
TPO-LLM-WebUI: 질문을 입력하여 실시간으로 모델을 학습시키고 결과를 출력할 수 있는 AI 프레임워크입니다.

일반 소개
TPO-LLM-WebUI는 직관적인 웹 인터페이스를 통해 대규모 언어 모델(LLM)을 실시간으로 최적화할 수 있는 혁신적인 프로젝트로, Airmomo가 GitHub에서 오픈 소스화했습니다. TPO(테스트 시간 프롬프트 최적화) 프레임워크를 채택하여 기존의 지루한 미세 조정 프로세스와 완전히 작별하고 학습 없이 모델 출력을 직접 최적화합니다. 사용자가 질문을 입력하면 시스템은 보상 모델과 반복 피드백을 사용하여 추론 과정에서 모델이 동적으로 진화하여 점점 더 똑똑해지고 출력 품질을 최대 50%까지 향상시킵니다. 기술 문서를 다듬거나 보안 응답을 생성할 때 이 가볍고 효율적인 도구는 개발자와 연구원에게 강력한 지원을 제공합니다.


기능 목록
- 실시간 진화추론 단계를 통해 출력을 최적화하면 더 많이 사용할수록 사용자의 요구 사항을 더 많이 충족할 수 있습니다.
- 미세 조정이 필요하지 않습니다.모델 가중치를 업데이트하지 않고 생성 품질을 직접 개선하지 않습니다.
- 여러 모델 호환다양한 기본 및 보상 모델 로딩을 지원합니다.
- 동적 환경 설정 정렬보상 피드백에 따라 출력을 조정하여 사람의 기대치에 근접하도록 합니다.
- 추론 시각화최적화 반복 프로세스를 쉽게 이해하고 디버깅할 수 있도록 최적화 반복 프로세스를 시연합니다.
- 가볍고 효율적컴퓨팅은 비용이 저렴하고 배포가 간단합니다.
- 오픈 소스 및 유연성소스 코드를 제공하고 사용자 정의 개발을 지원합니다.
도움말 사용
설치 프로세스
TPO-LLM-WebUI를 배포하려면 몇 가지 기본 환경 구성이 필요합니다. 다음은 사용자가 빠르게 시작할 수 있도록 도와주는 자세한 단계입니다.
1. 환경 준비하기
다음 도구가 설치되어 있는지 확인하세요:
- Python 3.10핵심 운영 환경.
- Git: 프로젝트 코드를 가져오는 데 사용됩니다.
- GPU(권장)NVIDIA GPU가 추론을 가속화합니다.
가상 환경을 만듭니다:
Condi를 사용합니다:
conda create -n tpo python=3.10
conda activate tpo
또는 Python 자체 도구:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
종속 요소를 다운로드하여 설치합니다:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
TextGrad를 설치합니다:
TPO는 추가 설치가 필요한 TextGrad에 의존합니다:
cd textgrad-main
pip install -e .
cd ..
2. 구성 모델
기본 모델과 보너스 모델을 수동으로 다운로드해야 합니다:
- 기본 모델As
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(포옹하는 얼굴) - 인센티브 모델링As
sfairXC/FsfairX-LLaMA3-RM-v0.1(포옹하는 얼굴)
모델을 지정된 디렉터리에 배치합니다(예/model/HuggingFace/), 그리고config.yaml경로를 설정합니다.
3. vLLM 서비스 시작
활용 vLLM 호스팅 기본 모델. GPU 2개를 예로 들어보겠습니다:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
서비스가 실행되고 나면 http://127.0.0.1:8000.
4. WebUI 실행
새 터미널에서 웹 인터페이스를 시작합니다:
python gradio_app.py
브라우저 액세스 http://127.0.0.1:7860바로 사용할 수 있습니다.
주요 기능
기능 1: 모델 초기화
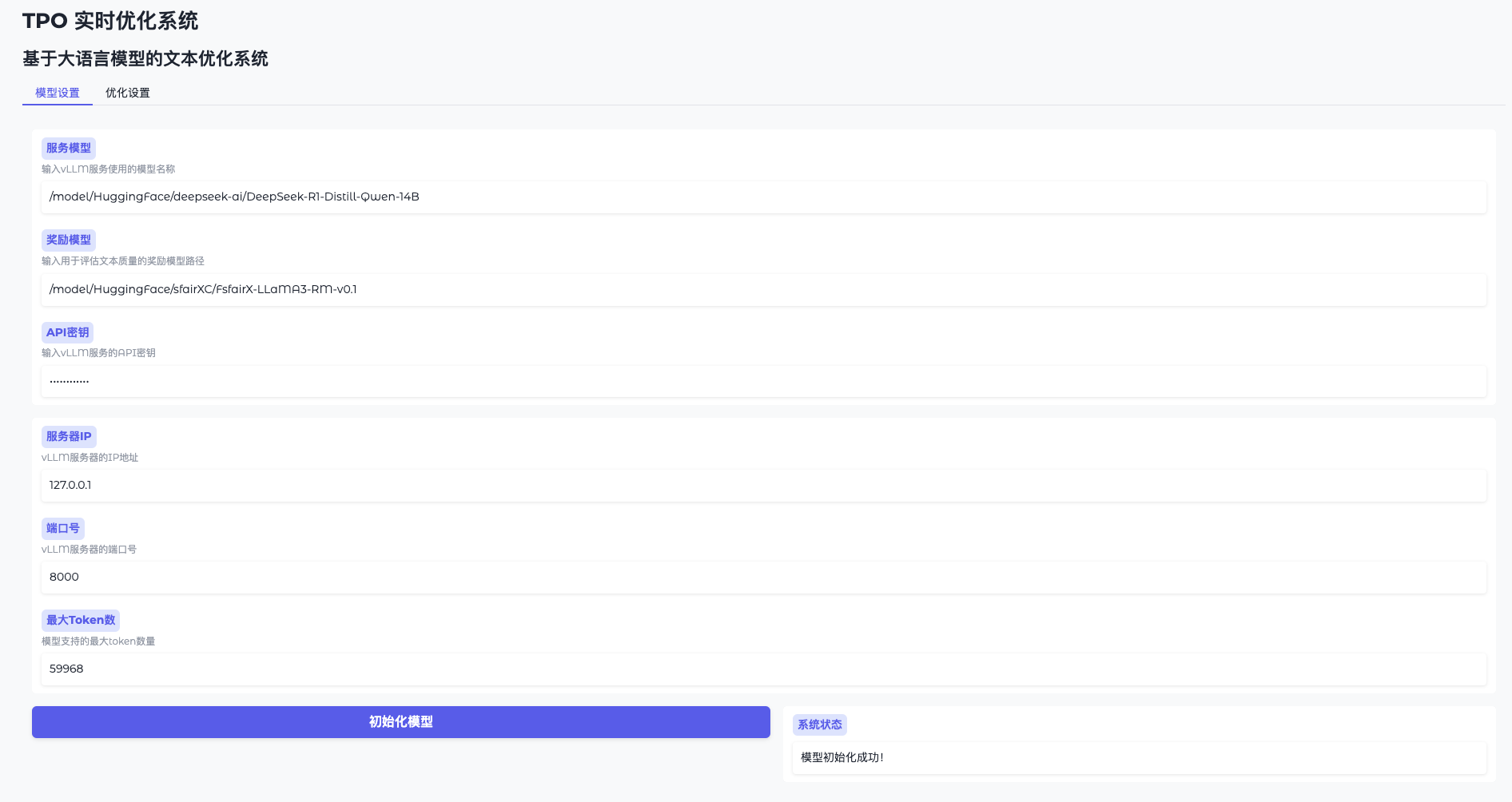
- 모델 설정 열기
WebUI로 이동하여 '모델 설정'을 클릭합니다. - vLLM에 연결
주소를 입력합니다(예http://127.0.0.1:8000)와 키(token-abc123). - 보상 모델 로드
경로를 지정합니다(예/model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1'초기화'를 클릭하고 1~2분 정도 기다립니다. - 준비 상태 확인
인터페이스에 "모델 준비 완료"라는 메시지가 표시되면 계속 진행할 수 있습니다.
기능 2: 실시간 출력 최적화
- 최적화 페이지 토글
'설정 최적화'로 이동합니다. - 입력 문제
"이 기술 문서 수정"과 같은 콘텐츠를 입력합니다. - 운영 최적화
'최적화 시작'을 클릭하면 시스템이 여러 후보 결과를 생성하고 이를 반복적으로 개선합니다. - 진화 과정을 확인하세요.
결과 페이지에는 초기 및 최적화된 결과물이 표시되며 품질이 점진적으로 향상됩니다.
기능 3: 스크립트 모드 최적화
WebUI를 사용하지 않는 경우 스크립트를 실행할 수 있습니다:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
최적화 결과는 다음 위치에 저장됩니다. logs/ 폴더.
특수 기능에 대한 자세한 설명
미세 조정은 이제 그만하고 실시간으로 진화하세요.
- 절차::
- 질문을 입력하면 시스템이 초기 답변을 생성합니다.
- 모델 평가 및 피드백을 보상하여 다음 반복을 안내합니다.
- 여러 번 반복하면 출력물이 '더 스마트'해지고 품질이 크게 향상됩니다.
- 최첨단교육 없이도 언제든지 최적화하여 시간과 산술 계산을 절약하세요.
사용하면 할수록 더 똑똑해집니다.
- 절차::
- 문제마다 다른 입력값으로 동일한 모델을 여러 번 사용합니다.
- 시스템은 각 피드백을 기반으로 경험을 축적하고 필요에 따라 더 나은 결과물을 제공합니다.
- 최첨단장기적으로 더 나은 결과를 위해 사용자 선호도를 동적으로 학습합니다.
주의
- 하드웨어 요구 사항권장 16GB 이상의 비디오 메모리, 여러 개의 GPU를 사용하려면 리소스를 확보하고 사용 가능한 여유 공간이 있어야 합니다.
export CUDA_VISIBLE_DEVICES=2,3지정. - 문제 해결비디오 메모리가 넘치면 비디오 메모리의
sample_size를 클릭하거나 GPU 점유율을 확인하세요. - 커뮤니티 지원도움말은 GitHub README 또는 이슈를 참조하세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...