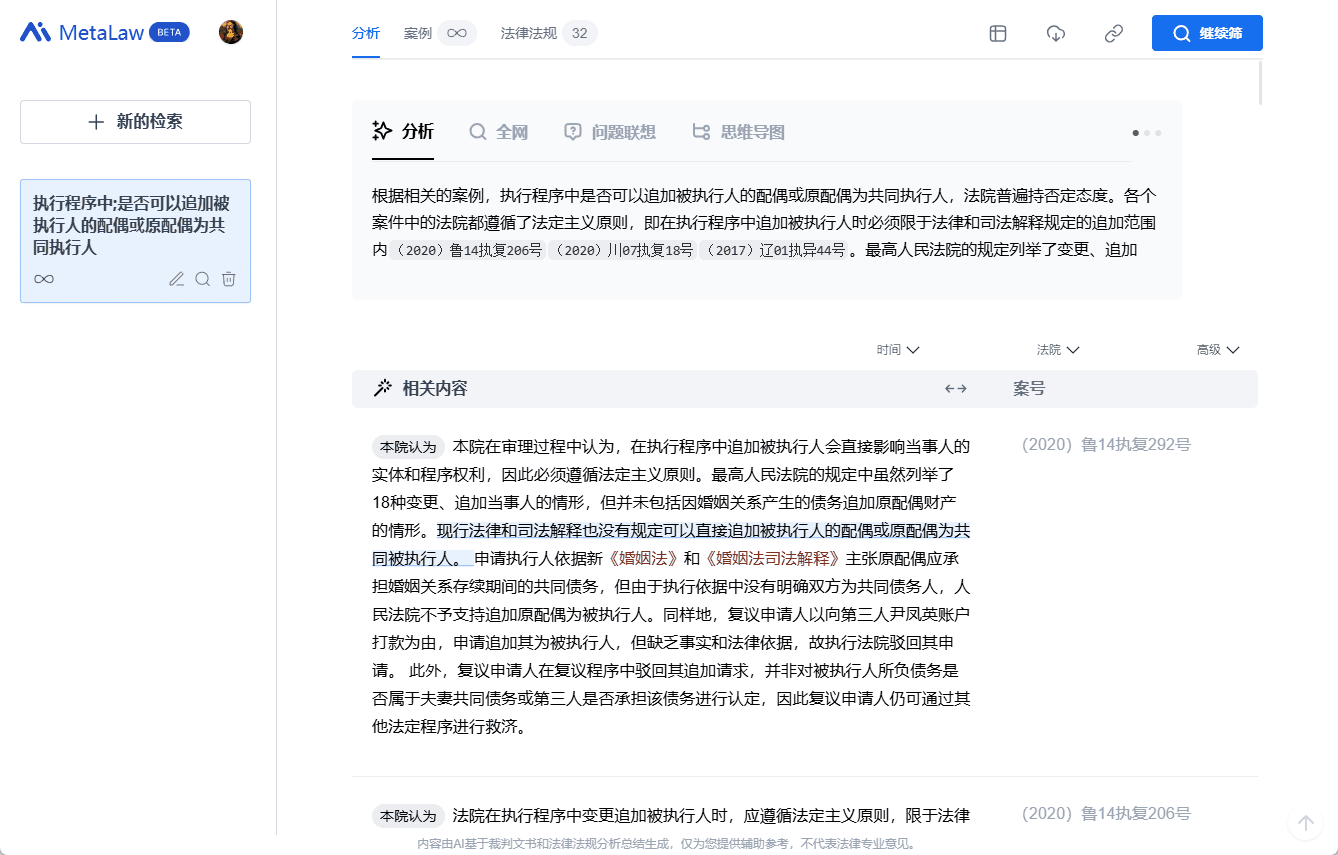

综合介绍
LiveTalking是一个开源的实时互动数字人系统,致力于构建高质量的数字人直播解决方案。该项目采用Apache 2.0开源协议,集成了多项前沿技术,包括ER-NeRF渲染、实时音视频流处理、唇形同步等。系统支持实时数字人渲染和互动,可用于直播、在线教育、客服等多个场景。项目在GitHub上获得了超过4300个星标和600多个分支,展现了强大的社区影响力。LiveTalking特别注重实时性能和交互体验,通过整合AIGC技术,为用户提供了一个完整的数字人开发框架。项目持续更新维护,拥有完善的文档支持,是构建数字人应用的理想选择。

功能列表
- 支持多种数字人模型:ernerf、musetalk、wav2lip、Ultralight-Digital-Human
- 实现音视频同步对话
- 支持声音克隆
- 支持数字人说话被打断
- 支持全身视频拼接
- 支持 RTMP 和 WebRTC 推流
- 支持视频编排:不说话时播放自定义视频
- 支持多并发
使用帮助
1.安装流程
- 环境要求 :Ubuntu 20.04, Python 3.10, Pytorch 1.12, CUDA 11.3
- 安装依赖 :
conda create -n nerfstream python=3.10
conda activate nerfstream
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
如果不训练 ernerf 模型,不需要安装以下库:
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
pip install --upgrade "protobuf<=3.20.1"
2.快速开始
- 运行 SRS :
export CANDIDATE='<服务器外网ip>'
docker run --rm --env CANDIDATE=$CANDIDATE -p 1935:1935 -p 8080:8080 -p 1985:1985 -p 8000:8000/udp registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5 objs/srs -c conf/rtc.conf
备注:服务端需要开放端口 tcp:8000,8010,1985; udp:8000
- 启动数字人 :
python app.py
如果访问不了 Huggingface,在运行前执行:
export HF_ENDPOINT=https://hf-mirror.com
用浏览器打开 http://serverip:8010/rtcpushapi.html,在文本框输入任意文字,提交,数字人将播报该段文字。
更多使用说明
- Docker 运行 :不需要前面的安装,直接运行:
docker run --gpus all -it --network=host --rm registry.cn-beijing.aliyuncs.com/codewithgpu2/lipku-metahuman-stream:vjo1Y6NJ3N
代码在 /root/metahuman-stream,先 git pull 拉一下最新代码,然后执行命令同第2、3步。
3. 配置说明
- 系统配置
- 编辑config.yaml文件,设置基本参数
- 配置摄像头和音频设备
- 设置AI模型参数和路径
- 配置直播推流参数
- 数字人模型准备
- 支持导入自定义3D模型
- 可使用预置的示例模型
- 支持MetaHuman模型导入
主要功能操作
- 实时音视频同步对话:
- 选择数字人模型:在配置页面中选择合适的数字人模型(如ernerf、musetalk等)。
- 选择音视频传输方式:根据需求选择合适的音视频传输方式(如WebRTC、RTMP等)。
- 开始对话:启动音视频传输,即可实现实时音视频同步对话。
- 数字人模型切换:
- 进入设置页面:在项目运行页面中,点击设置按钮进入设置页面。
- 选择新模型:在设置页面中选择新的数字人模型,并保存设置。
- 重启项目:重启项目以应用新的模型配置。
- 音视频参数调整:
- 进入参数设置页面:在项目运行页面中,点击参数设置按钮进入参数设置页面。
- 调整参数:根据需求调整音视频参数(如分辨率、帧率等)。
- 保存并应用:保存设置,并应用新的参数配置。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...