

众所周知,当我们需要让大语言模型执行任务,需要输入 Prompt 来指导其执行,而 Prompt 是使用自然语言描述的。对于简单的任务,自然语言能描述的很清楚,比如:“请翻译以下内容为简体中文:”、“请生成以下内容的摘要:”等。
但是当我们遇到一些复杂的任务,比如要求模型生成特定的 JSON 格式,或者任务有多个分支,每个分支需要执行多个子任务,子任务之间还相互关联,这时候用自然语言描述就显得力不从心了。
思考题
在继续阅读之前,这里有两道思考题可以先试试看:
- 有多个长句子,需要将每一个都拆分成不超过 80 个字符的短句子,然后输出成一个 JSON 格式,清晰的描述长句子和短句子之间的对应关系。
比如:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- 一段原始字幕文稿,只有对话信息,现在需要从中提取章节、发言人,然后按照章节和段落列出对话内容。如果是多个发言人,每段对话前需要标明发言人,如果是同一个发言人连续发言,则不需要。(实际上这就是我自己用的一个整理视频文稿的 GPT 视频文稿整理 GPT)
示例输入:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
示例输出:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
Prompt 的本质
或许你已经在网上看过很多关于如何写 Prompt 技巧的文章,记住了很多 Prompt 模板,但是 Prompt 的本质是什么呢?我们为什么需要 Prompt?
Prompt 的本质是一种对 LLM 的控制指令,用自然语言描述,让 LLM 理解我们的要求,然后按照要求把输入变成我们期望的输出结果。
比如常用的 few-shot 技巧,就是通过举例子,通过示例让 LLM 理解我们的要求,然后参考样例输出我们期望的结果。比如 CoT(思维链,Chain of Thought),就是通过人为的对任务进行分解,并且限定执行的流程,让 LLM 能按照我们指定的流程和步骤执行,而不至于过于发散或者跳过关键步骤,从而得到更好的结果。
就好比我们上学的时候,老师在讲数学定理,要给我们举例子,通过例子让我们理解定理的含义;在做实验的时候,要告诉我们实验的步骤,哪怕不理解实验的原理,但能按照步骤执行实验,也能得到差不多的结果。
为什么有时候 Prompt 的结果不够理想呢?
因为 LLM 不能准确的理解我们的要求,这里面一方面局限于 LLM 理解和跟随指令的能力,另一方面局限于我们的 Prompt 描述的是否清晰和准确。
如何借助伪代码精准的控制 LLM 的输出结果和定义其执行逻辑
既然 Prompt 的本质是一种对 LLM 的控制指令,那么我们可以不必局限于传统自然语言描述的方式写 Prompt,还可以借助伪代码(pseudocode)来精准的控制 LLM 的输出结果和定义其执行逻辑。
什么是伪代码?
实际上伪代码已经有很长的历史了,伪代码是一种用于描述算法的一种形式化描述方法,它是一种介于自然语言和编程语言之间的一种描述方法,用于描述算法的步骤和流程。在各种算法书籍和论文中,我们经常看到伪代码的描述,甚至于你不需要懂变成语言,也能通过伪代码理解算法的执行流程。
那么 LLM 对于伪代码的理解能力如何呢?实际上 LLM 对于伪代码的理解能力是相当强的,LLM 在训练的时候,已经训练过大量的优质代码,可以轻易的理解伪代码的含义。
如何写伪代码 Prompt?
伪代码对于程序员来说是非常熟悉的,对于非程序员,只需要记住一些基本的规则,就可以写出简单的伪代码。举几个例子:
- 变量,用来存储数据,比如用一些特定符号表示输入或者中间结果
- 类型,用来定义数据的类型,比如字符串、数字、数组等
- 函数,用来定义某个子任务的执行逻辑
- 控制流,用来控制程序的执行流程,比如循环、条件判断等
- if-else 语句,如果满足条件 A,执行任务 A,否则执行任务 B
- for 循环,对于数组中的每一个元素,执行某个任务
- while 循环,当满足条件 A,持续执行任务 B
现在以前面的两个思考题为例,我们来写一下伪代码 Prompt。
用伪代码输出特定的 JSON 格式
借助一段类似于 TypeScript 类型定义的伪代码,就可以清晰的描述我们期望的 JSON 格式:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
用伪代码整理字幕文稿
整理字幕文稿这个任务相对比较复杂,如果想象一下要写一个程序来完成这个任务,可能会有很多步骤,比如先提取章节,再提取发言人,最后按照章节和发言人整理对话内容。我们可以借助伪代码,将这个任务分解成几个子任务,对于子任务,甚至不必写出具体的代码,只需要描述清楚子任务的执行逻辑即可。然后一步步执行这些子任务,最后整合结果输出。
我们可以用一些变量来存储中,比如 subject、speakers、chapters、paragraphs 等。
在输出的时候,我们还可以用 For 循环来遍历章节和段落,用 If-else 语句来判断是否需要输出发言人的名字。
You task is to re-organize video transcripts for readability, and recognize speakers for multi-person dialogues. Here are the pseudo-code on how to do it:
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
看看效果如何:
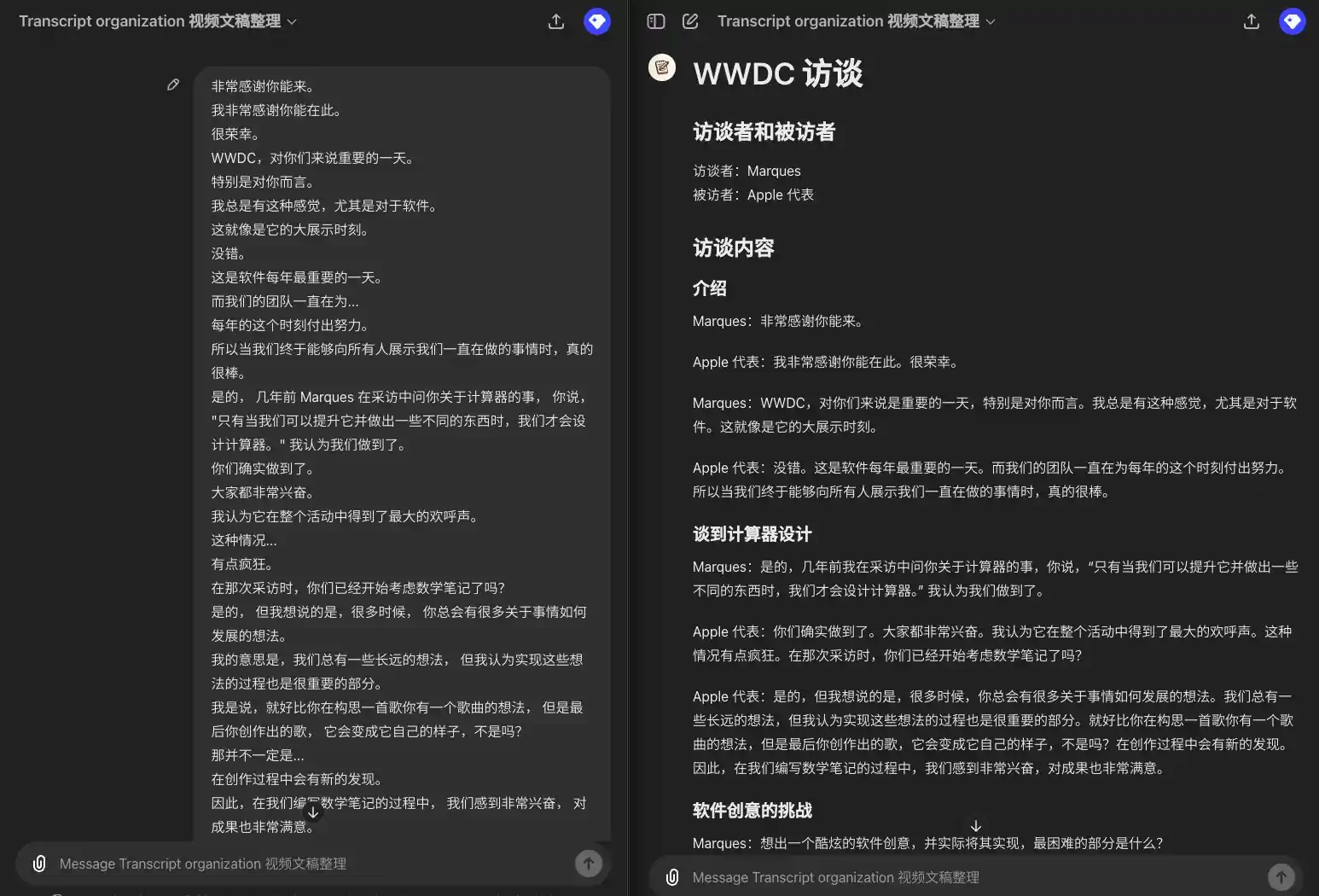
整理 WWDC 访问文稿
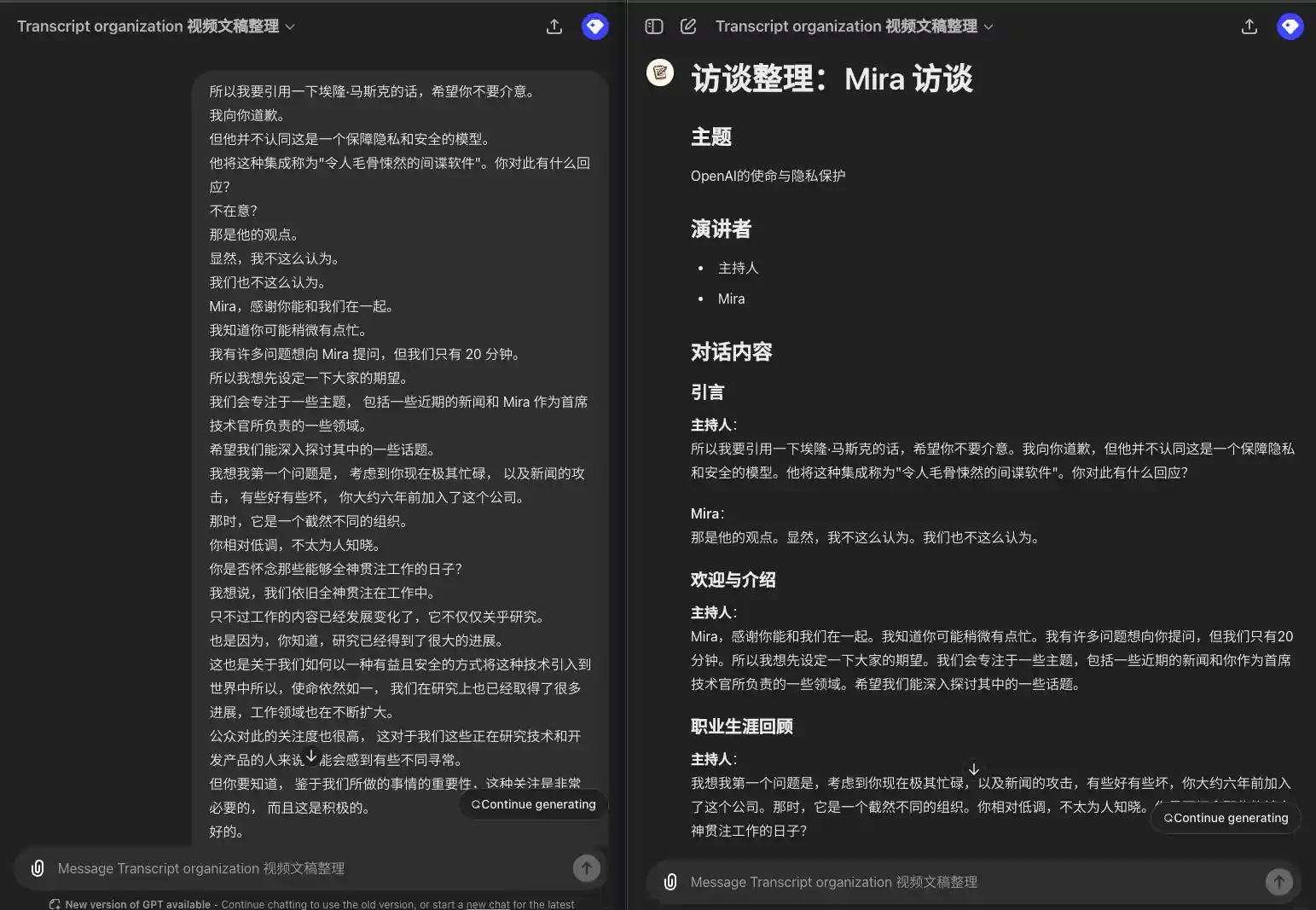
多个 Speaker,显示发言人
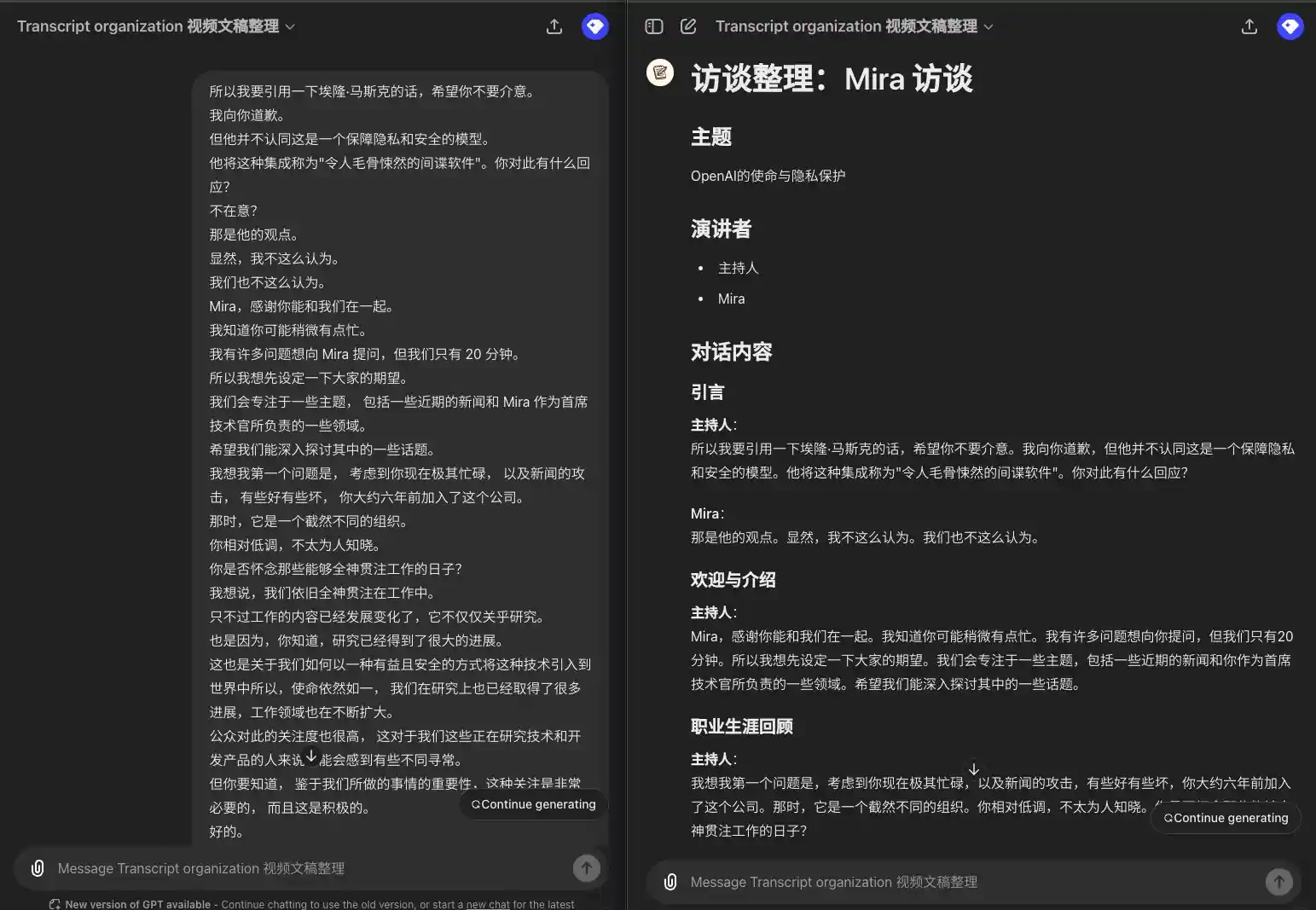
1 个 Speaker,不显示发言人
你也可以直接使用我用这个 Prompt 生成的 GPT:Transcript organization 视频文稿整理 GPT
借助伪代码让 ChatGPT 一次画多张图片
最近还从一位台湾网友尹相志老師那里学到了一个很有意思的用法,就是借助伪代码,让 ChatGPT 一次画多张图片。
现在如果你想让 ChatGPT 画图,一般一次只会给你生成一张图片,如果你想一次生成多张图片,可以借助伪代码,将多个图片的生成任务分解成多个子任务,然后一次执行多个子任务,最后整合结果输出。
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

总结
通过上面的例子,我们可以看到,借助伪代码,我们可以更精准的控制 LLM 的输出结果和定义其执行逻辑,而不仅仅局限于自然语言描述的方式。当我们遇到一些复杂的任务,或者任务有多个分支,每个分支需要执行多个子任务,子任务之间还相互关联,这时候用伪代码描述 Prompt,会更加清晰和准确。
当我们写 Prompt 时,记住 Prompt 的本质是一种对 LLM 的控制指令,用自然语言描述,让 LLM 理解我们的要求,然后按照要求把输入变成我们期望的输出结果。至于用什么形式来描述 Prompt,则可以多种形式灵活运用,比如 few-shot(少样本样例)、CoT(思维链)、伪代码等。
更多示例:
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...