

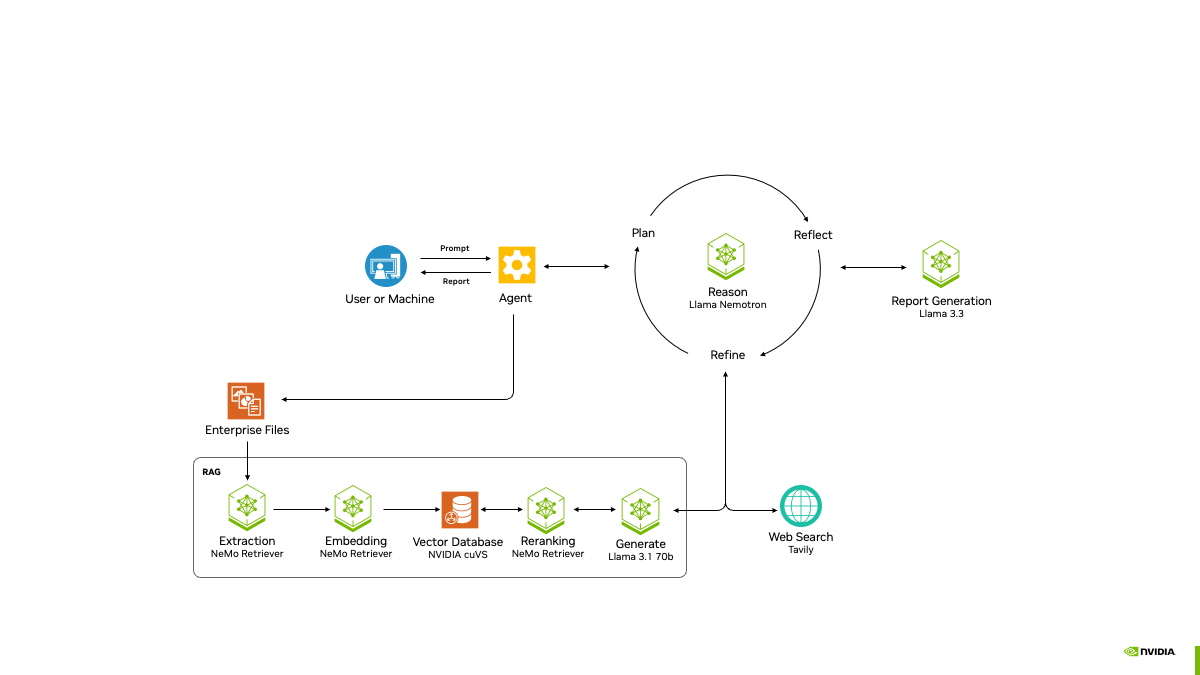

综合介绍
LatentSync 是字节跳动(ByteDance)开发的一个开源工具,托管在 GitHub 上。它通过音频直接驱动视频中人物的唇部动作,让嘴型与声音精准匹配。项目基于 Stable Diffusion 的 latent diffusion 模型,结合 Whisper 提取音频特征,通过 U-Net 网络生成视频帧。2025 年 3 月 14 日发布的 LatentSync 1.5 版本优化了时间一致性、对中文视频的支持,并将训练显存需求降至 20GB。用户只需准备一台支持 6.8GB 显存的显卡,就能运行推理代码,生成 256x256 分辨率的唇形同步视频。工具完全免费,提供代码和预训练模型,适合技术爱好者和开发者使用。

体验地址:https://huggingface.co/spaces/fffiloni/LatentSync
API演示地址:https://fal.ai/models/fal-ai/latentsync

功能列表
- 音频驱动唇形同步:输入音频和视频,自动生成与声音匹配的唇部动作。
- 端到端视频生成:无需中间表示,直接输出清晰的唇形同步视频。
- 时间一致性优化:通过 TREPA 技术和时序层减少画面跳动。
- 支持中文视频:1.5 版本提升了对中文音频和视频的处理效果。
- 高效训练支持:提供多种 U-Net 配置,显存需求低至 20GB。
- 数据处理管道:内置工具清洗视频数据,保证生成质量。
- 参数调整:支持调整推理步数和引导尺度,优化生成效果。
使用帮助
LatentSync 是一个本地运行的工具,适合有技术基础的用户。下面详细介绍安装、推理和训练流程。
安装流程
- 硬件和软件要求
- 需要 NVIDIA 显卡,至少 6.8GB 显存(推理用),训练推荐 20GB 以上(如 RTX 3090)。
- 支持 Linux 或 Windows(Windows 需手动调整脚本)。
- 安装 Python 3.10、Git 和 CUDA 支持的 PyTorch。
- 下载代码
在终端运行:
git clone https://github.com/bytedance/LatentSync.git
cd LatentSync
- 安装依赖
执行以下命令安装所需库:
pip install -r requirements.txt
额外安装 ffmpeg,用于音视频处理:
sudo apt-get install ffmpeg # Linux
- 下载模型
- 从 Hugging Face 下载
latentsync_unet.pt和tiny.pt。 - 将文件放入
checkpoints/目录,结构如下:checkpoints/ ├── latentsync_unet.pt ├── whisper/ │ └── tiny.pt - 若训练 SyncNet,还需下载
stable_syncnet.pt和其他辅助模型。
- 验证环境
运行测试命令:
python gradio_app.py --help
若无报错,环境搭建成功。
推理流程
LatentSync 提供两种推理方式,显存需求均为 6.8GB。
方法 1:Gradio 界面
- 启动 Gradio 应用:
python gradio_app.py
- 打开浏览器,访问提示的本地地址。
- 上传视频和音频文件,点击运行,等待生成结果。
方法 2:命令行
- 准备输入文件:
- 视频(如
input.mp4),需含清晰人脸。 - 音频(如
audio.wav),建议 16000Hz。
- 运行推理脚本:
python -m scripts.inference
--unet_config_path "configs/unet/stage2_efficient.yaml"
--inference_ckpt_path "checkpoints/latentsync_unet.pt"
--inference_steps 25
--guidance_scale 2.0
--video_path "input.mp4"
--audio_path "audio.wav"
--video_out_path "output.mp4"
inference_steps:20-50,值越大质量越高,速度越慢。guidance_scale:1.0-3.0,值越高唇形越准,可能有轻微失真。
- 检查
output.mp4,确认唇形同步效果。
输入预处理
- 视频帧率建议调整为 25 FPS:
ffmpeg -i input.mp4 -r 25 resized.mp4
- 音频采样率需为 16000Hz:
ffmpeg -i audio.mp3 -ar 16000 audio.wav
数据处理流程
若需训练模型,需先处理数据:
- 运行脚本:
./data_processing_pipeline.sh
- 修改
input_dir为你的视频目录。 - 流程包括:
- 删除损坏视频。
- 调整视频为 25 FPS,音频为 16000Hz。
- 使用 PySceneDetect 分割场景。
- 将视频切为 5-10 秒片段。
- 用 face-alignment 检测人脸并调整为 256x256。
- 过滤同步得分低于 3 的视频。
- 计算 hyperIQA 分数,移除低于 40 的视频。
- 处理后的视频保存在
high_visual_quality/目录。
训练 U-Net
- 准备数据和所有检查点。
- 选择配置文件(如
stage2_efficient.yaml)。 - 运行训练:
./train_unet.sh
- 修改配置文件中的数据路径和保存路径。
- 显存需求:
stage1.yaml:23GB。stage2.yaml:30GB。stage2_efficient.yaml:20GB,适合普通显卡。
注意事项
- Windows 用户需将
.sh改为 Python 命令运行。 - 若画面跳动,增加
inference_steps或调整视频帧率。 - 中文音频支持在 1.5 版本优化,确保使用最新模型。
通过以上步骤,用户可以轻松安装并使用 LatentSync 生成唇形同步视频,或进一步训练模型。
应用场景
- 影视后期
为已有视频替换音频,生成新唇形,适合配音调整。 - 虚拟形象
输入音频,生成虚拟人物说话视频,用于直播或短视频。 - 游戏制作
为角色添加动态对话动画,提升游戏体验。 - 多语言教学
用不同语言音频生成教学视频,适配全球用户。
QA
- 支持实时生成吗?
不支持。当前版本需完整音频和视频,生成耗时数秒到数分钟。 - 最低显存是多少?
推理需要 6.8GB,训练推荐 20GB(1.5 版本优化后)。 - 可以处理动漫视频吗?
可以。官方示例中包括动漫视频,效果良好。 - 如何提高中文支持?
使用 LatentSync 1.5 版本,已优化中文音频处理。
LatentSync 一键安装包
夸克:https://pan.quark.cn/s/c3b482dcca83
WIN/MAC独立安装包
夸克:https://pan.quark.cn/s/90d2784bc502
百度:https://pan.baidu.com/s/1HwN1k6v-975uLfI0d8N_zQ?pwd=gewd
LatentSync加强版:https://pan.quark.cn/s/f8d3d9872abb
LatentSync1.5本地部署1:https://pan.baidu.com/s/1QLqoXHxGbAXV3dWOC5M5zg?pwd=ijtt
LatentSync1.5本地部署2:https://pan.baidu.com/share/init?surl=zIUPiJc0qZaMp2NMYNoAug&pwd=8520
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...