450 для обучения 'o1-preview'? Калифорнийский университет в Беркли выложил в открытый доступ 32-битную модель вывода Sky-T1, ИИ-сообщество в восторге

Ценник в 450 долларов на первый взгляд кажется не слишком большим. Но что, если это вся стоимость обучения 32-битной модели вывода?
Да, по мере приближения к 2025 году модели вывода становятся все более простыми в разработке, а их стоимость быстро снижается до уровня, который мы даже не могли себе представить раньше.
Недавно компания NovaSky, исследовательская группа из лаборатории Sky Computing Lab при Калифорнийском университете в Беркли, выпустила Sky-T1-32B-Preview. Интересно, что, по словам команды, "обучение Sky-T1-32B-Preview стоит менее 450 долларов, что говорит о возможности экономичного и эффективного воспроизведения высокоуровневых возможностей рассуждений".

- Домашняя страница проекта: https://novasky-ai.github.io/posts/sky-t1/
- Адрес с открытым исходным кодом: https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
Согласно официальной информации, эта модель умозаключений превосходит раннюю версию OpenAI o1 в нескольких ключевых бенчмарках.

Дело в том, что Sky-T1, похоже, является первой моделью вывода с открытым исходным кодом, поскольку команда выпустила обучающий набор данных, а также необходимый обучающий код, чтобы любой желающий мог воспроизвести ее с нуля.
Люди восклицали: "Какой удивительный вклад данных, кода и модельных весов".
Еще недавно стоимость обучения модели с эквивалентной производительностью часто исчислялась миллионами долларов. Синтетические обучающие данные или обучающие данные, полученные с помощью других моделей, позволили значительно снизить стоимость обучения.
Ранее компания Writer, занимающаяся разработкой искусственного интеллекта, выпустила Palmyra X 004, который обучался практически полностью на синтетических данных, а его разработка обошлась всего в 700 000 долларов.
Представьте, что эта программа выполняется на суперкомпьютере Nvidia Project Digits AI, который стоит 3 000 долларов (недорого для суперкомпьютера) и может запускать модели с 200 миллиардами параметров. В ближайшем будущем модели с менее чем 1 триллионом параметров будут выполняться локально отдельными людьми.
Эволюция технологий больших моделей в 2025 году ускоряется, и это действительно сильное чувство.
Обзор модели
Рассуждения o1 и Близнецы 2.0 Такие модели, как flash thinking, позволяют решать сложные задачи и добиваться других успехов, генерируя длинные внутренние цепочки мыслей. Однако технические детали и весовые коэффициенты моделей недоступны, что создает препятствия для участия академического сообщества и сообщества с открытым исходным кодом.
В этой связи в области математики были получены заметные результаты по обучению моделей с открытым взвешенным выводом, таких как Still-2 и Journey. Тем временем команда NovaSky из Калифорнийского университета в Беркли изучает различные методы для развития возможностей вывода как базовых моделей, так и моделей с командной настройкой.
В этой работе, Sky-T1-32B-Preview, команда добилась конкурентоспособных результатов не только в математической части, но и в части кодирования одной и той же модели.

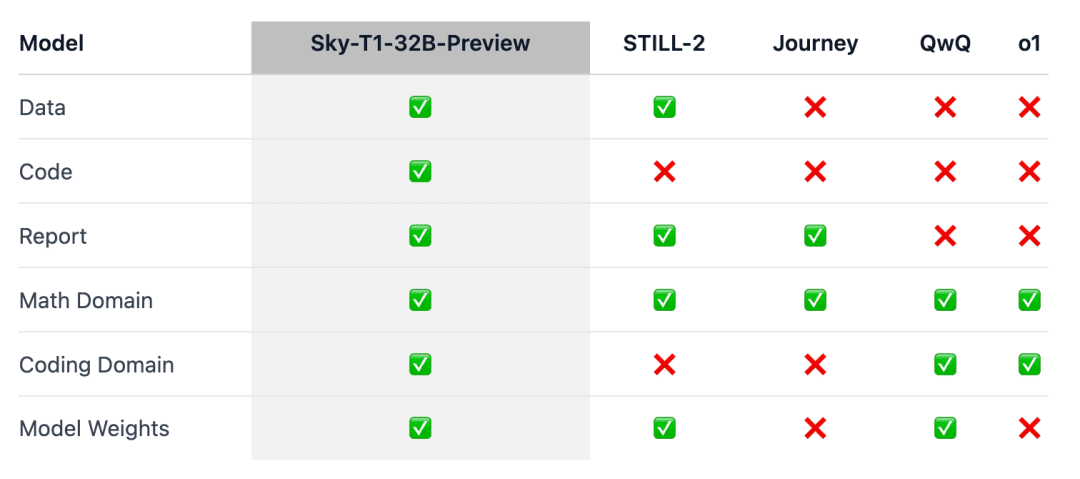
Для того чтобы эта работа принесла пользу широкому сообществу, команда открыла доступ ко всем деталям (например, данным, коду, весовым коэффициентам модели), чтобы сообщество могло легко воспроизвести и улучшить ее:
- Инфраструктура: сбор данных, обучение и оценка моделей в едином хранилище;
- Данные: 17K данных, использованных для обучения Sky-T1-32B-Preview;
- Технические подробности: технические отчеты и журналы wandb;
- Вес модели: 32B Вес модели.
Технические детали
Процесс обобщения данных
Для создания обучающих данных команда использовала QwQ-32B-Preview - модель с открытым исходным кодом, возможности которой в области выводов сопоставимы с o1-preview. Команда организовала набор данных таким образом, чтобы охватить различные области, в которых требовалось сделать выводы, и использовала процедуру выборки с отклонением для улучшения качества данных.
Затем, вдохновившись Still-2, команда переписала трассу QwQ в структурированную версию с помощью GPT-4o-mini, чтобы улучшить качество данных и упростить их разбор.
Они обнаружили, что простота синтаксического анализа особенно полезна для моделей вывода. Они обучены отвечать в определенном формате, и результаты часто сложно разобрать. Например, на наборе данных APPs без переформатирования команда могла предположить, что код был написан только в последнем блоке кода, и QwQ смог достичь точности около 25%. Однако иногда код может быть написан в середине, и после переформатирования точность возрастает до более чем 90%.
Отклонить образец. В зависимости от решения, предоставленного вместе с набором данных, если образец QwQ неверен, команда отбрасывает его. Для математических задач команда выполняет точное совпадение с истинным решением. Для задач кодирования команда выполняет модульные тесты, предоставленные в наборе данных. Итоговые данные команды состоят из 5 тыс. кодовых данных из APPs и TACO и 10 тыс. математических данных из подмножества олимпиад наборов данных AIME, MATH и NuminaMATH. Кроме того, команда сохранила 1k данных о науке и головоломках из STILL-2.
поезд
Команда использовала обучающие данные для доработки Qwen2.5-32B-Instruct, модели с открытым исходным кодом без возможности делать выводы. Модель обучалась с использованием 3 эпох, скорости обучения 1e-5 и размера партии 96. Обучение модели было завершено за 19 часов на 8 серверах H100 с использованием выгрузки DeepSpeed Zero-3 (цена около 450 долларов по данным Lambda Cloud). Для обучения команда использовала Llama-Factory.
Результаты оценки
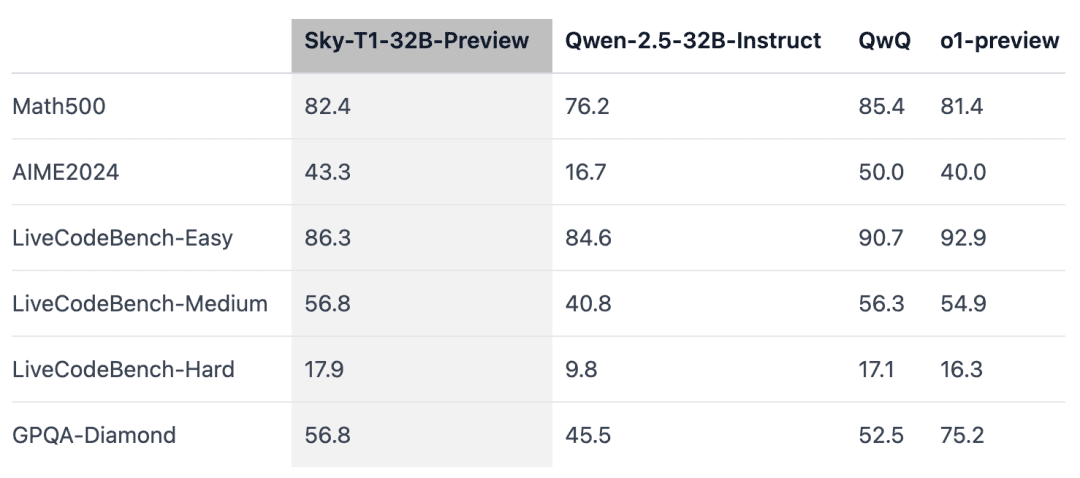
Sky-T1 превзошел предыдущую предварительную версию o1 в MATH500, математической задаче "соревновательного уровня", а также превзошел предварительную версию o1 в наборе головоломок из LiveCodeBench, оценке кодирования. Однако Sky-T1 не так хорош, как предварительная версия o1 в GPQA-Diamond, содержащей задачи по физике, биологии и химии, которые должны знать выпускники аспирантуры.
Однако релиз OpenAI o1 GA более мощный, чем предварительная версия o1, и в ближайшие недели OpenAI планирует выпустить более производительную модель вывода, o3.
Новые результаты, заслуживающие внимания
Размер модели имеет значение.Сначала команда попробовала тренироваться на небольших моделях (7B и 14B), но не заметила особых улучшений. Например, обучение Qwen2.5-14B-Coder-Instruct на наборе данных APPs показало небольшое улучшение производительности в LiveCodeBench - с 42,6% до 46,3%. Однако при ручном изучении результатов работы моделей меньшего размера (меньше 32B) команда обнаружила, что они часто генерируют дублированный контент, что ограничивает их эффективность. что снижает их эффективность.
Смешивание данных имеет большое значение.Первоначально команда обучила модель 32B, используя 3-4К математических задач из набора данных Numina (предоставленных STILL-2), и точность AIME24 значительно повысилась с 16,7% до 43,3%. Однако, когда в процесс обучения были включены данные по программированию из набора данных APPs, точность AIME24 упала до 36,7%. Можно предположить, что это падение связано с различием методов вывода, требуемых для задач математики и программирования.
Рассуждения в программировании обычно включают дополнительные логические шаги, такие как моделирование тестовых входов или внутреннее выполнение сгенерированного кода, в то время как рассуждения для математических задач, как правило, более просты и структурированы.Чтобы устранить эти различия, команда обогатила обучающие данные сложными математическими задачами из набора данных NuminaMath и сложными задачами по программированию из набора данных TACO. Такое сбалансированное сочетание данных позволило модели преуспеть в обеих областях, восстановив точность 43,3% на AIME24 и улучшив при этом свои возможности в программировании.
В то же время некоторые исследователи выражают скептицизм:


Что люди думают об этом? Не стесняйтесь обсуждать это в разделе комментариев.
Ссылка: https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...