
Phi-4는 140억 개의 파라미터만으로 혁신적인 훈련 방법과 고품질 데이터를 통해 일부 대규모 모델과 비슷하거나 심지어 이를 능가하는 성능을 보여줍니다. 이 백서에서는 실제 애플리케이션과 벤치마크에서 Phi-4의 아키텍처, 기능, 훈련 방법론 및 성능에 대해 자세히 설명합니다.
https://github.com/xinyuwei-david/david-share.git
I. 용량 측정을 위한 지표 살펴보기

o1과 Phi-4를 비교하는 세 가지 질문을 측정합니다.
첫 번째 질문입니다:
phi-4

o1

두 번째 질문입니다:
Phi-4.

o1:
세 번째 질문입니다:
Phi-4

o1.
要求五个连续偶数的平均数,已知它们的和为90,下面我们逐步解答。步骤1:设未知数设这五个连续的偶数为:第一个偶数:( n - 4 )第二个偶数:( n - 2 )第三个偶数:( n )第四个偶数:( n + 2 )第五个偶数:( n + 4 )(因为偶数之间相差2,所以相邻的偶数可以这样表示)步骤2:列方程求和根据题目,五个数的和为90:[(n - 4) + (n - 2) + n + (n + 2) + (n + 4) = 90]步骤3:简化方程合并同类项:[5n = 90]步骤4:求解 n[n = frac{90}{5} = 18]步骤5:求出五个偶数第一个偶数:( 18 - 4 = 14 )第二个偶数:( 18 - 2 = 16 )第三个偶数:( 18 )第四个偶数:( 18 + 2 = 20 )第五个偶数:( 18 + 4 = 22 )步骤6:计算平均数平均数等于总和除以数量:[text{平均数} = frac{14 + 16 + 18 + 20 + 22}{5} = frac{90}{5} = 18]答案:这五个连续的偶数的平均数是 18。
이런 식으로 보면 Phi-4의 추론은 여전히 괜찮습니다.
II. Phi-4 모델 아키텍처
1. 트랜스포머 기반 디코더 아키텍처
Phi-4는 다음을 기반으로 하는 시스템을 사용합니다. 트랜스포머 (명목식 형태로 사용됨) 디코더 전용 이 아키텍처는 GPT 모델군과 유사합니다. 이 아키텍처는 자기 주의 메커니즘을 활용하여 텍스트 시퀀스의 장기적인 종속성을 효과적으로 포착하고 자연어 생성 작업에 탁월합니다.
2. 매개변수 크기 및 레이어 수
- 총 매개변수 수입니다: 140억 달러(14B) 매개변수.
- 모델 층수: 40
3. 컨텍스트 길이
- 초기 컨텍스트 길이: 4,096 토큰.
- 중기 교육 연장: 훈련 중간 단계에서 Phi-4의 컨텍스트 길이가 다음과 같이 확장되었습니다. 16,000 토큰(16K)을 추가하여 모델의 긴 텍스트 처리 능력을 향상시켰습니다.
4. 용어집 및 렉서
- 스플리터: OpenAI의 틱톡 스플리터이 회사는 다국어를 지원하며 자막 효과가 더 좋습니다.
- 용어집 크기: 100,352여기에는 사용하지 않은 일부 예약 토큰이 포함됩니다.
III. 주의 메커니즘 및 위치 코딩
1. 글로벌 관심 메커니즘
Phi-4 용도 전체 주의 메커니즘즉, 전체 컨텍스트 시퀀스에 대해 자기 주의력이 계산됩니다. 이는 2,048개를 사용하는 이전 모델인 Phi-3-medium과는 대조적입니다. 토큰 의 슬라이딩 윈도우를 사용하는 반면, Phi-4는 4,096 토큰(초기) 및 16,000 토큰(확장)의 컨텍스트에서 직접 글로벌 주의 계산을 수행하여 모델의 장거리 종속성을 포착하는 능력을 향상시킵니다.
2. 회전 위치 인코딩(RoPE)
더 긴 컨텍스트 길이를 지원하기 위해 Phi-4는 훈련 도중에 다음과 같이 조정되었습니다. 로터리 위치 임베딩(RoPE) 의 기본 주파수입니다:
- 기본 주파수 조정: RoPE의 기본 주파수를 다음과 같이 증가시킵니다. 250,000를 사용하여 16K 컨텍스트 길이를 수용합니다.
- 역할: RoPE는 모델이 긴 시퀀스에서 위치 인코딩의 효율성을 유지하도록 지원하여 긴 텍스트에서도 우수한 성능을 유지할 수 있도록 합니다.
IV. 교육 전략 및 방법
1. 데이터 품질 우선순위 지정의 개념
Phi-4의 교육 전략은 다음을 기반으로 합니다. 데이터 품질 을 핵심으로 합니다. 주로 인터넷의 유기적 데이터(예: 웹 콘텐츠, 코드 등)를 사용하여 사전 학습하는 다른 모델과 달리 Phi-4는 학습 프로세스 전반에 걸쳐 전략적으로 다음과 같은 요소를 도입합니다. 합성 데이터.
합성 데이터의 생성 및 적용 2.
합성 데이터 는 Phi-4의 사전 교육과 중간 교육에서 핵심적인 역할을 했습니다:
- 다양한 데이터 생성 기술:
- 멀티 에이전트 프롬프트: 여러 언어 모델 또는 에이전트를 사용하여 데이터를 공동 생성함으로써 데이터의 다양성이 더욱 풍부해집니다.
- 자체 수정 워크플로: 모델이 초기 출력을 생성한 후에는 자체 평가 및 수정을 수행하여 출력의 품질을 반복적으로 개선합니다.
- 명령 반전: 기존 출력에서 해당 입력 지침을 생성하면 모델의 지침 이해 및 생성 능력이 향상됩니다.
- 합성 데이터의 장점:
- 체계적이고 점진적인 학습: 합성 데이터를 통해 난이도와 내용을 정밀하게 제어하여 모델이 복잡한 추론과 문제 해결 능력을 점진적으로 학습하도록 유도할 수 있습니다.
- 교육 효율성을 개선하세요: 합성 데이터 생성은 모델의 취약점에 대한 타겟팅된 학습 데이터를 제공할 수 있습니다.
- 데이터 오염을 방지하세요: 합성 데이터가 생성되므로 리뷰 세트의 내용이 포함된 학습 데이터의 위험을 피할 수 있습니다.
3. 오가닉 데이터의 정밀한 선별 및 필터링
Phi-4는 합성 데이터 외에도 여러 소스에서 고품질 데이터를 신중하게 선택하고 필터링하는 데 중점을 둡니다. 오가닉 데이터::
- 데이터 소스: 웹 콘텐츠, 책, 코드 라이브러리, 학술 논문 등이 포함됩니다.
- 데이터 필터링:
- 품질이 낮은 콘텐츠를 제거합니다: 자동 및 수동 방법을 사용하여 무의미하거나 부정확하거나 중복되거나 유해한 콘텐츠를 걸러냅니다.
- 데이터 오염을 방지하세요: 훈련 데이터에 리뷰 세트의 콘텐츠가 포함되지 않도록 하기 위해 중복 제거 및 오염 제거를 위해 하이브리드 n-그램 알고리즘(13-그램 및 7-그램)을 사용했습니다.
4. 데이터 혼합 전략
Phi-4는 다음과 같은 비율로 학습 데이터의 구성을 최적화했습니다:
- 합성 데이터: 소유 40%.
- 웹 재작성: 소유 15%새 교육 샘플의 경우 고품질 웹 콘텐츠에서 다시 작성하여 새 교육 샘플을 생성합니다.
- 오가닉 웹 데이터: 소유 15%웹 콘텐츠는 가치 있는 웹 콘텐츠를 엄선한 것입니다.
- 코드 데이터: 소유 20%공개 코드 베이스 및 생성된 코드 합성 데이터를 포함합니다.
- 타겟팅된 획득: 소유 10%학술 논문, 전문 서적 및 기타 고부가가치 콘텐츠를 포함합니다.
5. 다단계 교육 과정
사전 교육 단계:
- 목표: 기본적인 언어적 이해와 생성 기술을 모델링합니다.
- 데이터 볼륨: 예약하기 10조(10T) 토큰.
중기 교육 단계:
- 목표: 컨텍스트 길이를 확장하여 긴 텍스트 처리를 개선합니다.
- 데이터 볼륨: 2,500억(2,500억 달러) 토큰.
교육 후 단계(미세 조정):
- 감독형 미세 조정(SFT): 고품질의 다중 도메인 데이터를 사용하여 미세 조정하면 모델의 지시 사항을 따르는 능력과 응답 품질이 향상됩니다.
- 직접 환경 설정 최적화(DPO): 활용 피보탈 토큰 검색(PTS) 및 기타 방법을 사용하여 모델 출력을 더욱 최적화할 수 있습니다.
V. 혁신적인 교육 기술
1. 피보탈 토큰 검색(PTS)
PTS 방법론 는 Phi-4 교육 과정의 주요 혁신입니다:
- 원칙: 생성 과정에서 정답의 정확성에 큰 영향을 미치는 주요 토큰을 식별함으로써, 모델은 이러한 토큰에 대한 예측을 최적화하는 것을 목표로 합니다.
- 장점:
- 교육 효율성을 개선하세요: 결과에 가장 큰 영향을 미치는 부분에 최적화를 집중하면 효과가 두 배로 높아집니다.
- 모델 성능 향상: 모델이 주요 의사 결정 지점에서 올바른 선택을 하도록 돕고 결과물의 전반적인 품질을 향상시킵니다.
2. 직접 환경 설정 최적화(DPO) 개선
- DPO 방식: 최적화는 선호도 데이터를 사용하여 직접 수행되어 모델의 결과가 사람의 선호도와 더 일치하도록 합니다.
- 혁신 포인트:
- PTS와 결합: DPO에 PTS로 생성된 학습 데이터 쌍을 도입하면 최적화가 향상됩니다.
- 지표 평가: 주요 토큰에 대한 모델의 성능을 평가하여 보다 정확하게 최적화를 측정합니다.
VI. 모델 기능 및 장점
1. 뛰어난 성능
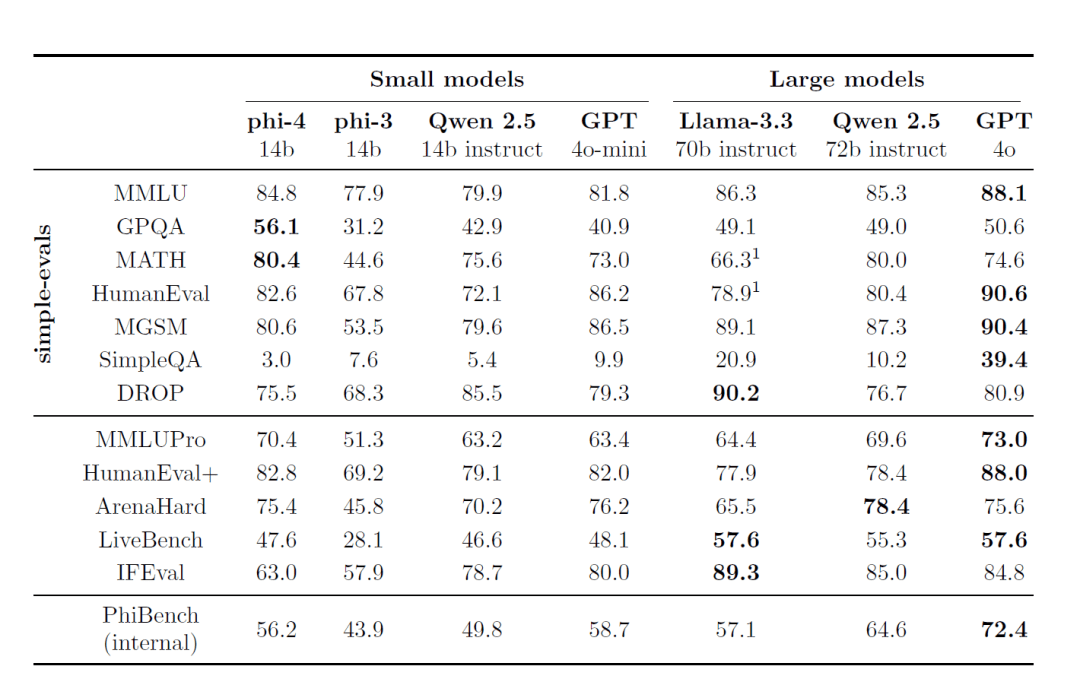
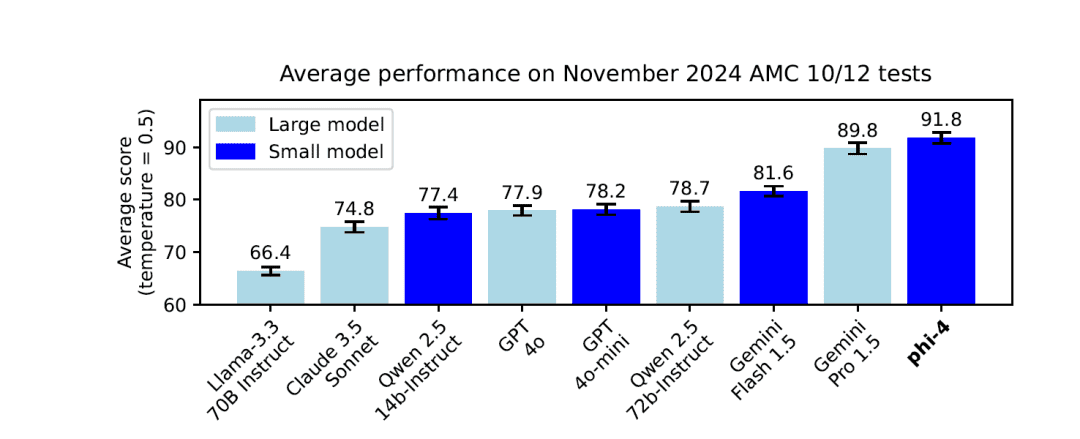
- 작은 모델, 큰 기능: 매개변수 스케일은 14B그러나 Phi-4는 여러 리뷰 벤치마크, 특히 추론 및 문제 해결 작업에서 우수한 성능을 발휘합니다.
2. 뛰어난 추론 능력
- 수학 및 과학 문제 풀이: 존재 GPQA및수학 이와 같은 벤치마크 테스트에서 Phi-4는 교사 모델보다 훨씬 우수한 점수를 받았습니다. GPT-4o.
3. 긴 컨텍스트 처리 기능
- 컨텍스트 길이 확장: 교육 도중 컨텍스트 길이를 다음과 같이 확장하여 16,000 토큰, Phi-4는 긴 텍스트와 장거리 종속성을 보다 효율적으로 처리할 수 있습니다.
4. 다국어 지원
- 다국어 지원: 학습 데이터는 다음과 같이 구성되었습니다. 독일어, 스페인어, 프랑스어, 포르투갈어, 이탈리아어, 힌디어, 일본어 및 기타 여러 언어.
- 언어 간 역량: 번역 및 다국어 퀴즈와 같은 작업에 탁월합니다.
5. 보안 및 규정 준수
- 책임감 있는 AI의 원칙: 개발 프로세스는 모델의 보안과 윤리에 초점을 맞춘 Microsoft의 책임 있는 AI 원칙을 엄격하게 따릅니다.
- 데이터 오염 제거 및 개인정보 보호: 엄격한 데이터 중복 제거 및 필터링 전략을 사용하여 민감한 콘텐츠가 학습 데이터에 포함되지 않도록 합니다.
VII. 벤치마크 및 성능
1. 외부 벤치마킹
Phi-4는 여러 공개 리뷰 벤치마크에서 최고의 성능을 입증했습니다:
- MMLU(멀티태스킹 언어 이해): 복잡한 멀티태스킹 이해력 테스트에서 우수한 결과를 얻었습니다.
- GPQA(대학원 수준의 STEM 퀴즈): 는 어려운 STEM 퀴즈에서 다른 대형 모델보다 높은 점수를 받으며 뛰어난 성적을 거두었습니다.
- MATH(수학 경시대회): 수학 문제 해결에서 Phi-4는 강력한 추론과 계산 능력을 발휘합니다.
- 휴먼에벌 / 휴먼에벌+(코드 생성): 코드 생성 및 이해 작업에서 Phi-4는 같은 규모의 모델보다 성능이 뛰어나며 심지어 더 큰 모델에 근접합니다.
2. 내부 평가 제품군(PhiBench)
모델의 기능과 단점에 대한 인사이트를 얻기 위해 팀은 전문화된 내부 평가 제품군을 개발했습니다. PhiBench::
- 다각화라는 과제: 코드 디버깅, 코드 완성, 수학적 추론 및 오류 식별을 포함합니다.
- 모델 최적화에 대한 안내입니다: 팀은 PhiBench의 결과를 분석하여 모델 개선의 목표를 설정할 수 있었습니다.
VIII. 보안 및 책임
1. 엄격한 보안 정렬 전략
Phi-4의 개발은 Microsoft의 책임감 있는 AI를 위한 원칙를 통해 훈련 및 미세 조정 중 모델의 안전과 윤리에 초점을 맞춥니다:
- 유해한 콘텐츠로부터 보호: 학습 후 단계에서 안전 미세 조정 데이터를 포함시켜 모델이 부적절한 콘텐츠를 생성할 확률을 줄입니다.
- 레드팀 테스트 및 자동화된 평가: 수십 개의 잠재적 위험 범주를 포괄하는 광범위한 레드팀 테스트와 자동화된 보안 평가가 수행되었습니다.
2. 데이터 오염 제거 및 과적합 방지
- 향상된 데이터 오염 제거 전략: 13그램과 7그램의 하이브리드 알고리즘을 사용하여 학습 데이터와 검토 벤치마크의 중복 가능성을 제거하고 모델 과적합을 방지합니다.
IX. 교육 리소스 및 시간
1. 교육 시간
공식 보고서에는 Phi-4의 총 교육 시간이 명시되어 있지 않지만, 다음 사항을 고려하세요:
- 모델 스케일: 14B 매개변수.
- 학습 데이터의 양: 트레이닝 전 단계 10T 토큰, 트레이닝 중반 250B 토큰.
전체 교육 과정에 상당한 시간이 걸렸을 것으로 추측할 수 있습니다.
2. GPU 리소스 소비
| GPU | 1920 H100-80G |
| 교육 시간 | 21일 |
| 학습 데이터 | 9.8T 토큰 |
X. 적용 및 제한 사항
1. 애플리케이션 시나리오
- Q&A 시스템: Phi-4는 복잡한 퀴즈 작업에서 뛰어난 성능을 발휘하며 모든 종류의 지능형 퀴즈 애플리케이션에 적합합니다.
- 코드 생성 및 이해: 프로그래밍 작업에 탁월하며 코드 튜터링, 자동 생성 및 디버깅과 같은 시나리오에서 사용할 수 있습니다.
- 다국어 번역 및 처리: 글로벌화된 언어 서비스를 위한 다국어 지원.
2. 잠재적 제한 사항
- 지식 차단: 모델의 지식은 학습 데이터에서 단절되며 학습 후 발생하는 이벤트에 대해서는 아무것도 알지 못할 수 있습니다.
- 긴 시퀀스 챌린지: 컨텍스트 길이가 16K로 확장되었지만 더 긴 시퀀스를 처리할 때는 여전히 문제가 있을 수 있습니다.
- 위험 관리: 엄격한 보안 조치에도 불구하고 모델은 여전히 적대적인 공격을 받거나 실수로 부적절한 콘텐츠가 생성될 수 있습니다.
Phi-4의 성공은 대규모 언어 모델 개발에서 데이터 품질과 훈련 전략이 얼마나 중요한지를 보여줍니다. 혁신적인 합성 데이터 생성 방법, 신중한 훈련 데이터 혼합 전략, 고급 훈련 기법을 통해 Phi-4는 작은 파라미터 크기를 유지하면서도 뛰어난 성능을 달성했습니다:
- 추론 능력이 뛰어납니다: 수학, 과학 및 프로그래밍 분야에서 탁월합니다.
- 긴 텍스트 처리: 확장된 컨텍스트 길이는 긴 텍스트 처리 작업에서 모델에 이점을 제공합니다.
- 안전과 책임: 책임감 있는 AI 원칙을 엄격하게 준수하여 모델이 안전하고 윤리적으로 작동하도록 보장합니다.
Phi-4는 데이터 품질과 학습 전략에 집중함으로써 작은 매개변수 규모에서도 우수한 성능을 달성할 수 있음을 보여줌으로써 소규모 매개변수 정량 모델 개발의 새로운 기준을 제시합니다.
참조: /https://www.microsoft.com/en-us/research/uploads/prod/2024/12/P4TechReport.pdf
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...