
Инженерная академия ИИ: 2.10 Автоматизированный ретривер слияний

краткое содержание
Автоматизированная программа поиска слиянийУсовершенствованная система генерации извлечений (RAG)Высокоуровневая реализация Этот подход направлен на повышение уровня осознания контекста и согласованности ответов, генерируемых ИИ, путем объединения потенциально разрозненных и мелких контекстов в более крупные и всеобъемлющие.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
Фоновая мотивация
Традиционные системы генерации расширенного поиска часто не могут обеспечить согласованность в больших контекстах или плохо работают при работе с информацией, охватывающей несколько сегментов текста. Системы автоматического слияния устраняют это ограничение, рекурсивно объединяя наборы дочерних узлов, которые ссылаются на родительский узел, превышающий определенный порог, обеспечивая тем самым более полный и согласованный контекст в процессе поиска и генерации.
Методологические детали
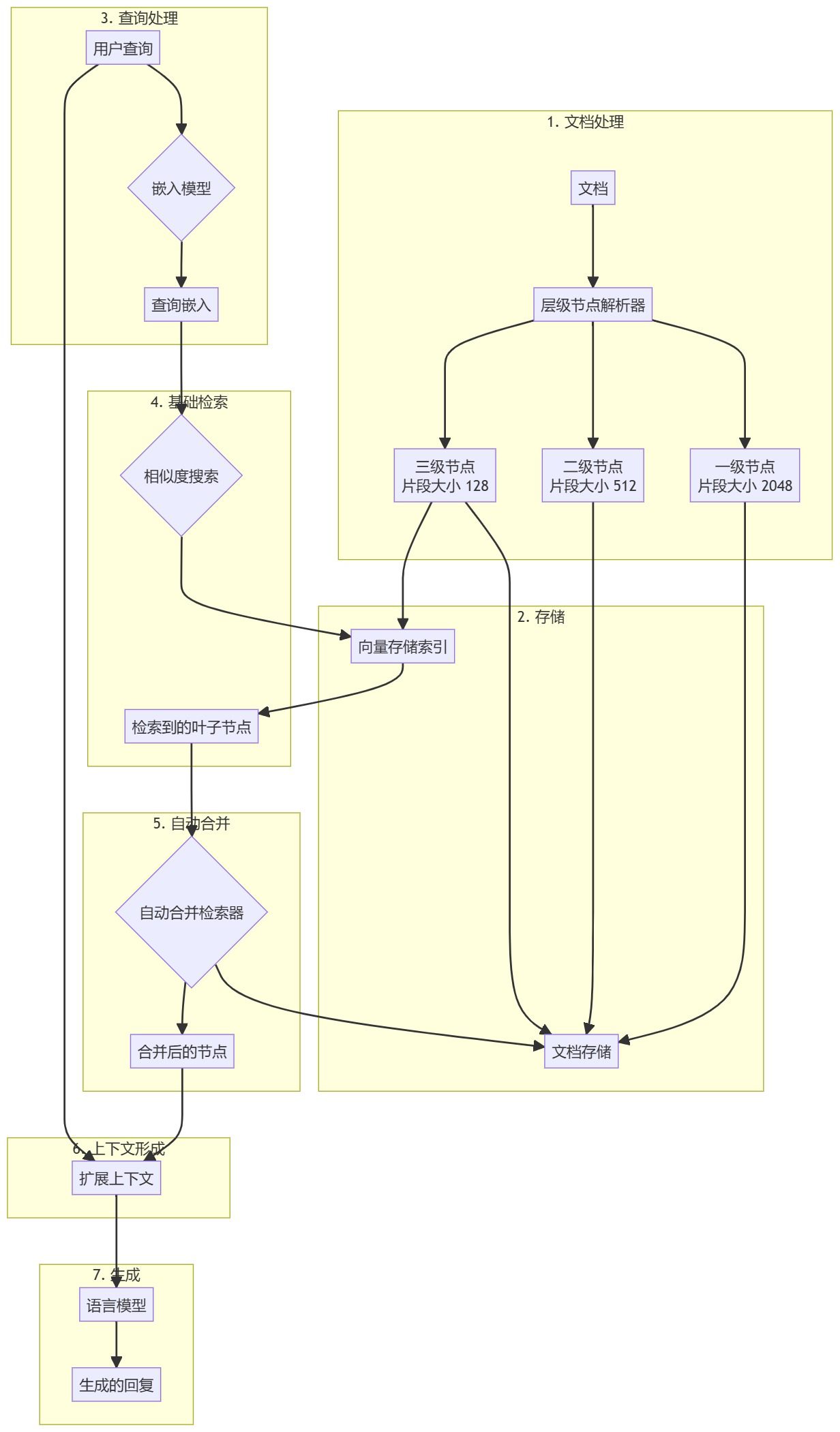
Предварительная обработка документов и создание иерархий
- Загрузка документовЗагрузка и обработка входных документов (например, файлов PDF).
- иерархическое разрешение: Использование
HierarchicalNodeParserСоздает иерархию узлов из документа:- Уровень 1: размер блока 2048
- Уровень 2: размер блока 512
- Уровень 3: размер блока 128
- Хранение узлов: Храните все узлы в хранилище документов, а узлы листьев также индексируются в хранилище векторов.
Усовершенствованный рабочий процесс создания поиска
- Предварительная обработка запросов: Для обработки пользовательских запросов используйте ту же модель встраивания, что и для блоков документов.
- Основной поиск: Базовый поисковик выполняет первоначальный поиск по сходству, чтобы найти релевантные узлы листа.
- Автоматическое слияние::
AutoMergingRetrieverПолученный набор листовых узлов анализируется, и подмножество листовых узлов, которые ссылаются на родительский узел сверх заданного порога, рекурсивно "объединяется". - расширение контекста (вычислительная техника): Объединенные узлы образуют расширенный контекст и объединяются с исходным запросом.
- Генерирование ответа: Генерируйте ответы, вводя контексты расширений и запросы в большую языковую модель (LLM).
Ключевые особенности автоматического поиска слияний
- Иерархическое представление документов: Поддерживайте многоуровневую иерархию блоков документа.
- Эффективный базовый поиск: Достижение быстрого и точного предварительного поиска информации с помощью поиска по векторному сходству.
- Расширение динамического контекста: Автоматическое объединение связанных блоков текста в более крупные, более связные контексты.
- Гибкая реализация: Может использоваться для широкого спектра типов документов и языковых моделей.
Преимущества этого метода
- Повышение контекстуальной согласованности: Обеспечьте более последовательный и полный контекст для более крупной языковой модели, объединив связанные фрагменты текста.
- Гибкая адаптация поиска: Процесс слияния автоматически подстраивается под запрос и результаты поиска, чтобы предоставить контекстно-значимую информацию.
- Эффективная структура хранения: Быстрая реализация базового поиска узлов листа при сохранении иерархической структуры.
- Возможность улучшения качества ответов: Ожидается, что расширенный контекст приведет к более точным и подробным ответам на языковые модели.
Результаты
Результаты экспериментов показывают, что при сравнении автоматического поиска слияния с базовым поисковиком:
- Аналогичные показатели по метрикам корректности, релевантности, точности и семантического сходства.
- При попарном сравнении 52,5% пользователей предпочли ответ поисковика с автоматическим слиянием.
Эти результаты показывают, что производительность автоматизированной системы поиска слияний сопоставима с традиционными методами поиска или даже немного превосходит их.
вынести вердикт
Автоматизированная система поиска слияний обеспечивает усовершенствованный метод улучшения RAG процесс поиска в системе. Благодаря динамическому объединению релевантных текстовых блоков в более крупные, более связные контексты, он устраняет некоторые ограничения традиционных методов поиска на основе текстовых блоков. Хотя первые результаты показывают положительные перспективы, ожидается, что дальнейшие исследования и оптимизация позволят значительно улучшить качество и согласованность ответов.
предварительные условия
Чтобы внедрить эту систему, вам понадобятся:
- Большая языковая модель, способная генерировать текст (например, GPT-3.5-turbo, GPT-4).
- Модель встраивания для преобразования текстовых блоков и запросов в векторные представления.
- Векторные базы данных для эффективного поиска сходства (например, FAISS).
- Хранилище документов для хранения полной иерархии узлов.
- предложение
LlamaIndexбиблиотека, которая содержитHierarchicalNodeParserответить пениемAutoMergingRetrieverРеализация. - Достаточные вычислительные ресурсы для обработки и хранения больших коллекций документов.
- Знакомство с языком программирования Python для реализации и тестирования.
Пример использования
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...