
Инженерная академия ИИ: 2.1 Внедрение RAG с нуля

в общих чертах
В этом руководстве вы узнаете, как создать простую генерацию улучшений поиска с помощью чистого Python (RAG) система. Мы будем использовать модель встраивания и большую языковую модель (LLM) для извлечения релевантных документов и генерации ответов на основе запросов пользователя.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
Этапы работы
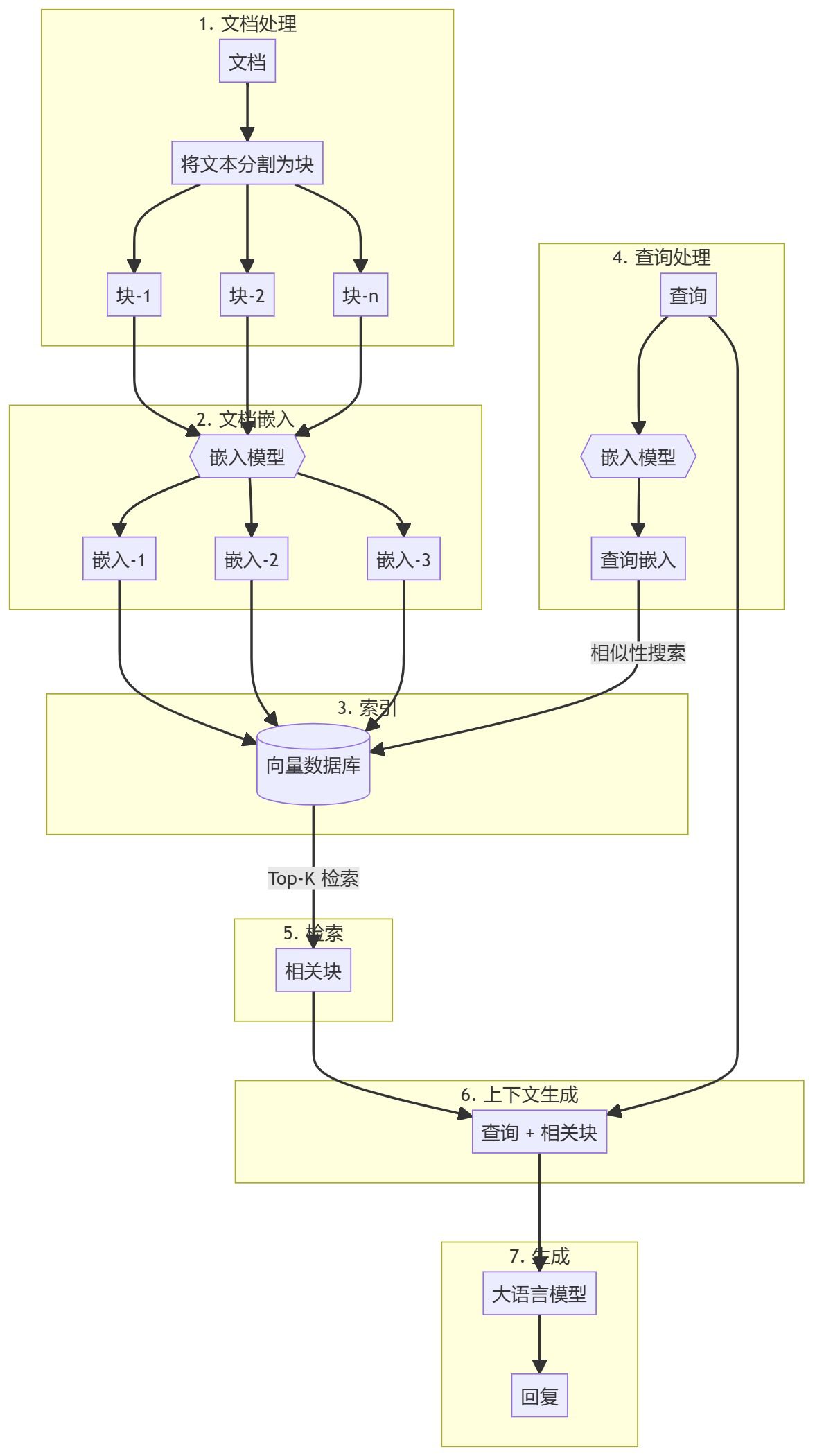
Весь процесс можно разделить на два основных этапа:
- Создание базы знаний
- генерируемая часть
Создание базы знаний
Сначала необходимо подготовить базу знаний (документы, PDF-файлы, вики-страницы). Это базовые данные для языковой модели (LLM). Конкретный процесс включает в себя:
- кусок: Разбейте текст на небольшие фрагменты, чтобы упростить обработку.
- встраивание: Вычислите числовые вкрапления для каждого блока поддокументов, чтобы понять семантическое сходство запроса.
- запас: Храните эти вкрапления таким образом, чтобы их можно было быстро найти. Хотя обычно принято использовать векторные хранилища/базы данных, этот учебник показывает, что это не обязательно.
генерируемая часть
Когда вводится запрос пользователя, для него вычисляется вложение и из базы знаний извлекаются наиболее релевантные блоки поддокументов. Эти релевантные блоки добавляются к запросу пользователя для формирования контекста и передаются в LLM для генерации ответа.
1. настройки окружающей среды
Перед началом работы необходимо установить несколько пакетов.
sentence-transformers: Используется для создания вкраплений для документов и запросов.numpy: для сравнения сходства.scipy: для расширенных расчетов сходства.wikipedia-api: Используется для загрузки страниц Википедии в качестве базы знаний.textwrap: Используется для форматирования выходного текста.
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. Загрузка модели встраивания
Давайте загрузим встроенную модель. В этом учебнике используется gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
О модели
gte-base-en-v1.5 Model - это модель английского языка с открытым исходным кодом, предоставленная командой Alibaba NLP. Она является частью семейства GTE (Generic Text Embedding), предназначенного для генерации высококачественных вкраплений для различных задач обработки естественного языка. Модель оптимизирована для передачи семантического смысла английского текста и может быть использована для решения таких задач, как сходство предложений, семантический поиск и кластеризация.trust_remote_code=True Параметры позволяют использовать пользовательский код, связанный с моделью, чтобы убедиться, что она работает так, как ожидается.
3. Получение текстового контента из Википедии и его подготовка
- Сначала статья Википедии загружается как база знаний. Текст разбивается на управляемые фрагменты (поддокументы), обычно на абзацы.
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - Хотя существует множество стратегий разбивки на части, многие из них могут быть неприменимы. Для определения наиболее подходящей стратегии лучше всего обратиться к своей Базе знаний (БЗ). В этом примере мы разбиваем по абзацам.
- Если вы хотите посмотреть, как выглядят эти блоки, вы можете импортировать файл
textwrapбиблиотеку и распечатайте его абзац за абзацем.import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - Если документ содержит изображения и таблицы, рекомендуется извлекать их отдельно и встраивать с помощью визуальной модели.
4. Встраивание документов
- Затем создается модель, вызывая функцию
encodeметод, который принимает текстовые данные (например.paragraphs) кодируются как встроенные.docs_embed = model.encode(paragraphs, normalize_embeddings=True) - Эти вкрапления представляют собой плотные векторные представления текста, отражающие его семантическое значение и позволяющие модели понимать и обрабатывать текст в математической форме.
- Здесь мы нормируем вложения.
- Что такое нормализация? Нормализация - это процесс приведения значений вкраплений к единичной парадигме (т.е. длина вектора равна 1).
- Зачем нормализовывать? Нормализованное вложение гарантирует, что расстояния между векторами в первую очередь отражают различия в направлении, а не в размере. Это улучшает производительность модели в задачах поиска по сходству, где сравнивается "близость" или "сходство" между текстами.
- в конце концов
docs_embedэто набор векторных представлений текстовых данных, где каждый вектор соответствуетparagraphsПараграф в списке. - пользоваться
shapeчтобы увидеть количество блоков и размерность каждого вектора встраивания (размер вектора встраивания зависит от типа модели встраивания).docs_embed.shape - Вы также можете увидеть, как выглядит фактическое вложение, которое представляет собой набор нормализованных значений.
docs_embed[0]
5. встраивание запросов
Вставьте пример пользовательского запроса аналогично встроенному документу.
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
Вы можете проверить query_embed форма, чтобы подтвердить размерность встроенного запроса.
query_embed.shape
6. поиск наиболее близкого к запросу абзаца
Один из самых простых способов извлечь наиболее релевантные фрагменты контента - вычислить точечное произведение вкраплений документа и вкраплений запроса.
a. Вычисление точечного произведения
Точечное произведение - это математическая операция, которая перемножает и суммирует соответствующие элементы двух векторов (или матриц). Она часто используется для измерения сходства между двумя векторами.
(Обратите внимание, что точечное произведение вычисляется путем взятия query_embed (транспонирование вектора).
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. Понять точечные произведения и их формы
Массивы NumPy из .shape Свойство возвращает кортеж, представляющий размеры массива.
similarities.shape
Ожидаемая форма в этом коде выглядит следующим образом:
- в случае, если
docs_embedимеет форму (n_docs, n_dim):- n_docs - количество документов.
- n_dim - это размерность, заложенная в каждом документе.
query_embed.Tбудет иметь форму (n_dim, 1), поскольку мы сравниваем с одним запросом.- точечный продукт
similaritiesФорма массива будет (n_docs,), что указывает на то, что это одномерный массив (вектор), содержащий n_docs элементов. Каждый элемент представляет собой оценку сходства между запросом и конкретным документом. - Зачем проверять форму? Убедившись, что форма соответствует ожидаемой (n_docs,), подтвердите, что точечное произведение было выполнено правильно и что баллы сходства для каждого документа были рассчитаны верно.
Вы можете распечатать similarities массив для проверки оценок сходства, где каждое значение соответствует результату точечного произведения:
print(similarities)
c. Интерпретация точечного произведения
Точечное произведение между двумя векторами (вкраплениями) измеряет их сходство: более высокие значения указывают на большее сходство между запросом и документом. Если вкрапления нормализованы, эти значения прямо пропорциональны косинусному сходству между векторами. Если они не нормализованы, они по-прежнему указывают на сходство, но также отражают размер вкраплений.
d. Определите 3 наиболее похожих документа
Чтобы найти 3 наиболее похожих документа на основе их оценок сходства, можно использовать следующий код:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similarities, axis=0). Эта функция сопрягает
similaritiesСортировка массива производится по индексу. Например, еслиsimilarities = [0.1, 0.7, 0.4](математика) родnp.argsortвернётся[0, 2, 1]Индексы минимального и максимального значений равны 0 и 1 соответственно. - [-3:]: Эта операция нарезки выбирает 3 индекса с наибольшими показателями сходства (последние 3 элемента после сортировки).
- [::-1]: Эта операция меняет порядок, поэтому индекс сортируется в порядке убывания сходства.
- tolist(). Преобразует индексированный массив в список Python. Результат:
top_3_idxИндекс, содержащий 3 наиболее похожих документа в порядке убывания сходства.
e. Извлечение наиболее похожих документов
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- Список производных: Эта строка создает файл с именем
most_similar_documentsСписокparagraphsСписок, соответствующийtop_3_idxСобственно абзац индекса. - Параграфы[idx]. в отношении
top_3_idxЭта операция извлекает соответствующий параграф для каждого индекса в
f. Форматирование и отображение наиболее похожих документов
CONTEXT Изначально переменная инициализируется пустой строкой, а затем в цикле перечисления к ней будет добавляться текст с новой строки наиболее похожего документа.
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. Создайте ответ
Теперь у нас есть запрос и связанные с ним блоки контента, которые будут переданы в Большую языковую модель (LLM).
a. Заявление о поиске
query = "What was Studio Ghibli's first film?"
b. Создайте подсказку
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. Настройка OpenAI
- Установите OpenAI для доступа и использования Большой языковой модели (LLM).
!pip install -q openai - Включите доступ к API-ключам OpenAI (их можно задать в секретах в Google Colab).
from google.colab import userdata userdata.get('openai') import openai - Создайте клиента OpenAI.
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. Вызовите API для создания ответа
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create. Этот метод вызывает большую языковую модель чата для создания нового ответа (генерации).
- клиент. Представляет собой объект клиента API, который подключается к сервису (в данном случае OpenAI).
- chat.completions.create. Укажите, что вы запрашиваете создание генерации на основе чата.
Для получения дополнительной информации о параметрах, передаваемых в метод
- model="gpt-4o". Указывает модель, используемую для генерации ответа." gpt-4o" - это конкретный вариант модели GPT-4. Различные модели могут иметь разное поведение, методы тонкой настройки или возможности, поэтому указание модели важно для обеспечения получения желаемого результата.
- сообщения. Этот параметр представляет собой список объектов сообщений для представления истории диалога. Это позволяет модели понять контекст чата. В этом примере мы предоставляем только одно сообщение в списке:
{"role": "user", "content": prompt}. - роль. "user" обозначает роль отправителя сообщения, т.е. пользователя, который взаимодействует с моделью.
- содержание. Содержит фактический текст сообщения, отправленного пользователем. В переменной prompt хранится этот текст, который модель будет использовать в качестве входных данных для генерации ответа.
e. В связи с полученными ответами
Когда вы делаете запрос к API, например, к модели OpenAI GPT, чтобы сгенерировать ответ чата, ответ обычно возвращается в структурированном формате, обычно в виде словаря.
В эту структуру обычно входят:
- варианты. Список (массив), содержащий множество возможных ответов, сгенерированных моделью. Каждый элемент в этом списке представляет собой возможный ответ или завершение.
- сообщение. Объект или словарь в каждой подборке, который содержит фактическое содержимое сообщения, сгенерированного моделью.
- содержание. Текстовое содержание сообщения, т.е. фактический ответ или завершение, сгенерированное моделью.
f. Печатные ответы
print(response.choices[0].message.content)
Мы выбираем choices Первый элемент в списке, а затем обращение к одному из message объект. Наконец, мы получаем доступ к message попал в точку content поле, которое содержит фактический текст, сгенерированный моделью.
вынести вердикт
На этом мы закончим объяснение создания систем RAG с нуля. Настоятельно рекомендуем вам сначала создать свою начальную установку RAG на чистом Python, чтобы лучше понять, как работают эти системы.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...