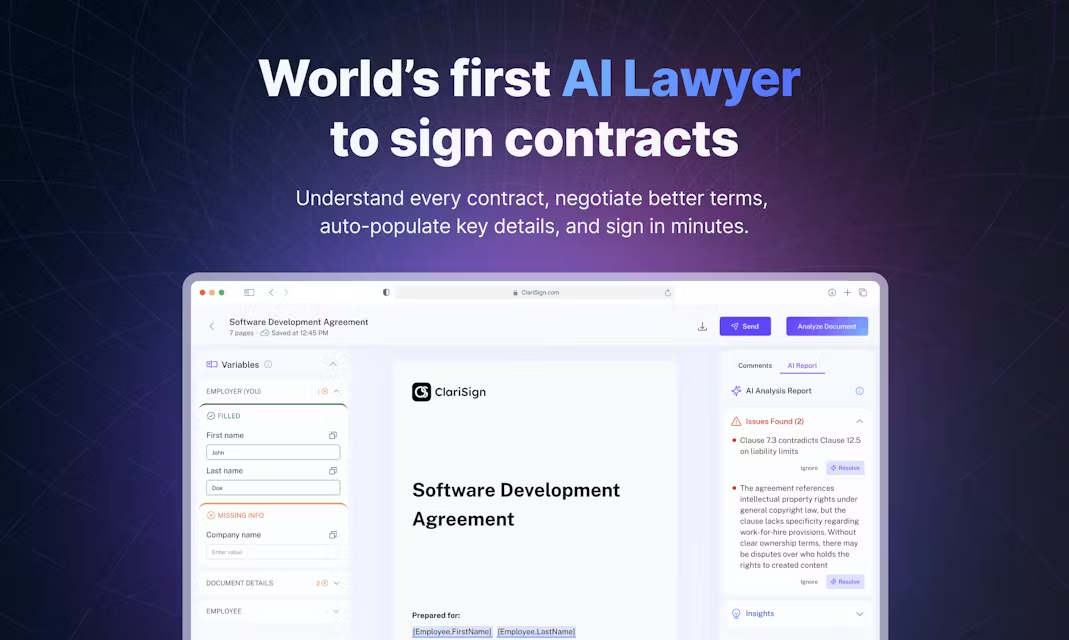

Lepton Search 综合介绍
Lepton Search是一个对话式AI搜索引擎,由贾扬清推出,使用Lepton AI平台构建。Lepton Search可以根据用户的自然语言问题,主动搜索网络数据并整理成有条理和逻辑的答案,并且附带信息来源。Lepton Search不仅可以回答常见的知识性问题,如“电子是轻子吗?”或“人类第一次登月是什么时候?”,还可以回答一些复杂的问题,如“为什么苹果会掉下来?”或“如何用Python编写一个聊天机器人?”。Lepton Search的代码是开源的,开发者可以自行部署和修改,也可以使用Lepton AI平台快速搭建自己的对话式AI应用。

Lepton Search 主页

Lepton Search 搜索结果页
Lepton Search 功能列表
- 支持自然语言输入和输出
- 支持多种类型的问题,包括知识性、原因性、方法性等
- 支持多种数据源,包括Wikipedia、Twitter、Google、Bing等
- 支持多种语言,包括英语、中文、日语等
- 支持多种展示方式,包括文本、图片、表格、图表等
- 支持多种交互方式,包括网页、命令行、API等
Lepton Search 使用帮助
- 在网页版,输入您想要搜索的问题,按回车键或点击搜索按钮,即可看到Lepton Search的回答
- 在官方GitHub仓库中查阅使用文档
- 可按照官方Demo搭建个人的搜索引擎
- 开发者可以在Apache License授权下自由使用开源代码
Lepton Search 代码注释
# 导入必要的库和模块
import concurrent.futures # 用于并发执行任务
import glob # 用于文件路径模式匹配
import json # 用于处理JSON数据
import os # 用于操作文件系统
import re # 用于正则表达式匹配
import threading # 用于线程操作
import requests # 用于发起网络请求
import traceback # 用于追踪异常信息
from typing import Annotated, List, Generator, Optional # 用于类型注解# 导入FastAPI相关的类和异常
from fastapi import HTTPException
from fastapi.responses import HTMLResponse, StreamingResponse, RedirectResponse
import httpx # 用于HTTP请求
from loguru import logger # 用于日志记录# 导入Lepton AI相关的库和模块
import leptonai
from leptonai import Client
from leptonai.kv import KV # 用于键值存储
from leptonai.photon import Photon, StaticFiles # 用于Photon应用开发
from leptonai.photon.types import to_bool # 用于布尔值转换
from leptonai.api.workspace import WorkspaceInfoLocalRecord # 用于工作空间信息
from leptonai.util import tool # 包含一些实用工具# RAG模型的常量值
BING_SEARCH_V7_ENDPOINT = "https://api.bing.microsoft.com/v7.0/search" # 必应搜索API端点
BING_MKT = "en-US" # 必应搜索市场
GOOGLE_SEARCH_ENDPOINT = "https://customsearch.googleapis.com/customsearch/v1" # 谷歌自定义搜索API端点
SERPER_SEARCH_ENDPOINT = "https://google.serper.dev/search" # Serper搜索API端点
SEARCHAPI_SEARCH_ENDPOINT = "https://www.searchapi.io/api/v1/search" # SearchApi搜索API端点# 搜索结果数量
REFERENCE_COUNT = 8# 搜索超时时间
DEFAULT_SEARCH_ENGINE_TIMEOUT = 5# 默认查询
_default_query = "Who said 'live long and prosper'?"# RAG模型的查询文本模板
_rag_query_text = """你是由Lepton AI构建的大型语言AI助手。当你收到一个用户问题,请提供干净、简洁且准确的回答。你将获得一系列与问题相关的上下文,每个上下文前都有一个引用编号,如[[citation:x]],其中x为数字。请使用这些上下文,并在适用的情况下在每句话的末尾引用上下文编号。
你的回答必须正确、准确,并且由专家用中立和专业的语气撰写。请限制在1024个令牌以内。不要提供与问题无关的信息,也不要重复。如果给定的上下文没有提供足够的信息,请说“关于...的信息缺失”。
请用引用编号的格式引用上下文,如[citation:x]。如果一句话来自多个上下文,请列出所有适用的引用,如[citation:3][citation:5]。除了代码、特定名称和引用之外,你的回答必须使用与问题相同的语言。
这里是一系列的上下文:
{context}
记住,不要盲目地逐字重复上下文。这里是用户的问题:
"""
# 停用词列表
stop_words = [
"<|im_end|>",
"[End]",
"[end]",
"\nReferences:\n",
"\nSources:\n",
"End.",
]# 生成相关问题的提示文本
_more_questions_prompt = """你是一个有用的助手,帮助用户根据原始问题及其相关上下文提出相关问题。请确定值得跟进的话题,并且用不超过20个词的问题进行提问。请确保具体信息,如事件、名字、地点等,在后续问题中被包含,以便它们可以独立提问。例如,如果原始问题询问的是“曼哈顿计划”,在后续问题中,不要仅仅说“该计划”,而应使用完整名称“曼哈顿计划”。你的相关问题必须与原始问题保持相同的语言。
这里是问题的上下文:
{context}
记住,基于原始问题及相关上下文,提出三个这样的进一步问题。不要重复原始问题。每个相关问题都应该不超过20个词。这是原始问题:
"""
# 以下是搜索函数的定义,用于与不同的搜索引擎进行交互
def search_with_bing(query: str, subscription_key: str):
# 使用必应搜索引擎进行搜索并返回上下文信息
passdef search_with_google(query: str, subscription_key: str, cx: str):
# 使用谷歌搜索引擎进行搜索并返回上下文信息
passdef search_with_serper(query: str, subscription_key: str):
# 使用Serper搜索引擎进行搜索并返回上下文信息
passdef search_with_searchapi(query: str, subscription_key: str):
# 使用SearchApi.io进行搜索并返回上下文信息
pass# RAG类,继承自Photon,用于构建RAG引擎
class RAG(Photon):
# 类的初始化和方法定义
pass# 如果直接运行此脚本,则启动RAG应用
if __name__ == "__main__":
rag = RAG()
rag.launch()
开源地址
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...