
Разработка и реализация DeepSearch и DeepResearch


Еще только февраль, а Deep Search уже вырисовывается как новый стандарт поиска к 2025 году. Такие гиганты, как Google и OpenAI, представили свои продукты "Глубокого поиска" в попытке опередить технологическую волну. (Мы также гордимся тем, что выпустили наш продукт с открытым исходным кодом.node-deepresearch).
Недоумение Компания X AI Маска пошла дальше, интегрировав возможности глубокого поиска непосредственно в свой компьютер. Grok 3, которая по сути является вариантом Deep Research.
Честно говоря, концепция глубокого поиска не представляет собой ничего особенного; по сути, это то, что в прошлом году мы называли RAG (Retrieval Augmented Generation) или многоцелевые викторины. Но в конце января этого года с Deepseek-r1 После выхода в свет он привлек к себе небывалое внимание и стал расти.
Только в минувшие выходные Baidu Search и Tencent WeChat Search интегрировали Deepseek-r1 в свои поисковые системы.Инженеры ИИ поняли, чтоВключив в поисковую систему процессы долгосрочного мышления и рассуждения, можно добиться более точного и глубокого поиска, чем когда-либо прежде.
Но почему этот сдвиг происходит именно сейчас? На протяжении 2024 года "Глубокий(повторный) поиск", похоже, не привлекал особого внимания. Следует помнить, что в начале 2024 года Стэнфордская лаборатория NLP опубликовала ШТОРМ Проект по созданию длинных отчетов на основе веб-технологий. Может быть, это просто потому, что "Deep Search" звучит более модно, чем "More QA", "RAG" или "STORM"? Честно говоря, иногда удачный ребрендинг - это все, что нужно, чтобы отрасль внезапно приняла то, что уже есть.
Мы считаем, что переломным моментом станет релиз OpenAI в сентябре 2024 года.o1-previewОна ввела концепцию "вычислений в тестовое время" и слегка изменила восприятие отрасли.Термин "вычислять, рассуждая" означает вкладывать больше вычислительных ресурсов в фазу рассуждений (т. е. в фазу, на которой большая языковая модель генерирует конечный результат), а не концентрироваться на фазах до и после обучения. Классические примеры включают рассуждения по цепочке мыслей (Chain-of-Thought, CoT), а также такие подходы, как"Wait" Такие техники, как инъекции (также известные как бюджетный контроль), дают модели более широкие возможности для внутренней рефлексии, например, для оценки нескольких потенциальных ответов, более глубокого планирования и самоанализа перед тем, как дать окончательный ответ.
Такая философия "вычисляй, пока рассуждаешь", а также модели, сосредоточенные на рассуждениях, заставляют пользователей принять понятие "отложенного удовлетворения":Обменяйте длительное время ожидания на более качественные и полезные результаты. Как и в знаменитом Стэнфордском эксперименте с зефиром, дети, которые могут противостоять соблазну съесть одну зефирку сразу, чтобы потом получить две, обычно добиваются больших успехов в долгосрочной перспективе. deepseek-r1 еще больше закрепляет этот пользовательский опыт, который большинство пользователей негласно приняли, нравится вам это или нет.
Это значительно отличается от традиционных потребностей в поиске. В прошлом, если ваше решение не могло дать ответ в течение 200 миллисекунд, это было равносильно провалу. Но в 2025 году опытные разработчики поисковых систем и RAG Инженеры ставят на первое место точность и отзыв, а не задержку. Пользователи привыкли к более длительному времени обработки: пока они видят, что система пытается<thinking>.
В 2025 году отображение процесса рассуждений стало стандартной практикой, и многие интерфейсы чатов отображаются в специальных областях пользовательского интерфейса. <think> Содержание.
В этой статье мы обсудим принципы работы DeepSearch и DeepResearch, рассмотрев нашу реализацию с открытым исходным кодом. Мы представим ключевые проектные решения и укажем на возможные предостережения.
Что такое глубокий поиск?
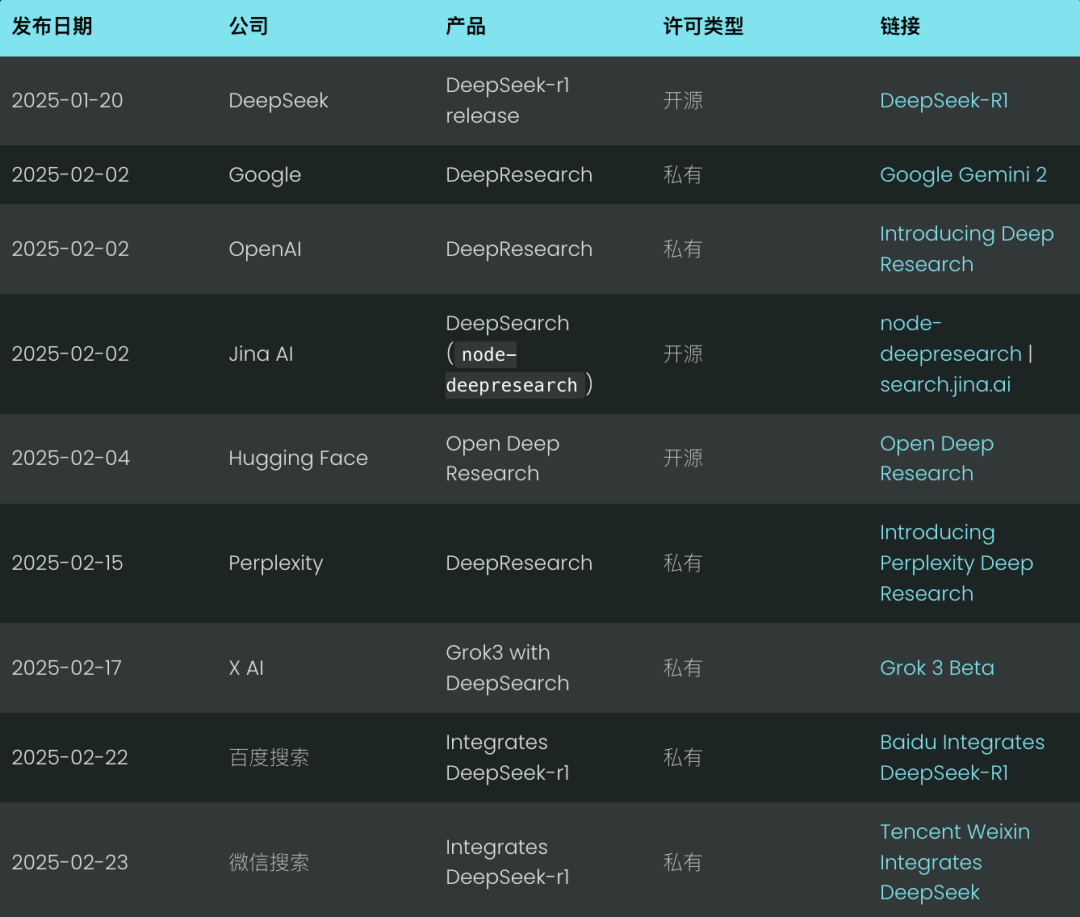
Основная идея DeepSearch - найти оптимальный ответ, проходя три этапа: поиск, чтение и рассуждения, пока не будет найден оптимальный ответ. Сессия поиска исследует Интернет с помощью поисковой системы, а сессия чтения сосредоточена на исчерпывающем анализе конкретных веб-страниц (например, с помощью Jina Reader). Сессия рассуждений отвечает за оценку текущего состояния и принятие решения о том, следует ли разбить исходную проблему на более мелкие подпроблемы или попробовать альтернативные стратегии поиска.
 DeepSearch - непрерывный поиск, чтение веб-страниц и рассуждения до тех пор, пока не будет найден ответ (или за его пределами). жетон (Бюджет).
DeepSearch - непрерывный поиск, чтение веб-страниц и рассуждения до тех пор, пока не будет найден ответ (или за его пределами). жетон (Бюджет).
В отличие от системы 2024 RAG, которая обычно запускает один процесс генерации поиска, DeepSearch выполняет несколько итераций, требующих явных условий остановки. Эти условия могут быть основаны на ограничениях использования токенов или количестве неудачных попыток.
Попробуйте DeepSearch на сайте search.jina.ai и понаблюдайте за тем, как <thinking>в нем и посмотрите, сможете ли вы определить, где происходит зацикливание.
Другими словами.DeepSearch можно рассматривать как LLM-агент, оснащенный различными веб-инструментами, такими как поисковые системы и веб-ридеры.Агент анализирует текущие наблюдения и прошлые действия, чтобы определить дальнейшие действия: дать ли ответ напрямую или продолжить исследование сети. Таким образом, строится архитектура машины состояний, где LLM отвечает за управление переходами между состояниями.
В каждой точке принятия решения у вас есть два варианта: вы можете создать подсказки, которые позволят стандартной генеративной модели выдать конкретные инструкции к действию; или, наоборот, вы можете использовать специализированную модель вывода, такую как Deepseek-r1, чтобы естественным образом вывести следующее действие, которое следует предпринять. Однако даже при использовании r1 вам придется периодически прерывать генеративный процесс, чтобы ввести в контекст результаты работы инструмента (например, результаты поиска, содержимое веб-страниц) и побудить его продолжить процесс рассуждений.
В конечном счете, это всего лишь детали реализации. Независимо от того, создаете ли вы слова-подсказки или просто используете модель вывода, вВсе они следуют основным принципам проектирования DeepSearch: поиск, чтение и вывод.продолжающегося цикла.
А что такое DeepResearch?
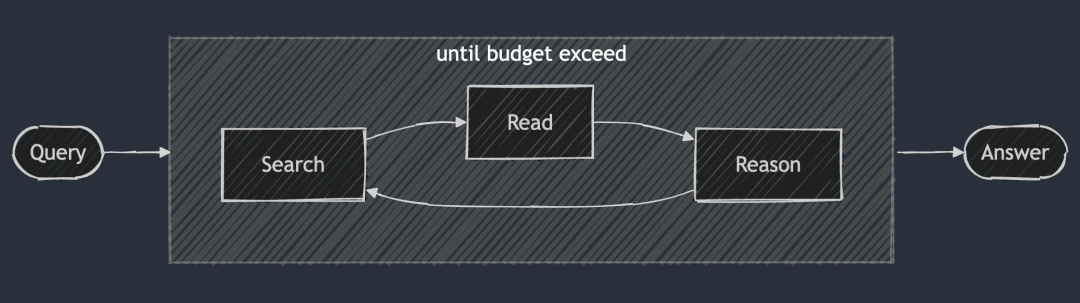
DeepResearch добавляет к DeepSearch структурированную основу для создания длинных исследовательских отчетов. Его рабочий процесс обычно начинается с создания оглавления, а затем систематически применяется DeepSearch к каждому требуемому разделу отчета: от введения, связанных работ, методологии до окончательного заключения. Каждый раздел отчета создается путем ввода в DeepSearch конкретных исследовательских вопросов. Наконец, все разделы были объединены в единую подсказку для улучшения связности общего повествования отчета.
 DeepSearch служит базовым строительным блоком для DeepResearch. Каждая глава строится итеративно с помощью DeepSearch, а затем улучшается общая согласованность перед созданием окончательного длинного отчета.
DeepSearch служит базовым строительным блоком для DeepResearch. Каждая глава строится итеративно с помощью DeepSearch, а затем улучшается общая согласованность перед созданием окончательного длинного отчета.
В 2024 году мы также занимались проектом "Исследование" внутри компании, и тогда, чтобы обеспечить связность отчета, мы использовали довольно глупый подход, который заключался в том, чтобы учитывать все главы в каждой итерации и делать несколько улучшений связности. Но теперь кажется, что такой подход слишком сложен, потому что современные большие языковые модели имеют сверхдлинное контекстное окно, и можно выполнить связную правку за один раз, что гораздо эффективнее.
Однако мы не стали выпускать проект "Исследование" по нескольким причинам:
Самое примечательное, что качество отчетов постоянно не соответствовало нашим внутренним стандартам. Мы протестировали его с помощью двух знакомых внутренних запросов: "Анализ конкурентов Jina AI" и "Стратегия продукта Jina AI". Результаты оказались разочаровывающими, отчеты были посредственными и скудными и не преподнесли нам никаких сюрпризов "а-ха". Во-вторых, надежность результатов поиска оставляет желать лучшего, а иллюзии - серьезная проблема. Наконец, общая читабельность плохая, много повторов и избыточности между разделами. Короче говоря, он ничего не стоит. А сам отчет настолько длинный, что читать его - и пустая трата времени, и непродуктивно.
Однако этот проект также дал нам ценный опыт и породил ряд субпродуктов:
Например.Наше глубокое понимание достоверности результатов поиска и важности проверки фактов на уровне абзацев и даже предложений непосредственно привело к последующей разработке конечной точки g.jina.ai.Мы также осознали ценность расширения запросов и начали вкладывать усилия в обучение малых языковых моделей (SLM) для расширения запросов. Наконец, нам очень понравилось название ReSearch, которое одновременно является умным выражением идеи переосмысления поиска и каламбуром. Было стыдно не использовать его, поэтому мы решили использовать его для ежегодника 2024 года.
Летом 2024 года наш проект "Исследование" принял "инкрементный" подход, сосредоточившись на создании более длинных отчетов. Он начинается с одновременной генерации оглавления отчета (TOC), за которым следует одновременная генерация содержания всех глав. Наконец, каждая глава постепенно пересматривается асинхронным способом, при этом каждый пересмотр учитывает общее содержание отчета. В демонстрационном видеоролике выше мы использовали запрос "Анализ конкурентов для Jina AI".
DeepSearch vs DeepResearch
Многие склонны путать DeepSearch с DeepResearch. Но, на наш взгляд, они решают совершенно разные задачи.DeepSearch - это строительный блок DeepResearch, основной движок, на котором работает последний.
DeepResearch специализируется на написании высококачественных, читабельных и объемных исследовательских отчетов.Это больше, чем просто поиск информации, это систематический проект.Проект DeepSearch был разработан как высокоэффективный инструмент для функции поиска, требующий интеграции эффективных элементов визуализации (например, графиков, таблиц), логичной структуры глав, обеспечивающей плавное перетекание между подглавами, последовательной терминологии во всем тексте, избегания избыточной информации и использования плавных переходов для связи контекстов. Эти элементы не имеют прямого отношения к базовой поисковой функциональности, поэтому мы уделяем больше внимания DeepSearch как компании.
Различия между DeepSearch и DeepResearch приведены в таблице ниже. Стоит отметить, чтоИ DeepSearch, и DeepResearch неотделимы от длинного контекста и моделей вывода, но по разным причинам.
DeepResearch требует длинного контекста для создания длинных отчетов, что вполне объяснимо. И хотя DeepSearch может казаться инструментом поиска, ему также необходимо запоминать предыдущие попытки поиска и содержимое веб-страниц, чтобы планировать последующие операции, поэтому длинные контексты также необходимы.

Узнайте о реализации DeepSearch
Ссылка на открытый источник: https://github.com/jina-ai/node-DeepResearch
В основе DeepResearch лежит механизм круговых рассуждений. В отличие от большинства RAG-систем, которые пытаются ответить на вопросы за один шаг, мы используем итерационный цикл. Он продолжает искать информацию, читать соответствующие источники и рассуждать до тех пор, пока не найдет ответ или не исчерпает бюджет на маркеры. Вот сокращенный скелет этого большого цикла while:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// Получите текущий выпуск из очереди пробелов или используйте исходный выпуск, если он недоступен
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/
/ Генерируйте подсказки на основе текущего контекста и разрешенных действий
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding.
badContext, allKnowledge, unvisitedURLs);/
/ Пусть LLM решает, что делать дальше
const result = await LLM.generateStructuredResponse(system, messages, schema);
thisStep = result.object;/
/ Выполните выбранные действия (ответ, размышление, поиск, посещение, код)
if (thisStep.action === 'answer') {
// Обрабатываем ответные действия...
} else if (thisStep.action === 'reflect') {
// Обработка рефлексивных действий...
} // ... И так далее для других действий
Для обеспечения стабильности и структуры выпуска была принята ключевая мера:Выборочное отключение определенных операций на каждом шаге.
Например, мы отключаем операцию "посетить", если в памяти нет URL-адреса, и запрещаем Агенту повторять операцию "ответить", если последний ответ был отклонен. Этот механизм ограничений направляет агента в нужное русло и не позволяет ему кружить на одном и том же месте.
системная подсказка
При разработке системных подсказок мы используем XML-теги для определения различных частей, что позволяет нам генерировать более надежные системные подсказки и генерируемый контент. В то же время мы обнаружили, что непосредственно в схеме JSON description полей с ограничениями на поля для получения лучших результатов. Действительно, модели вывода, подобные DeepSeek-R1, теоретически могут генерировать большинство слов-подсказок автоматически. Однако, учитывая ограничения на длину контекста и нашу потребность в тонком контроле над поведением агента, такой способ явного написания слов-подсказок на практике более надежен.
function getPrompt(params...) {
const sections = [];// Добавьте заголовок с системными командами
sections.push("Вы - старший научный сотрудник ИИ, специализирующийся на многоступенчатых рассуждениях...") ;
// Добавьте фрагменты накопленных знаний (если они есть)
if (knowledge?.length) {
sections.push("[запись знаний]");;
}// Добавьте контекстную информацию о предыдущих действиях
if (context?.length) {
sections.push("[История действий]");;
}
// Добавьте неудачные попытки и изученные стратегии
if (badContext?.length) {
sections.push("[неудачные попытки]");;
sections.push("[улучшенная стратегия]");;
}
// Определите доступные варианты действий в зависимости от текущего состояния
sections.push("[доступные определения действий]");;
// Добавьте инструкции по форматированию ответа
sections.push("Пожалуйста, отвечайте в правильном формате JSON и строго в соответствии со схемой JSON.");;
return sections.join("nn");
}
Решение проблемы пробелов в знаниях
В DeepSearchВопрос "пробел в знаниях" означает пробел в знаниях, который агенту необходимо заполнить, прежде чем ответить на основной вопрос.Вместо того чтобы пытаться ответить на исходный вопрос напрямую, агент определяет и решает подвопросы, которые создают необходимую базу знаний.
Это очень элегантный способ решения проблемы.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// Всегда добавляйте исходный вопрос в конец очереди
gaps.push(originalQuestion);
}
Он создает очередь FIFO (First In First Out) с механизмом ротации, который следует следующим правилам:
- Новые вопросы, касающиеся пробелов в знаниях, получают приоритет и попадают в начало очереди.
- Первоначальный вопрос всегда находится в конце очереди.
- На каждом этапе система извлекает задания из заголовка очереди для обработки.
Тонкость этой конструкции заключается в том, что она сохраняет общий контекст для всех проблем. То есть, когда проблема пробела в знаниях решена, полученные знания могут быть немедленно применены ко всем последующим проблемам и в конечном итоге помогут нам решить и исходную проблему.
Очередь FIFO против рекурсии
Помимо очередей FIFO, мы также можем использовать рекурсию, которая соответствует стратегии поиска в глубину. Для каждой проблемы "пробела в знаниях" рекурсия создает совершенно новый стек вызовов с отдельным контекстом. Система должна полностью решить каждую проблему "пробела в знаниях" (и все ее потенциальные подпроблемы), прежде чем вернуться к родительской проблеме.
В качестве примера можно привести простую трехуровневую рекурсию задач с глубоким разрывом знаний, где цифры в кружках обозначают порядок решения задач.
В рекурсивном режиме система должна полностью решить Q1 (и ее возможные производные подпроблемы), прежде чем переходить к другим проблемам! Это контрастирует с подходом очереди, который возвращается к Q1 после решения 3 проблем с пробелами в знаниях.
На практике мы обнаружили, что в рекурсивных методах сложно контролировать бюджет. Поскольку подпроблемы могут продолжать порождать новые подпроблемы, трудно определить, сколько бюджета Token должно быть выделено на них без четких указаний. Преимущество рекурсии в плане четкой контекстной изоляции меркнет по сравнению со сложностью контроля бюджета и возможностью отложенной отдачи. В отличие от этого, дизайн очередей FIFO хорошо балансирует между глубиной и широтой, гарантируя, что система будет продолжать накапливать знания, постепенно совершенствоваться и в конечном итоге вернется к исходной проблеме, а не погрузится в потенциально бесконечную трясину рекурсии.
Переработка запросов
Одна из довольно интересных задач, с которой мы столкнулись, заключалась в том, как эффективно переписать поисковый запрос пользователя:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// Переработка запросов на естественном языке в более эффективные поисковые выражения
const optimisedQueries = await rewriteQuery(uniqueRequests);
// Убедитесь в отсутствии дублирования предыдущих поисков
const newQueries = await dedupQueries(optimisedQueries, allKeywords);
// Выполните поиск и сохраните результаты
for (const query of newQueries) {
const results = await searchEngine(query);
if (results.length > 0) {
storeResults(results);
allKeywords.push(query);
}
}
}
Мы обнаружили, чтоПереписывание запросов имеет гораздо большее значение, чем ожидалось, и, пожалуй, является одним из самых важных факторов, определяющих качество результатов поиска.Хороший рерайтер запросов не только преобразует естественный язык пользователя в нечто более подходящее для BM25 Алгоритмы обрабатывают формы ключевых слов, которые также расширяют запрос, чтобы охватить больше потенциальных ответов на разных языках, тонах и форматах контента.
Что касается дедупликации запросов, то сначала мы попробовали схему на основе LLM, но обнаружили, что трудно точно контролировать порог сходства, и результаты оказались неудовлетворительными. В итоге мы выбрали схему jina-embeddings-v3. Ее превосходные результаты в задаче семантического сходства текстов позволили нам легко добиться межъязыковой дедупликации, не беспокоясь о том, что неанглоязычные запросы будут отфильтрованы по ложным срабатываниям. По совпадению, именно модель Embedding в конечном итоге сыграла ключевую роль. Сначала мы не собирались использовать ее для поиска в памяти, но с удивлением обнаружили, что она очень эффективно справляется с задачей дедупликации.
Просмотр веб-содержимого
Важнейшей частью процесса также является веб-ползание и обработка контента, где мы используем Джина Ридер API. В дополнение к полному содержимому веб-страницы мы собираем краткие фрагменты, возвращаемые поисковыми системами, которые служат в качестве вспомогательной информации для последующих рассуждений. Эти фрагменты можно рассматривать как краткое изложение содержания веб-страницы.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// Параллельно обрабатывайте каждый URL
const results = await Promise.all(uniqueURLs.map(async url => {
попробуйте {
// Получение и извлечение содержимого
const content = await readUrl(url);
// Хранится как знание
addToKnowledge(`Что находится в ${url}? `, content, [url], 'url');
return {url, success: true};
} catch (error) {
return {url, success: false};
} finally {
visitedURLs.push(url);
}
}));
// Обновление журналов на основе результатов
updateDiaryWithVisitResults(results).
}
Для облегчения отслеживания мы нормализуем URL-адреса и ограничиваем количество обращений к ним на каждом шаге, чтобы контролировать объем памяти агента.
управление памятью
Ключевой проблемой в многошаговых рассуждениях является эффективное управление памятью агента. Разработанная нами система памяти различает, что считать "памятью", а что "знаниями". Но в любом случае все они являются частью контекста реплики LLM, разделенной различными XML-тегами:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// Запись шагов в журнал
функция addToDiary(step, action, question, result, evaluation) {
diaryContext.push(`
На шаге ${шаг} вы предприняли **${действие}** по вопросу: "${вопрос}".
[Подробности и результаты] [Оценка (если есть)] `); и
}
Учитывая тенденцию к созданию очень длинных контекстов в LLM 2025, мы решили отказаться от векторных баз данных в пользу подхода с использованием контекстной памяти. Память агента состоит из трех частей в рамках контекстного окна: приобретенные знания, посещенные веб-сайты и журналы неудачных попыток. Такой подход позволяет агенту напрямую обращаться к полной истории и состоянию знаний в процессе рассуждений без дополнительных шагов по поиску.
Оценка ответов
Мы также обнаружили, что генерация и оценка ответов лучше осуществляются, если поместить их в разные слова-подсказки.В нашей реализации, когда поступает новый вопрос, мы сначала определяем критерии оценки, а затем оцениваем их по одному. Оценщик обращается к небольшому количеству примеров для оценки согласованности, что более надежно, чем самооценка.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// Оцените каждый критерий в отдельности
const results = [];
for (const criterion of evaluationCriteria) {
const result = await evaluateSingleCriterion(criterion, question, answer, context);
results.push(result);
}
// Определите, прошел ли ответ общую оценку
вернуться {
pass: results.every(r => r.pass),
think: results.map(r => r.reasoning).join('n')
};
}
Бюджетный контроль
Бюджетный контроль - это не только экономия средств, но и обеспечение того, чтобы система адекватно решала вопросы до того, как бюджет будет исчерпан, и избегала преждевременного возврата ответов.С момента выпуска DeepSeek-R1 наше представление о контроле бюджета изменилось с простой экономии бюджета на стимулирование более глубокого мышления и стремление к получению качественных ответов.
В нашей реализации мы явно требуем от системы выявлять пробелы в знаниях, прежде чем пытаться ответить.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
Имея возможность включать и выключать определенные действия, мы можем направить систему на использование инструментов, углубляющих рассуждения.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
Чтобы не тратить жетоны на недействительные пути, мы ограничиваем количество неудачных попыток. При приближении к лимиту бюджета мы включаем "режим зверя", чтобы убедиться, что мы все равно дадим ответ и не уйдем домой с пустыми руками.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// Настройте подсказки, чтобы направлять решительные ответы
system = getPrompt(
diaryContext, allQuestions, allKeywords.
false, false, false, false, false, false, false, false, // отключить другие операции
badContext, allKnowledge, unvisitedURLs.
true // Включить режим зверя
);
// Принудительная генерация ответов
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
thisStep = result.object;
thisStep.isFinal = true;
}
Сообщение подсказки Beast Mode намеренно завышено, четко информируя LLM о том, что теперь он должен принять решительное решение и дать ответ на основе имеющейся информации!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥Главная директива:
- Устраните все колебания! Лучше дать ответ, чем молчать!
- Можно принять локальную стратегию - с использованием всей известной информации!
- Разрешите повторное использование предыдущих неудачных попыток!
- Когда вы не можете принять решение: основываясь на имеющейся информации, нанесите решительный удар!
Неудача - это не вариант! Обязательно достигните своих целей! ⚡️
</action-answer
Это гарантирует, что даже на сложные или неясные вопросы мы сможем дать полезный ответ, а не просто ничего.
вынести вердикт
DeepSearch можно назвать важным прорывом в поисковых технологиях при работе со сложными запросами. Он разбивает весь процесс на независимые этапы поиска, чтения и рассуждения, преодолевая многие ограничения традиционных однораундовых систем RAG или многоходовых систем вопросов и ответов.
В процессе разработки мы постоянно размышляли о том, как должна выглядеть будущая база поисковых технологий в 2025 году, учитывая радикальные изменения во всей поисковой индустрии после выхода DeepSeek-R1. Какие новые потребности появляются? Какие потребности устарели? Какие потребности на самом деле являются псевдопотребностями?
Оглядываясь на реализацию DeepSearch, мы тщательно определили, что было ожидаемо и необходимо, что мы считали само собой разумеющимся и не очень нужным, а что мы вообще не ожидали, но оказалось критически важным.
Во-первых.LLM с длинным контекстом, который генерирует вывод в каноническом формате (например, JSON Schema), необходим!. Возможно, также необходима модель выводов, чтобы улучшить рассуждения о действиях и расширение запросов.
Расширения запросов также абсолютно необходимыНеизбежной частью этого процесса является использование SLM, LLM или специализированных моделей вывода. Но после выполнения этого проекта мы поняли, что SLM может не очень хорошо подходить для этой задачи, поскольку расширение запросов должно быть по своей сути многоязычным и не может ограничиваться простой заменой синонимов или извлечением ключевых слов. Он должен быть достаточно полным, чтобы иметь базу токенов, охватывающую множество языков (чтобы масштаб легко достигал 300 миллионов параметров), и он должен быть достаточно умным, чтобы мыслить нестандартно. Таким образом, масштабирование запросов только за счет SLM может не сработать.
Навыки поиска и чтения в Интернете - это, несомненно, первостепенная задача!К счастью, наш [Reader (r.jina.ai)] работает очень хорошо и является не только мощным, но и масштабируемым, что вдохновило меня на размышления о том, как мы можем улучшить конечную точку поиска (s.jina.ai) - это множество вдохновений, которые можно направить на оптимизацию в следующей итерации.
Векторные модели полезны, но используются в совершенно неожиданных местах. Изначально мы думали использовать ее для поиска в памяти или в сочетании с векторной базой данных для сжатия контекста, но ни то, ни другое не оказалось необходимым. В итоге мы пришли к выводу, что лучше всего использовать векторную модель для дедупликации, по сути, задачи STS (Semantic Text Similarity). Поскольку количество запросов и пробелов в знаниях обычно исчисляется сотнями, вполне достаточно вычислять косинусное сходство непосредственно в памяти без использования векторной базы данных.
Мы не использовали модель Reranker.Теоретически модель Embeddings и Reranker можно использовать в качестве инструмента, помогающего определить, какие URL-адреса должны быть приоритетными для доступа на основе запроса, заголовка URL-адреса и краткого фрагмента. Для моделей Embeddings и Reranker основным требованием является многоязычность, поскольку запросы и вопросы бывают многоязычными. Длительная обработка контекста полезна для моделей Embeddings и Reranker, но не является решающим фактором. Мы не столкнулись с какими-либо проблемами, вызванными использованием векторов, вероятно, благодаря тому, что jina-embeddings-v3 (отличная длина контекста - 8192 лексемы). В совокупностиjina-embeddings-v3 ответить пением jina-reranker-v2-base-multilingual Это по-прежнему мой первый выбор: многоязыковая поддержка, производительность SOTA и хорошая работа с длинными контекстами.
В конечном счете, система Agent оказалась ненужной. С точки зрения дизайна системы мы предпочитали придерживаться собственных возможностей LLM и избегали введения ненужных уровней абстракции. Vercel AI SDK обеспечивает большое удобство в адаптации к различным производителям LLM, что значительно сокращает объем разработки, поскольку для создания нового LLM в системе необходимо изменить всего одну строку кода. Близнецы Переключение между Studio, OpenAI и Google Vertex AI. Управление прокси-памятью имеет смысл, но введение специализированного фреймворка для него сомнительно. Лично я считаю, что чрезмерная зависимость от фреймворков может создать барьер между LLM и разработчиком, а синтаксический сахар, который они предоставляют, может стать бременем для разработчика. Многие фреймворки LLM/RAG уже подтвердили это. Мудрее использовать родные возможности LLM и не привязываться к фреймворкам.
Это сообщение было получено из WeChat: Jina AI
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...