
Инженерная академия ИИ: 2.2 Базовая реализация RAG

представить (кого-л. на работу и т.д.)
Поиск расширенной генерации (RAG) - это мощная техника, которая сочетает в себе преимущества больших языковых моделей с возможностью извлечения релевантной информации из базы знаний. Этот подход повышает качество и точность генерируемых ответов, основывая их на конкретной извлеченной информации.a Этот блокнот предназначен для ясного и краткого введения в RAG и подходит для новичков, которые хотят понять и применить эту технику.
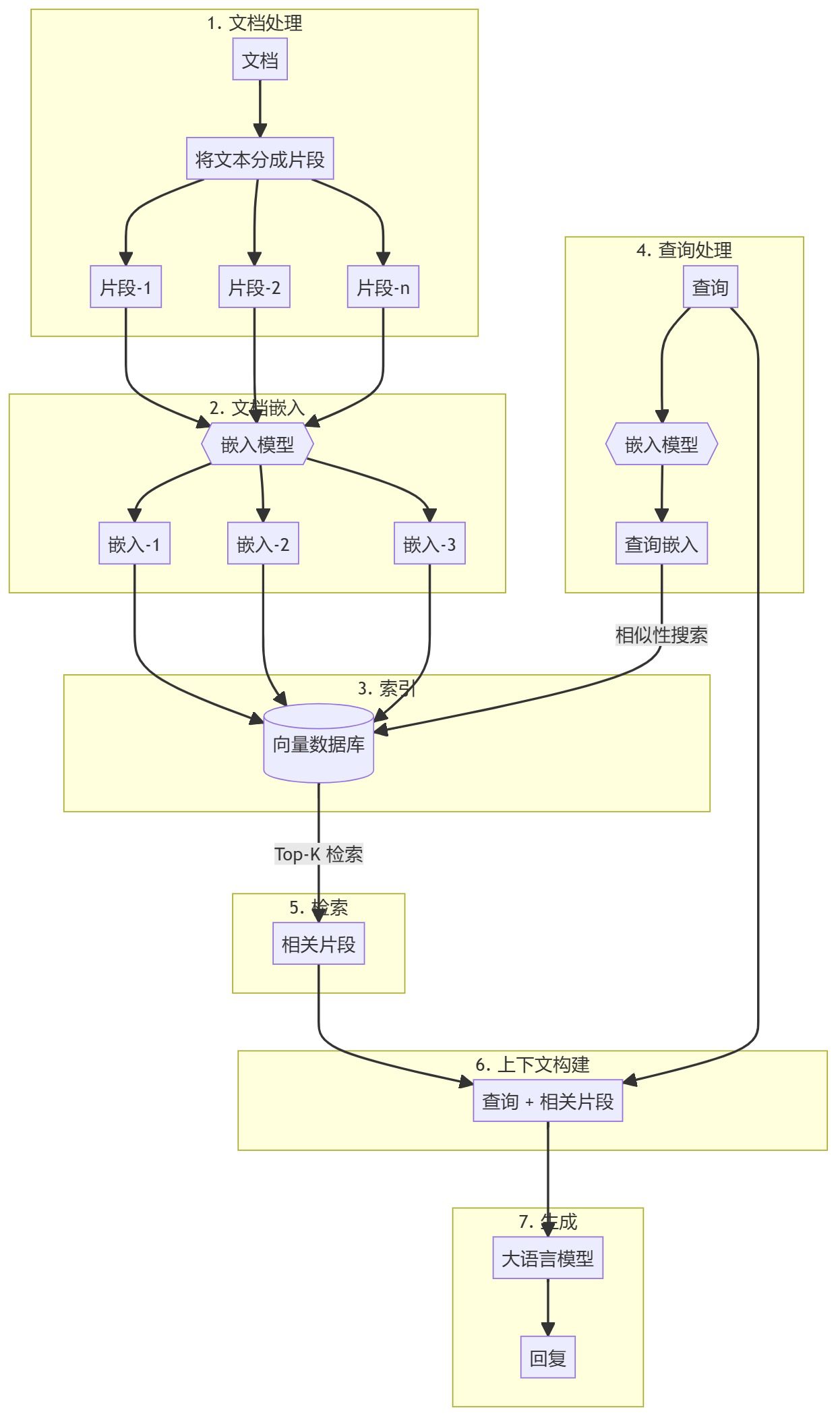
Процесс RAG
торжественная церемония
Блокнот
Вы можете запустить блокнот, поставляемый в этом репозитории. https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
чат-приложение
- Установите зависимости:
pip install -r requirements.txt - Запустите приложение:
python app.py - Динамический импорт данных:
python app.py --ingest --data_dir /path/to/documents
сервер (компьютер)
Чтобы запустить сервер, выполните следующую команду:
python server.py
Сервер предоставляет две конечные точки:
/api/ingest/api/query
локомотив
Традиционные языковые модели генерируют текст на основе шаблонов, полученных из обучающих данных. Однако они не всегда могут дать точный ответ, когда сталкиваются с запросами, требующими конкретной, обновленной или специализированной информации. RAG устраняет это ограничение, внедряя этап поиска, который обеспечивает языковую модель соответствующим контекстом для создания более точных ответов.
Методологические детали
Предварительная обработка документов и создание векторного хранилища
- Распределение документов по частям: Предварительная обработка и разбивка документов базы знаний (например, PDF-файлов, статей) на удобные для поиска фрагменты. Таким образом, создается корпус документов, пригодный для поиска.
- Создать встраиваниеКаждый блок преобразуется в векторное представление с помощью предварительно обученного встраивания (например, встраивание OpenAI). Затем эти документы хранятся в векторной базе данных (например, Qdrant) для эффективного поиска сходства.
Рабочий процесс создания дополнений к поисковым запросам (RAG)
- Ввод запроса:: Пользователи задают запросы, на которые необходимо получить ответ.
- этап поиска: Встраивает запрос в вектор, используя ту же модель встраивания, что и документы. Затем выполняет поиск сходства в базе векторов, чтобы найти наиболее релевантный блок документов.
- Шаги генерации:: Извлеченные фрагменты документов передаются в качестве дополнительного контекста в большую языковую модель (например, GPT-4). Модель использует этот контекст для создания более точных и релевантных ответов.
Ключевые особенности RAG
- контекстуальная значимость: Генерируя ответы на основе фактической полученной информации, модель RAG может давать более точные и контекстуально релевантные ответы.
- масштабируемостьШаг поиска может быть расширен для работы с большими базами знаний, что позволяет модели извлекать содержимое из огромных массивов информации.
- Гибкость в использованииRAG может быть адаптирован к различным сценариям применения, включая вопросы и ответы, составление резюме, рекомендательные системы и многое другое.
- Повышенная точность:: Сочетание поиска и генерации часто дает более точные результаты, особенно для запросов, требующих специфической или холодной информации.
Преимущества этого метода
- Сочетание преимуществ поиска и генерацииRAG эффективно сочетает поисковый подход с генеративной моделью для точного поиска фактов и генерации естественного языка.
- Улучшенная обработка длинных запросов: Метод особенно хорошо справляется с запросами, требующими специфической и редкой информации.
- Адаптация доменаМеханизмы поиска могут быть настроены для конкретных доменов, чтобы гарантировать, что генерируемые ответы основаны на наиболее релевантной и точной информации, специфичной для конкретного домена.
вынести вердикт
Retrieval-Augmented Generation (RAG) - это инновационное объединение поисковых и генеративных технологий, которое эффективно расширяет возможности языковой модели, основывая ее вывод на релевантной внешней информации. Такой подход особенно ценен в сценариях реагирования, требующих точных и контекстно-зависимых ответов (например, поддержка клиентов, академические исследования и т. д.). Поскольку ИИ продолжает развиваться, RAG выделяется своим потенциалом для создания более надежных и контекстно-чувствительных систем ИИ.
предварительные условия
- Предпочтительный Python 3.11
- Jupyter Notebook или JupyterLab
- Ключ API LLM
- Можно использовать любой LLM. В этом блокноте мы используем OpenAI и GPT-4o-mini.
Выполнив эти шаги, вы сможете реализовать базовую систему RAG, которая будет включать в себя реальную, актуальную информацию для повышения эффективности вашей языковой модели в различных приложениях.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...