
近日,Qwen 团队隆重推出了一系列 Qwen2.5-VL 用例 Notebook 示例,全面展示了本地模型和 API 的强大功能。 这批精心打造的 Notebook 旨在帮助开发者和用户更深入地了解 Qwen2.5-VL 强大的视觉理解能力,并启发更多创新应用。
Notebook 示例:快速上手,体验 Qwen2.5-VL 的卓越性能
通过这些详尽的 Notebook 示例,开发者能够 快速上手并亲身体验 Qwen2.5-VL 模型在各项任务中的出色表现。 无论是应对复杂的文档解析、执行精准的 OCR 任务,还是进行深入的视频内容理解,Qwen2.5-VL 都能提供高效且准确的反馈,充分展现其卓越的性能。
同时,Qwen 团队也期待社区能够积极反馈并贡献力量,共同完善和拓展 Qwen2.5-VL 的能力边界,携手推动多模态技术的发展。
🔗 相关链接:
- GitHub 代码仓库: https://github.com/QwenLM/Qwen2.5-VL/tree/main/cookbooks
- 在线体验: https://chat.qwenlm.ai (选择 Qwen2.5-VL-72B-Instruct 模型)
- ModelScope 模型链接: https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
- 百炼 API 接口: https://help.aliyun.com/zh/model-studio/user-guide/vision/

Notebook 示例详解
01 Computer Use (电脑使用)
此 Notebook 示例演示了如何利用 Qwen2.5-VL 执行与电脑使用相关的任务。
用户只需截取电脑桌面屏幕截图并提出查询,Qwen2.5-VL 模型即可分析截图内容,理解用户意图,进而生成精确的点击或输入等操作指令,实现对电脑的智能控制。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/computer_use.ipynb

02 Spatial Understanding (空间理解)
此 Notebook 示例着重展示了 Qwen2.5-VL 先进的空间定位能力,包括精准的物体检测和图像中特定目标的定位。
通过示例,可以深入了解 Qwen2.5-VL 如何有效地整合视觉和语言理解,从而准确解读复杂场景,实现高级的空间推理。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/spatial_understanding.ipynb

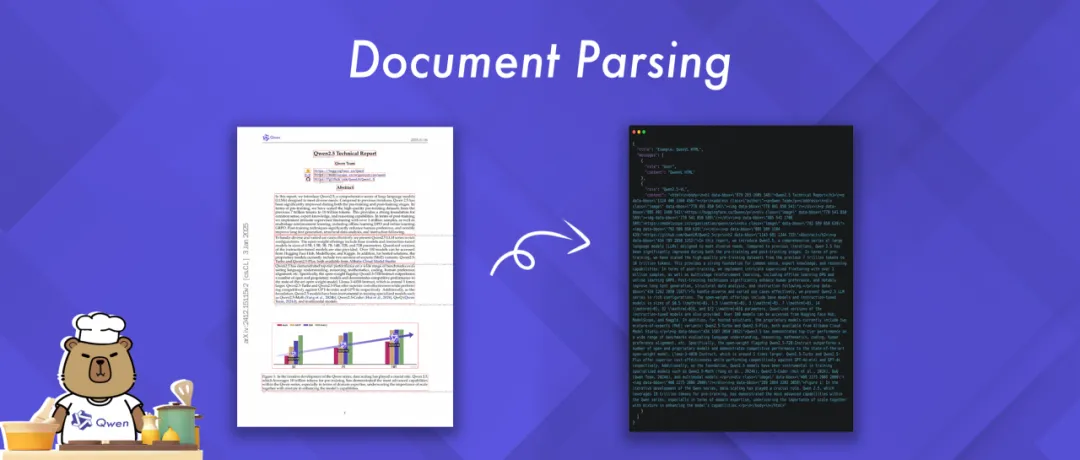
03 Document Parsing (文档解析)
此 Notebook 示例突显了 Qwen2.5-VL 强大的文档解析能力。 它可以处理各种图像格式的文档,并以 HTML、JSON、MD 和 LaTeX 等多种格式输出解析结果。
特别值得关注的是,Qwen 创新性地引入了一种独特的 QwenVL HTML 格式。 这种格式包含了文档中每个组件的位置信息,从而能够实现对文档的精确重建和灵活操作。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/document_parsing.ipynb
04 Mobile Agent (移动设备代理)
此 Notebook 示例演示了如何利用 Qwen2.5-VL 的代理功能与移动设备进行智能交互。
示例展示了 Qwen2.5-VL 模型如何根据用户的查询和移动设备的视觉上下文,生成并执行相应的操作,实现对移动设备的便捷控制。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/mobile_agent.ipynb

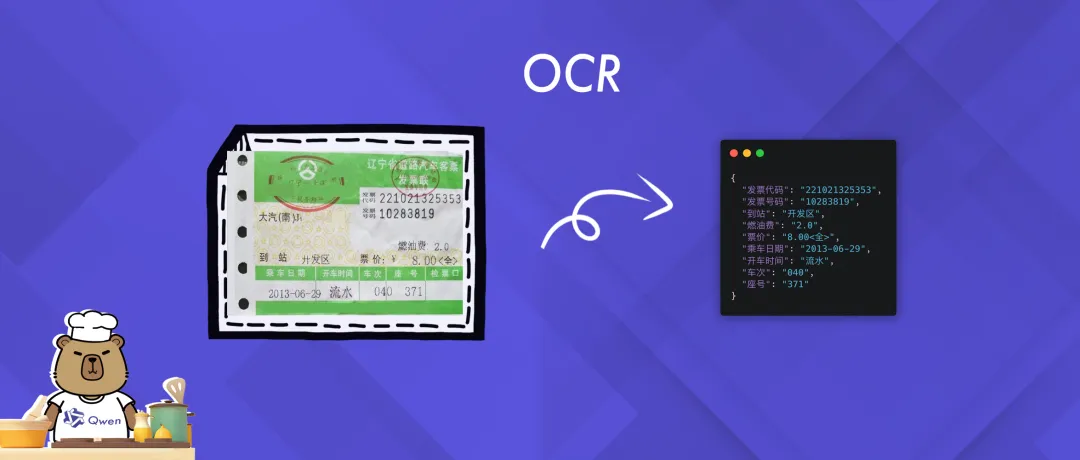
05 OCR (光学字符识别)
此 Notebook 示例专注于展示 Qwen2.5-VL 的 OCR (光学字符识别) 能力,包括从图像中精准提取和识别文本信息。
通过示例,用户可以直观地了解 Qwen2.5-VL 如何在复杂场景下准确捕捉和解读文本内容,展现其强大的文字识别能力。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/ocr.ipynb
06 Universal Recognition (万物识别)
此 Notebook 示例 演示 了如何使用 Qwen2.5-VL 进行通用物体识别。
用户只需提供一张图像和一个查询,Qwen2.5-VL 模型便能分析图像,理解用户查询意图,并给出相应的识别结果,实现对图像内容的 全面的 理解。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/universal_recognition.ipynb

07 Video Understanding (视频理解)
Qwen2.5-VL 具备强大的长视频理解能力,可以处理时长超过 1 小时的视频内容。 此 Notebook 示例将深入探索 Qwen2.5-VL 模型在视频理解任务中的各项能力。
Qwen2.5-VL 旨在展示其在各种视频分析场景中的应用潜力, 从基础的 OCR (光学字符识别) 到复杂的事件检测和内容总结,均能胜任。
👉 Notebook 链接: https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/video_understanding.ipynb

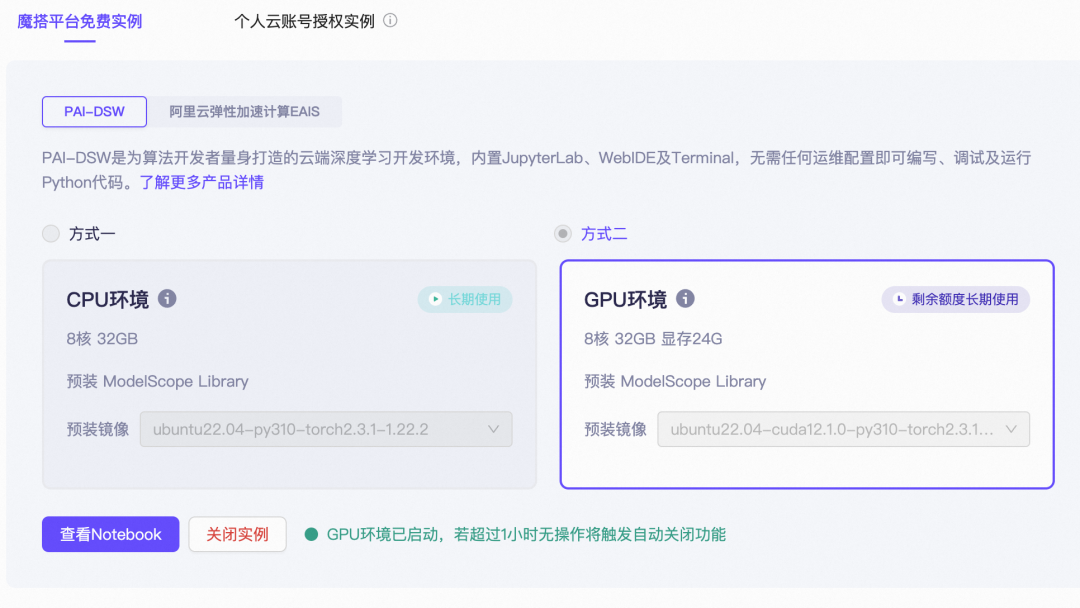
魔搭最佳实践:免费算力玩转 Cookbook 示例
在 ModelScope 魔搭社区,用户可以利用免费算力轻松体验这些 Cookbook 示例。
首先,下载 Qwen2.5-VL 代码:
git clone https://github.com/QwenLM/Qwen2.5-VL.git
Notebook 中使用模型 API: 魔搭平台 API-Inference 提供了免费的 Qwen2.5-VL 系列模型 API。魔搭用户可以通过 API 调用的方式直接使用,只需替换 Cookbook 中的 base-URL 并填写魔搭 SDK Token 即可。详细文档: https://www.modelscope.cn/docs/model-service/API-Inference/intro
from openai import OpenAI
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"}
},
{ "type": "text",
"text": "Count the number of birds in the figure, including those that are only showing their heads. To ensure accuracy, first detect their key points, then give the total number."
},
],
}
],
stream=True
)
Notebook 使用本地模型: 请选择 GPU 机型。
结语:欢迎体验,共创未来
未来,Qwen 团队将持续更新和扩展这些 Notebook 示例,融入更多实用功能和应用场景,力求为开发者提供更全面的解决方案。 欢迎访问 Qwen2.5-VL 的 GitHub 仓库或 ModelScope 魔搭平台,体验这些 Notebook 示例,并分享您的使用心得与创新应用!Qwen 团队期待与您一同探索 Qwen2.5-VL 的更多可能性。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...