

머리말
지난 2년 동안 검색 증강 생성(RAG, Retrieval-Augmented Generation) 기술은 점차 향상된 지능의 핵심 구성 요소로 자리 잡았습니다. 검색과 생성의 두 가지 기능을 결합한 RAG는 외부 지식을 도입할 수 있어 복잡한 시나리오에서 대규모 모델을 적용할 수 있는 더 많은 가능성을 제공합니다. 그러나 실제 착륙 시나리오에서는 낮은 검색 정확도, 노이즈 간섭, 리콜 무결성, 불충분한 전문성 등의 문제가 종종 발생하여 심각한 LLM 착시 현상을 초래합니다. 이 백서에서는 실제 착륙 시나리오에서 RAG의 지식 처리 및 검색 세부 사항, RAG 핀라인 링크를 최적화하는 방법, 궁극적으로 리콜 정확도를 개선하는 방법에 초점을 맞추고자 합니다.
RAG 스마트 Q&A 앱을 빠르게 구축하는 것은 쉽지만 실제 비즈니스 시나리오에 적용하려면 많은 준비가 필요합니다.
1.RAG 주요 프로세스 소스 코드 해석
센터지식 처리노래로 응답RAG주요 프로세스 중 일부입니다:
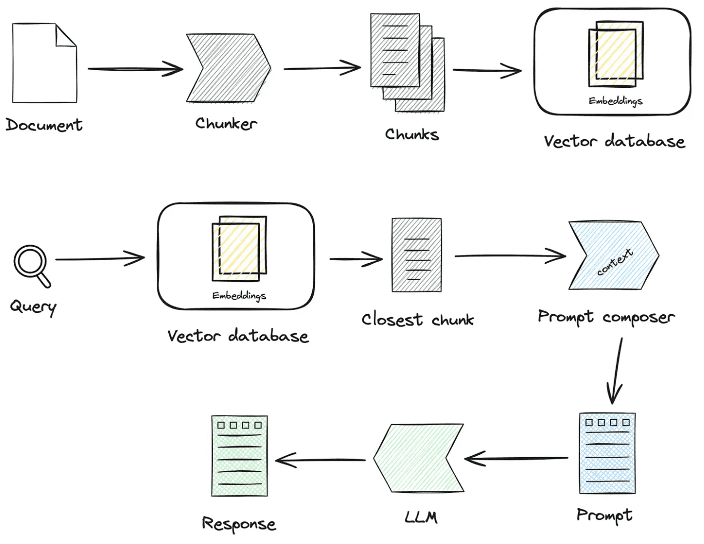
1. 지식 처리
지식 로딩 -> 지식 슬라이싱 -> 정보 추출 -> 지식 처리(임베딩/그래프/키워드) -> 지식 저장
- 지식 로딩
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
확장하는 방법:
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- 지식 슬라이스
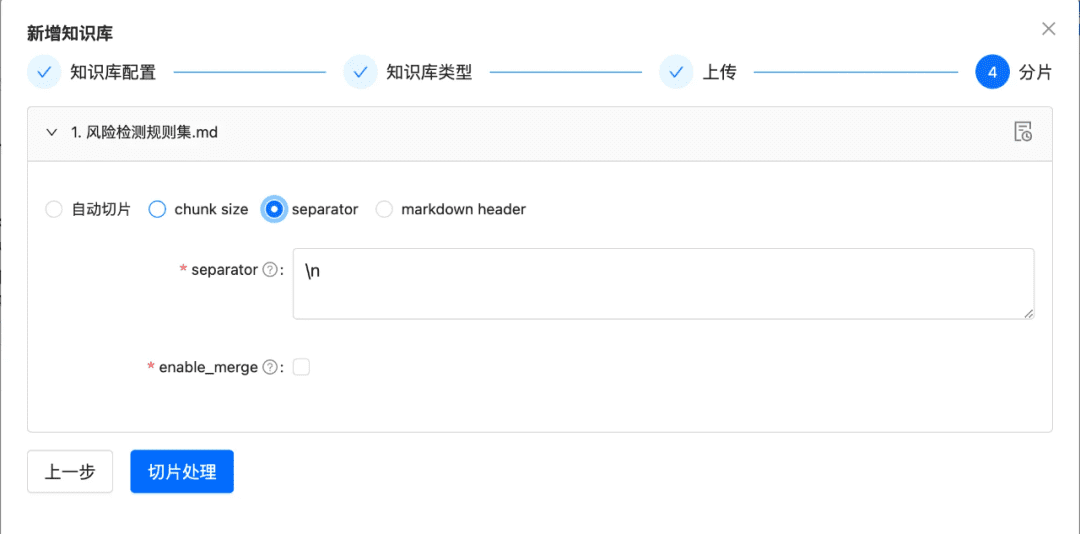
청크 관리자: 로드된 지식 데이터를 사용자가 지정한 청크 정책 및 청크 매개변수에 따라 할당할 수 있도록 해당 청크 프로세서로 라우팅합니다.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
확장 방법: 인터페이스에서 새로운 슬라이싱 전략을 사용자 지정하려는 경우
- 새로운 슬라이싱 전략
- 새로운 스플리터 구현 로직
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- 지식 추출
- 벡터 추출 -> 임베딩, 구현
Embeddings커넥터
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- 지식 그래프 추출 -> 지식 그래프
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- 역 인덱스 추출 -> 키워드 세분화
- es 기본 어휘집을 사용하거나 es 플러그인 모드를 사용하여 어휘집을 사용자 지정할 수 있습니다.
- 역 인덱스 추출 -> 키워드 세분화
- 지식 저장소
전체 지식 지속성이 균일하게 달성됩니다.IndexStoreBase인터페이스는 현재 벡터 데이터베이스, 그래프 데이터베이스, 전체 텍스트 인덱싱의 세 가지 유형의 구현을 제공합니다.

- 인덱스 스키마 생성, 벡터 데이터 일괄 쓰기 등을 포함한 벡터 데이터베이스의 주요 로직은 load_document()에 있습니다.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- 특정 그래프 저장소는 일반적으로 특정 그래프 데이터베이스의 쿼리 언어를 호출하여 수행되는 삼항식 쓰기 구현을 제공합니다. 예를 들어
TuGraphStore특정 사이퍼 문은 트리플을 기반으로 생성 및 실행됩니다.
- 그래프 저장소 인터페이스 GraphStoreBase는 그래프 저장소를 위한 통합 추상화를 제공하며 현재 내장된
MemoryGraphStore노래로 응답TuGraphStore구현을 위해 개발자가 액세스할 수 있도록 Neo4j 인터페이스도 제공합니다.
- 그래프 저장소 인터페이스 GraphStoreBase는 그래프 저장소를 위한 통합 추상화를 제공하며 현재 내장된
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- 풀텍스트스토어: 단어 분할을 위해 es에 내장된 단어 분할 알고리즘을 통해 es 인덱스를 구축한 다음, 키워드->doc_id 반전 인덱스를 구축하기 위해 es를 사용합니다.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. 지식 검색
질문 -> 재작성 -> 유사도_검색 -> 재순위 -> 컨텍스트_후보자
다음은 지식 검색이며, 현재 커뮤니티 검색 로직은 주로 이러한 단계로 나뉘며, 쿼리 재 작성 매개 변수를 설정하면 현재 빅 모델을 통해 질문 재 작성 라운드를 제공 한 다음 지식 처리 방식에 따라 해당 리트리버로 라우팅되고, 벡터를 통해 처리되는 경우 EmbeddingRetriever를 통해 검색되고, 빌드 방식이면 를 통해 구축한 경우 지식 그래프 방식에 따라 검색되며, 재랭크 모델을 설정한 경우 거친 선별 후 후보 값에 대해 사용자의 질문과 연관성이 높은 후보 값으로 만들기 위한 미세 선별을 거치게 됩니다.
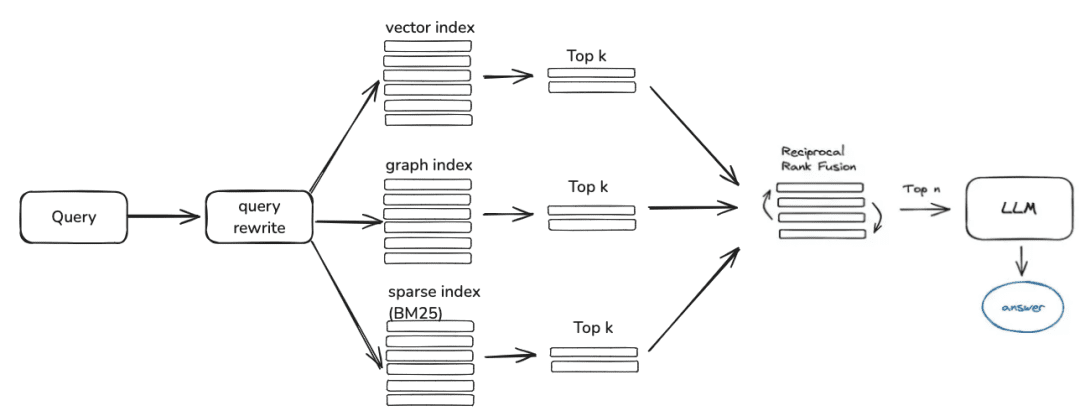
- 임베딩 리트리버
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store: 특정 벡터 데이터베이스
- top_k: 반환된 특정 후보 청크의 수
- 쿼리 재작성: 쿼리 재작성 함수
- 재순위: 재정렬 기능
- 쿼리:원본 쿼리
- score_threshold: 점수, 기본적으로 유사도 점수가 임계값보다 낮은 컨텍스트를 필터링합니다.
- 필터:
Optional[MetadataFilters]메타데이터 정보 필터는 주로 속성 정보를 통해 일부 불일치 후보 정보를 걸러내는 데 사용할 수 있습니다.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- 그래프 RAG
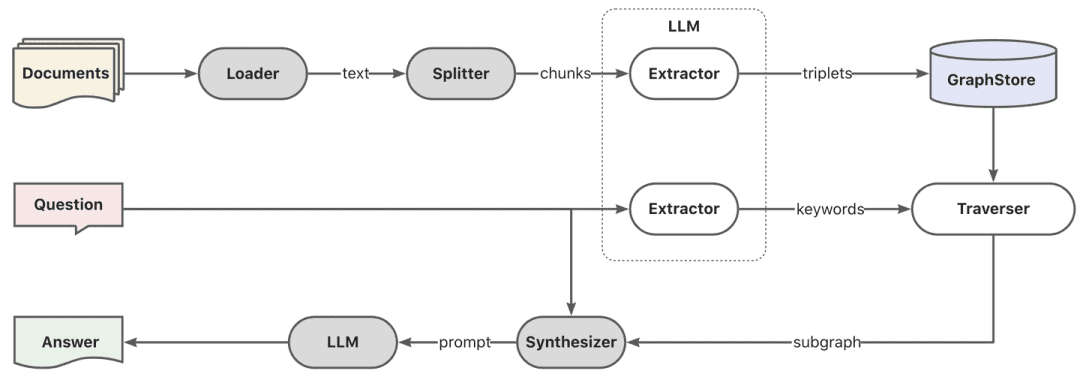
먼저 모델을 통해 키워드 추출을 수행하는데, 여기서 단어 분할은 전통적인 NLP 기법을 통해 수행하거나 빅 모델을 통해 단어 분할을 수행한 다음 키워드를 동의어에 따라 확장하여 키워드 후보 목록을 찾고, 키워드 후보 목록에 따라 로컬 하위 그래프를 불러오는 탐색 방법을 호출하는 것이 좋습니다.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetriever이것은 부분적으로 ChatData 시나리오에 대한 스키마 연결 검색입니다.주로 2단계 유사도 검색을 통한 스키마 연결 방식을 통해 가장 관련성이 높은 테이블을 먼저 찾은 다음 가장 관련성이 높은 필드 정보를 찾습니다.
장점: 이 2단계 검색은 대형 와이드 테이블 환경에 대한 커뮤니티 피드백을 해결하기 위해 고안되었습니다.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- 테이블_벡터_스토어_커넥터: 가장 관련성이 높은 테이블을 검색하는 역할을 담당합니다.
- 필드_벡터_스토어_커넥터: 가장 관련성이 높은 필드 검색을 담당합니다.
2. 지식 처리, 지식 검색 최적화 아이디어
현재 RAG 스마트 퀴즈 앱에는 몇 가지 문제점이 있습니다:
- 지식창고에 문서가 점점 더 많아지면 검색이 노이즈가 심하고 리콜 정확도가 높지 않습니다.
- 불완전한 리콜 및 완전성 부족
- 리콜과 사용자 질문 의도는 거의 관련이 없습니다.
- 정적 데이터에만 답변할 수 있고 동적으로 지식에 액세스할 수 없다면, 답변 애플리케이션은 둔하고 멍청한 결과를 초래합니다.
1. 지식 처리 최적화
비정형/반정형/정형 데이터의 처리는 RAG 적용의 상한선을 결정할 준비가 되어 있으므로 우선 지식 처리, 색인화 단계와 아이디어 방향의 주요 최적화를 위한 세밀한 ETL 작업을 많이 해야 합니다:
- 비구조화 -> 구조화: 지식 정보를 구조화된 방식으로 정리합니다.
- 더 풍부하고 다양한 시맨틱 정보를 추출하세요.
1.1 지식 로드
목적: 다양한 유형의 데이터를 보다 다양한 방식으로 식별하려면 정확한 문서 구문 분석이 필요합니다.
최적화 권장 사항:
- 일부 인식 도구를 사용하여 텍스트의 내용을 더 잘 추출할 수 있도록 PDF 또는 마크다운 형식으로 처리하기 전에 docx, txt 또는 기타 텍스트를 먼저 처리하는 것이 좋습니다.
- 텍스트에서 테이블 정보를 추출합니다.
- 다음 계층 관계 트리 및 기타 색인 방법을 준비하기 위해 마크다운 및 PDF 제목 계층 구조 정보를 보존합니다.
- 이미지 링크, 수식 및 기타 정보도 마크다운 형식으로 균일하게 처리하여 유지합니다.
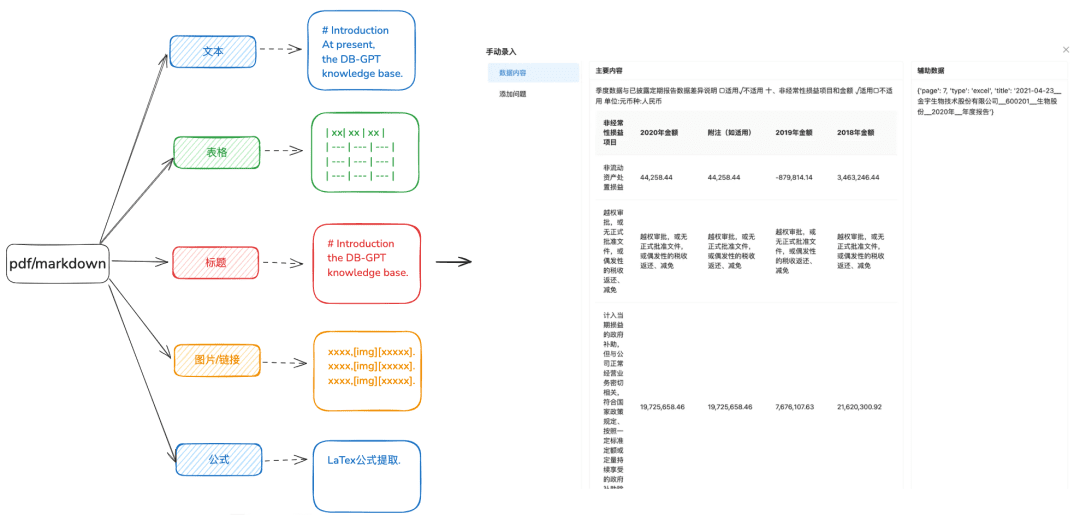
1.2 청크를 최대한 온전하게 슬라이스하기
목적: 응답 정확도와 직결되는 문맥 무결성 및 관련성을 유지하기 위한 것입니다.
청킹은 더 큰 모델의 문맥적 한계를 유지하면서 LLM에 입력되는 텍스트가 토큰 한도를 초과하지 않도록 보장합니다.
최적화 권장 사항:
- 이미지 + 테이블을 별도의 청크로 추출하여 메타데이터 메타데이터에 테이블 및 이미지 캡션 유지
- 문서 콘텐츠는 헤더 계층 구조 또는 마크다운 헤더에 따라 가능한 한 많이 분할되어 청크의 무결성을 최대한 유지합니다.
- 사용자 지정 구분 기호가 있는 경우 사용자 지정 구분 기호에 따라 분할할 수 있습니다.
1.3 다양한 정보 추출
문서의 벡터 추출을 임베딩하는 것 외에도 다른 다양한 정보 추출을 통해 문서의 데이터를 향상시키고 RAG 리콜 효과를 크게 향상시킬 수 있습니다.
- 지식 지도
- 장점: 1. NativeRAG의 완전성 부족을 해결하고, 여전히 착각의 문제가 있으며, 지식 경계의 완전성, 지식 구조 및 의미의 명확성을 포함한 지식의 정확성은 유사성 검색 기능의 의미론적 보완입니다.
- 시나리오: 지식의 준비에 제약이 필요하고 지식 간의 계층적 관계를 명확하게 설정할 수 있는 엄격한 전문 영역(의료, O&M 등)의 경우.
- 달성 방법:
1. 빅 모델에 따라 (엔티티, 관계, 엔티티) 삼원 관계를 추출합니다.
2. 지식 그래프를 구축하기 위해 수동 또는 사용자 지정 SOP 프로세스에 따른 비즈니스 규칙을 통해 사전 품질의 구조화된 지식 준비, 정리, 추출에 의존합니다.
- 문서 트리
- 적용 가능한 시나리오: 문맥 무결성 부족 문제를 해결하고 의미론과 키워드만을 기반으로 일치시키며 노이즈를 줄일 수 있습니다.
- 달성 방법: 제목 수준에서 청크의 트리 노드를 구축하여 다항식 트리 구조를 형성하고, 각 수준 노드는 문서 제목만 저장하고 리프 노드는 특정 텍스트 콘텐츠만 저장하면 됩니다. 이러한 방식으로 트리 탐색 알고리즘을 사용하면 사용자 질문이 관련 리프가 아닌 제목 노드에 닿으면 관련 하위 노드 데이터를 불러올 수 있습니다. 이렇게 하면 청크 무결성 결여 문제가 발생하지 않습니다.
이 기능은 내년 초에 커뮤니티에도 추가할 예정입니다.
- QA 쌍을 추출하려면 미리 정의된 방법 또는 모델 추출 방법을 통해 QA 쌍 정보를 프런트엔드에서 추출해야 합니다.
- 적용 가능한 시나리오:
- 검색에서 질문을 치고 사용자가 원하는 답변을 직접 불러오는 기능, 일부 FAQ 시나리오에 적용 가능한 무결성 리콜 기능만으로는 충분한 시나리오가 아닙니다.
- 달성 방법:
- 미리 정의: 각 청크에 대해 미리 몇 가지 질문을 추가합니다.
- 모델 추출: 컨텍스트가 주어지면 모델이 QA 쌍 추출을 수행하도록 합니다.
- 메타데이터 추출
- 달성 방법: 자체 비즈니스 데이터의 특성에 따라 태그, 카테고리, 시간, 버전 및 기타 메타데이터 속성과 같은 보존 대상 데이터의 특성을 추출합니다.
- 적용 가능한 시나리오: 메타데이터 속성을 기반으로 검색을 사전 필터링하여 대부분의 노이즈를 걸러낼 수 있습니다.
- 요약 및 추출
- 적용 가능한 시나리오: 해결 방법
这篇文章讲了个啥(수학.) 속总结一下및 기타 글로벌 문제 시나리오. - 구현 방법: 맵리듀스 등을 통해 세그먼트 추출, 모델을 통해 각 청크의 요약 정보를 추출합니다.
- 적용 가능한 시나리오: 해결 방법
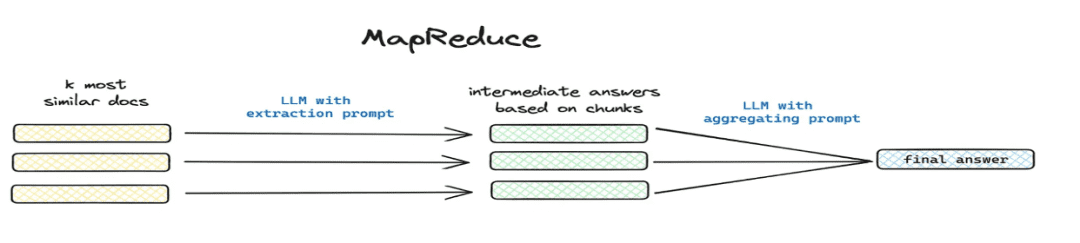
1.4 지식 처리 워크플로
현재 시점 DB-GPT 지식베이스는 문서 업로드 -> 파싱 -> 슬라이싱 -> 임베딩 -> 지식 그래프 트라이어드 추출 -> 벡터 데이터베이스 저장 -> 그래프 데이터베이스 저장 등의 지식 처리 기능을 제공하지만, 문서에서 복잡하고 개인화된 정보를 추출하는 기능은 없기 때문에 지식 처리 워크플로우 템플릿을 구축하여 복잡하고 시각적인 사용자 정의 지식 추출, 변환 및 처리 프로세스를 완성하고자 합니다. 따라서 지식 처리 워크플로우 템플릿을 구축하여 복잡하고 시각적이며 사용자 정의 가능한 지식 추출, 변환, 처리 프로세스를 완료할 수 있기를 바랍니다.
지식 처리 워크플로:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. RAG 프로세스 최적화 RAG 프로세스 최적화 우리는 정적 문서 RAG와 동적 데이터 획득 RAG로 세분화되며, 현재 관련된 대부분의 RAG는 비정형 문서 정적 자산 만 다루지 만, Q&A의 많은 시나리오의 실제 비즈니스는 도구를 통해 동적 데이터 + 정적 지식 데이터를 함께 획득하여 시나리오에 답해야하며 정적 지식을 검색해야 할뿐만 아니라 RAG가되어야합니다. 도구 자산 라이브러리에서 도구의 정보를 검색하고 동적 데이터 수집을 실행해야합니다.
2.1 정적 지식 RAG 최적화
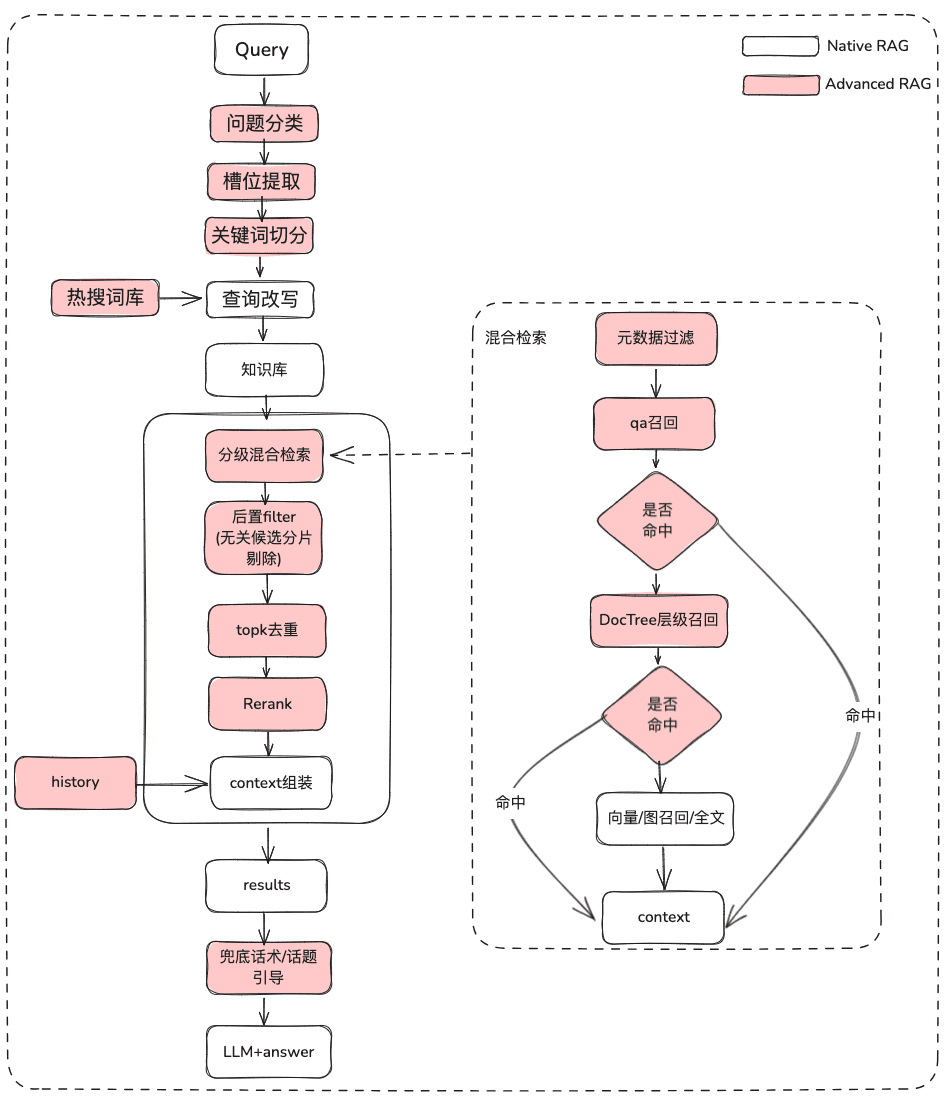
(1) 원래 문제의 치료
목적: 사용자 의미를 명확히 하고 사용자의 원래 질문을 모호하고 의도가 불분명한 쿼리에서 보다 풍부한 의미를 가진 검색 가능한 쿼리로 최적화합니다.
- 원시 문제 분류, 다음과 같은 문제가 있을 수 있습니다.
- LLM 분류(
LLMExtractor) - 임베딩 + 로지스틱 회귀를 구축하여 투타워 모델 구현, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md에서 메인 - eosphoros-ai/DB-GPT-Hub 구현
- LLM 분류(
- 팁: 고품질 임베딩 모델 필요, bge-v1.5-large 권장
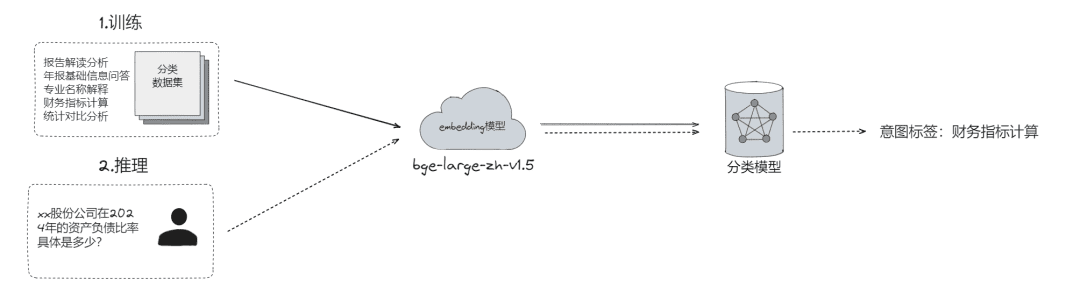
- 사용자에게 다시 질문하고, 의미가 명확하지 않은 경우 여러 차례의 상호 작용을 통해 사용자에게 질문을 다시 던져 질문을 명확히 합니다.
- 검색 가능한 동의어 사전을 사용하여 의미적 관련성을 기반으로 사용자에게 질문의 후보 목록을 제안합니다.
- 슬롯 추출: 의도, 비즈니스 속성 등과 같은 사용자 질문의 주요 슬롯 정보를 얻는 것을 목표로 합니다.
- LLM 추출(
LLMExtractor)
- LLM 추출(
- 질문 다시 작성하기
- 인기 검색어 사전 다시 쓰기
- 다층적 상호 작용
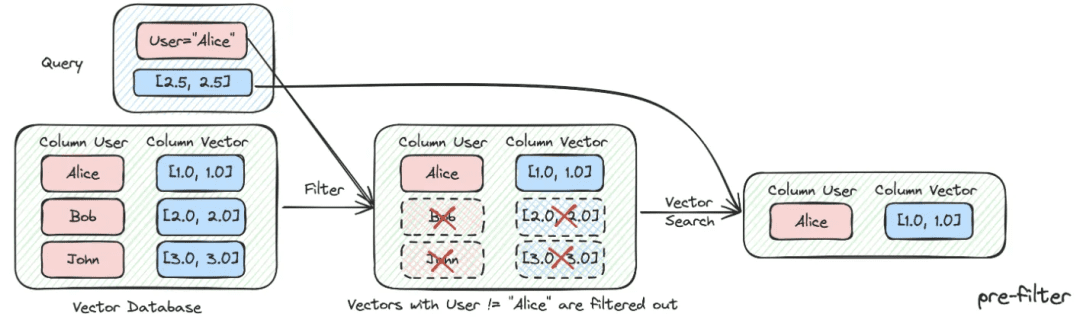
(2) 메타데이터 필터링
색인을 여러 덩어리로 나누고 동일한 지식 공간에 저장하면 검색 효율성이 문제가 될 수 있습니다. 예를 들어 사용자가 '절강 이우 기술 회사'에 대한 정보를 요청할 때 다른 회사에 대한 정보는 기억하고 싶지 않을 것입니다. 따라서 회사명 메타데이터 속성으로 먼저 필터링할 수 있다면 효율성과 관련성이 크게 향상될 것입니다.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
(3) 다중 전략 하이브리드 리콜
- 우선순위 리콜에 따라 다양한 검색기의 우선순위를 정의하고, 검색되는 즉시 콘텐츠를 반환합니다.
- 큐에 기록할 qa_retriever, doc_tree_retriever와 같은 다양한 검색을 정의하고 큐의 선입선출 속성을 통해 우선순위 호출을 달성하세요.
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
- 다중 지식 인덱싱/공간 병렬 리콜
- 리콜의 완전성을 보장하기 위해 다양한 인덱싱 형태의 지식을 통해 병렬 리콜을 통해 후보 목록을 가져옵니다.
(4) 사후 필터링
거친 선별 후보자 목록을 검토한 후 미세 선별을 통해 노이즈를 어떻게 걸러내나요?
- 관련 없는 후보 슬라이스 컬링
- 적시성 거부
- 비즈니스 속성은 컬링을 만족시키지 못합니다.
- TOPK 중복 제거
- 재순서화 거친 선별의 리콜에 의존하는 것만으로는 충분하지 않으며, 이때 검색된 결과를 재순서화하기 위해 조합 관련성, 매칭 등과 같은 요소를 재조정하여 비즈니스 시나리오에 더 부합하는 순서를 얻기위한 몇 가지 전략이 필요합니다. 이 단계가 끝나면 최종 처리를 위해 LLM으로 결과를 보내게 되므로 이 부분의 결과가 매우 중요합니다.
- 오픈 소스 모델 또는 비즈니스 시맨틱 미세 조정이 적용된 모델 중 관련 재정렬 모델을 사용하여 미세 스크리닝합니다.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- 다양한 인덱싱된 리콜을 기반으로 한 비즈니스 RRF 가중치 종합 점수 컬링
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
(5) 디스플레이 최적화 + 홍보/토픽 리더십
- 마크다운 서식을 사용하여 모델 출력하기
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 동적 지식 RAG 최적화
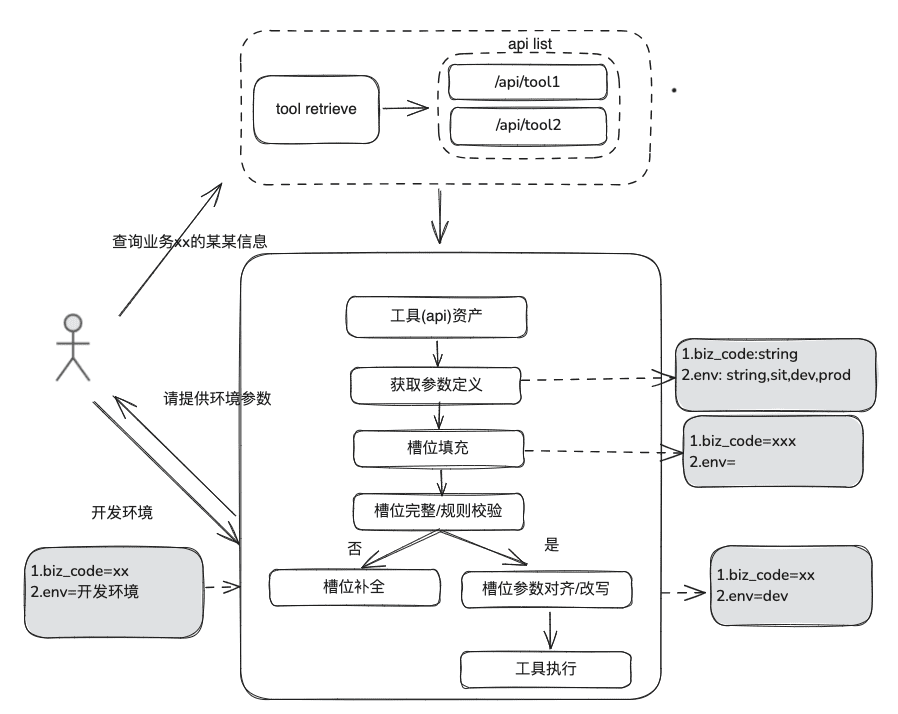
문서화 지식은 상대적으로 정적이며 개인화되고 동적 인 정보에 답할 수 없으며 일부 타사 플랫폼 도구에 의존하여 답변해야하며 이러한 상황에 따라 도구 자산 정의-> 도구 선택-> 도구 유효성 검사-> 도구 실행을 통해 동적 데이터를 얻기 위해 일부 동적 RAG 방법이 필요합니다.
(1) 도구 에셋 라이브러리
엔터프라이즈 도메인 도구 자산 라이브러리를 구축하여 다양한 플랫폼에 흩어져 있는 도구 API, 도구 스크립트를 통합함으로써 인텔리전스를 위한 엔드투엔드 사용 기능을 제공할 수 있습니다. 예를 들어 정적 지식창고 외에도 도구 라이브러리를 가져와서 도구를 처리할 수 있습니다.

(2) 도구 리콜
도구 리콜은 정적 지식에 대한 RAG 리콜의 개념을 따르며, 전체 도구 실행 라이프사이클을 사용하여 도구 실행 결과를 얻습니다.
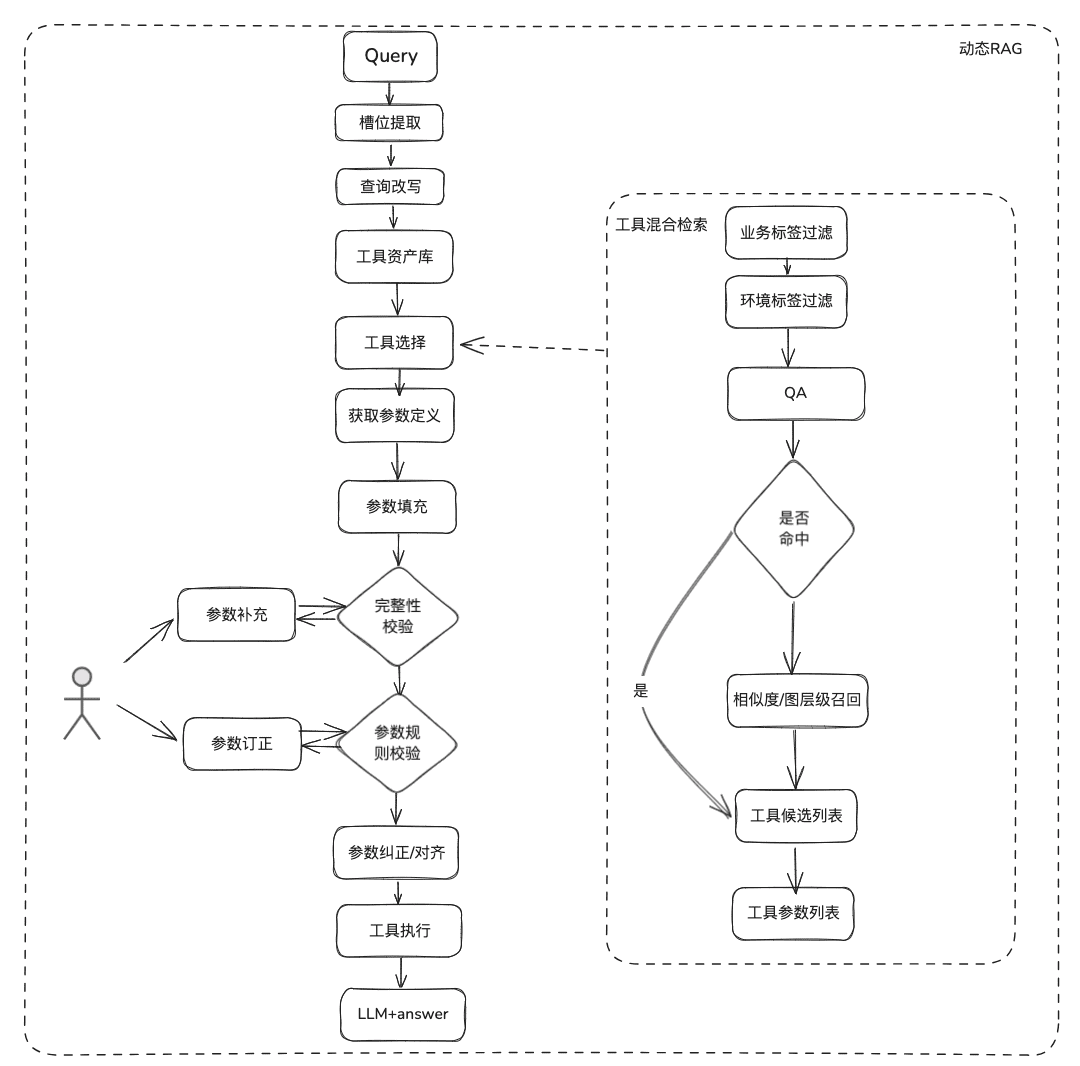
- 슬롯 추출: 일반적인 비즈니스 유형, 환경 마커, 도메인 모델 매개변수 등을 포함하여 사용자의 문제를 구문 분석하기 위해 기존 nlp를 통해 LLM을 가져옵니다.
- 도구 선택: 도구 이름 불러오기와 도구 매개변수 불러오기라는 두 가지 주요 레이어로 정적 RAG 라인을 따라 불러오기.
- 도구 매개변수 호출은 TableRAG 아이디어와 유사하게 테이블 이름을 먼저 호출한 다음 필드 이름을 호출합니다.
- 매개변수 채우기: 리콜의 도구 매개변수 정의에 따라 슬롯에서 추출한 매개변수를 일치시켜야 합니다.
- 코딩하여 채우거나 모델이 채우도록 할 수 있습니다.
- 최적화 아이디어: 다양한 플랫폼 도구의 동일한 파라미터의 파라미터 이름이 통일되어 있지 않고 거버넌스로 이동하는 것이 편리하지 않으므로 도메인 모델 데이터 확장을 먼저 수행하고 전체 도메인 모델을 가져온 후 필요한 파라미터가 존재할 수 있도록 제안합니다.
- 매개변수 보정
- 무결성 검사: 매개변수 수에 대한 무결성 검사를 수행합니다.
- 매개변수 규칙 검사: 매개변수 이름 유형, 매개변수 값, 열거형 등에 대한 규칙 검사를 수행합니다.
- 매개변수 수정/정렬, 이 부분은 주로 사용자와의 상호작용 횟수를 줄이고 대소문자 규칙, 열거 규칙 등을 포함한 사용자 매개변수 오류 수정의 자동 완성을 위한 것입니다.
2.3 RAG 검토
스마트 Q&A 프로세스를 평가할 때는 리콜 관련성 정확도와 모델 Q&A 관련성을 별도로 평가한 다음 함께 고려하여 RAG 프로세스에서 여전히 개선이 필요한 부분을 결정해야 합니다.
지표 평가:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric:RetrieverHitRateMetric:: 적중률은 RAG를 측정합니다.retriever검색된 결과 중 상위 k개 문서에 나타나는 리콜의 비율입니다.RetrieverMRRMetric:Mean Reciprocal Rank각 쿼리의 정확도는 검색 결과에서 가장 관련성이 높은 문서의 순위를 분석하여 계산됩니다. 더 구체적으로 말하면, 모든 쿼리에 대한 관련 문서의 역순위를 평균한 값입니다. 예를 들어 가장 관련성이 높은 문서가 1순위인 경우 그 문서의 역순위는 1, 2순위인 경우 1/2 등입니다.RetrieverSimilarityMetric유사성 메트릭은 불러온 콘텐츠와 예측된 콘텐츠 간의 유사성을 계산하기 위해 계산됩니다.
模型生成응답 표시기.
AnswerRelevancyMetric:: 지능형 본문 답변 관련성 메트릭은 지능형 본문 답변이 사용자의 질문과 얼마나 잘 일치하는지를 기준으로 합니다. 관련성 높은 답변을 위해서는 모델이 사용자의 질문을 이해해야 할 뿐만 아니라 질문과 밀접한 관련이 있는 답변을 생성해야 합니다. 이는 사용자 만족도와 모델의 유용성에 직접적인 영향을 미칩니다.
3.RAG 랜딩 사례 공유
1. 데이터 인프라 영역의 RAG
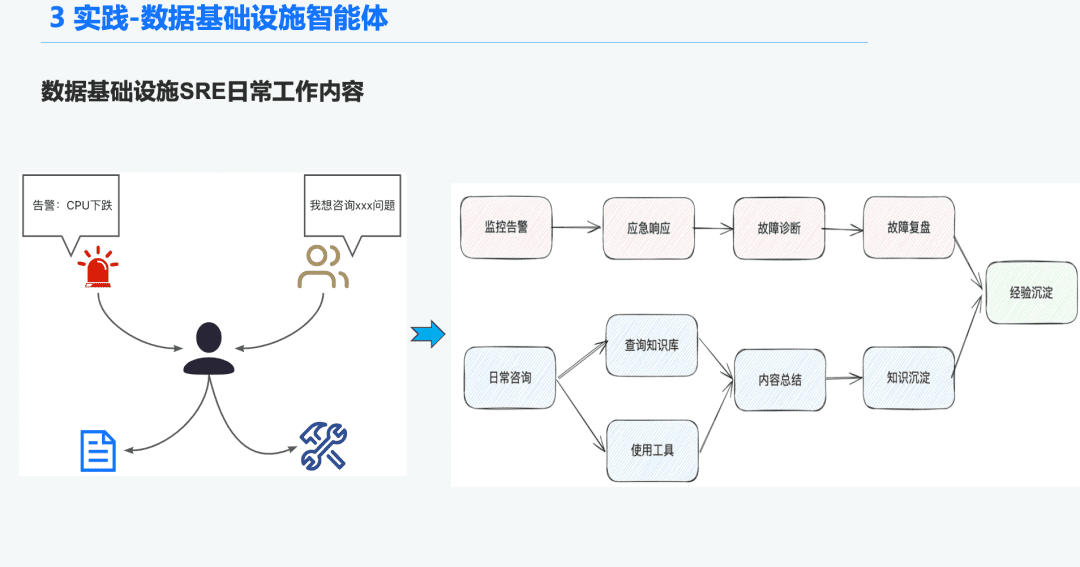
1.1 O&M 인텔리전스 기관 배경
데이터 인프라 영역에서는 매일 수많은 알림을 수신하는 운영 SRE가 많기 때문에 긴급 상황에 대응하는 데 많은 시간이 소요되고, 이는 다시 문제 해결로 이어지고, 문제 해결 검토로 이어지며, 이는 다시 경험으로 이어집니다. 또 다른 시간의 일부는 사용자 문의에 응답하는 데 사용되므로 도구 사용에 대한 지식과 경험을 바탕으로 질문에 답변해야 합니다.
따라서 데이터 인프라에 대한 일반 인텔리전스를 만들어 이러한 경보 진단 및 질문에 대한 답변 문제를 해결하고자 합니다.
1.2 엄격하고 전문적인 RAG
기존의 RAG + 에이전트 기술은 범용적이고 덜 결정론적인 단일 단계 작업 시나리오를 해결할 수 있습니다. 그러나 데이터 인프라 분야의 전문적인 시나리오에 직면할 때는 전체 검색 프로세스가 결정론적이고 전문적이며 현실적이어야 하며 단계별 추론이 필요합니다.
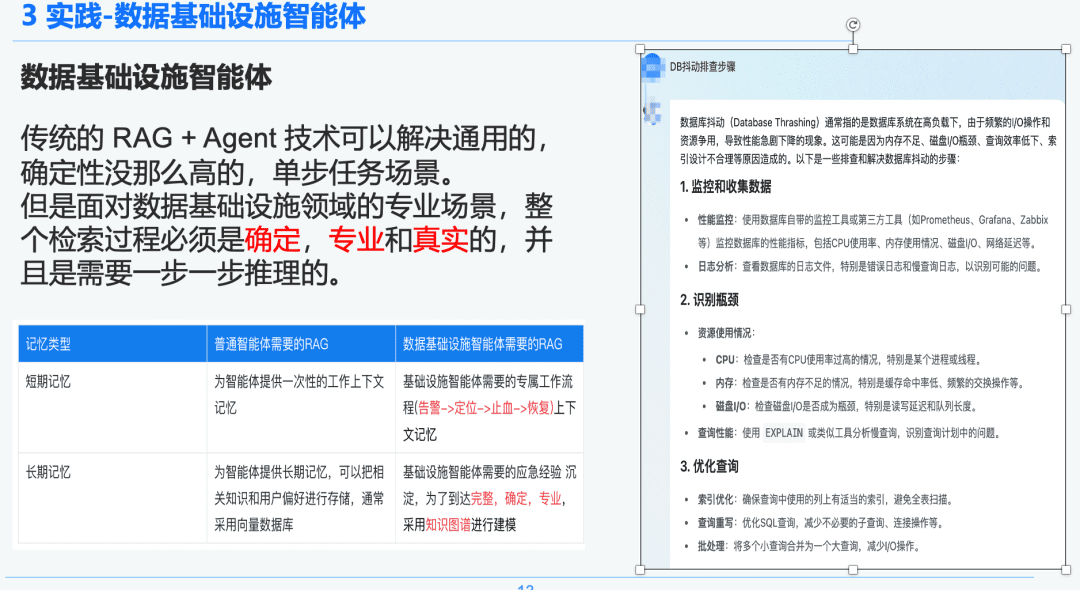
오른쪽은 NativeRAG를 통한 일반화된 요약으로, 도메인 지식이 많지 않은 최고 경영진 사용자에게는 유용한 정보가 될 수 있지만 전문가에게는 이 부분이 큰 의미가 없을 수 있습니다.
따라서 RAG를 통해 일반 인텔리전스와 데이터 인프라 인텔리전스의 차이를 비교합니다:
- 범용 인텔리전스: 기존의 RAG는 지적 엄격성과 전문성이 크게 필요하지 않으며 고객 서비스, 관광, 플랫폼 Q&A 봇 등 일부 비즈니스 시나리오에 적합합니다.
- 데이터 인프라 인텔리전스 바디: RAG 프로세스는 엄격하고 전문적이며, 전문가가 계층적 관계를 설정하기 위해 Q&A 및 긴급 대응 경험을 구조적으로 추출하고 (경고 -> 위치 찾기 -> 출혈 중지 -> 복구) 컨텍스트가 포함된 전용 RAG 워크플로우를 필요로 합니다. 따라서 지식 그래프를 데이터 전달자로 선택합니다.
1.3 지식 처리
데이터 인프라의 결정론과 특이성을 기반으로 지식 그래프를 결합하여 긴급 대응 경험을 진단하는 지식 전달자로 사용하기로 결정했습니다. SRE에 의해 촉발된 긴급 문제 해결 이벤트에 대한 지식 경험을 긴급 검토 프로세스와 결합하여 DB 긴급 이벤트 중심 지식 그래프를 구축하고, DB 지터를 예로 들어 느린 SQL 문제, 용량 문제 등 DB 지터에 영향을 미치는 여러 이벤트를 예로 들어 각 긴급 이벤트 간의 관계를 설정했습니다.
마지막으로, 여러 소스의 지식 -> 지식 구조화 추출 -> 긴급 관계 추출 -> 전문가 검토 -> 지식 저장이라는 단계별 긴급 이벤트 규칙을 표준화하여 표준화된 지식 처리 시스템을 구축했습니다.

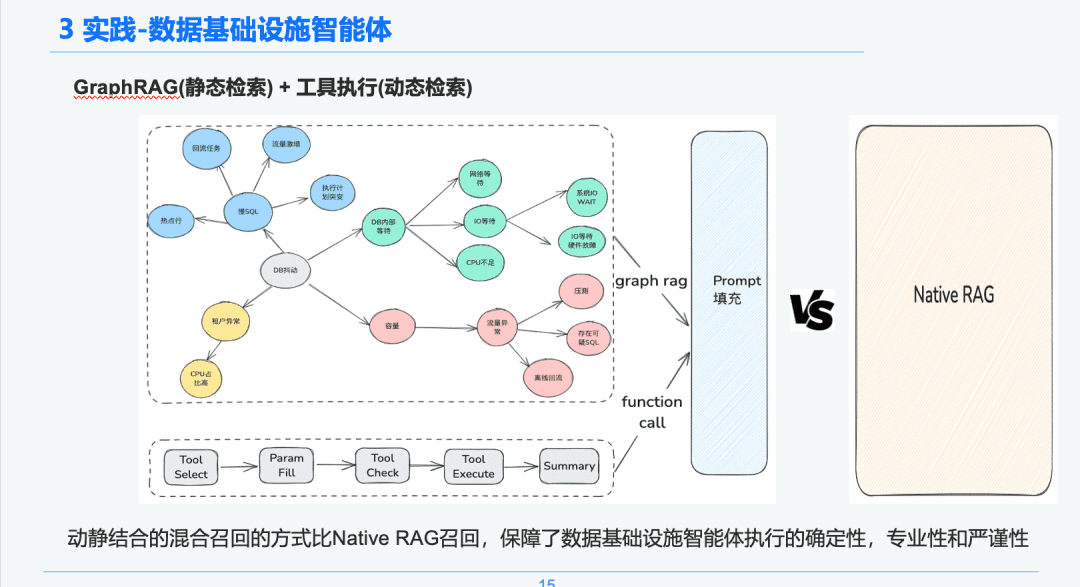
1.4 지식 검색
지능형 본문 검색 단계에서는 정적 지식 검색의 전달자로 GraphRAG를 사용하므로 DB 지터 이상 징후를 식별한 후 각 노드가 지식 추출 단계에서 이벤트 이름, 이벤트 설명, 관련 도구, 도구 매개 변수 등 각 이벤트에 대한 메타데이터 정보도 일부 보유하고 있으므로 DB 지터 이상 징후 노드와 관련된 노드를 분석의 기초로 찾습니다.
따라서 실행 도구의 실행 라이프사이클 링크를 통해 리턴 결과를 얻어 문제 해결을 위한 긴급 진단의 기초로 사용할 동적 데이터를 확보할 수 있습니다. 이러한 동적 및 정적 하이브리드 리콜 접근 방식을 통해 순수하고 단순한 RAG 리콜보다 데이터 인프라 인텔리전스 실행의 확실성, 전문성 및 엄격성이 보장됩니다.
1.5 AWEL + 에이전트
마지막으로 커뮤니티 AWEL+AGENT 기술을 통해 에이전트 오케스트레이션의 패러다임을 사용하여 인텐트 -> 긴급 진단 전문가 -> 진단 근본 원인 분석 전문가로 이어지는 전문가를 만들었습니다.
인텐트 전문가는 사용자의 인텐트를 식별 및 파싱하고 알림 메시지를 식별하는 역할을 담당하며, 진단 전문가는 GraphRAG를 통해 분석할 근본 원인 노드를 찾아 구체적인 근본 원인 정보를 얻어야 합니다. 분석 전문가는 각 근본 원인 노드의 데이터와 과거 분석 검토 보고서를 결합하여 진단 분석 보고서를 생성해야 합니다.
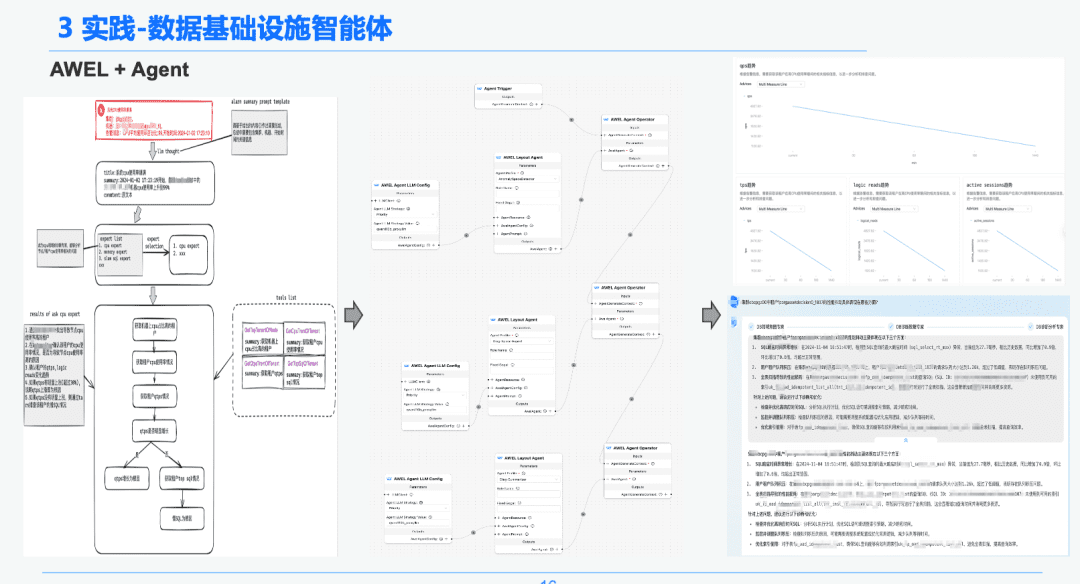
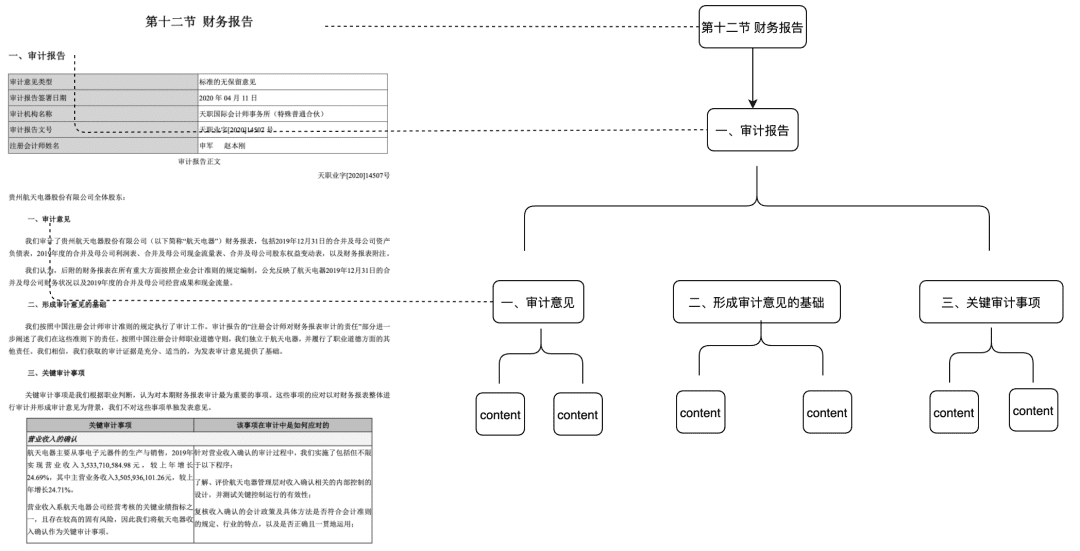
2. 재무 보고 분석 분야의 RAG
최신 실습! DB-GPT를 기반으로 재무 보고서 분석 도우미를 구축하는 방법은 무엇인가요?
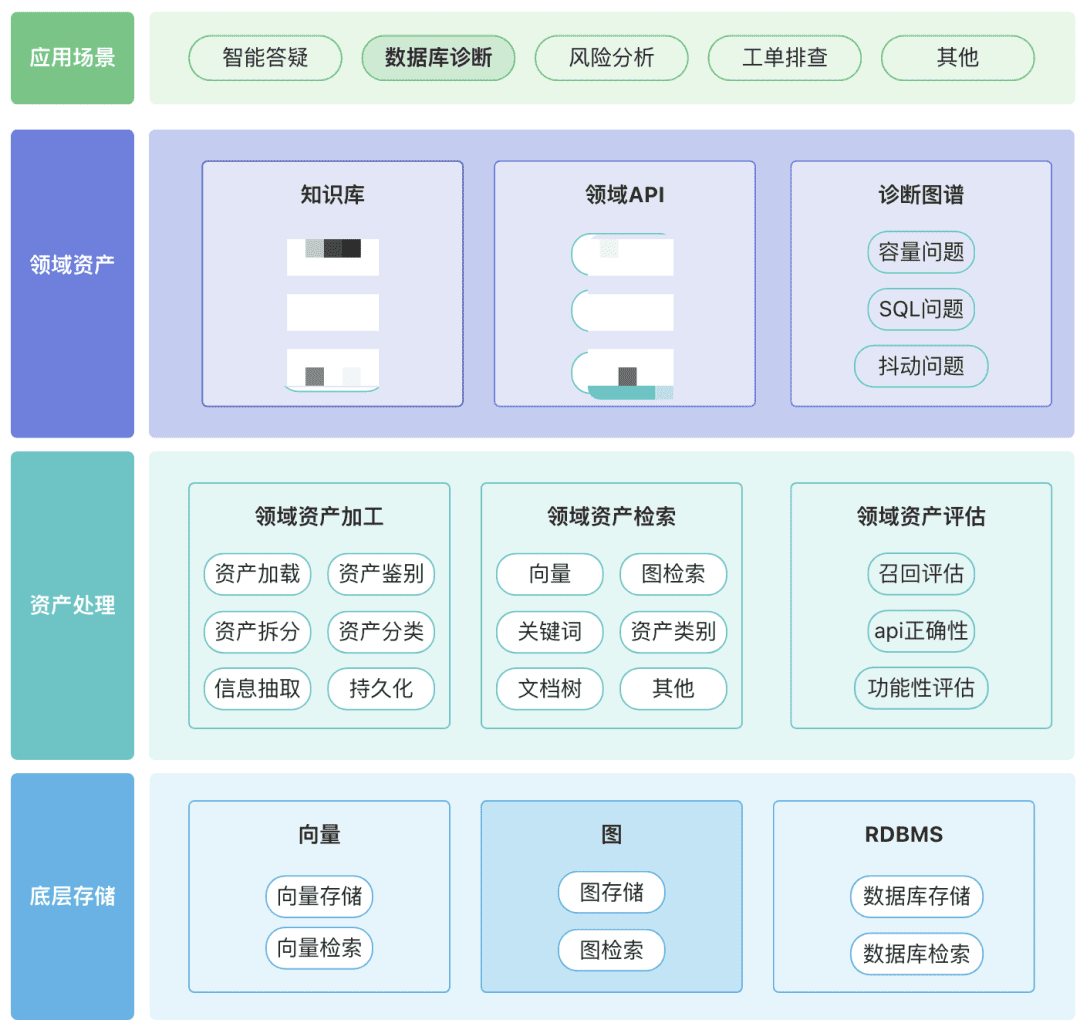
도메인에 지식 자산, 도구 자산 및 지식 그래프 자산을 포함한 도메인 자산의 자체 리포지토리를 구축할 수 있습니다.
- 도메인 자산: 도메인 자산에는 지식창고, API 및 도구 스크립트가 포함됩니다.
- 자산 처리, 전체 자산 데이터 링크에는 도메인 자산 처리, 도메인 자산 검색 및 도메인 자산 평가가 포함됩니다.
- 비구조화 -> 구조화: 구조화된 방식으로 분류되어 올바르게 정리된 지식 정보입니다.
- 더 풍부한 시맨틱 정보를 추출하세요.
- 자산 검색:
- 단일 검색이 아닌 우선순위가 지정된 계층적 검색이 되길 바랍니다.
- 일부 규칙의 비즈니스 의미를 통해 사후 필터링하는 것이 중요합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...