Избежать подводных камней руководство: Taobao DeepSeek R1 установки пакета платных upsell? Научите вас локальному развертыванию бесплатно (с установщиком в один клик)

Недавно на платформе Taobao DeepSeek Явление продажи установочных пакетов вызвало всеобщее беспокойство. Удивительно, что некоторые компании наживаются на этой бесплатной модели ИИ с открытым исходным кодом. Это также отражает бум локальных внедрений, который порождают модели DeepSeek.

При поиске "DeepSeek" на платформах электронной коммерции, таких как Taobao и Jinduoduo, вы можете найти множество продавцов, продающих ресурсы, которые можно было бы получить бесплатно, включая установочные пакеты, пакеты слов для подсказок, учебники и т. д. Даже некоторые продавцы помечают учебники по DeepSeek для продажи. Некоторые продавцы даже продают учебники по DeepSeek по завышенной цене, но на самом деле пользователи могут легко найти большое количество ссылок на бесплатное скачивание, просто воспользовавшись поисковой системой.
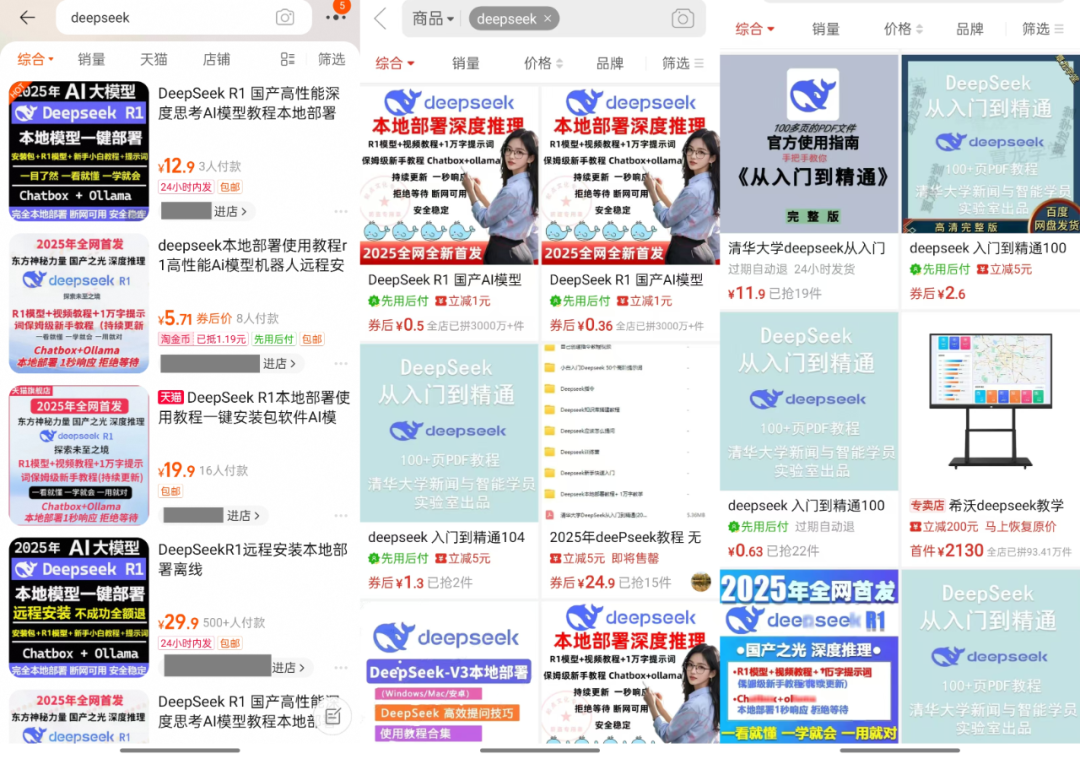
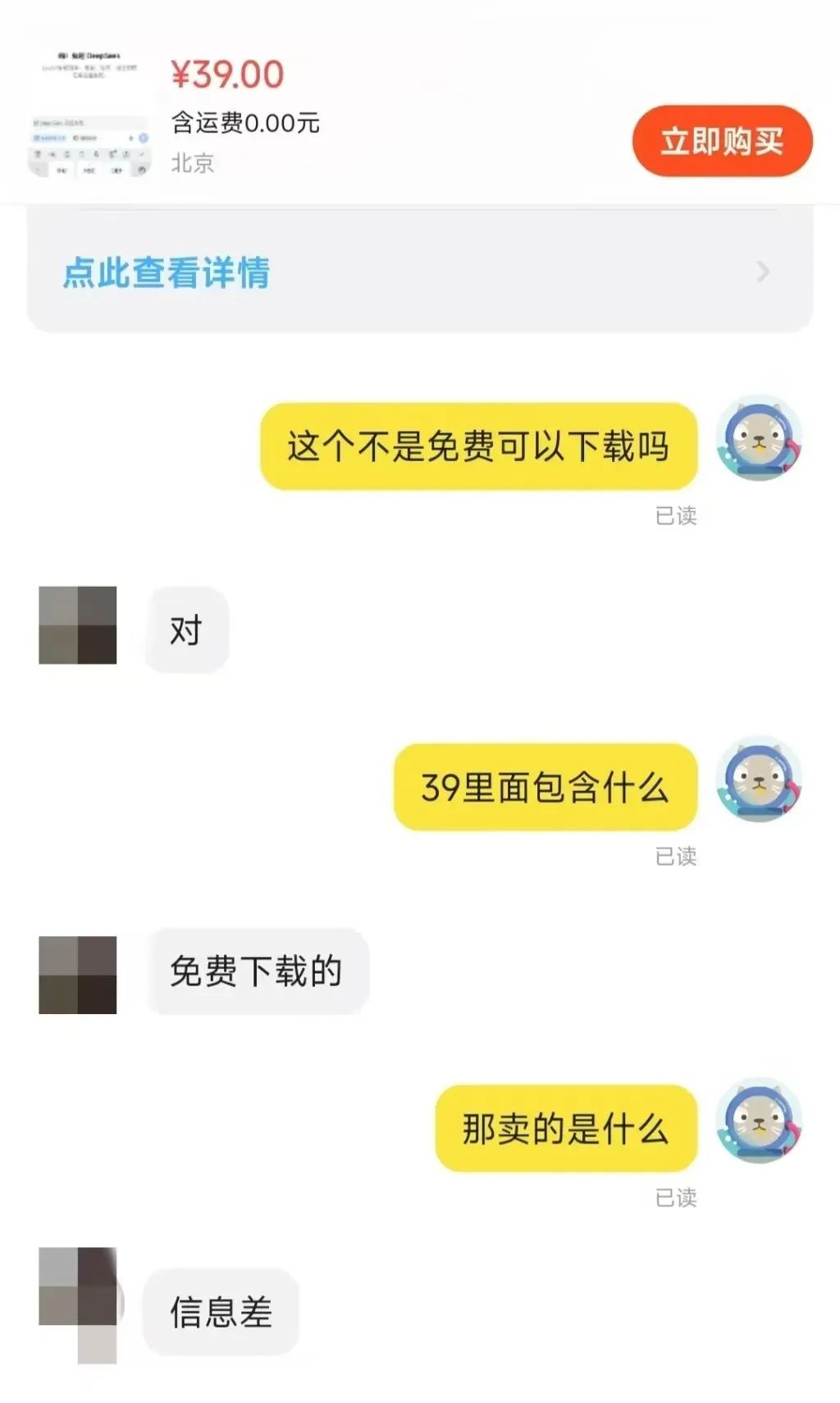
Так за сколько же продаются эти ресурсы? Было замечено, что цена пакета "установщик + учебники + советы" обычно колеблется от 10 до 30 долларов, а большинство продавцов также предоставляют определенную степень поддержки клиентов. Среди них многие товары были проданы сотнями копий, несколько популярных товаров и вовсе достигают тысячи человек, чтобы оплатить шкалу. Более удивительно, что при цене $ 100 пакеты программного обеспечения и учебники, но и 22 человека решили купить.

Таким образом, возможности для бизнеса, открывающиеся благодаря информационному пробелу, очевидны.
В этой статье мы расскажем читателю о том, как развернуть модели DeepSeek локально и без особых затрат. Перед этим мы кратко проанализируем необходимость локального развертывания.
Почему стоит выбрать локальное развертывание DeepSeek-R1?
DeepSeek-R1 модели, хотя они и не являются самыми высокопроизводительными моделями вывода на сегодняшний день, безусловно, являются очень востребованным вариантом на рынке. Однако, пользуясь услугами официальных или сторонних хостинговых платформ напрямую, пользователи часто сталкиваются с перегрузкой серверов.
Модель локального развертывания позволяет эффективно обойти эту проблему. В двух словах, локальное развертывание означает установку моделей ИИ на собственные устройства пользователей, а не на облачные API или онлайн-сервисы. К распространенным методам локального развертывания относятся следующие:
- Легкие локальные рассуждения: Работает на ПК или мобильном устройстве, например, модели формата Llama.cpp, Whisper, GGUF.
- Развертывание серверов/рабочих станций: Выполняйте большие модели на высокопроизводительных GPU или TPU, таких как NVIDIA RTX 4090, A100 и др.
- Частные облачные/интранет-серверыРазвертывание на локальных серверах, например, с помощью таких инструментов, как TensorRT, ONNX Runtime, vLLM.
- Развертывание пограничных устройств: Запуск моделей ИИ на встраиваемых системах или устройствах IoT, таких как Jetson Nano, Raspberry Pi и др.
Различные методы развертывания подходят для разных сценариев применения. Технологии локального развертывания показали свою уникальную ценность в нескольких областях:
- Местные приложения искусственного интеллекта: Создание частных чат-ботов, систем анализа документов и т. д.
- Исследовательский калькулятор: Применение в анализе данных и обучении моделей в биомедицине, физическом моделировании и других областях.
- Функции автономного искусственного интеллекта: Предоставляет возможности распознавания речи, OCR и обработки изображений в среде без сети.
- Аудит и мониторинг безопасности: Помощь в проведении анализа соответствия нормативным требованиям в юридической, финансовой и других отраслях.
В этой статье мы сосредоточимся на легком локальном выводе, который является наиболее актуальным вариантом развертывания для широкого круга индивидуальных пользователей.
Преимущества локального развертывания
Помимо устранения основной причины проблемы "занятого сервера", локальное развертывание дает ряд преимуществ:
- Конфиденциальность и безопасность данныхМодели ИИ можно развертывать локально, без необходимости загружать конфиденциальные данные в облако, что эффективно предотвращает риск утечки данных. Это очень важно для таких отраслей, как финансы, здравоохранение и юриспруденция, где требуется высокий уровень безопасности данных. Кроме того, локальное развертывание помогает компаниям и организациям соответствовать требованиям по соблюдению данных, таким как китайский закон о безопасности данных и GDPR ЕС.
- Низкая задержка и производительность в режиме реального времени: Поскольку все вычисления выполняются локально, без сетевых запросов, скорость вывода полностью зависит от вычислительной производительности локального устройства. Поэтому, если производительность устройства достаточна, пользователи могут получить отличный отклик в реальном времени, что делает локальное развертывание идеальным для таких требовательных к реальному времени сценариев применения, как распознавание речи, автоматизированное вождение и промышленный контроль.
- Долгосрочная экономическая эффективностьНативное развертывание: нативное развертывание позволяет отказаться от платы за подписку на API, что обеспечивает возможность однократного развертывания и долгосрочного использования. Для приложений с низкими требованиями к производительности аппаратные затраты также могут быть снижены за счет развертывания облегченных моделей, таких как 8- или 4-битные квантованные модели INT.
- Доступность в режиме офлайнМодели ИИ можно использовать даже при отсутствии сетевого подключения, что подходит для пограничных вычислений, автономного офиса, удаленной среды и других сценариев. Возможность автономной работы также обеспечивает непрерывность работы критически важных сервисов и позволяет избежать перерывов в работе из-за отключения сети.
- Высокая настраиваемость и управляемостьЛокальное развертывание позволяет пользователям тонко настраивать и оптимизировать модель в соответствии с конкретными потребностями бизнеса. Например, модель DeepSeek-R1 породила множество доработанных и оптимизированных версий, включая неограниченную версию deepseek-r1-abliterated. Кроме того, локальные развертывания не зависят от изменений политики третьих сторон, что обеспечивает больший контроль и позволяет избежать потенциальных рисков, таких как корректировка цен на API или ограничение доступа.
Ограничения локального развертывания
Преимущества локального развертывания значительны, но и ограничения не так уж незначительны, не в последнюю очередь это вычислительные мощности, необходимые для крупномасштабных моделей.
- Затраты на оборудование: Индивидуальные пользователи часто испытывают трудности с запуском моделей с большими параметрами на своем локальном оборудовании, в то время как модели с меньшими параметрами могут иметь низкую производительность. Поэтому пользователям приходится искать компромисс между стоимостью оборудования и производительностью модели. Стремление к созданию высокопроизводительных моделей неизбежно потребует дополнительных инвестиций в оборудование.
- Возможность обработки крупномасштабных задач: Когда перед вами стоят задачи, требующие обработки больших объемов данных, для их эффективного решения часто требуется аппаратная поддержка на уровне сервера. Персональные устройства имеют естественное узкое место в плане вычислительной мощности.
- технологический порог: По сравнению с удобством облачных сервисов, которые можно использовать, просто зайдя на веб-страницу или настроив API, существует технический барьер для локального развертывания. Если пользователям необходимо дополнительно настраивать свои модели, развертывание будет еще сложнее. К счастью, технические барьеры для локального развертывания постепенно снижаются.
- стоимость обслуживания: Обновления и итерации модели и связанных с ней инструментов могут вызвать проблемы с конфигурацией среды, что потребует от пользователя затрат времени и усилий на обслуживание и решение проблем.
Поэтому выбор локального развертывания или онлайн-модели необходимо рассматривать в зависимости от реальной ситуации пользователя. Ниже приведен краткий обзор сценариев, в которых локальное развертывание применимо и неприменимо:
- Сценарии, подходящие для локального развертывания: Высокие требования к конфиденциальности, низкая задержка, долгосрочное использование (например, корпоративные ИИ-помощники, системы юридической аналитики и т. д.).
- Сценарии, не подходящие для локального развертывания: Краткосрочная проверка тестов, высокие арифметические требования, зависимость от очень больших моделей (например, 70B+ уровень параметров).
Частное развертывание с использованием бесплатных серверов в облаке - тоже неплохой вариант, его давно рекомендуют, но он требует определенной технической базы:Развертывание модели DeepSeek-R1 с открытым исходным кодом в режиме онлайн с использованием бесплатных мощностей GPU
Локальное развертывание DeepSeek-R1 в действии
Существует множество способов локального развертывания DeepSeek-R1, но в этой статье мы представим два простых варианта: на основе Оллама методы развертывания и сценарии развертывания с нулевым кодом с помощью LM Studio.
Вариант 1: развертывание DeepSeek-R1 на базе Ollama
Ollama - это доминирующий фреймворк для развертывания и запуска моделей родного языка. Он отличается легкостью и высокой масштабируемостью, а его популярность возросла после выпуска семейства моделей Llama компании Meta. Несмотря на свое название, проект Ollama управляется сообществом и не связан напрямую с разработкой Meta и семейства моделей Llama.

Проект Ollama быстро развивается, и разнообразие моделей и экосистем, которые он поддерживает, стремительно расширяется.
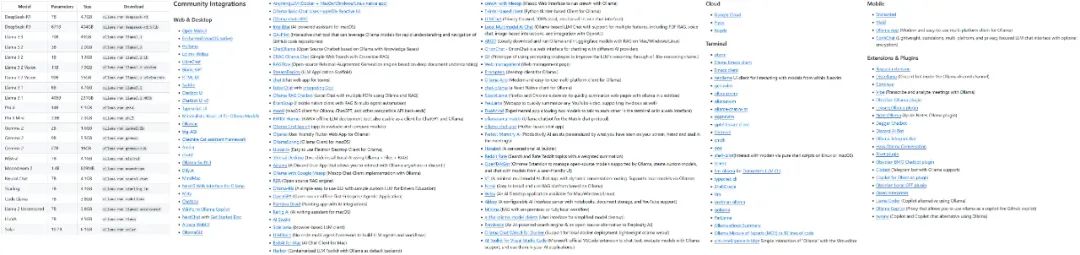
Некоторые из моделей и экологий, поддерживаемых Олламой
Первым шагом в использовании Ollama является загрузка и установка программного обеспечения Ollama. Посетите официальную страницу загрузки Ollama и выберите версию, соответствующую вашей операционной системе.
Скачать: https://ollama.com/download
После установки Ollama необходимо настроить модель искусственного интеллекта для устройства. В качестве примера возьмем DeepSeek-R1. Посетите библиотеку моделей на сайте Ollama, чтобы просмотреть поддерживаемые модели и версии:
https://ollama.com/search
DeepSeek-R1 доступен в 29 различных версиях библиотеки моделей Ollama в масштабах от 1,5 до 67 ББ, включая версии, доработанные, уточненные или квантованные на основе моделей Llama и Qwen с открытым исходным кодом.
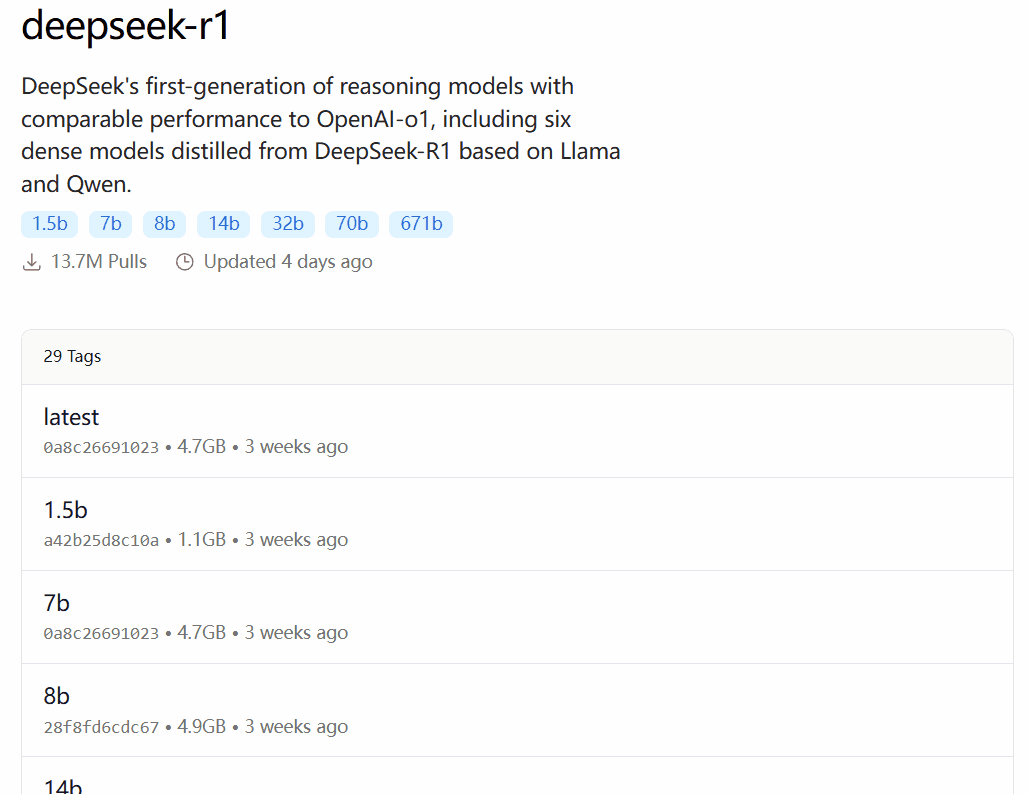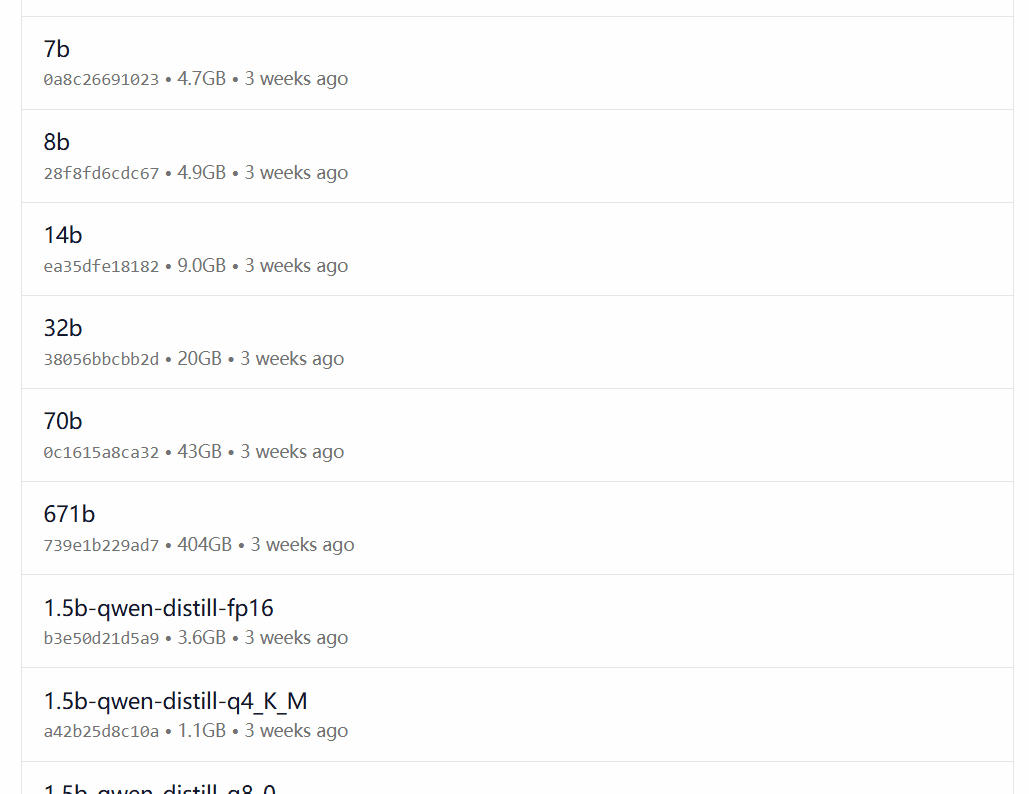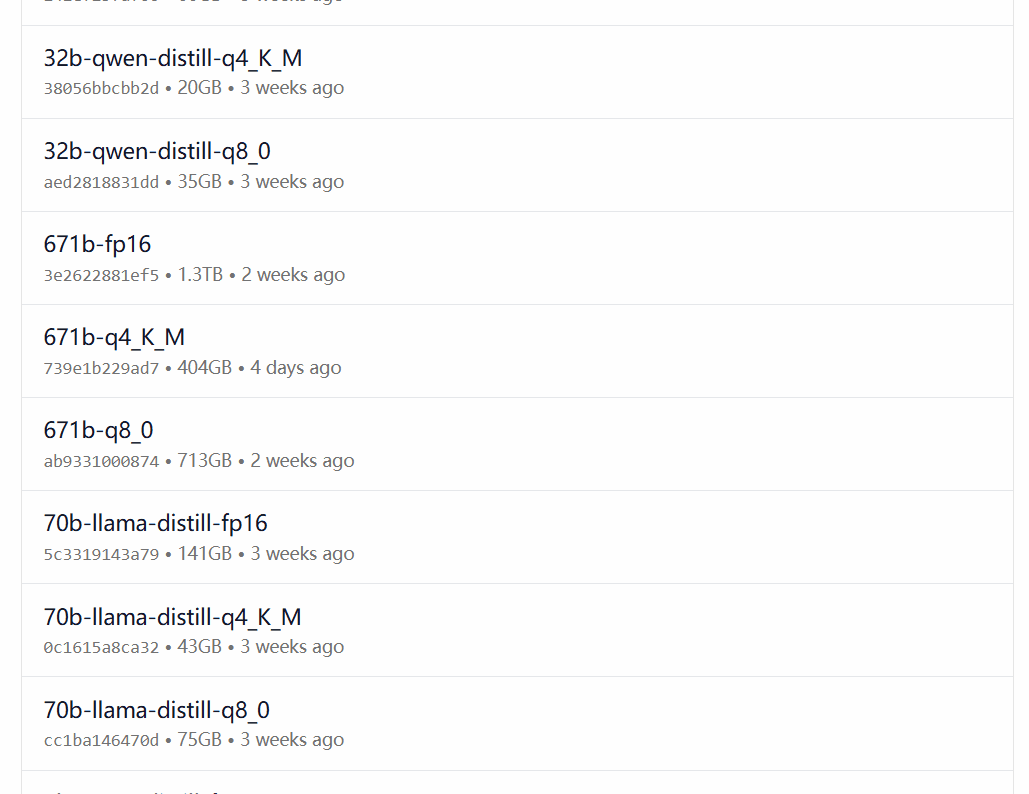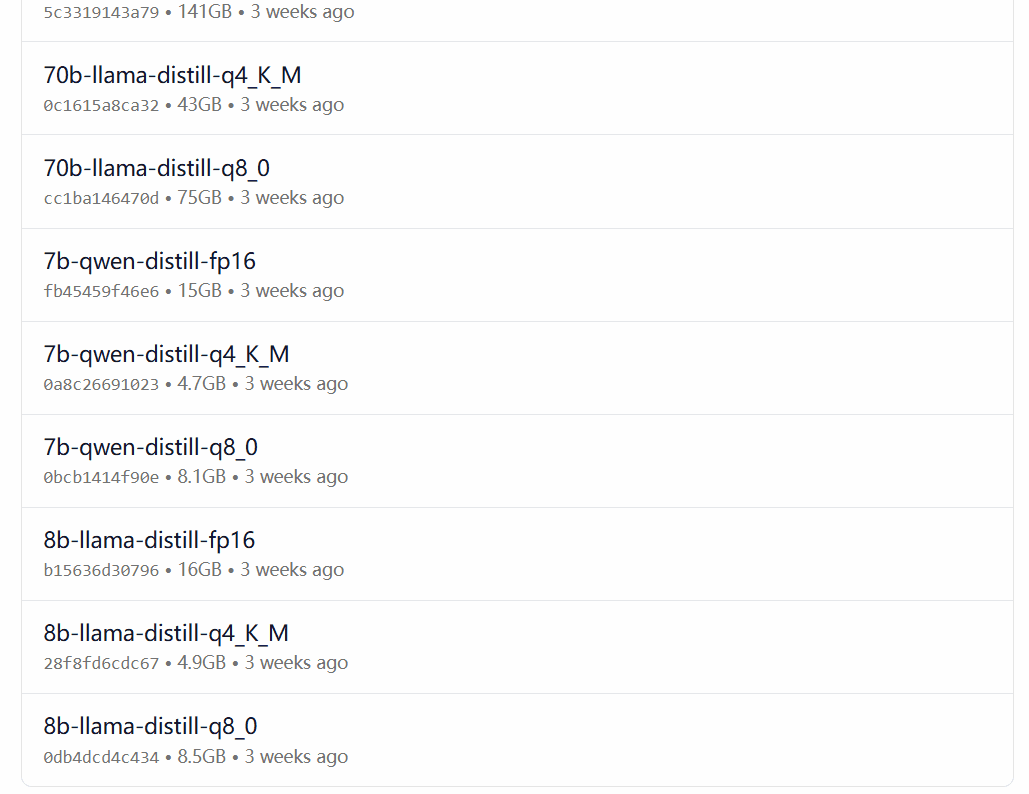
Выбор версии зависит от аппаратной конфигурации пользователя. Авниш из сообщества разработчиков dev.to написал статью с кратким описанием аппаратных требований для различных по размеру версий DeepSeek-R1:
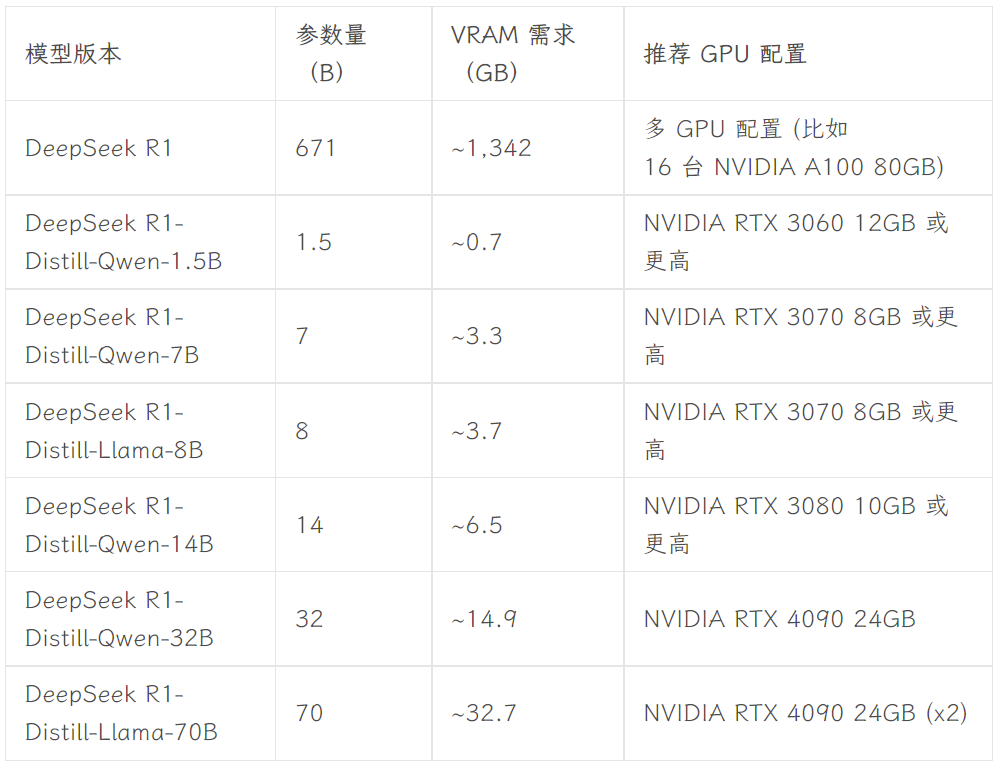
Источник изображения: https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
В данной статье в качестве примера взята версия 8B. Откройте терминал устройства и выполните следующую команду:
ollama run deepseek-r1:8b
Далее просто дождитесь окончания загрузки модели. (Ollama также поддерживает загрузку моделей непосредственно из Hugging Face, с помощью команды ollama run hf.co/{username}/{library}:{quantified version}, например, ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0).

После загрузки модели вы можете пообщаться с 8B-версией DeepSeek-R1 в терминале.

Однако такой тип терминального диалога не является интуитивно понятным и удобным для рядового пользователя. Поэтому необходим удобный графический интерфейс. Существует широкий выбор фронтэндов, таких как Откройте WebUI Получаем что-то вроде ChatGPT Вы также можете выбрать Чатбокс и другие настольные приложения. Дополнительные возможности фронтенда можно найти в официальной документации Ollama:
https://github.com/ollama/ollama
- Откройте WebUI
Если вы выбрали Open WebUI, просто выполните следующие две строки кода в терминале:
Установите Open WebUI:
pip install open-webui
Запустите службу Open WebUI:
open-webui serve
После этого зайдите на сайт http://localhost:8080 в браузере, чтобы познакомиться с веб-интерфейсом, похожим на ChatGPT. В списке моделей Open WebUI вы можете увидеть несколько моделей, которые были настроены локальной Ollama, включая DeepSeek-R1 версий 7B и 8B, а также другие модели, такие как Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder и так далее. Для тестирования выбрана модель DeepSeek-R1 8B:

- Чатбокс
Если вы предпочитаете использовать отдельное настольное приложение, можно рассмотреть такие инструменты, как Chatbox. Этапы настройки также просты и начинаются с загрузки и установки приложения Chatbox:
https://chatboxai.app/zh
После запуска Chatbox войдите в интерфейс "Настройки", выберите OLLAMA API в "Поставщик модели", а затем выберите модель, которую вы хотите использовать, в колонке "Модель". Затем выберите модель, которую вы хотите использовать, в поле "Модель" и установите параметры, такие как максимальное количество контекстных сообщений и температура, в соответствии с вашими потребностями (вы также можете оставить настройки по умолчанию).

После настройки вы можете спокойно общаться с локально развернутой моделью DeepSeek-R1 в Chatbox. Однако результаты тестирования показывают, что модель DeepSeek-R1 7B немного отстает при обработке сложных команд. Это подтверждает предыдущий тезис о том, что отдельные пользователи обычно могут запускать на локальных устройствах только модели с относительно ограниченной производительностью. Однако можно предположить, что по мере развития аппаратных технологий барьеры для локального использования моделей с большими параметрами для индивидуальных пользователей будут снижаться и в будущем, и этот день, возможно, уже не за горами.

**И Open WebUI, и Chatbox поддерживают доступ к моделям DeepSeek, ChatGPT и Claude через API, Близнецы и другие бизнес-модели. Пользователи могут использовать их в качестве внешнего интерфейса для повседневного использования инструментов ИИ. Кроме того, модели, настроенные в Ollama, могут быть интегрированы в другие инструменты, например в приложения для ведения заметок, такие как Obsidian и Civic Notes.
Вариант 2: Развертывание DeepSeek-R1 с нулевым кодом с помощью LM Studio
Пользователи, которые не знакомы с командной строкой или кодом, могут использовать LM Studio для развертывания DeepSeek-R1 с нулевым кодом. Прежде всего, посетите официальную страницу загрузки LM Studio, чтобы загрузить программу, соответствующую вашей операционной системе:
https://lmstudio.ai
Запустите LM Studio после завершения установки. На вкладке "Мои модели" задайте локальную папку для хранения моделей:

Затем скачайте необходимые файлы языковых моделей с сайта Hugging Face и поместите их в указанную выше папку в соответствии с заданной структурой каталогов (в LM Studio есть встроенная функция поиска моделей, но на практике она работает не очень хорошо). Обратите внимание, что файлы моделей нужно скачивать в формате .gguf. Например Расстелите салфетку Коллекция моделей DeepSeek-R1, предоставленных организацией:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
Учитывая конфигурацию оборудования, в данной работе мы выбираем версию DeepSeek-R1 Distillate (номер параметра 14B), основанную на тонкой настройке модели Qwen, и 4-битную квантованную версию: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf.
После завершения загрузки поместите файлы модели в ранее созданную папку в соответствии со следующей структурой каталогов:
Папка модели /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Наконец, откройте LM Studio и выберите модель, которую вы хотите загрузить, в верхней части интерфейса приложения, чтобы общаться с локальной моделью.

Самое большое преимущество LM Studio заключается в том, что она полностью нулевой код, нет необходимости использовать терминал или писать какой-либо код - просто установите программу и настройте папки, что делает ее очень удобной для пользователя.
резюме
Учебные пособия, представленные в этой статье, обеспечивают лишь базовый уровень локального развертывания DeepSeek-R1. Для более глубокой интеграции этой популярной модели в локальные рабочие процессы требуется более детальная настройка, например, настройка системных подсказок и более продвинутая тонкая настройка модели, RAG Интеграция, функция поиска, мультимодальные возможности и возможности вызова инструментов. В то же время, по мере развития специфического для ИИ оборудования и технологий малых моделей, я считаю, что в будущем барьеры для развертывания больших моделей локально будут снижаться. Прочитав эту статью, готовы ли вы попробовать самостоятельно развернуть модель DeepSeek-R1?
Прилагается пакет для установки DeepSeek R1+OpenwebUI одним щелчком мыши
Пакет установки в один клик, предоставляемый Sword27, интегрирует специально для DeepSeek Откройте WebUI
DeepSeek локальное развертывание запуска в один клик, распаковка для использования Поддержка 1.5b 7b 8b 14b 32b, минимальная поддержка 2G видеокарты
Процесс установки
1.AI среда скачать: https://pan.quark.cn/s/1b1ad88c7244
2. Загрузка установочного пакета: https://pan.quark.cn/s/7ec8d85b2f95
Получить помощь можно в оригинальной статье: https://www.jian27.com/html/1396.html
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты




Нет комментариев...