
Problemas desafiadores em nível de olimpíada: uma análise dos 7 principais benchmarks de desempenho em matemática do LLM chinês

A capacidade matemática, que engloba a derivação de fórmulas, a construção de cadeias lógicas e o pensamento abstrato, há muito tempo é vista como uma área fundamental para testar os recursos da inteligência artificial (IA), especialmente os modelos de linguagem em grande escala (LLMs). Isso se deve ao fato de que ela não testa apenas o poder computacional, mas também se aprofunda na capacidade do modelo de raciocinar, entender e resolver problemas complexos.
No entanto, descobertas recentes de uma equipe da ETH Zurich mostram que até mesmo os melhores Modelos de Linguagem Grande (LLMs) geralmente têm uma pontuação baixa quando confrontados com perguntas difíceis de competições matemáticas, como desafios no nível da Olimpíada de Matemática dos EUA, o que suscitou uma discussão sobre os verdadeiros recursos dos LLMs atuais em termos de raciocínio matemático rigoroso.
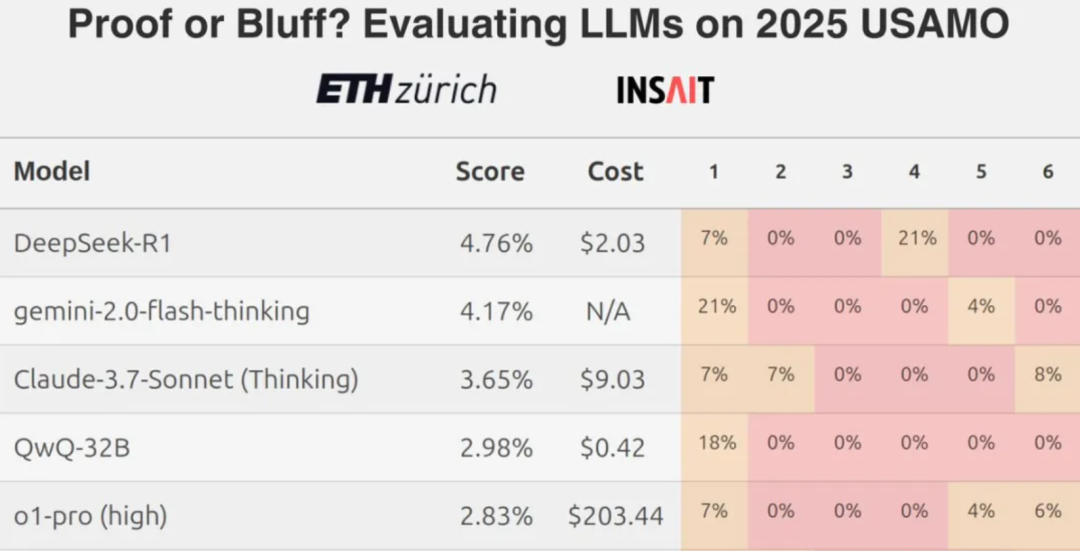
Nesse contexto, uma pergunta natural é: qual é o desempenho desses modelos ao lidar com problemas matemáticos formulados em chinês? Nesta análise, um total de sete modelos de linguagem em larga escala, tradicionais ou emergentes, nacionais e estrangeiros, foram selecionados para uma comparação lado a lado de suas habilidades matemáticas usando problemas do Alibaba Global Maths Competition e da Olimpíada Chinesa de Matemática.
Os modelos envolvidos no teste incluem:
- Modelos domésticos:
DeepSeek R1eHunyuan T1eTongyi Qwen-32B(texto original)通义QwQ-32B),YiXin-Distill-Qwen-72B - Modelagem internacional:
Grok 3 betaeGemini 2.0 Flash Thinkingeo3-mini
Avaliação geral de desempenho
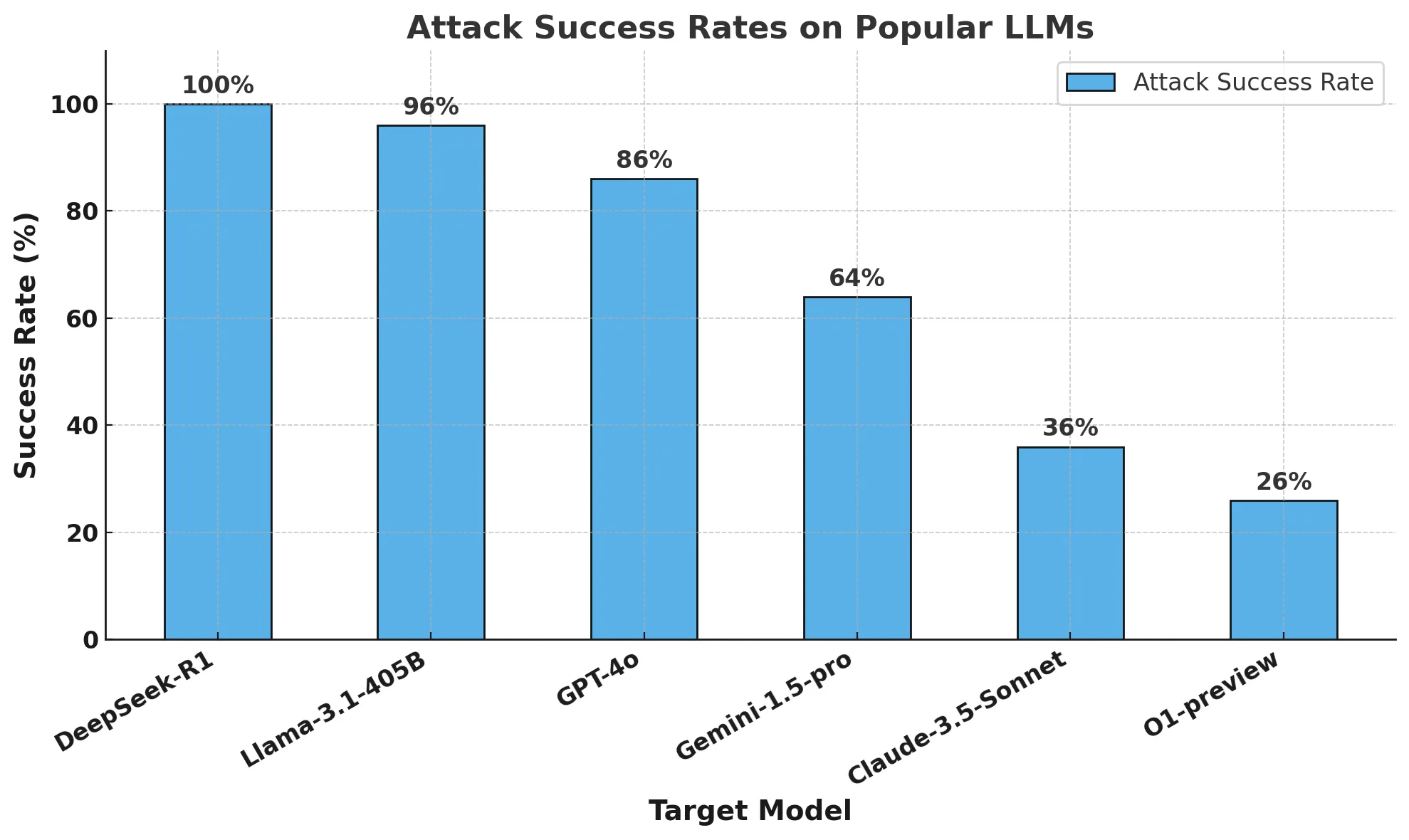
A avaliação consiste em 10 perguntas de alto nível de dificuldade, com um total de 13 perguntas de pontuação. Os critérios de pontuação foram: 1 ponto para acerto total, 0,5 ponto para acerto parcial e nenhum ponto para erros.
A correção geral de cada modelo nesse teste é a seguinte:

As distribuições detalhadas de pontuação mostram as diferenças de desempenho entre os modelos:
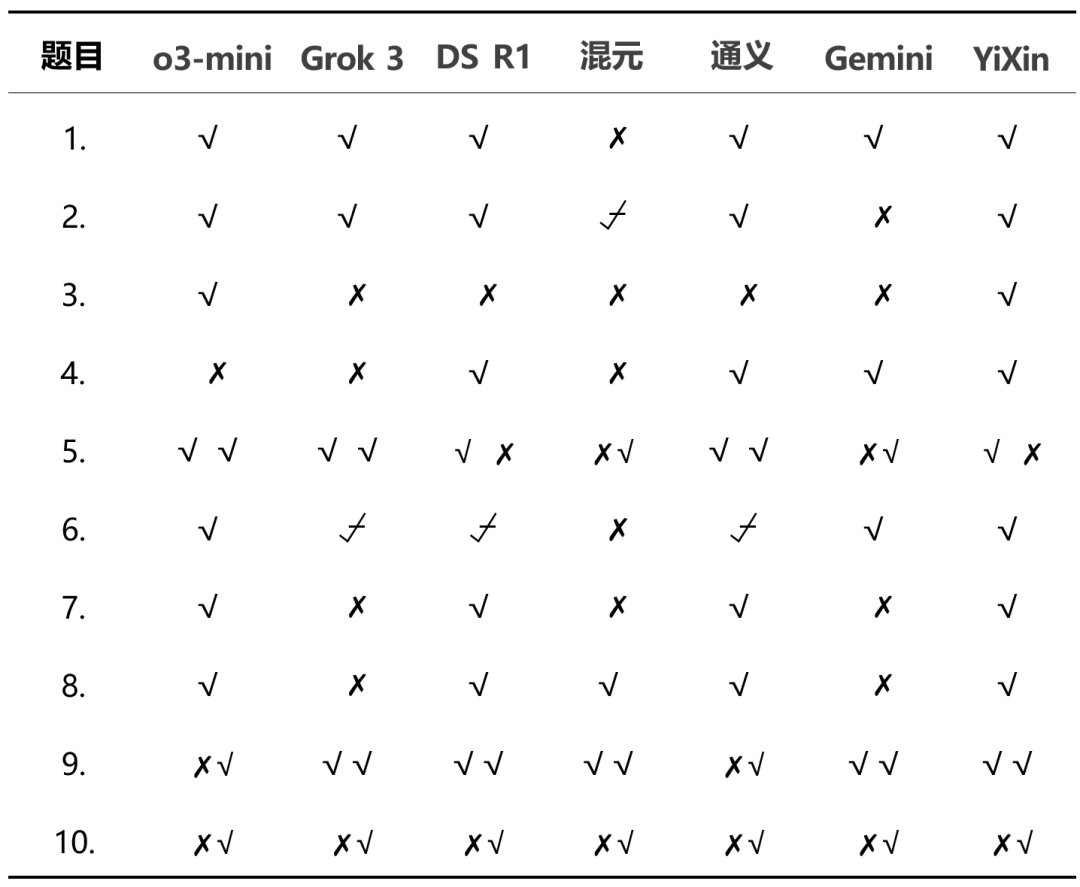
Dos resultados gerais.o3-mini responder cantando YiXin-Distill-Qwen-72B teve um bom desempenho nesse teste, demonstrando fortes habilidades de resolução de problemas matemáticos. O desempenho dos outros modelos variou.
As respostas específicas para algumas das perguntas do teste são mostradas a seguir.
Detalhes da medição
Rodada 1: O problema da mudança
Pergunta: Se o vovô tem US$ 60 e vai ao supermercado para comprar legumes no valor de US$ 20, como o caixa pode dar o troco ao vovô?
Análise: Esta é uma pergunta de aplicação de aritmética básica que examina a compreensão do modelo sobre cenários da vida e habilidades básicas de cálculo de dinheiro.
Resultados:o3-mini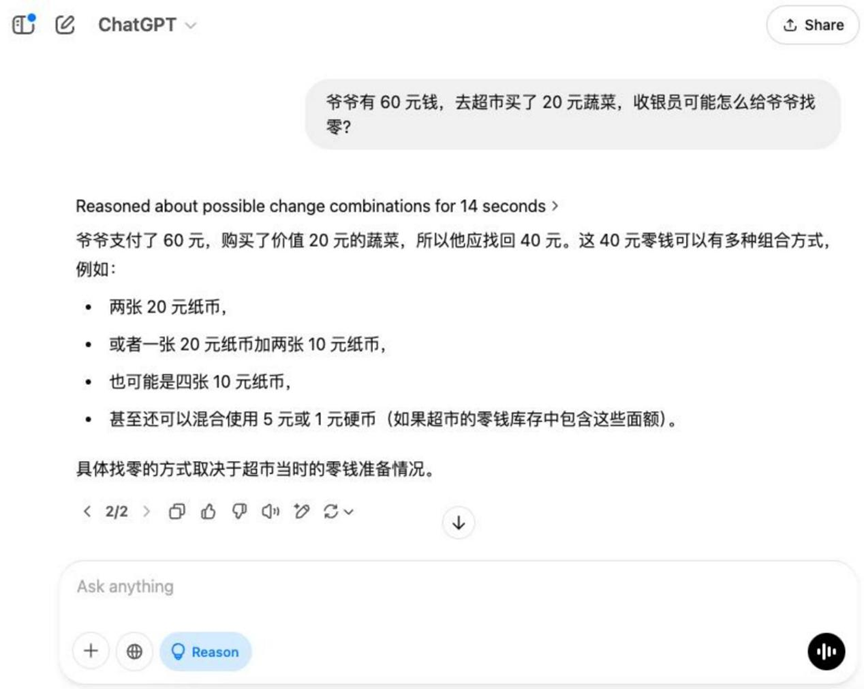
Grok 3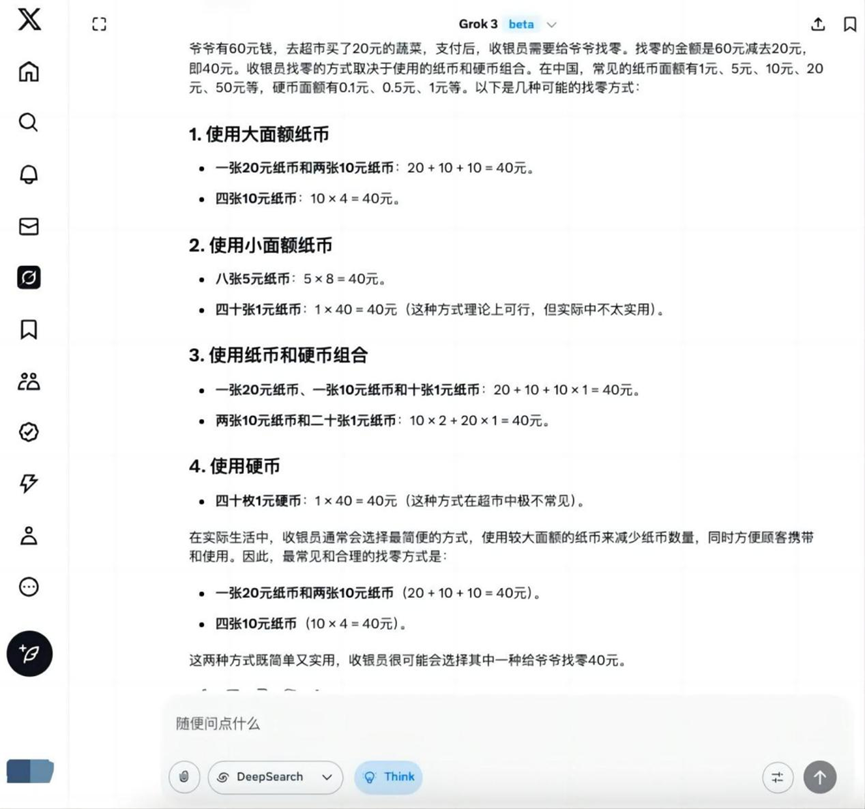
Hunyuan T1
Gemini 2.0 Flash Thinking
YiXin-Distill-Qwen-72B
Sobre esse tópico básico, além de Hunyuan T1 Fora isso, o restante dos modelos fornece a solução correta para encontrar o zero.
Rodada 2: Cálculo das distâncias percorridas a pé e julgamentos metodológicos
Pergunta: Xiao Ming e Xiao Hua vão a pé para a escola todos os dias. Ming caminha 48 metros por minuto e Hua caminha 55 metros por minuto. A casa de Xiaoming fica a 384 metros da escola. Xiaohua leva 4 minutos a mais do que Ming para ir de casa para a escola. Qual é a distância entre a casa de Xiaohua e a escola? Qual dos métodos a seguir está incorreto e por quê?
Método 1: 55 × 4 = 220 (metros), 384 + 220 = 604 (metros)
Método 2: 384 / 48 = 8 (minutos), 55 × (8 + 4) = 660 (metros)
Análise: Esta questão combina o cálculo de problemas de viagem e o julgamento lógico, exigindo que o modelo seja capaz não apenas de calcular a resposta correta, mas também de analisar a correção ou a incorreção da solução dada, examinando o raciocínio em várias etapas e o discernimento lógico.
Resultados:DeepSeek R1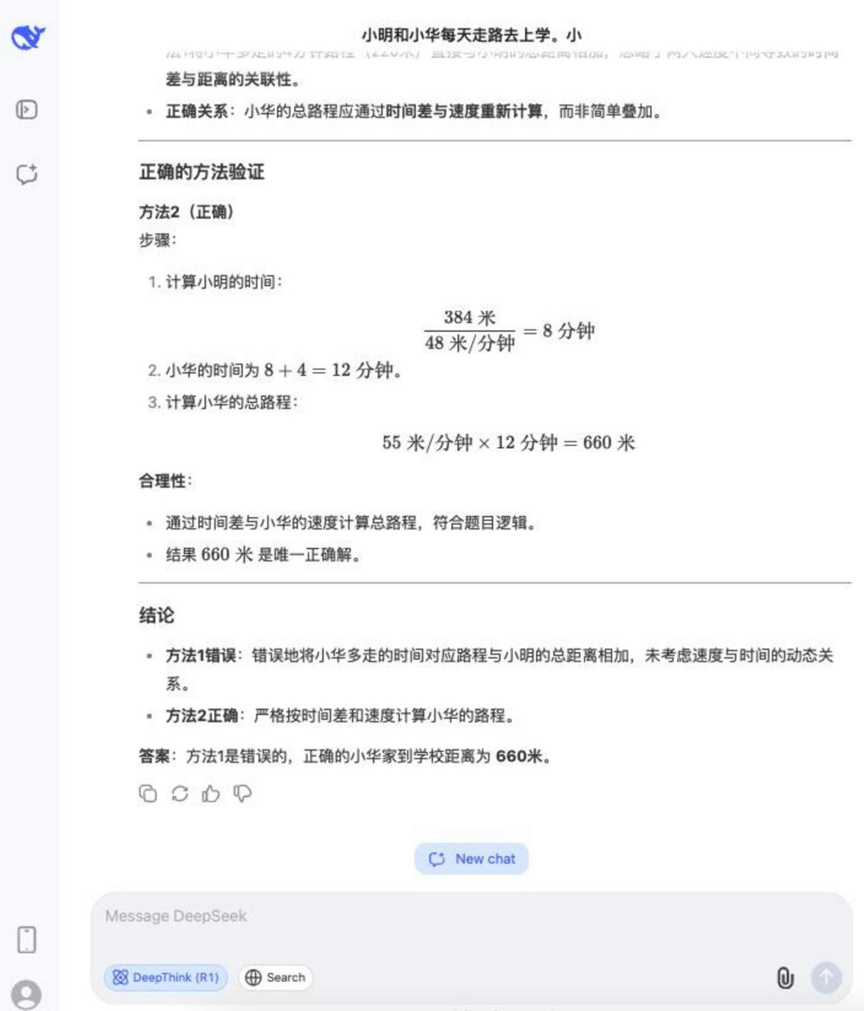
Tongyi Qwen-32B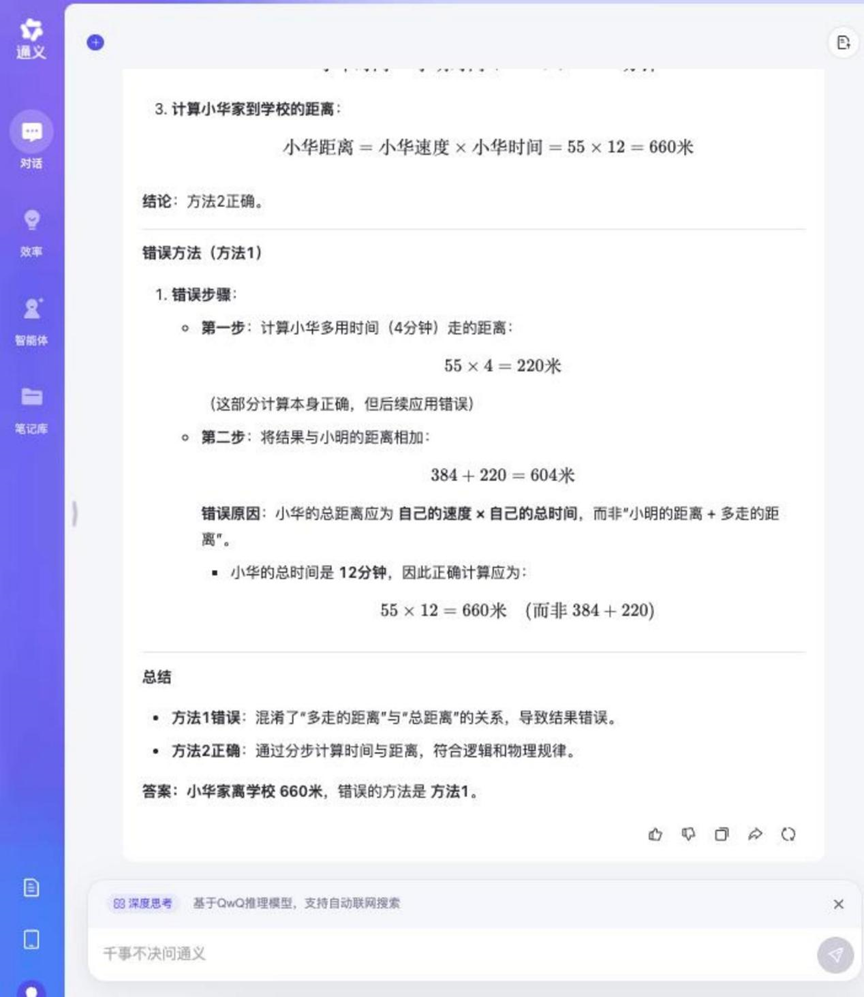
YiXin-Distill-Qwen-72B
O processo de raciocínio para essa pergunta foi relativamente longo, mas a maioria dos modelos envolvidos no teste conseguiu respondê-la corretamente e determinar o método incorreto.
Rodada 3: Problema de oclusão geométrica (torres invisíveis)
Pergunta: Em uma cidade, há 6 torres localizadas nos pontos A, B, C, D, E e F. Vários alunos formam um grupo de viagem para fazer uma excursão gratuita à cidade. Depois de algum tempo, cada um dos alunos percebe que só consegue ver as 4 torres localizadas nos pontos A, B, C e D, mas não as torres localizadas nos pontos E e F. Sabe-se que as posições dos alunos e das torres são consideradas pontos no mesmo plano e que esses pontos não coincidem entre si, e que quaisquer 3 dos pontos A, B, C, D, E e F não compartilham uma linha comum. A única possibilidade de não conseguir ver a torre é se a linha de visão estiver bloqueada por outra torre. Por exemplo, se um aluno estiver em um ponto P que esteja co-localizado com A e B e A estiver no segmento de reta PB, então o aluno não poderá ver a torre localizada em B. Pergunte: qual é o número máximo de alunos que podem estar nesse grupo itinerante? a. 3 b. 4 c. 6 d. 12
Análise: Essa é uma questão complexa de raciocínio geométrico e lógico que envolve visibilidade, oclusão e questões de configuração de conjunto de pontos, o que exige um alto nível de imaginação espacial e raciocínio lógico no modelo.
Resultados:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B
A dificuldade das perguntas aumentou significativamente. Nesta rodada de testes, apenas o3-mini responder cantando YiXin-Distill-Qwen-72B resolvidos com sucesso, os outros modelos não conseguiram dar uma resposta correta.
Rodada 4: Problemas de probabilidade (Tigres e Tigres)
Pergunta: Durante o Festival da Primavera, uma empresa de leite lançou uma atividade de caixa cega para o Ano Novo Chinês: cada caixa de leite vem com um "pacote vermelho", que contém "Tiger" "Sheng" Wei", um dos três padrões. Coletar dois "Tiger", um "Sheng" e um "Wei" pode ser soletrado como retrato de família "Tiger Tiger Sheng Wei". Depois que a atividade foi lançada, ela se tornou um sucesso da Netflix e atraiu muitas pessoas para participar. As condições conhecidas são as seguintes: os padrões nos pacotes vermelhos são distribuídos aleatoriamente de forma independente e não podem ser distinguidos uns dos outros. A probabilidade de aparecimento dos três padrões "Tiger", "Sheng" e "Wei" é de 1/3. P: Para coletar um conjunto completo de "Tiger Tiger Sheng Wei P: Quantas caixas de leite você precisa comprar, em média, para coletar um conjunto completo de fotos da família "Tiger, Tiger, Mighty"?
Análise: Esse é um problema típico de coletor (variante do problema de coletor de cupom), que requer o uso da teoria da probabilidade e cálculos de expectativa, e examina a capacidade do modelo de lidar com modelos de probabilidade e realizar cálculos matemáticos de expectativa.
Resultados:DeepSeek R1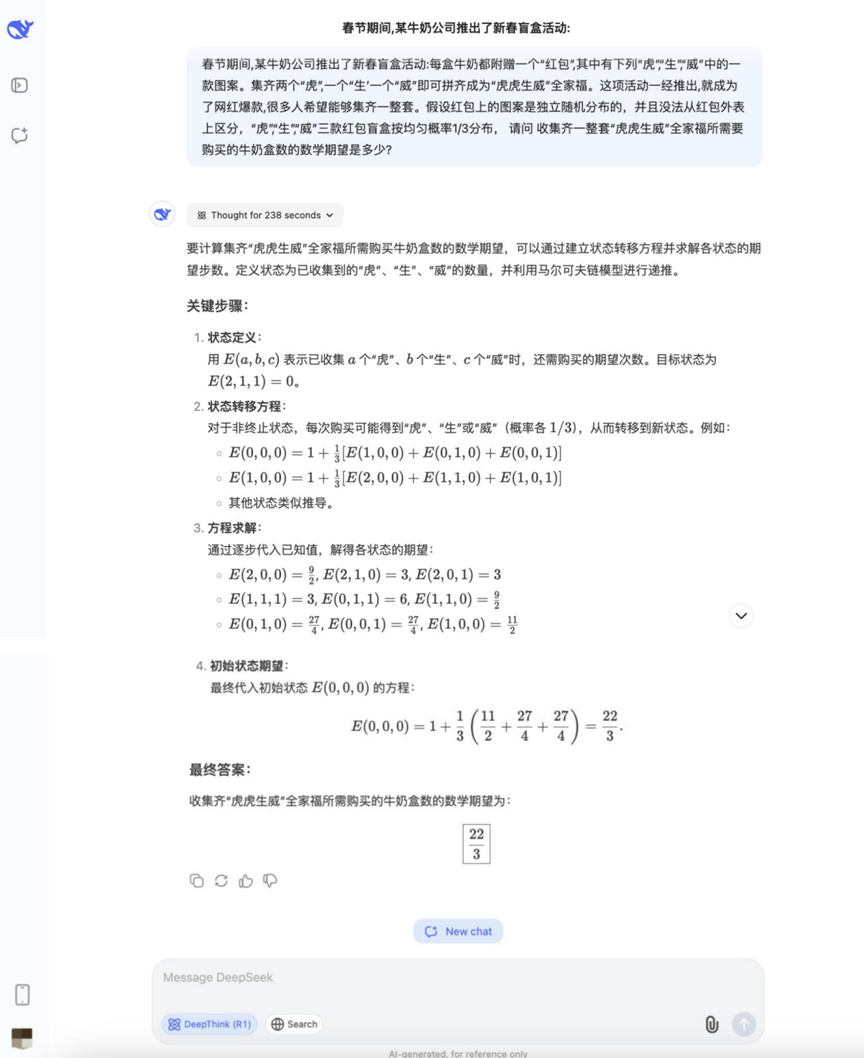
Hunyuan T1
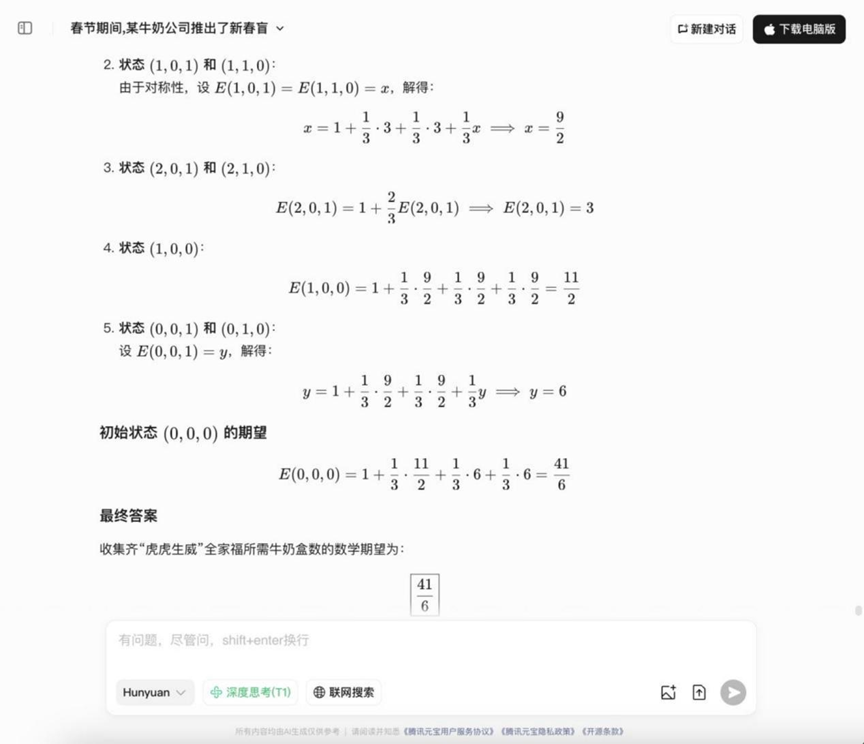
YiXin-Distill-Qwen-72B
As respostas às perguntas sobre probabilidade nessa rodada começaram a divergir, com alguns modelos sendo capazes de listar ideias e calculá-las corretamente.
Rodada 5: Geometria e planejamento de caminhos (Jogos de luta)
Descrição do problema Imagem:
Análise: Esse é um problema que combina geometria, sistemas de coordenadas ou de grade e estratégias de caminho mais curto/ótimo, e pode exigir que o modelo compreenda as informações gráficas e execute o raciocínio e o planejamento espacial.
Resultados:o3-miniResolução bem-sucedida
YiXin-Distill-Qwen-72BParcialmente correto

Essa rodada de testes exige um grau mais alto de integração de modelos, com cerca de metade dos modelos testados sendo tratados de forma totalmente correta.
Rodada 6: Problemas de prova de teoria dos números (Encontrar o mínimo de não-fatores)
Descrição do problema Imagem:
Análise: Passando para o campo das questões de prova, que exigem dedução lógica rigorosa e uma compreensão profunda dos conceitos da teoria dos números, essas questões são um teste direto da capacidade do modelo de raciocinar abstratamente.
Resultados:o3-mini
YiXin-Distill-Qwen-72B

Na modelagem doméstica, oYiXin-Distill-Qwen-72B Apresentou melhor desempenho nessa rodada de questões de prova. As questões de prova foram significativamente mais desafiadoras para o modelo.
Rodada 7: Funções e problemas de mapeamento (mapeamento no círculo unitário)
Descrição do problema Imagem:
Análise: Esta questão trata dos conceitos de funções, mapeamentos e do círculo unitário na matemática superior e examina a capacidade do modelo de entender e aplicar definições matemáticas abstratas.
Resultados:o3-mini
YiXin-Distill-Qwen-72B
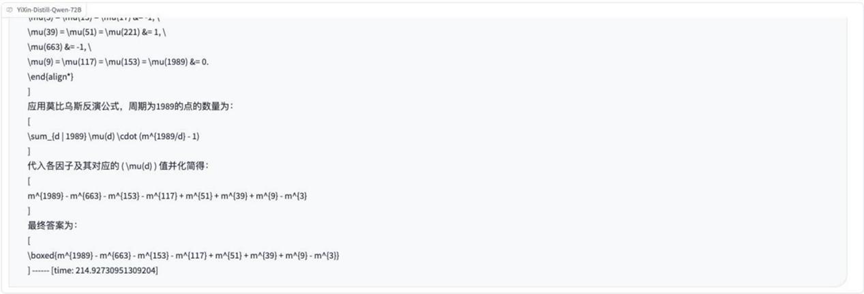
Cerca de metade dos modelos foi capaz de lidar corretamente com esse problema envolvendo mapeamentos abstratos.
Rodada 8: Problemas de otimização combinatória (Triângulo máximo)
Pergunta: Há 1989 pontos no espaço, três dos quais não compartilham uma linha. Esses pontos são divididos em 30 grupos, cada um com um número diferente de pontos. Um triângulo pode ser formado tomando-se como vértice um ponto de quaisquer três grupos diferentes. P: Como o número de pontos em cada grupo pode ser distribuído de modo a maximizar o número de triângulos formados?
Análise: Esse é um problema de otimização em matemática combinatória que exige que os modelos compreendam os princípios da contagem combinatória e encontrem a estratégia de alocação ideal, envolvendo modelagem matemática mais complexa e ideias de otimização.
Resultados:o3-mini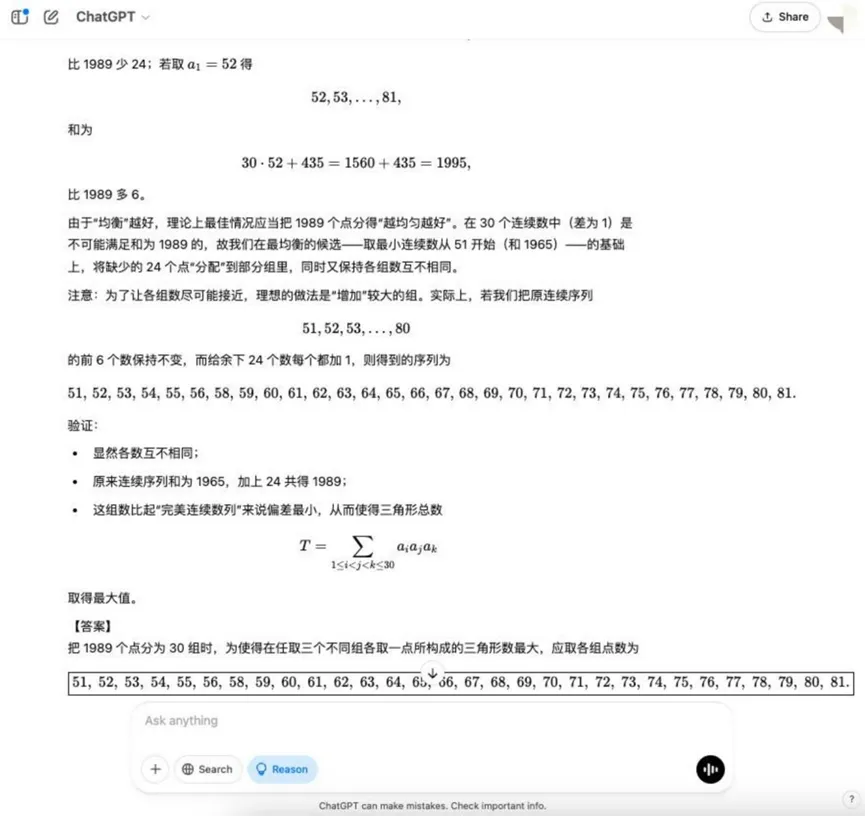
YiXin-Distill-Qwen-72B

Os problemas de otimização combinatória aumentam ainda mais a dificuldade e exigem mais das estratégias matemáticas e das habilidades computacionais do modelo.
Rodada 9: Problemas de teoria dos números (cadeias de fatores)
Descrição do problema Imagem:
Análise: Novamente, os conceitos de teoria dos números estão envolvidos, examinando a compreensão do modelo e a aplicação de relações como fatoriais e integralidade, que podem exigir provas construtivas ou contagem.
Resultados:o3-miniParcialmente correto
YiXin-Distill-Qwen-72B: Absolutamente correto.

YiXin-Distill-Qwen-72B Desempenho sólido sobre esse tópico de contagem.
Rodada 10: Problemas geométricos (pontos de área igual)
Descrição do problema Imagem:
Análise: A questão final era uma questão geométrica envolvendo cálculos de área, trajetórias de pontos ou provas de existência, testando a intuição geométrica, as operações algébricas e o raciocínio lógico do modelo.
Resultados:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B

As perguntas finais de geometria também mostraram diferenças entre os modelos em sua capacidade de lidar com problemas geométricos complexos.
Observações e análises
Com base nesse teste da capacidade matemática chinesa em vários modelos de idiomas grandes, podemos fazer as seguintes observações:
- A modelagem de habilidades matemáticas básicas melhora significativamente: Em comparação com os modelos anteriores, a geração atual de LLMs apresenta melhorias significativas no tratamento de problemas matemáticos que envolvem raciocínio em várias etapas, como geometria, probabilidade e alguns problemas de aplicativos abertos. Isso pode ser atribuído ao aumento do tamanho do modelo, à abundância de dados de treinamento e ao uso de técnicas de aprimoramento do raciocínio, como "cadeias de pensamento".
- Há diferenças nos estilos de solução de problemas: Modelos diferentes se comportam de forma diferente em termos do nível de detalhe do processo de solução.
o3-mini,Grok 3 beta,Tongyi Qwen-32BO resultado é relativamente conciso e as etapas de inferência são simples.DeepSeek R1,Hunyuan T1,YiXin-Distill-Qwen-72BA tendência de mostrar processos de pensamento mais detalhados, às vezes incluindo etapas de reflexão e correção, é mais "verbosa", mas isso pode ajudar a traçar a lógica de seu raciocínio.Gemini 2.0 Flash Thinkingnão é apenas demorado, mas também usa principalmente resultados em inglês, o que sugere que ele pode ser relativamente mal treinado no corpus matemático chinês.
- Robustez a erros de entrada: Observa-se no teste que, mesmo que haja pequenos erros de notação ou irregularidades de apresentação na descrição do problema, alguns modelos ainda conseguem entender corretamente o significado da pergunta e respondê-la, mostrando um certo grau de robustez. No entanto, isso não significa que os modelos possam sempre ignorar os erros, e erros em informações críticas ainda podem levar à falha na resposta.
- Aprimoramentos futuros: especialização e integração de ferramentas: Apesar do progresso óbvio, ainda há espaço para melhorias na precisão do LLM atual ao lidar com problemas matemáticos complexos, especialmente em questões difíceis de concursos e cenários que exigem provas rigorosas. Os caminhos de aprimoramento futuros podem incluir:
- Integração de mecanismos de computação externos: As deficiências do LLM em termos de computação exata e operações simbólicas são compensadas pela invocação de ferramentas de computação simbólica, como o Wolfram Alpha.
- Ajuste fino exclusivo do domínio: Construir conjuntos de dados ajustados de alta qualidade para lógica matemática, ramos específicos da matemática (por exemplo, álgebra, geometria, teoria da probabilidade) e fortalecer modelos para raciocínio especializado e profundidade de conhecimento.
- Aprendizado e revisão interativos: Desenvolva mecanismos que permitam ao usuário orientar o processo de solução, apontar erros e permitir que o modelo ajuste dinamicamente a estratégia de solução.
- Recomendações para os usuários:
- Alunos: O LLM pode ser usado para auxiliar o aprendizado, verificando rapidamente soluções e respostas a perguntas básicas. No entanto, para problemas complexos ou criativos, tenha cuidado com a possibilidade de o modelo fazer "bobagens sérias" (ou seja, dar a resposta errada com confiança).
- Educadores: Ao usar o ensino assistido por IA, é necessário elaborar perguntas que tenham maior probabilidade de testar a compreensão mais profunda e as habilidades de pensamento independente dos alunos, para que eles não dependam de modelos para chegar a respostas superficiais.
- Desenvolvedor: Ao aplicar o LLM para resolver problemas matemáticos, os limites do problema e os requisitos da solução devem ser esclarecidos por meio da otimização do Prompt Engineering para reduzir o raciocínio ineficaz ou o "brainstorming" do modelo devido à compreensão difusa.
Concluindo, a aplicação de modelos de linguagem em larga escala na matemática está gradualmente passando do estágio exploratório para o prático. A direção futura do desenvolvimento de modelos será buscar um melhor equilíbrio entre a simulação da flexibilidade do pensamento humano e a garantia do rigor da lógica matemática.
Observações:
Os melhores desempenhos nesta análise YiXin-Distill-Qwen-72B As informações do modelo são as seguintes:
- Versão padrão: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B
- AWQ Quantitative Edition: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B-AWQ
- Requisitos de recursos para implantação local: O 72B Standard Edition requer aproximadamente 8 placas de vídeo da classe NVIDIA 4090; o AWQ Quantitative Edition pode ser executado em 2 placas da mesma classe.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas


Nenhum comentário...