресурса. Вы можете пообщаться с последней версией модели V3, зайдя на chat.deepseek.com. Одновременно был обновлен API-сервис, поэтому нет необходимости менять конфигурацию интерфейса. Текущая версия DeepSeek-V3 не поддерживает мультимодальный ввод и вывод данных.
Выравнивание производительности Зарубежный лидер Модели с закрытыми источниками
DeepSeek-V3 - это отечественная модель MoE с 671B параметров и 37B активаций при 14,8T жетон Предварительное обучение проводилось на
Ссылка на статью:
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
DeepSeek-V3 превосходит другие модели с открытым исходным кодом, такие как Qwen2.5-72B и Llama-3.1-405B, в нескольких обзорах и соответствует производительности лучших в мире моделей с закрытым исходным кодом GPT-4o и Claude-3.5-Sonnet.
- энциклопедические знания: Уровень DeepSeek-V3 в задачах, основанных на знаниях (MMLU, MMLU-Pro, GPQA, SimpleQA), значительно улучшился по сравнению с предшественником, DeepSeek-V2.5, и приблизился к текущей лучшей модели, Claude-3.5-Sonnet-1022.
- длинный текст: В среднем DeepSeek-V3 превосходит другие модели на DROP, FRAMES и LongBench v2 по показателям длинных текстов.
- кодирование::DeepSeek-V3 значительно опережает по алгоритмическому кодовому усилию все представленные на рынке модели, не относящиеся к классу O1.; и приближается к Claude-3.5-Sonnet-1022 в сценарии кода инженерного класса (SWE-Bench Verified).
- математикаDeepSeek-V3 значительно превзошел все закрытые модели с открытым исходным кодом на Американском математическом конкурсе (AIME 2024, MATH) и Национальной математической лиге старших классов (CNMO 2024).
- Знание китайского языкаDeepSeek-V3 демонстрирует схожие с Qwen2.5-72B результаты в наборах оценок C-Eval и Pronoun Disambiguation в Education, но более продвинут в C-SimpleQA в Factual Knowledge.

Генерация в 3 раза быстрее
Благодаря алгоритмическим и инженерным инновациям DeepSeek-V3 значительно увеличивает скорость генерации слов с 20 TPS до 60 TPS, что в 3 раза больше, чем у модели V2.5, обеспечивая пользователям более быструю и плавную работу. 
Корректировка цен на услуги API
С выходом более мощного и быстрого обновления DeepSeek-V3 цены на наши услуги модельного API будут изменены.0,5 на миллион входных токенов (попадания в кэш) / $2 (пропуски в кэш), $8 на миллион выходных токеновЦель состоит в том, чтобы постоянно предоставлять всем желающим более качественные услуги моделирования.  В то же время мы решили предложить новую модель на срок до 45 дней: с этого момента и до 8 февраля 2025 года цена на API-сервис DeepSeek-V3 останется на прежнем уровне.0,1 на миллион входных токенов (хиты кэша) / $1 (пропуски кэша), $2 на миллион выходных токеновВышеуказанные скидки доступны как для существующих пользователей, так и для новых пользователей, которые зарегистрируются в этот период.
В то же время мы решили предложить новую модель на срок до 45 дней: с этого момента и до 8 февраля 2025 года цена на API-сервис DeepSeek-V3 останется на прежнем уровне.0,1 на миллион входных токенов (хиты кэша) / $1 (пропуски кэша), $2 на миллион выходных токеновВышеуказанные скидки доступны как для существующих пользователей, так и для новых пользователей, которые зарегистрируются в этот период. 
Весы с открытым исходным кодом и локальное развертывание
DeepSeek-V3 использует FP8 обучение и открытые исходники нативных FP8 весов. Благодаря поддержке сообщества разработчиков SGLang и LMDeploy впервые поддерживают нативный FP8-интерференцию модели V3, а TensorRT-LLM и MindIE - BF16-интерференцию. Кроме того, мы предоставляем скрипты преобразования из FP8 в BF16 для удобства сообщества, чтобы адаптировать и расширить сценарии применения.
Загрузить весовые коэффициенты модели и получить дополнительную информацию о местном развертывании можно на сайте:
https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...