
Конкурс ассистентов по исследованию ИИ: подробный обзор и руководство по выбору пяти основных инструментов

ИИ-помощники: кто действительно может помочь вам с домашним заданием?
Исследования в информационную эпоху часто означают продирание сквозь огромные массивы данных. В прошлом исследователям приходилось вручную искать, просеивать и систематизировать информацию, прежде чем предоставить ключевые материалы таким людям, как ChatGPT Анализируются такие большие языковые модели. Но с запуском функции глубокого исследования OpenAI ситуация начинает меняться. Эти новые инструменты ИИ обещают автоматизировать весь процесс исследования: пользователь просто задает вопрос, а ИИ автономно ищет информацию в Интернете, анализирует данные и создает отчет со ссылками. Часто для этого используются продвинутые модели на больших языках, такие как o3 от OpenAI, которые не только используют предварительно обученные знания, но и проактивно получают актуальную информацию и выполняют многоступенчатые рассуждения.
Попытки OpenAI быстро подтолкнули индустрию к действию.2023 С марта несколько компаний запустили собственные инструменты для автоматизированных исследований или ИИ-агенты (Agents), которые часто называют "помощниками ИИ-поиска" или инструментами "глубокого исследования". Основная концепция этих инструментов схожа: использование мощных возможностей моделирования ИИ в сочетании с веб-поиском для автономного выполнения исследовательских задач и предоставления результатов.

В этой статье мы рассмотрим несколько высоко оцененных продуктов, представленных на рынке, с целью изучения различий в их производительности, границ возможностей и наилучших сценариев для каждого из них с помощью реальных испытаний. В сравнении участвуют следующие инструменты:
- Близнецы Глубокий поиск: на основе данных Google Близнецы Серия моделей, подчеркивающих способность к синтезу и анализу информации.
- Grok 3 Глубокий поиск: Использование xAI Grok 3 Модель, предназначенная для самостоятельного выполнения задач, возможно, с большей ориентацией на информацию в реальном времени.
- Манус: система, поддерживающая широкий спектр моделей ИИ (например. Антропология (используется в форме номинального выражения) Клод и Ali's Qwen), которые известны тем, что выполняют многоэтапные задачи.
- Mita AI Shallow Research: Комбинирование модели R1 с разборкой логической структуры и использование собственной модели для выполнения веб-поиска и интеграции.
- Zhipu AutoGLM: Основанный на большой языковой модели Zhipu AI, он автономно управляет цифровыми устройствами для сбора и обработки информации, имитируя действия пользователя с помощью графического интерфейса пользователя (GUI).
Чтобы понять реальную производительность этих инструментов, мы предложили всем пяти продуктам одну и ту же относительно сложную исследовательскую задачу.
Сравнительное тестирование: создание модельных исследований ИИ
Требования к миссии:
Подготовьте исследовательскую работу объемом около 5 000 слов по моделированию искусственного интеллекта, руководствуясь следующим планом:
- Обзор современных больших языковых моделей (например, семейство GPT, Claude, LLaMA, DeepSeek и др.)
- Сравнение характеристик и сценариев применения каждой модели
- Анализ границ и ограничений возможностей модели
- Стратегии выбора моделей с открытым и закрытым исходным кодом
- Учебник по основам API моделей
- Краткое объяснение принципов технологии больших моделей
Реализация:
- Gemini Deep Search: за 8 минут можно найти более 300 веб-страниц.
- Grok 3 Deep Search: поиск по более чем 160 веб-страницам занял 6 минут.
- Manus: занял 21 минуту и сообщил о выполнении 8 подзадач.
- Mita AI Shallow Research: 7 минут на поиск более 300 веб-страниц.
- Zhipu AutoGLM: поиск 71 веб-страницы занял 16 минут.
Примечания: Время ожидания и объем поиска являются лишь справочными данными для данного теста, а реальная производительность может меняться в зависимости от сложности задачи, условий сети и нагрузки на сервер.
Сводка ответов по каждому инструменту:

(На изображениях показаны некоторые из скриншотов или резюме отчетов, созданных каждым инструментом)
Независимая оценка: резкий обзор Клода 3.7
Чтобы получить относительно объективную точку зрения третьей стороны, мы отправили пять сгенерированных отчетов на оценку модели Claude 3.7 компании Anthropic. Ниже приводится резюме оценки Claude 3.7 каждого отчета:
Zhipu AutoGLM
Отчет пытается имитировать формат академической статьи, приводя 71 ссылку, но это довольно пустое занятие. Язык излишне академичен, как будто отчет использует риторику, чтобы скрыть отсутствие сути. Анализ сильных и слабых сторон модели похож на повторение описания продукта и лишен глубины прочтения.
Манус
Отчет впадает в другую крайность, чрезмерно упрощая сложные технические вопросы во имя "для политиков" и превращая глубокий анализ в поверхностную маркетинговую копию. Подобно детской книжке по квантовой физике, он не является ни глубоким, ни точным.
Близнецы Глубокий поиск
Отчет выдержан в академическом стиле, но обширные кавычки мешают чтению. Он затянут и занимает слишком много места, объясняя простые понятия и не добавляя существенной информации. Заявляя о том, что отчет предназначен для нетехнических специалистов, он все же изобилует непонятным жаргоном и не отвечает поставленным целям.
Grok 3 Глубокий поиск
Наличие как краткой, так и подробной версий является особенностью, но при этом возникают проблемы с согласованностью содержания. Краткая версия чрезмерно упрощена, а некоторые прогнозы в подробной версии (например, на 2025 год) несколько спекулятивны, поскольку не имеют достаточной аргументации и необходимых допущений.
Mita AI Shallow Research
Широкое использование таблиц для структурирования информации повышает эффективность ее получения, однако чрезмерное увлечение таблицами и разделителями приводит к механизированному изложению материала, которому не хватает связности и глубины повествования. Технические пояснения недостаточно связаны с практическими сценариями применения, а в анализе затрат на ведение бизнеса отсутствуют дифференцированные соображения для предприятий разного размера, и рекомендации выглядят как "универсальные".
Общие замечания по Клоду 3.7:
Все эти пять докладов пытаются использовать различные "упаковки", чтобы скрыть недостатки содержания. Независимо от того, являются ли они академическими, коммерческими или техническими, они, похоже, не смогли коснуться самого главного - глубокого понимания природы технологий и глубокого осмысления их практического применения. Например, в докладе DeepSeek Чрезмерное внимание может отражать общее стремление индустрии к новым технологиям, в то время как замалчивание таких ключевых вопросов, как конфиденциальность данных и соблюдение этических норм, свидетельствует об ограниченности аналитических перспектив. Хороший отчет об исследовании технологий должен содержать глубокие выводы и прагматичный анализ, а не игру слов. По этому стандарту все пять отчетов нуждаются в улучшении.
Общая производительность и оценка
Основываясь на оценке Клода 3.7 и непосредственном просмотре содержания отчета, можно дать комплексную оценку эффективности инструментов в этом тесте:
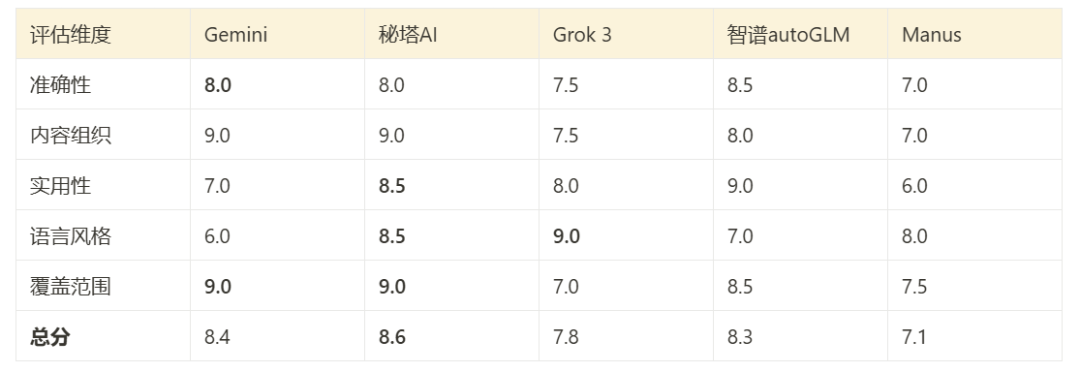
(На рисунке показана комплексная таблица оценок по результатам тестирования)
- Близнецы Глубокий поиск: Лучше организованный контент, широкий охват и многоязычная поддержка являются его сильными сторонами.
- Mita AI Shallow Research: Исполнение всеобъемлющее и сбалансированное, с хорошим сочетанием технической глубины и читабельности.
- Grok 3 Глубокий поиск: Гибкий языковой стиль (двойной вариант) и сильная прагматическая ориентация.
- Zhipu AutoGLM: Техническое содержание очень точное, но читабельность для неспециалистов ограничена.
- Манус: Отчет лаконичен и прост для понимания, но за счет глубины анализа.
Как выбрать: предложения по использованию в различных сценариях
Основываясь на этом тесте и характеристиках каждого инструмента, вот некоторые рекомендации по выбору:
Обзор возможностей поиска:
- Близнецы Глубокий поиск: Поиск является широким и хорошо интегрирует глобальные многоязычные ресурсы, но может быть не так хорош, как локализованные продукты, для понимания глубокого китайского контента.
- Grok 3 Глубокий поиск: Высокая оперативность, особенно в деловой информации и новостях, но относительно слабая глубина технического содержания.
- Zhipu AutoGLM: Цитируемые ссылки высокого качества, с глубоким пониманием технических концепций, но поиск относительно узкоспециализированный.
- Mita AI Shallow Research: Сильная интеграция информации на английском и китайском языках, более полный охват областей знаний и точное извлечение структурированной информации.
- Манус:: (В данном тесте основное внимание уделялось созданию отчетов, и функции поиска не были продемонстрированы в полной мере, однако платформа разработана для поддержки интеграции информации из нескольких источников и сложных рабочих процессов).
Предварительный рейтинг поисковых и исследовательских навыков (на основе этого теста):
- Mita AI Shallow Research: Выдающиеся результаты в глубоком поиске в специализированных областях, двуязычная обработка на английском и китайском языках.
- Близнецы Глубокий поиск: Самый универсальный и широкий охват глобальных ресурсов.
- Zhipu AutoGLM: Преимущества в работе с китайской технической литературой и глубокое понимание.
- Grok 3 Глубокий поиск: Лидер в области доступа к деловой информации и новостям в режиме реального времени.
- Манус: Сильные стороны могут заключаться в гибкости выполнения задач и вызове нескольких моделей, а не в чистом поисковом ранжировании.
Рекомендации на основе сценариев:
- научные исследования: Приоритет был отдан Zhipu AutoGLM (высокое качество ссылок), затем Mita AI (специализированный охват домена).
- Анализ бизнеса: Приоритет отдается Grok 3 (бизнес-информация в реальном времени), за ним следуют Gemini (глобальное видение).
- развитие технологий: Приоритет отдается Mita AI (понимание документов, структурированное извлечение), затем Zhipu AutoGLM (техническая глубина).
- Ежедневный доступ к информации/общие исследования: Приоритет отдается Gemini (широкий охват), затем Grok 3 (своевременность).
- Глубокое исследование китайского контента: Приоритет отдается Zhipu AutoGLM или Mita AI, которые лучше понимают родной язык и контекст.
Важный совет:
- кросс-валидация: Для получения критической информации или принятия важных решений настоятельно рекомендуется проводить сравнительную проверку с использованием как минимум двух различных инструментов, чтобы гарантировать точность и полноту информации.
- Сопоставление задач: Не существует универсального инструмента. Выбор продукта во многом зависит от конкретной исследовательской задачи, типа требуемой информации (оперативная или углубленная, техническая или коммерческая), а также от требований к формату и глубине отчета.
- Ограничения при тестировании: Это сравнение основано только на одной задаче. Например, Манус Преимущества подобного инструмента, в котором особое внимание уделяется потоку задач и возможностям доставки в нескольких форматах, могут быть полностью осознаны только после выполнения других типов задач. Кроме того, пользовательский интерфейс, стоимость и возможности интеграции с API также являются факторами, которые необходимо учитывать при выборе.
Эти инструменты исследовательского помощника с искусственным интеллектом, несомненно, представляют собой будущие тенденции в способах получения и анализа информации. Хотя у каждого из них на данный момент есть свои сильные и слабые стороны, они развиваются быстрыми темпами и заслуживают постоянного внимания. Выбор правильных инструментов и обучение их эффективному использованию значительно улучшат процесс исследования и принятия решений.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...