
비디오챗: 사용자 지정 이미지 및 톤 복제가 가능한 실시간 음성 대화형 디지털 사람, 엔드투엔드 음성 솔루션 및 캐스케이딩 솔루션 지원

일반 소개
비디오챗은 오픈소스 기술을 기반으로 하는 실시간 음성 상호작용 디지털 휴먼 프로젝트로, 엔드투엔드 음성 체계(GLM-4-Voice - THG)와 캐스케이드 체계(ASR-LLM-TTS-THG)를 지원합니다. 이 프로젝트를 통해 사용자는 디지털 휴먼의 이미지와 음색을 커스터마이징할 수 있으며 음색 복제 및 립싱크, 비디오 스트리밍 출력, 3초의 낮은 첫 패킷 지연 시간을 지원합니다. 사용자는 온라인 데모를 통해 기능을 체험하거나 자세한 기술 문서를 통해 로컬에 배포하여 사용할 수 있습니다.
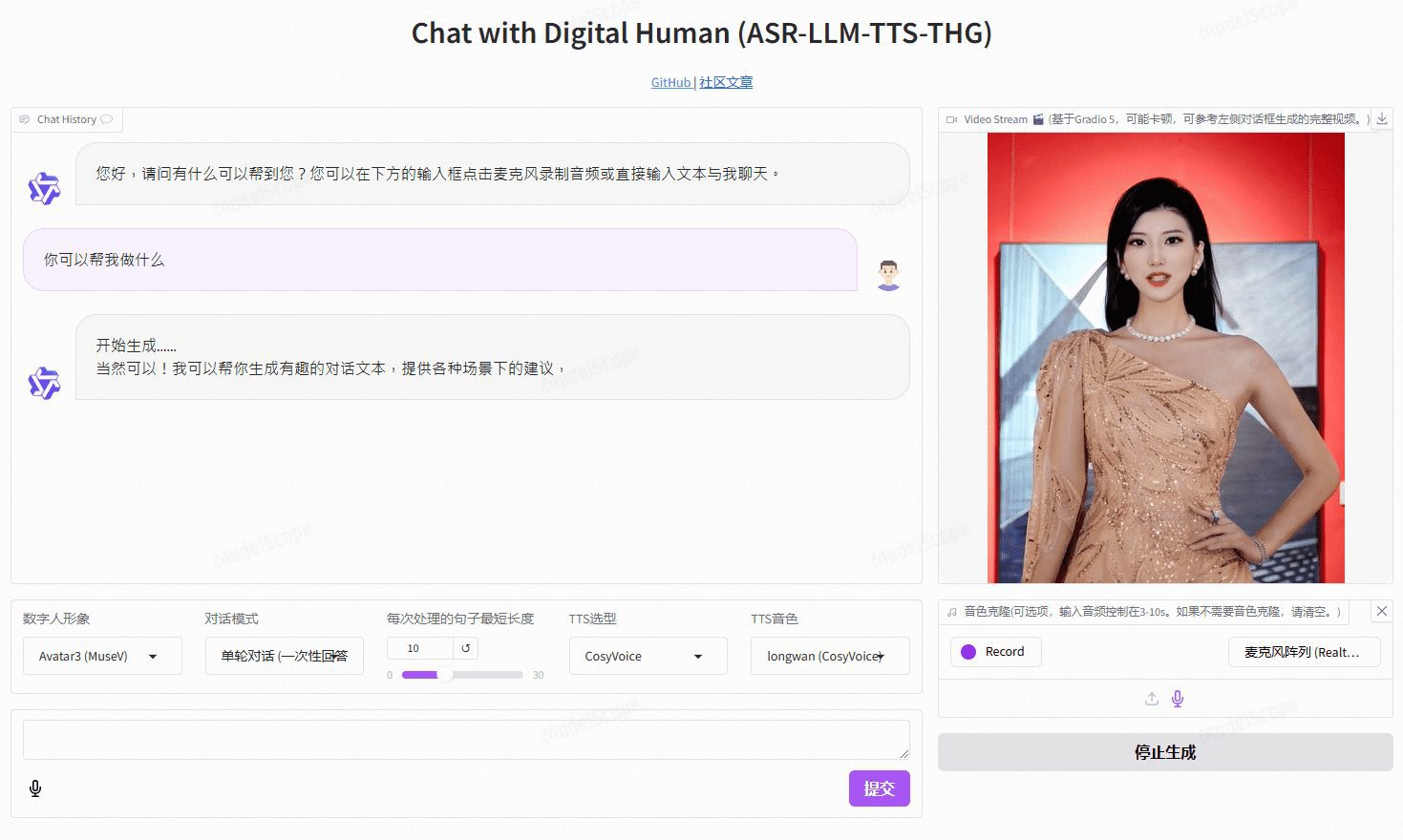
데모 주소: https://www.modelscope.cn/studios/AI-ModelScope/video_chat
기능 목록
- 실시간 음성 상호작용: 엔드투엔드 음성 솔루션 및 캐스케이딩 솔루션 지원
- 맞춤형 이미지 및 톤: 사용자는 필요에 따라 디지털 인물의 모양과 소리를 사용자 지정할 수 있습니다.
- 음성 복제: 개인화된 음성 경험을 제공하기 위해 사용자 음성 복제를 지원합니다.
- 짧은 지연 시간: 3초의 낮은 첫 패킷 지연 시간으로 원활한 상호 작용 경험 보장
- 오픈 소스 프로젝트: 오픈 소스 기술을 기반으로 사용자가 자유롭게 기능을 수정하고 확장할 수 있습니다.
도움말 사용
설치 프로세스
- 환경 구성
- 운영 체제: 우분투 22.04
- Python 버전: 3.10
- CUDA 버전: 12.2
- 토치 버전: 2.1.2
- 복제 프로젝트
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - 가상 환경 만들기 및 종속성 설치하기
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - 가중치 파일 다운로드
- CreateSpace를 사용하여 다운로드하고, 무게 파일을 추적하도록 git lfs를 설정한 후 사용하는 것이 좋습니다.
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - 서비스 시작
python app.py
사용 프로세스
- API-KEY 구성::
- 로컬 머신의 성능이 제한되어 있는 경우 알리윈의 빅모델 서비스 플랫폼인 Hundred Refine에서 제공하는 Qwen API와 CosyVoice API를 사용할 수 있습니다.
app.py에서 API-KEY를 구성합니다.
- 로컬 머신의 성능이 제한되어 있는 경우 알리윈의 빅모델 서비스 플랫폼인 Hundred Refine에서 제공하는 Qwen API와 CosyVoice API를 사용할 수 있습니다.
- 로컬 추론::
- API-KEY를 사용하지 않는 경우, 다음에서 사용할 수 있습니다.
src/llm.py노래로 응답src/tts.py로컬 추론 메서드를 구성하여 불필요한 API 호출 코드를 제거합니다.
- API-KEY를 사용하지 않는 경우, 다음에서 사용할 수 있습니다.
- 서비스 시작::
- 움직여야 합니다.
python app.py서비스를 시작합니다.
- 움직여야 합니다.
- 디지털 페르소나 사용자 지정::
- 존재
/data/video/카탈로그에 디지털 인체 이미지의 녹화된 동영상을 추가합니다. - 수정
/src/thg.py에 이미지 이름과 bbox_shift를 추가하여 Muse_Talk 클래스의 avatar_list에 추가합니다. - 존재
app.py디지털 페르소나의 이름을 Gradio의 avatar_name에 추가한 후 서비스를 다시 시작하고 초기화가 완료될 때까지 기다립니다.
- 존재
세부 운영 절차
- 사용자 지정 이미지 및 톤: in
/data/video/디렉토리에 디지털 인간 이미지의 녹화된 비디오를 추가하려면src/thg.py수정Muse_Talk클래스avatar_list를 클릭하고 이미지 이름을 추가하고bbox_shift매개변수. - 음성 복제: in
app.py중간 구성CosyVoice API또는Edge_TTS로컬 추론을 수행합니다. - 엔드투엔드 음성 솔루션사용
GLM-4-Voice모델을 사용하여 효율적인 음성 생성 및 인식을 제공합니다.
- 로컬로 배포된 서비스의 주소로 이동하여 Gradio 인터페이스로 이동합니다.
- 사용자 지정 디지털 페르소나 동영상을 선택하거나 업로드합니다.
- 음성 클론 기능을 구성하여 사용자의 음성 샘플을 업로드합니다.
- 실시간 음성 상호작용을 시작하고 지연 시간이 짧은 대화 기능을 경험하세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...