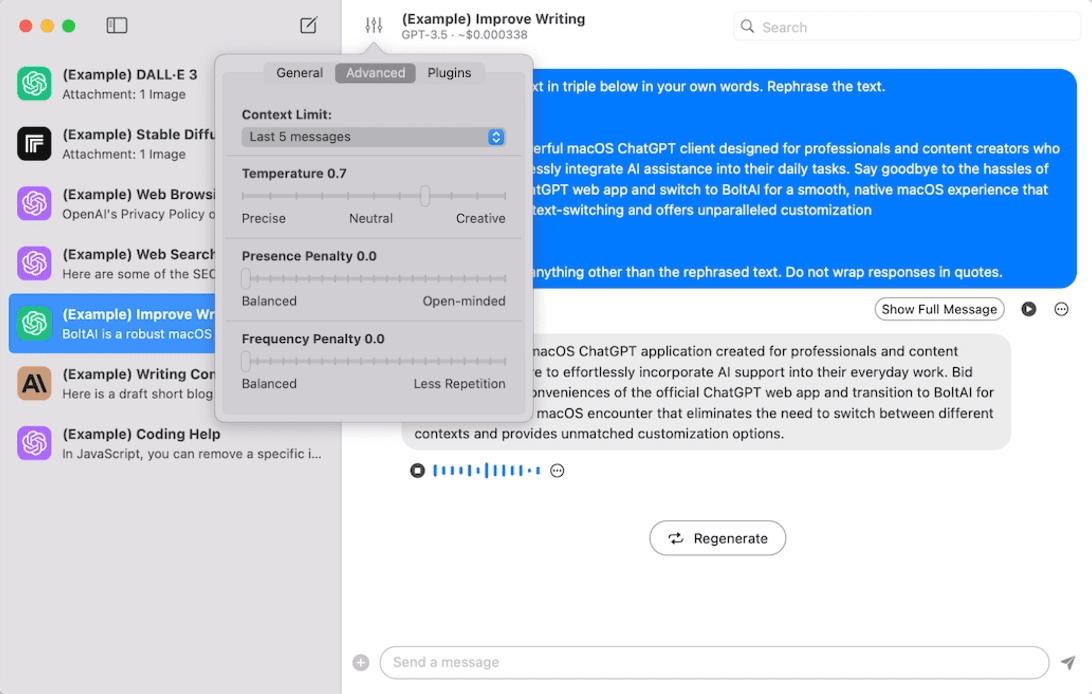

일반 소개
에서 검색, 추천, RAG(검색 증강 생성) 및 분석을 위해 개발한 포괄적인 인프라입니다. 이 플랫폼은 API를 통해 제공되며, 자체 호스팅되고, AWS, GCP, Kubernetes, Docker Compose 등의 환경에서 사용할 수 있습니다. Trieve는 OpenAI와 Jina의 임베딩 모델을 통합하고, 시맨틱 벡터 검색을 제공하며, 오타 허용 전체 텍스트/신경망 검색을 지원합니다. 추천 시스템은 사용자 행동을 기반으로 개인화된 콘텐츠 추천을 제공하여 사용자 경험을 향상시키며, Trieve는 검색 결과의 정확성과 관련성을 보장하기 위해 여러 필터링 및 그룹화 기능을 지원합니다.


오픈 소스 PDF를 마크다운으로 변환(PDF2MD): https://github.com/devflowinc/trieve/tree/main/pdf2md
기능 목록
- 자체 호스팅자세한 셀프 호스팅 가이드와 함께 VPC 또는 로컬 환경에서의 셀프 호스팅을 지원합니다.
- 시맨틱 벡터 검색고품질 시맨틱 벡터 검색을 제공하기 위해 OpenAI 또는 Jina 임베디드 모델을 통합합니다.
- 오타 허용 오차 검색오타 허용 신경 희소 벡터 검색을 네이버/efficient-splade-VI-BT-large-query 모델을 사용하여 제공합니다.
- 절 강조 표시검색 결과에서 일치하는 단어나 문장을 강조 표시하여 사용자 환경을 개선합니다.
- 추천 시스템사용자 행동(예: 즐겨찾기, 북마크, 좋아요)을 기반으로 개인화된 추천을 제공합니다.
- RAG API 라우팅오픈라우터와 통합, 다양한 LLM 액세스 옵션 제공, 토픽 메모리 관리 지원.
- 하이브리드 검색최상의 검색 결과를 제공하기 위해 BAAI/bge-reranker-large로 최적화 순서를 다시 지정합니다.
- 신선도 편향최신 콘텐츠를 기반으로 검색 결과를 편향하여 오래된 결과를 방지합니다.
- 조정 가능한 상업화클릭, 장바구니에 추가 또는 인용과 같은 신호를 기반으로 관련성을 조정합니다.
- 다중 필터링날짜 범위, 하위 문자열 일치, 레이블, 숫자 값 및 기타 여러 필터 유형을 지원합니다.
- 그룹화 기능여러 블록을 동일한 파일의 일부로 표시하는 기능을 지원하여 상위 결과가 중복되지 않도록 합니다.
도움말 사용
설치 프로세스
- 환경 준비하기curl, gcc, g++, make, pkg-config, python3, libpq-dev, libssl-dev 등과 같은 필요한 패키지가 설치되어 있는지 확인합니다.
- NodeJS 및 Yarn 설치NVM을 사용하여 NodeJS LTS 버전을 설치하고 Yarn을 전역으로 설치합니다.
- 환경 변수 설정.env 파일을 적절한 디렉터리에 복사하고 OpenAI API 키를 추가합니다.
- Docker 서비스 시작하기: docker-compose를 사용하여 필요한 컨테이너 서비스를 시작합니다.
- 지역 개발: tmuxp 또는 터미널 탭을 사용하여 로컬 개발 서비스를 관리하고 모듈을 시작합니다.
사용 가이드라인
- 계정 만들기로컬 서버를 방문하여 계정을 생성하고 테스트 데이터 세트를 업로드합니다.
- 데이터 집합 검색로컬 서버를 사용하여 데이터 세트 검색을 수행하여 설정이 제대로 작동하는지 확인합니다.
- 디버깅 및 지원문제가 발생하면 Discord를 통해 지원을 받거나 diesel::debug를 사용하세요.쿼리(&query).tostring()은 SQL 쿼리를 디버그합니다.
주요 기능
- 시맨틱 벡터 검색데이터를 업로드하면 시스템이 자동으로 벡터화를 수행하고 사용자는 API를 통해 시맨틱 검색을 수행할 수 있습니다.
- 추천 시스템사용자 행동 데이터를 기반으로 시스템이 자동으로 추천 콘텐츠를 생성하고, 사용자는 API를 통해 추천 결과를 확인할 수 있습니다.
- RAG API 라우팅사용자가 다른 LLM을 선택할 수 있습니다. RAG 작업을 수행하면 시스템은 주제 메모리 관리를 기반으로 최상의 결과를 제공합니다.
- 하이브리드 검색하이브리드 검색 기능을 사용하면 시스템이 자동으로 순서를 변경하고 최적화하여 가장 관련성 높은 검색 결과를 제공합니다.
- 필터링 및 그룹화검색 결과의 정확성과 관련성을 보장하기 위해 사용자는 필요에 따라 다양한 필터와 그룹을 설정할 수 있습니다.
위의 자세한 설치 및 사용 가이드를 통해 사용자는 Trieve의 기능을 쉽게 시작하고 강력한 검색, 추천 및 분석 기능을 최대한 활용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...