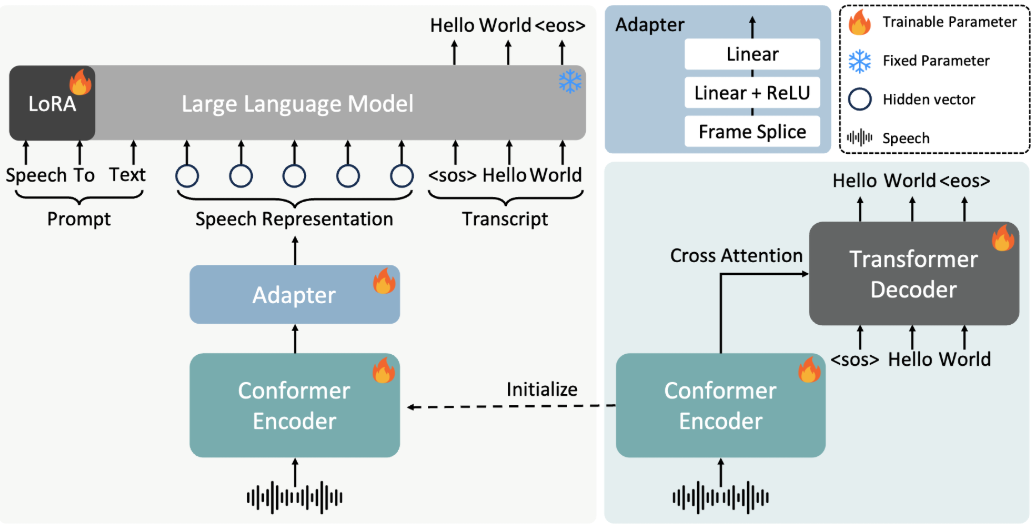
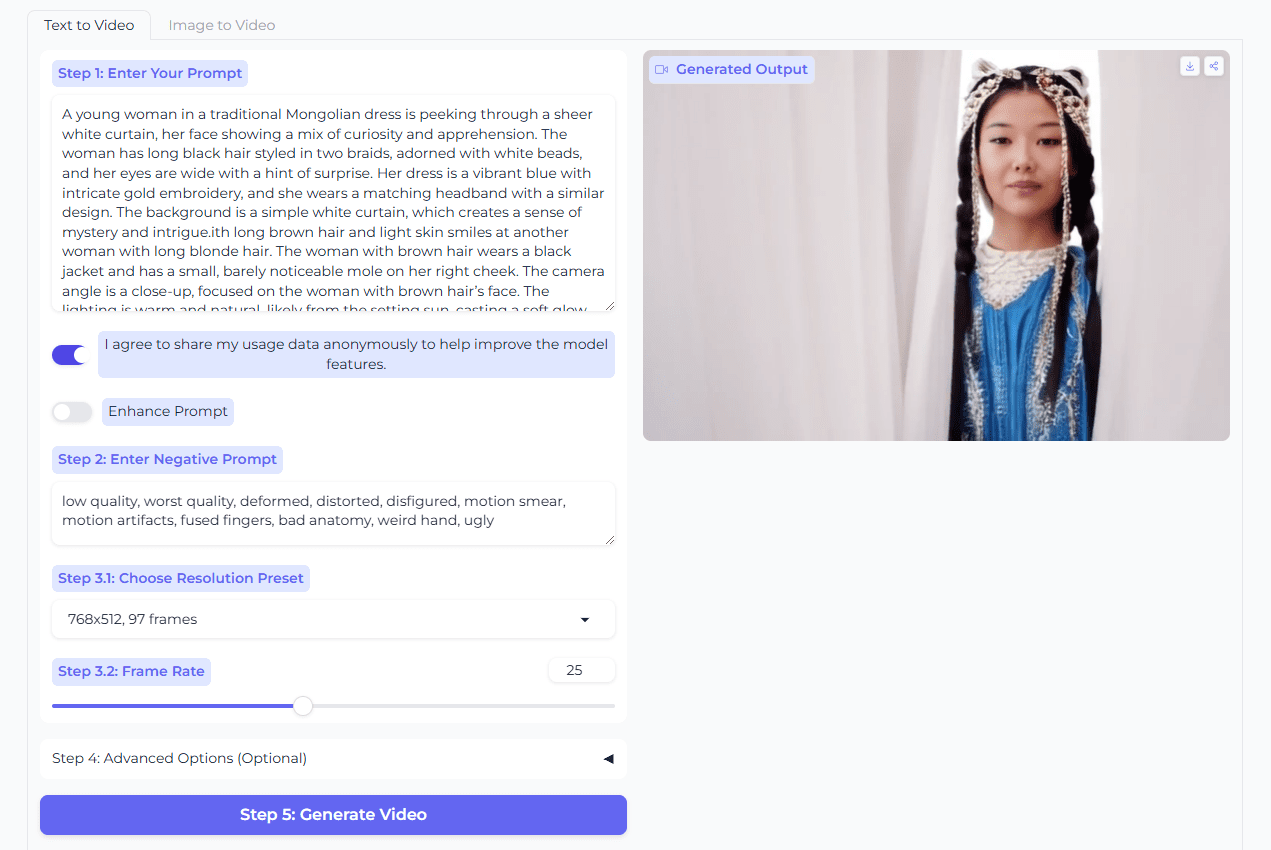
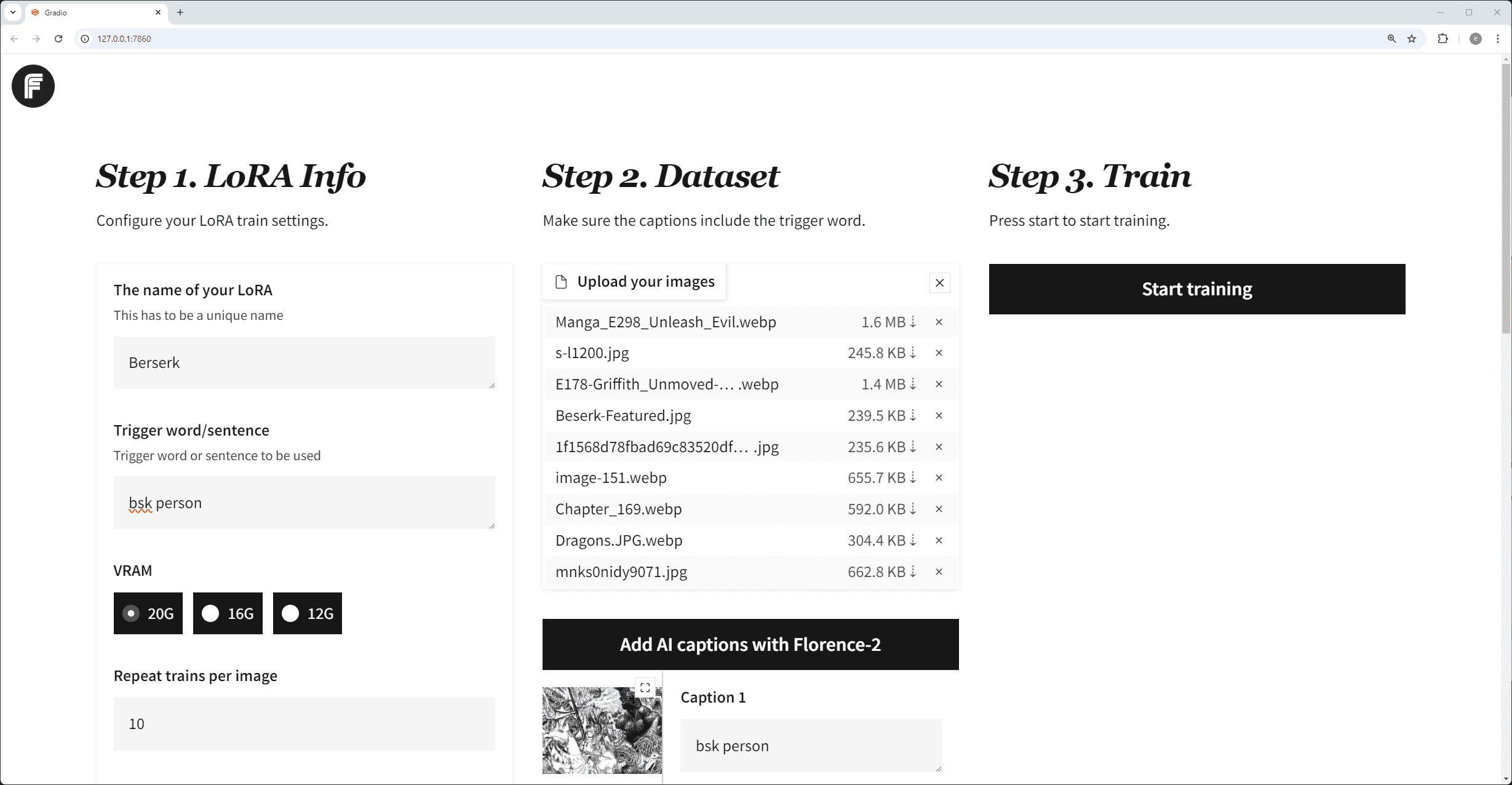
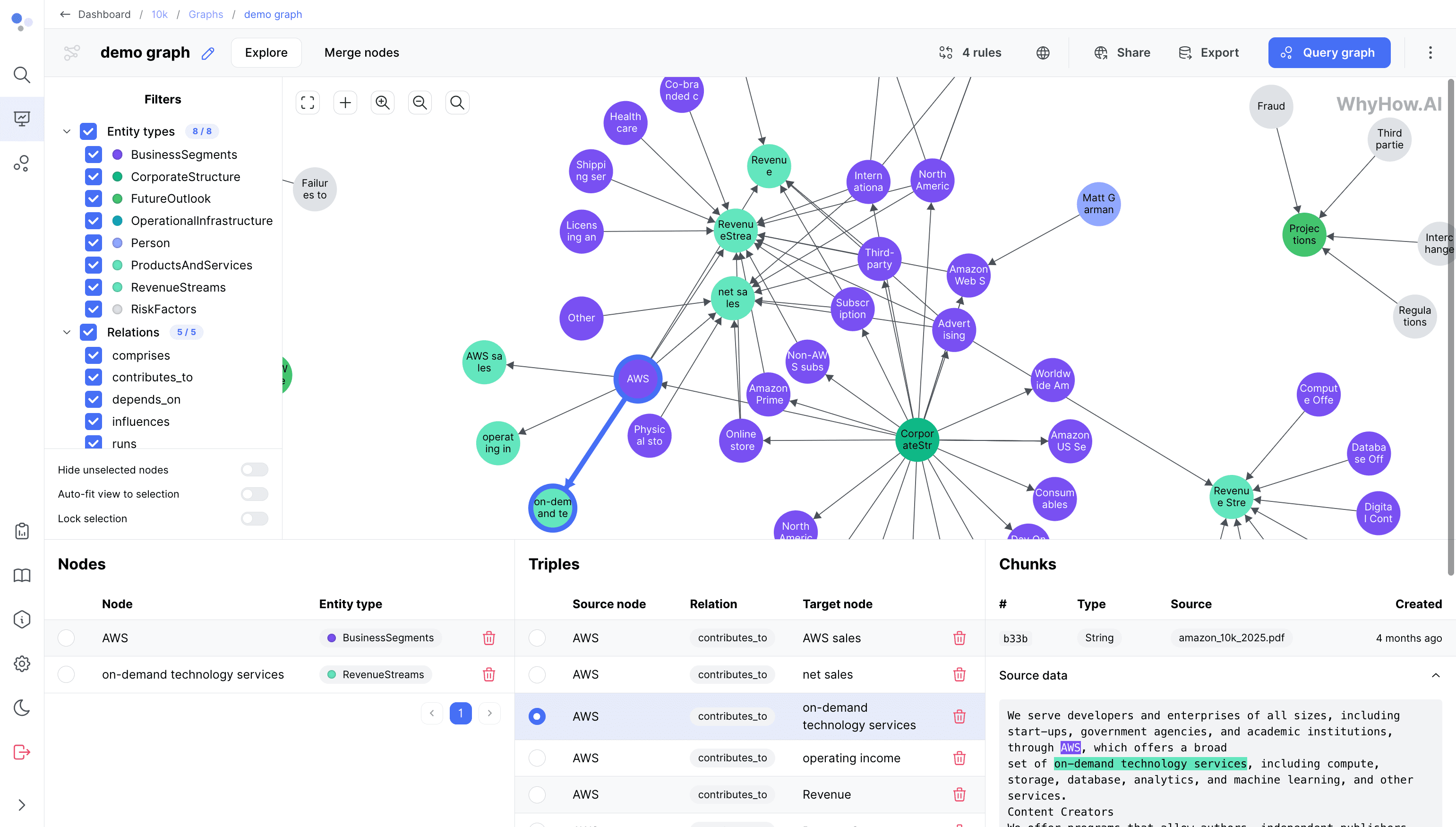
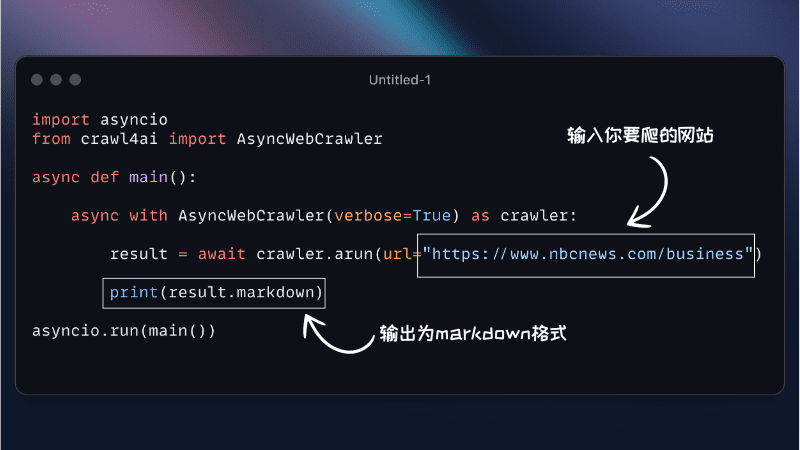
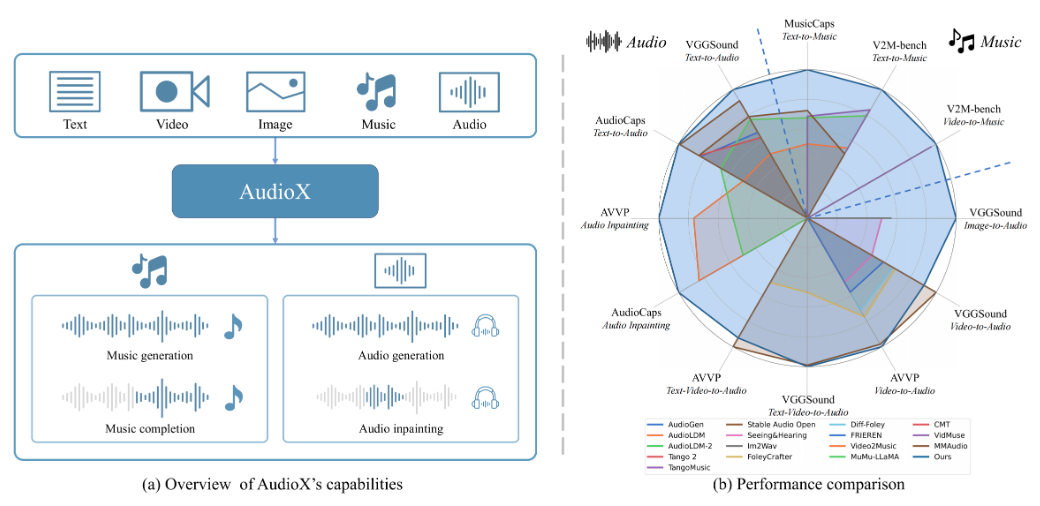
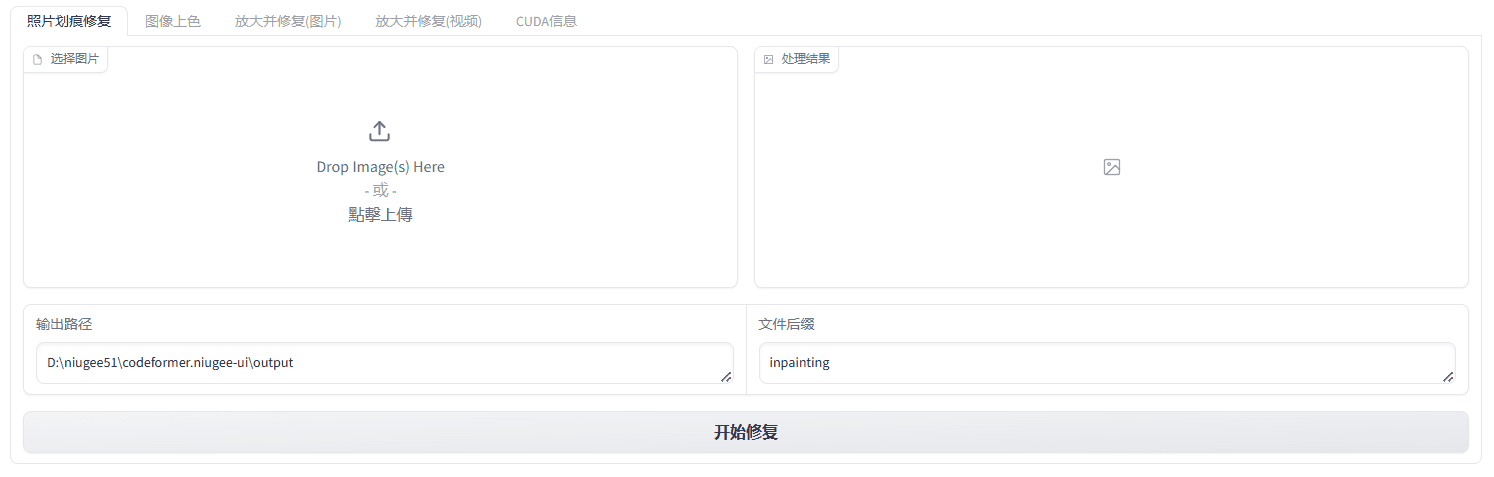
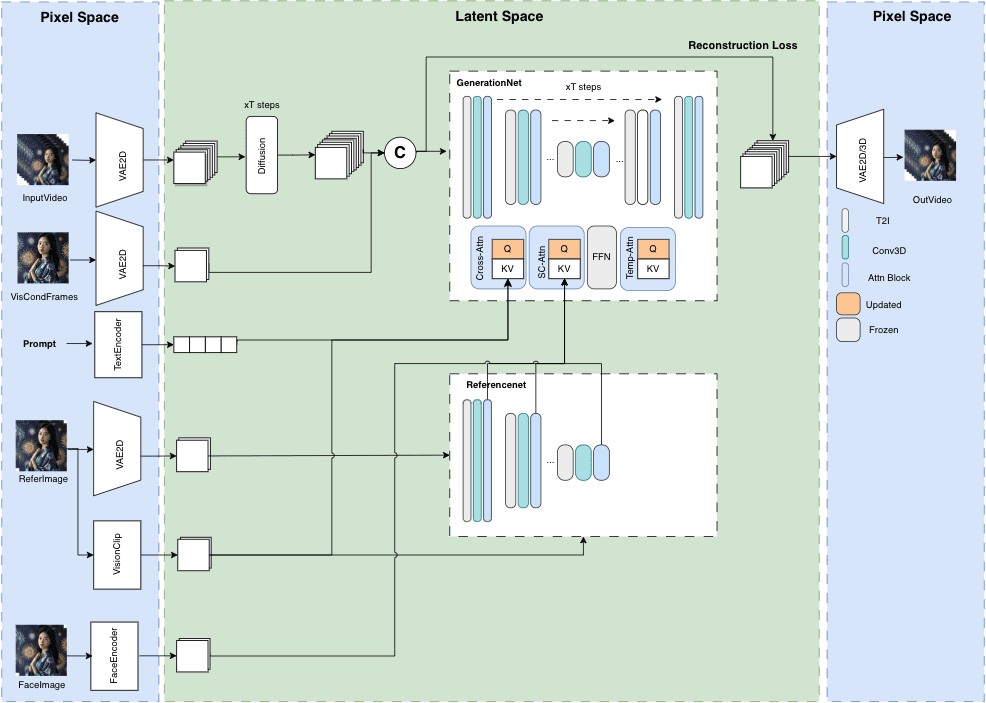
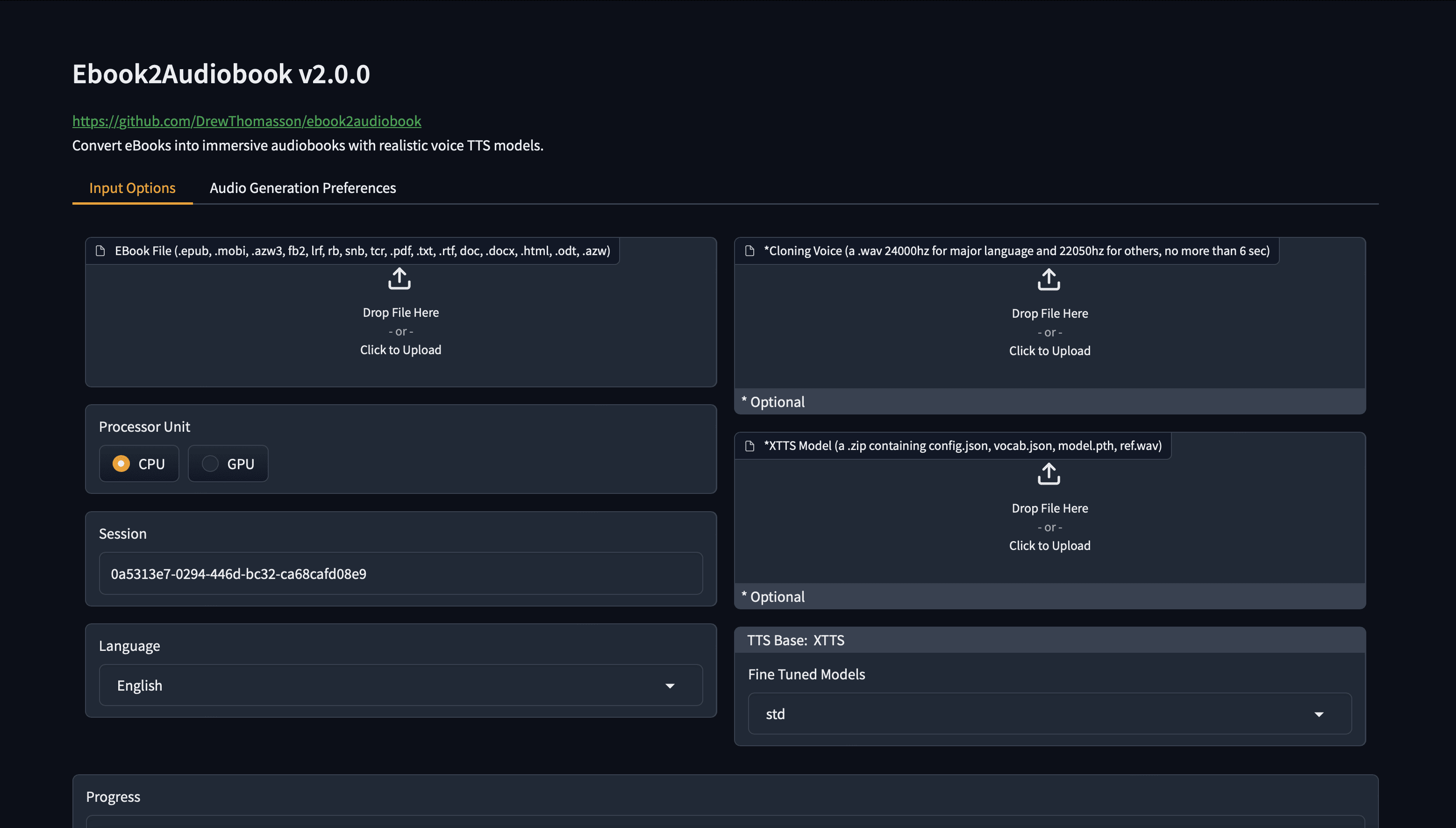
일반 소개 FireRedASR은 고정밀, 다국어 지원 자동 음성 인식(ASR) 솔루션을 제공하는 데 중점을 둔 Little Red Book FireRed 팀이 개발하여 오픈소스로 공개한 음성 인식 모델입니다. 이 프로젝트는 개발자와 연구자를 위해 GitHub에서 호스팅되며 다음과 같은 기능을 제공합니다.
일반 소개 OpenManus는 사용자가 간단한 설정으로 로컬에서 인텔리전스를 실행하여 다양한 창의적인 아이디어를 실현할 수 있도록 설계된 오픈 소스 프로젝트입니다. MetaGPT 커뮤니티 회원인 @mannaandpoem, @XiangJinyu, @Mos...가 개발했습니다.
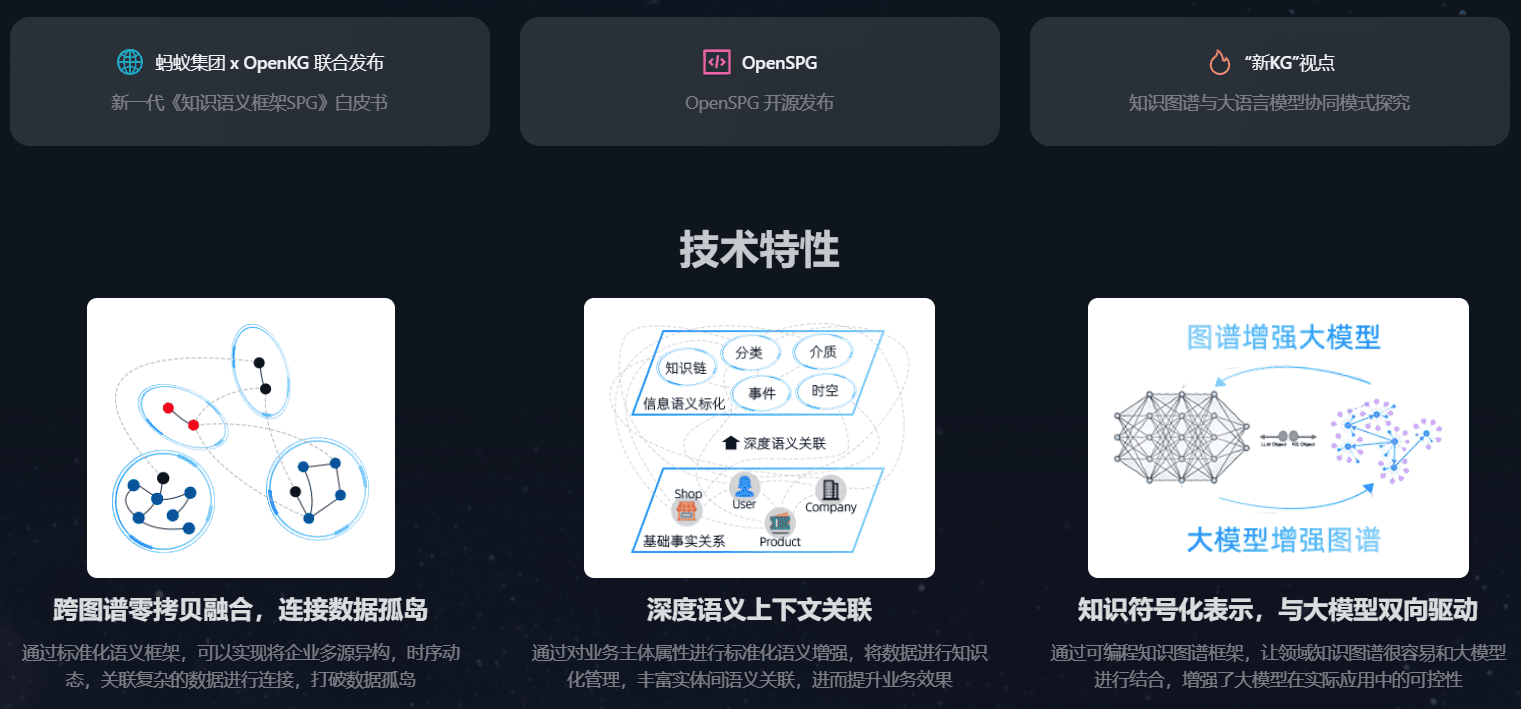
종합 소개 OpenSPG는 SPG(Semantic Augmented Programmable Graph) 프레임워크에 기반하여 Ant Group이 OpenKG와 협력하여 개발한 오픈 소스 지식 그래프 엔진입니다. 이 엔진은 도메인 지식 그래프의 구축 및 관리를 지원하기 위해 명시적 의미 표현, 논리적 규칙 정의 및 운영 프레임워크와 같은 기능을 제공하도록 설계되었습니다....
일반 소개 Void는 vscode 저장소의 브랜치를 기반으로 하는 오픈 소스 커서 대안입니다. 개발자에게 보다 효율적인 코딩 경험을 제공하도록 설계된 강력한 개발 환경을 제공하며, 커뮤니티 기여와 빠른 반복을 통해 기능과 안정성을 지속적으로 개선하는 것이 Void의 목표입니다....
일반 소개 Make Sense는 사용자가 컴퓨터 비전 프로젝트를 위한 데이터 세트를 빠르게 준비할 수 있도록 설계된 무료 온라인 이미지 주석 도구입니다. 복잡한 설치 없이 브라우저에 액세스하기만 하면 사용할 수 있고, 여러 운영 체제를 지원하며, 소규모 딥 러닝 프로젝트에 이상적입니다. 사용자는 다음을 수행할 수 있습니다.
일반 소개 NocoDB는 강력하고 사용하기 쉬운 온라인 데이터베이스 관리 도구를 제공하도록 설계된 오픈 소스 Airtable의 대안입니다. NocoDB를 사용하면 코드를 작성하지 않고도 데이터베이스에서 데이터를 쉽게 생성, 읽기, 업데이트 및 삭제할 수 있습니다. 이 플랫폼은 다음을 지원합니다.
종합 소개 RAGFlow는 심층 문서 이해 기술을 기반으로 하는 오픈 소스 검색 증강 생성(RAG) 엔진입니다. 모든 규모의 비즈니스에 효율적인 RAG 워크플로우를 제공하며, 실제 데이터를 기반으로 복잡한 형식의 데이터를 제공할 수 있는 대규모 언어 모델(LLM)을 통합합니다.
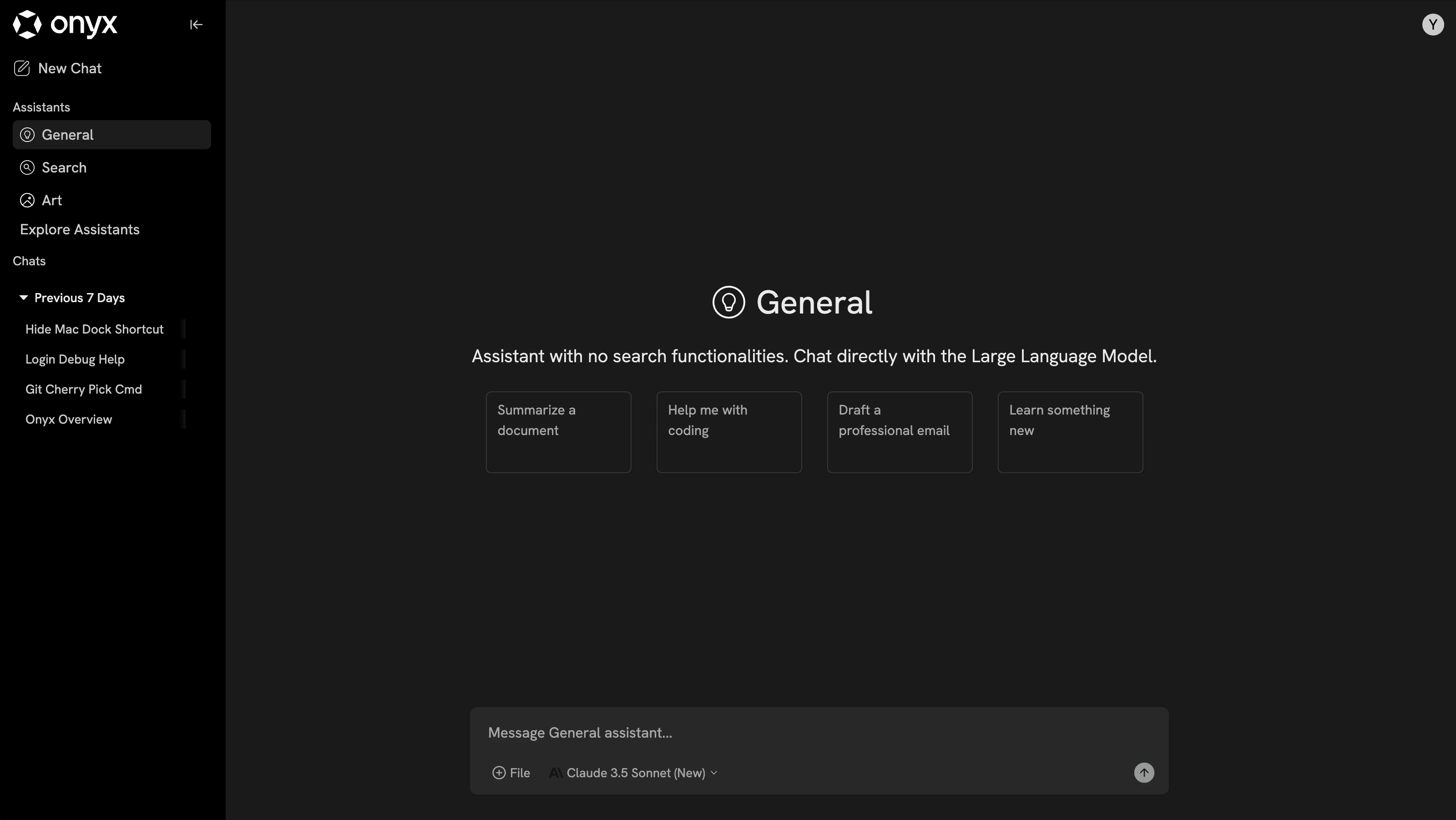
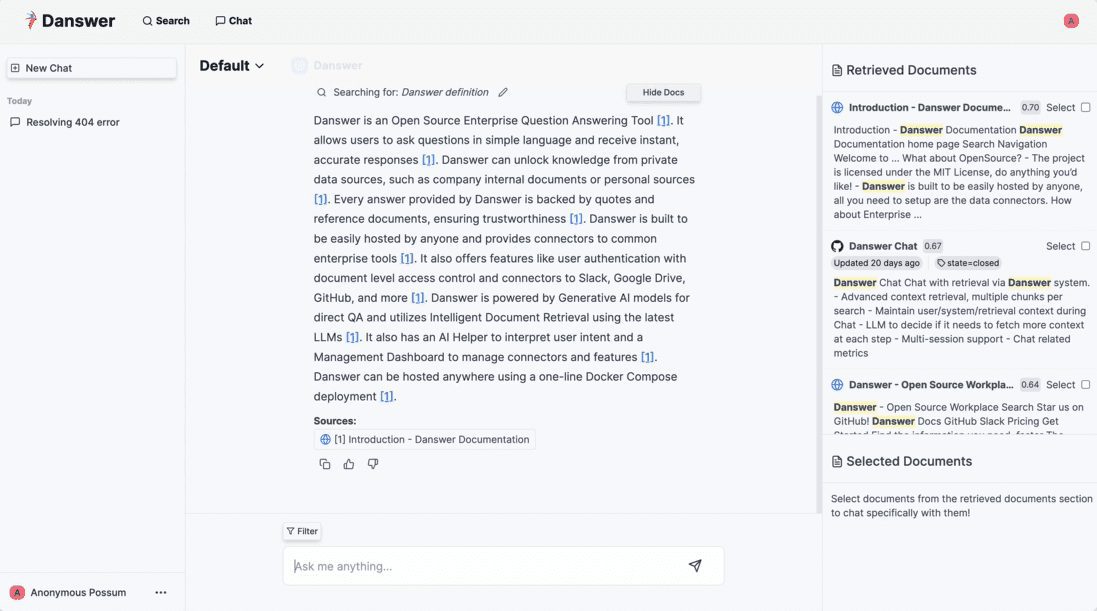
일반 소개 Onyx(구 Danswer)는 조직이 문서, 애플리케이션 및 직원 데이터를 통합하고 관리할 수 있도록 지원하기 위해 onyx-dot-app 팀에서 개발한 오픈 소스 AI 채팅 플랫폼입니다. 모든 대규모 언어 모델(LLM)을 연결할 수 있는 풍부한 채팅 기능을 제공합니다.
포괄적인 소개 KrillinAI는 인공 지능을 사용하여 사용자가 동영상을 번역하고 자동으로 더빙하는 데 중점을 둔 오픈 소스 동영상 처리 도구입니다. 동영상 다운로드부터 다양한 플랫폼에 적합한 완제품 생성까지 모든 과정을 단 몇 번의 클릭만으로 진행할 수 있습니다. 개발자는 깃허브에서 확인할 수 있습니다...
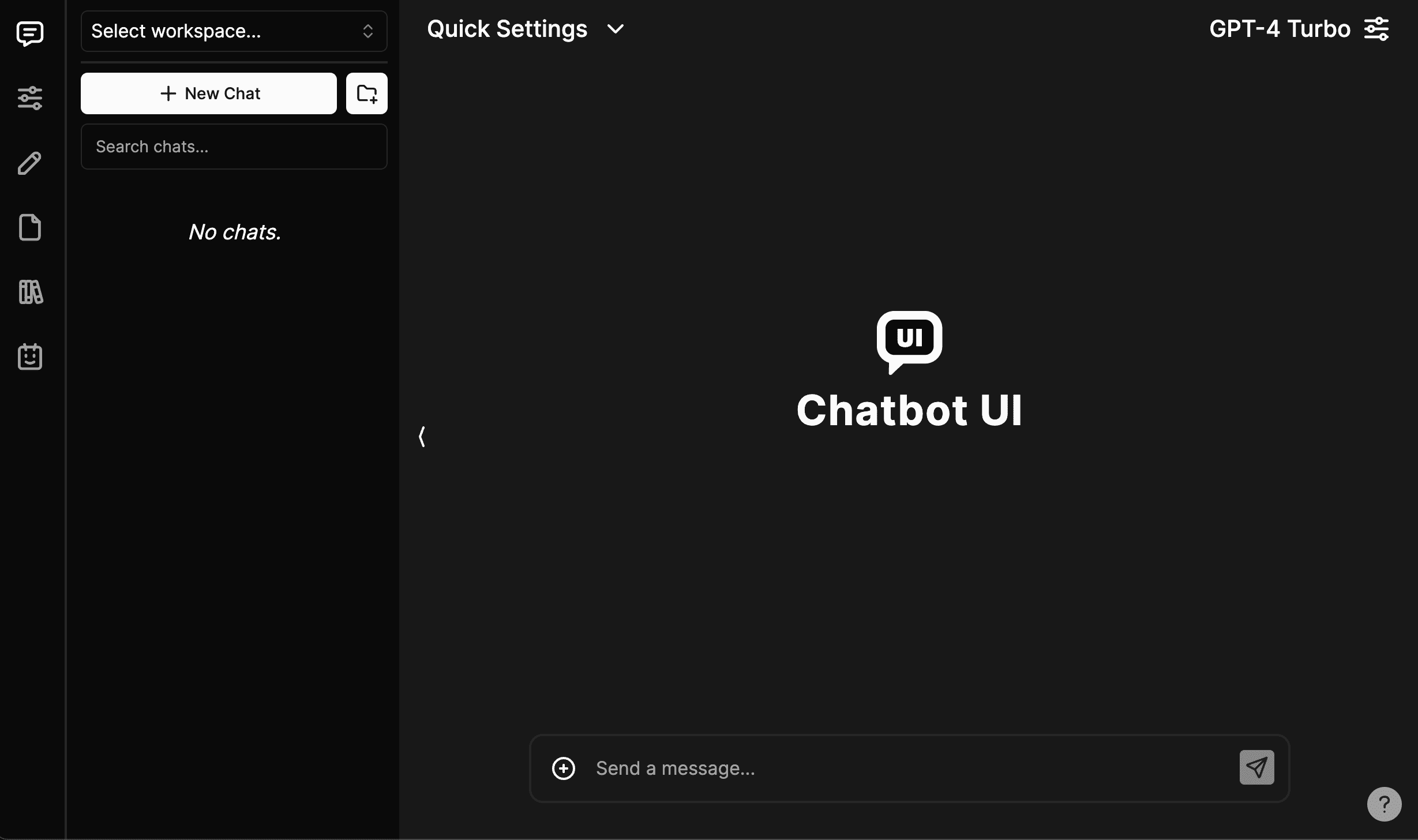
일반 소개 챗봇 UI는 개발자가 개인화되고 지능적인 대화형 인터페이스를 만들 수 있도록 설계된 오픈 소스 프로젝트입니다. 이 프로젝트는 기존 챗봇 시스템에 쉽게 통합할 수 있는 일련의 인터페이스 구성 요소와 대화형 기능을 제공하여 사용자에게 보다 유동적이고 지능적인 대화체를 제공합니다.
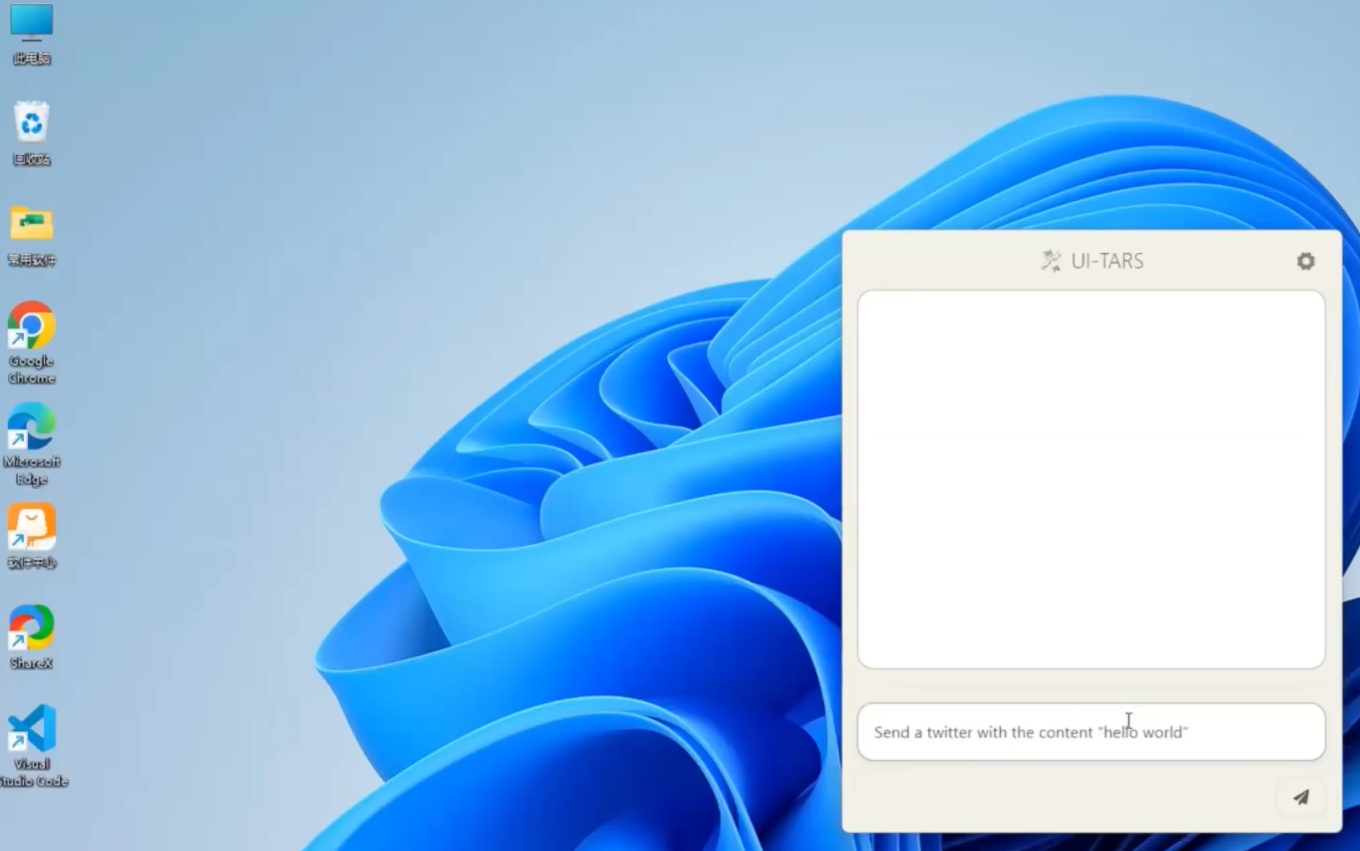
일반 소개 UI-TARS 데스크톱은 바이트댄스에서 개발한 UI-TARS(시각 언어 모델)를 기반으로 한 그래픽 인터페이스 에이전트 애플리케이션입니다. 이 애플리케이션을 통해 사용자는 자연어를 통해 컴퓨터를 제어하여 보다 직관적이고 효율적인 인간-컴퓨터 상호 작용을 할 수 있습니다.UI-TAR...
일반 소개 유튜브와 트위터 동영상을 다운로드해야 할 때가 종종 있어서 광고 없는 무료 동영상 다운로더를 찾았습니다.Cobalt는 사용자 친화적인 다운로드 환경을 제공하도록 설계된 오픈 소스 미디어 다운로더입니다. 다음을 포함한 여러 플랫폼에서 비디오 및 오디오 콘텐츠 다운로드를 지원합니다.
일반 소개 Chat2DB는 CodePhiliaX 팀이 개발한 오픈 소스 데이터베이스 관리 및 SQL 클라이언트 도구로, AI 기능과 통합되어 있으며, 신속한 SQL 쿼리 작성, 데이터베이스 관리, 데이터 보고서 생성 및 다중 데이터베이스 상호 작용을 지원합니다. 그것은 16 개 이상을 지원합니다 ...
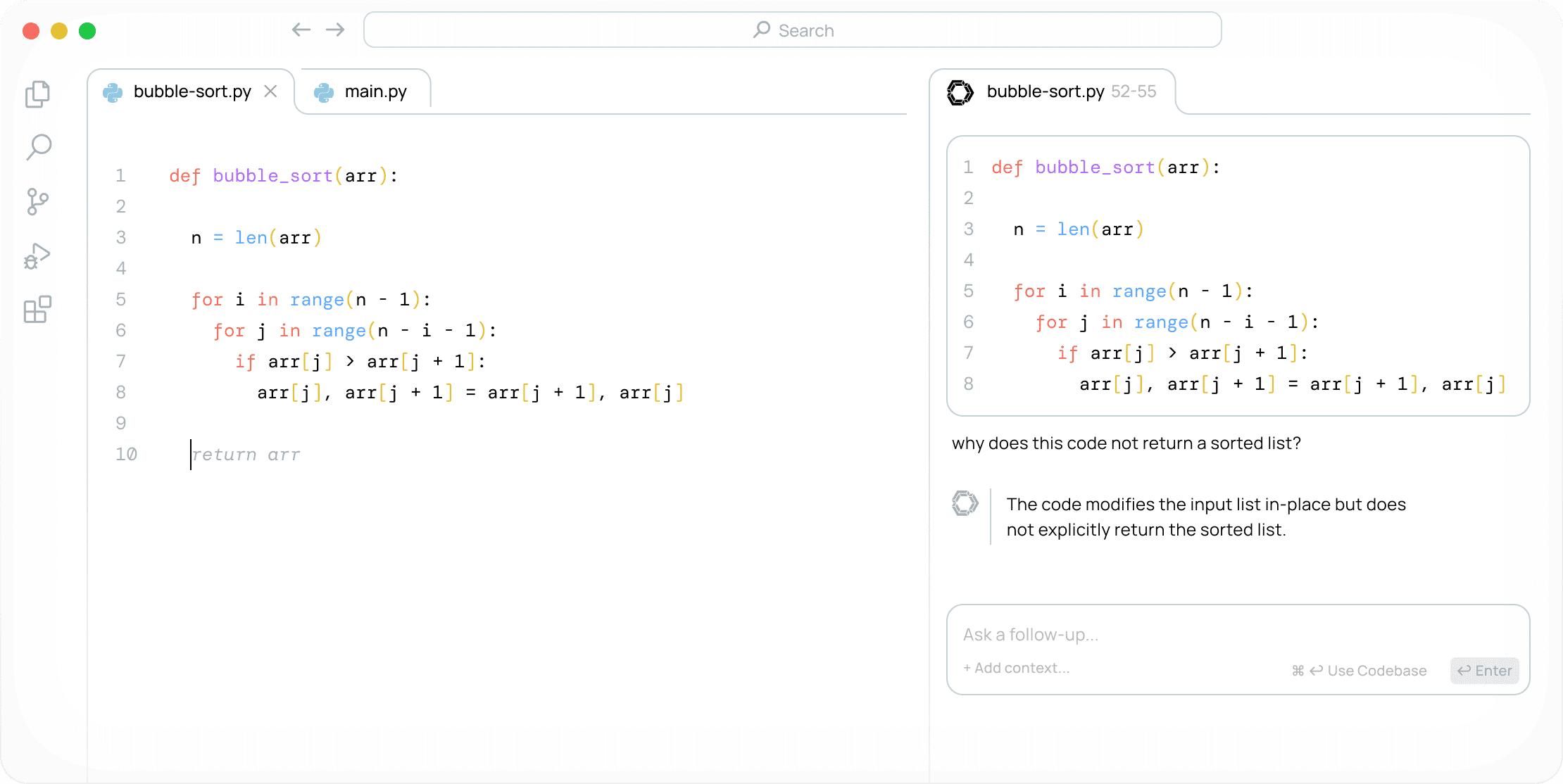
일반 소개 Continue는 소프트웨어 개발자의 효율성을 개선하기 위해 설계된 오픈 소스 AI 코드 어시스턴트입니다. 주요 기능으로는 코드 자동 완성, 코드 최적화, VS Code 및 JetBrains IDE를 위한 지능형 코드 제안 등이 있습니다.Continue의 기능은 다음과 같습니다.
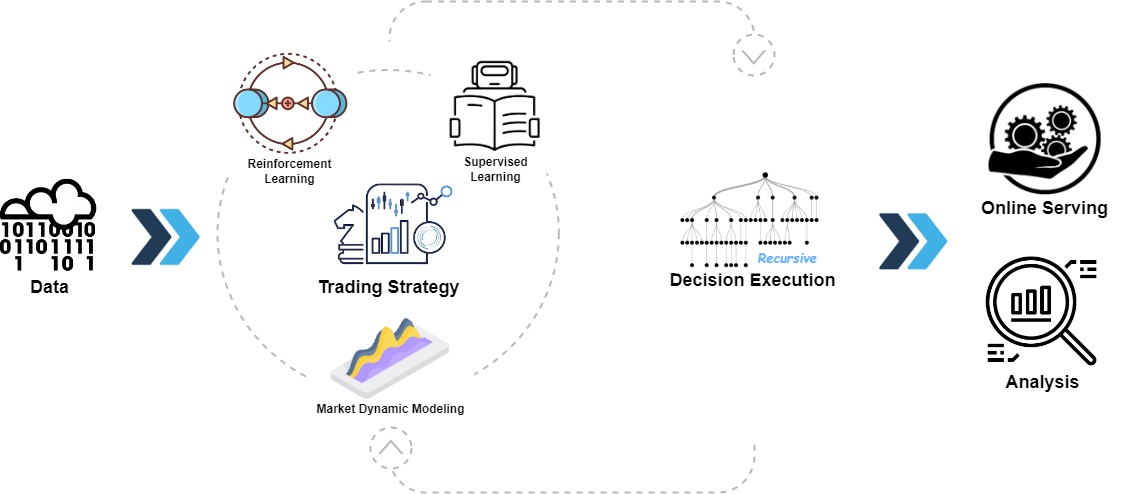
종합 소개 Qlib은 Microsoft에서 개발한 오픈 소스 플랫폼으로, AI 기술을 사용하여 사용자가 정량적 투자를 조사하는 데 중점을 두고 있습니다. 가장 기본적인 데이터 처리부터 시작하여 사용자가 투자 아이디어를 탐색하고 이를 사용 가능한 전략으로 전환할 수 있도록 지원합니다. 이 플랫폼은 간단하고 사용하기 쉬우며 머신 러닝을 사용하여 투자 연구를 개선하려는 사람들에게 적합합니다.
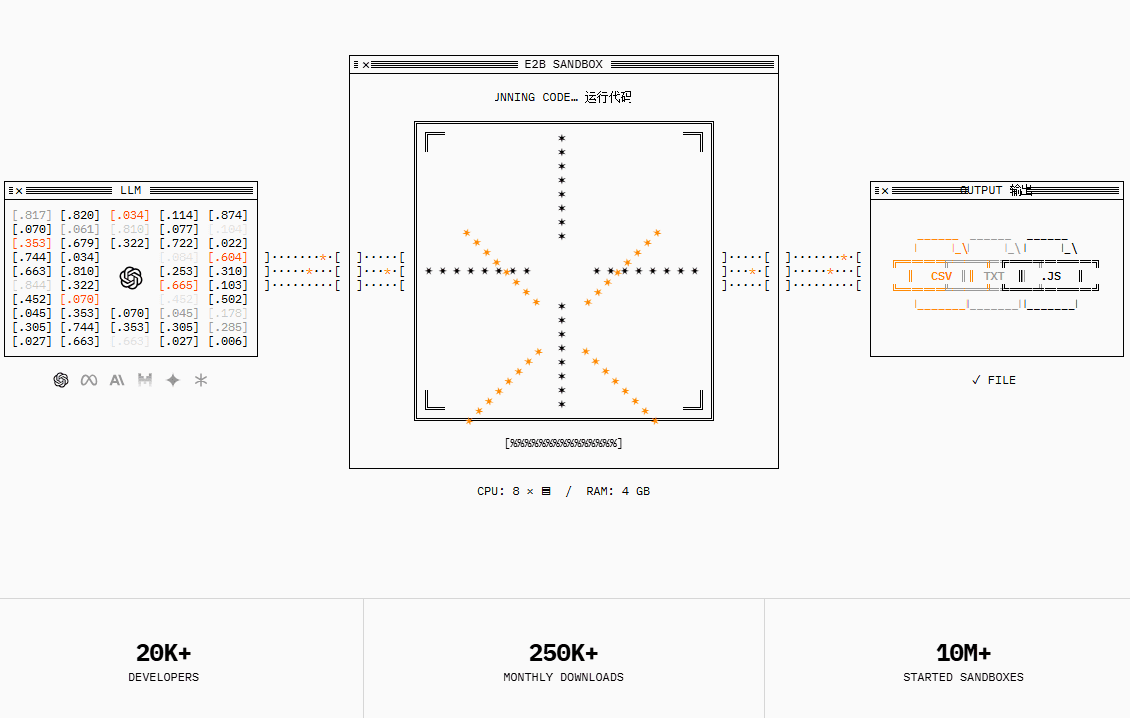
일반 소개 E2B는 안전한 클라우드 샌드박스에서 AI 생성 코드를 실행하도록 설계된 오픈 소스 플랫폼입니다. 다양한 프로그래밍 언어와 프레임워크를 지원하고 격리된 가상 환경을 제공하여 코드 실행의 보안과 안정성을 보장하며, E2B는 데이터 파티셔닝을 비롯한 다양한 AI 애플리케이션 시나리오에 적합합니다.
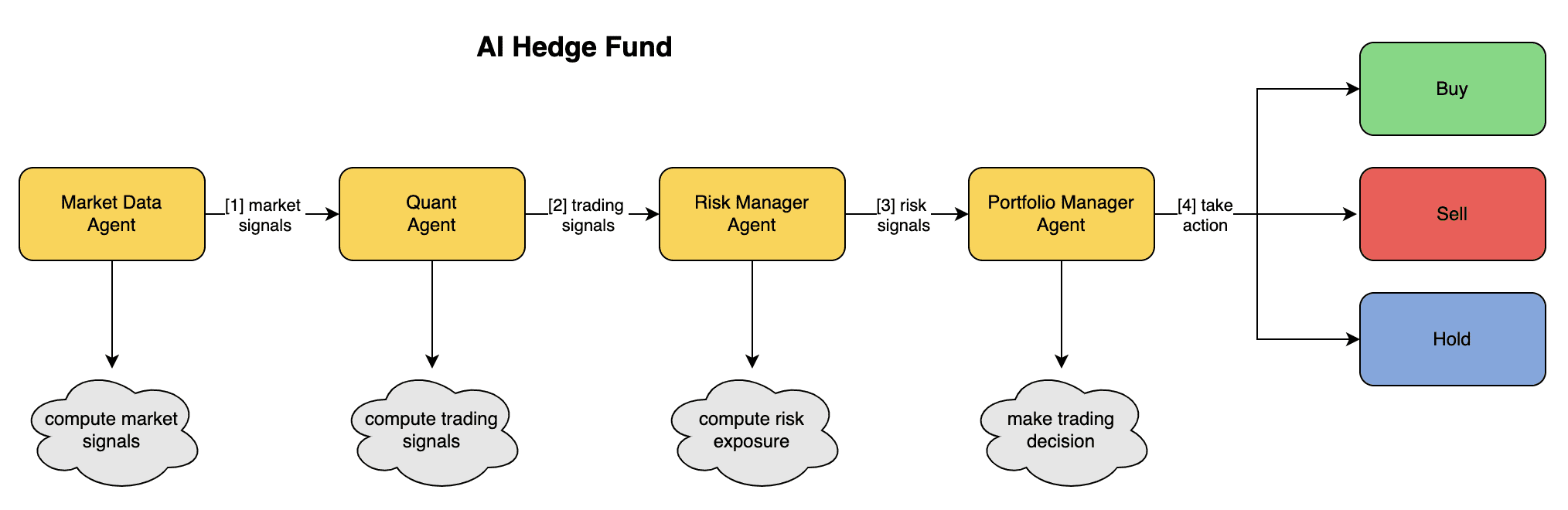
일반 소개 AI 헤지 펀드는 멀티 에이전트 시스템을 활용하여 매매 결정을 내리는 인공지능 헤지 펀드입니다. 이 시스템은 시장 데이터 에이전트, 퀀트 에이전트, 리스크 관리 에이전트, 포트폴리오 관리 에이전트 등 여러 전문 에이전트와 함께 작동하여 복잡한 트레이딩을 수행합니다....
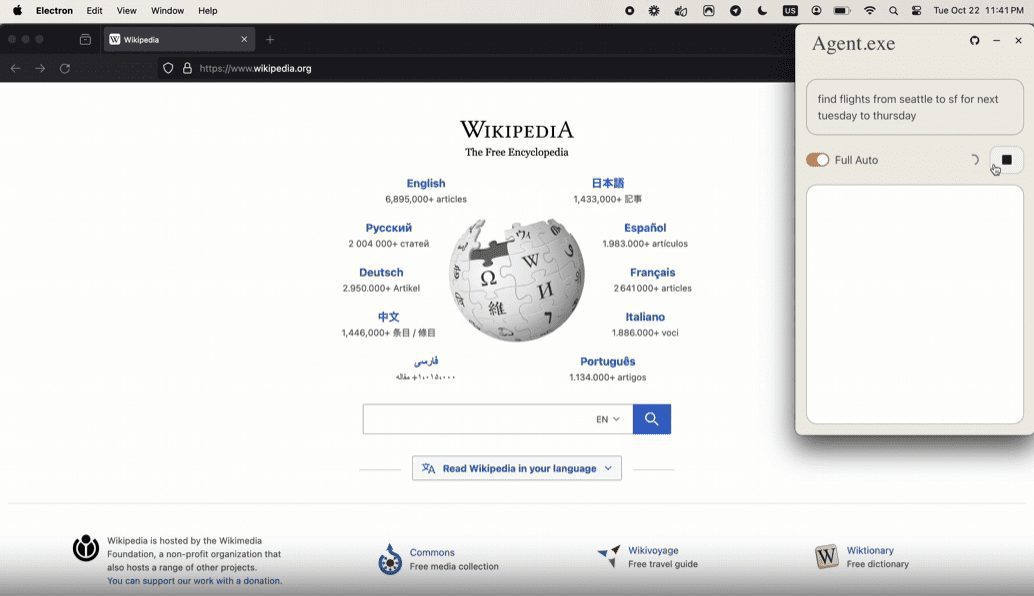
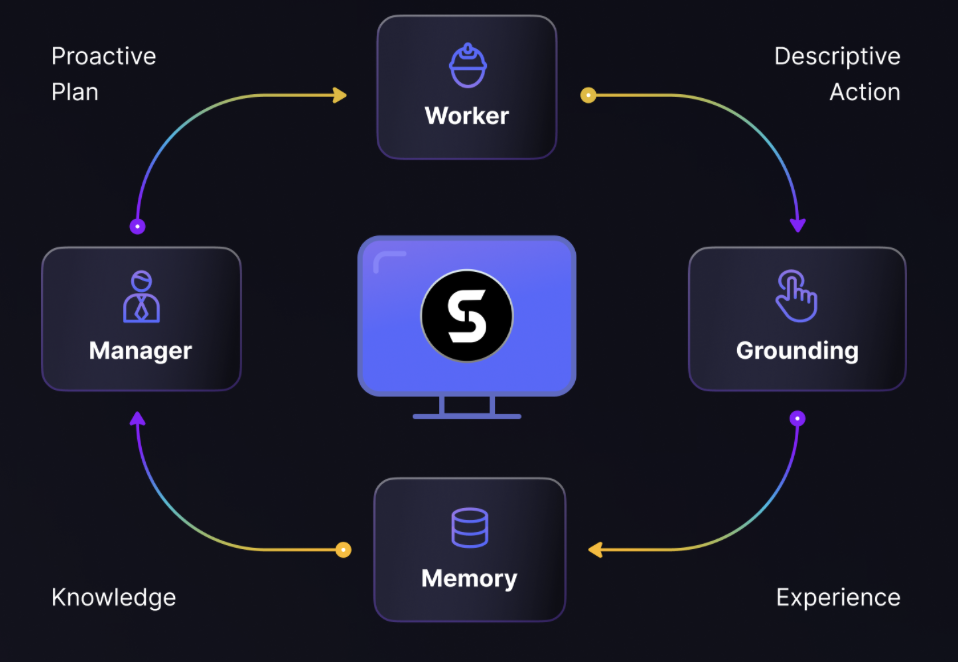
일반 소개 에이전트 S는 Simular AI에서 개발한 오픈 소스 프레임워크로, 그래픽 사용자 인터페이스(GUI)를 통해 인간처럼 컴퓨터를 조작할 수 있는 인공지능입니다. 멀티모달 대규모 언어 모델과 경험적 학습 기법을 사용하여 웹 검색, 문서 편집, 소프트웨어 사용 등의 작업을 수행합니다.
일반 소개 Langfuse는 오픈 소스 LLM(대규모 언어 모델) 엔지니어링 플랫폼입니다. 이 플랫폼은 호출 관찰, 단서 단어 관리, 실험 실행 및 결과 평가를 위한 도구를 제공하여 개발자가 LLM 애플리케이션을 추적, 디버그 및 최적화하는 데 도움을 줍니다. 이 플랫폼은 Langfuse 팀이 개발했습니다...
종합 소개 MaxKB(Max Knowledge Base)는 대규모 언어 모델과 RAG(검색 증강 생성)를 기반으로 하는 오픈 소스 지식 기반 Q&A 시스템입니다. 이 시스템은 지능형 고객 서비스, 기업 내부 지식 기반, 학술 연구 및 교육 및 기타 시나리오에서 널리 사용됩니다.MaxKB...
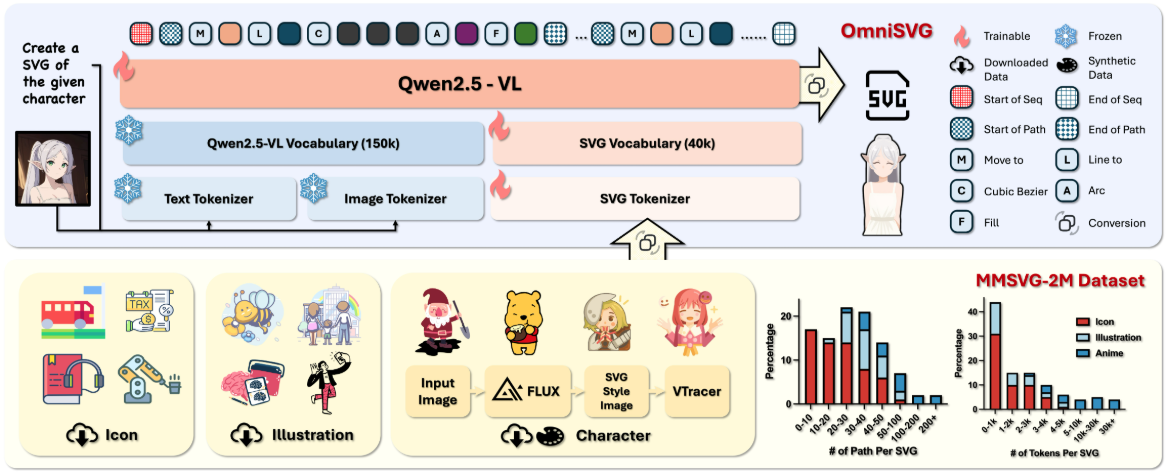
일반 소개 OmniSVG는 멀티모달 모델을 통해 고품질 벡터 그래픽(SVG)을 생성하는 데 중점을 둔 오픈 소스 프로젝트입니다. 사전 학습된 시각 언어 모델을 사용하여 텍스트 설명이나 이미지 입력에서 SVG 생성을 지원하며, 간단한 아이콘부터 복잡한 애니메이션 캐릭터까지 다양한 시나리오를 다룹니다. 항목 ...
일반 소개 Mem0("mem-zero"로 발음)는 AI 어시스턴트와 에이전트를 위한 지능형 메모리 계층을 제공하는 오픈 소스 프로젝트입니다. 사용자 선호도를 기억하고, 개인의 필요에 맞게 조정하며, 시간이 지남에 따라 개선되므로 고객 지원 챗봇, AI 비서 및 자율 시스템에 이상적입니다.
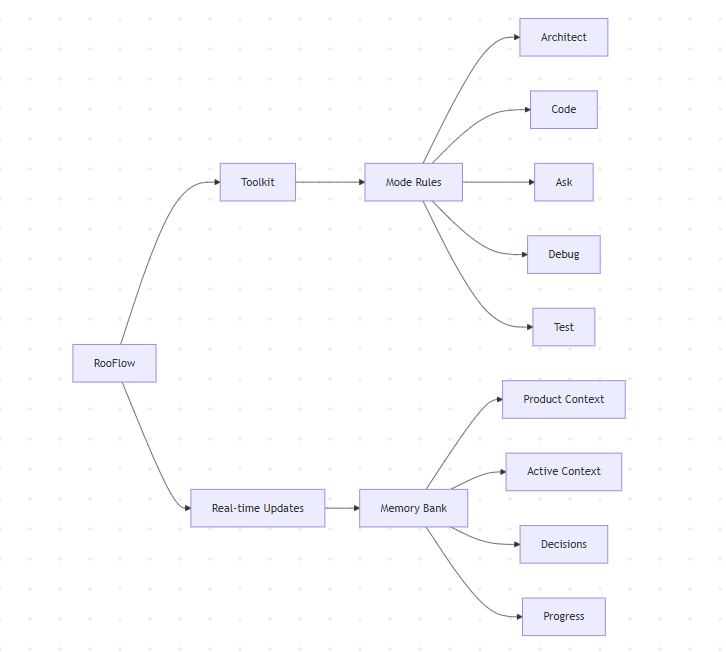
포괄적인 소개 RooFlow는 프로젝트 로깅을 통해 개발 중 코드, 의사 결정 및 작업 진행 상황을 보존하는 핵심 기능을 갖춘 오픈 소스 AI 지원 프로그래밍 도구입니다. Roo Code 확장을 기반으로 하며 아키텍처, 코딩, 테스트, 디버깅, Q&A의 다섯 가지 모드를 통합합니다. 이러한 모드는 상호 ...
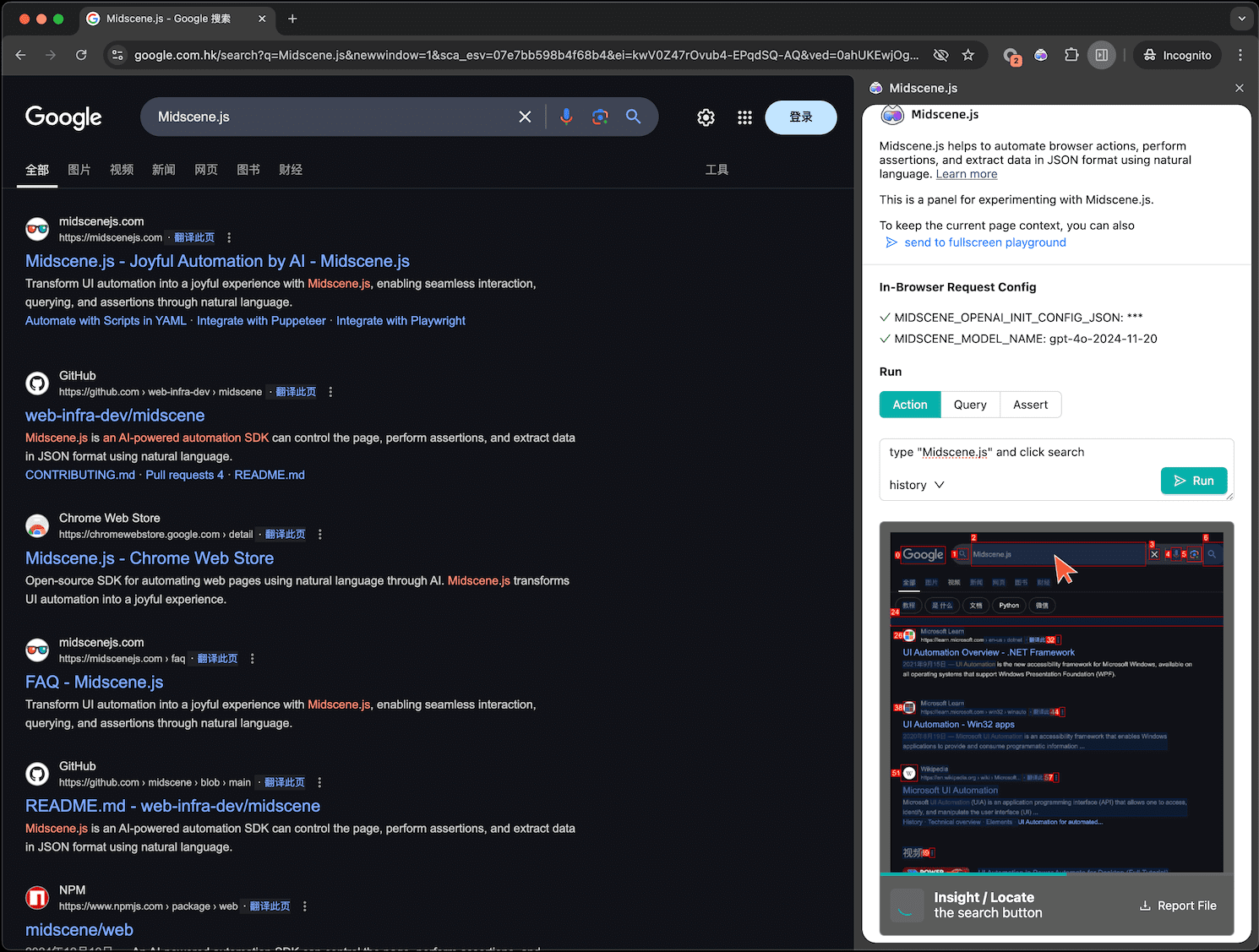
일반 소개 Midscene.js는 자연어 명령을 통해 웹 페이지를 제어하고, 어설션을 수행하고, 데이터를 추출하는 AI 기반 브라우저 자동화 도구입니다. 이 도구는 Chrome 확장 프로그램, JavaScript SDK 및 YAML 스크립트를 지원하여 UI 측정을 간소화합니다.
종합 소개 RF-DETR은 Roboflow 팀에서 개발한 오픈 소스 객체 감지 모델입니다. 트랜스포머 아키텍처를 기반으로 하며 핵심 기능은 실시간 효율성입니다. 이 모델은 처음으로 Microsoft COCO 데이터 세트에서 60개 이상의 실시간 AP를 달성했습니다....
일반 소개 TRV는 사용자가 슬라이드와 프레젠테이션 노트를 내레이션이 있는 동영상으로 빠르게 변환할 수 있도록 설계된 오픈 소스 도구로, GitHub에서 호스팅됩니다. 간단한 명령줄 작업을 통해 입력된 프레젠테이션 파일에서 오디오 및 비디오 콘텐츠를 자동으로 생성하며, 프레젠테이션을 빠르게 만들어야 하는 사용자에게 적합합니다.
일반 소개 VITA는 선도적인 오픈 소스 대화형 대규모 언어 모델링 프로젝트로, 진정한 완전한 멀티모달 상호 작용을 구현하는 기능을 개척하고 있습니다. 이 프로젝트는 2024년 8월에 VITA-1.0을 출시하여 최초의 오픈 소스 대화형 완전 모달 대규모 언어 모델을 개척했습니다.2024...
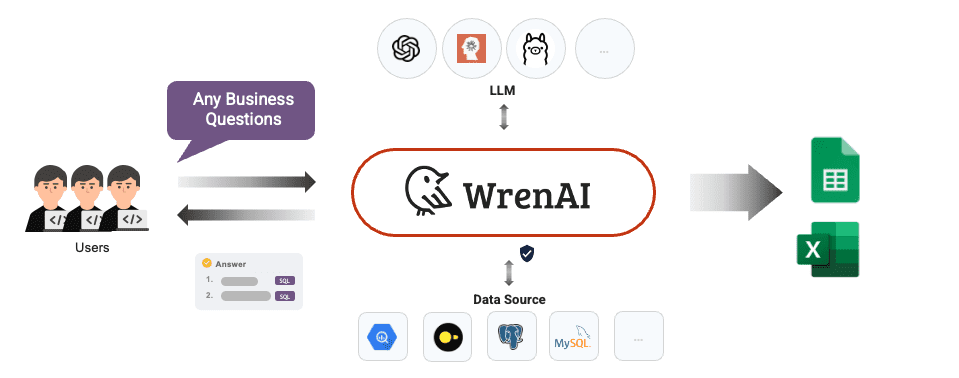
일반 소개 WrenAI는 데이터 팀, 제품 팀, 비즈니스 팀이 자연어 대화를 통해 데이터 인사이트를 얻을 수 있도록 특별히 설계된 오픈 소스 SQL AI 어시스턴트입니다. 자연어를 SQL 쿼리로 변환하고, 차트, 스프레드시트 및 보고서를 생성하고, 다국어를 지원할 수 있습니다.
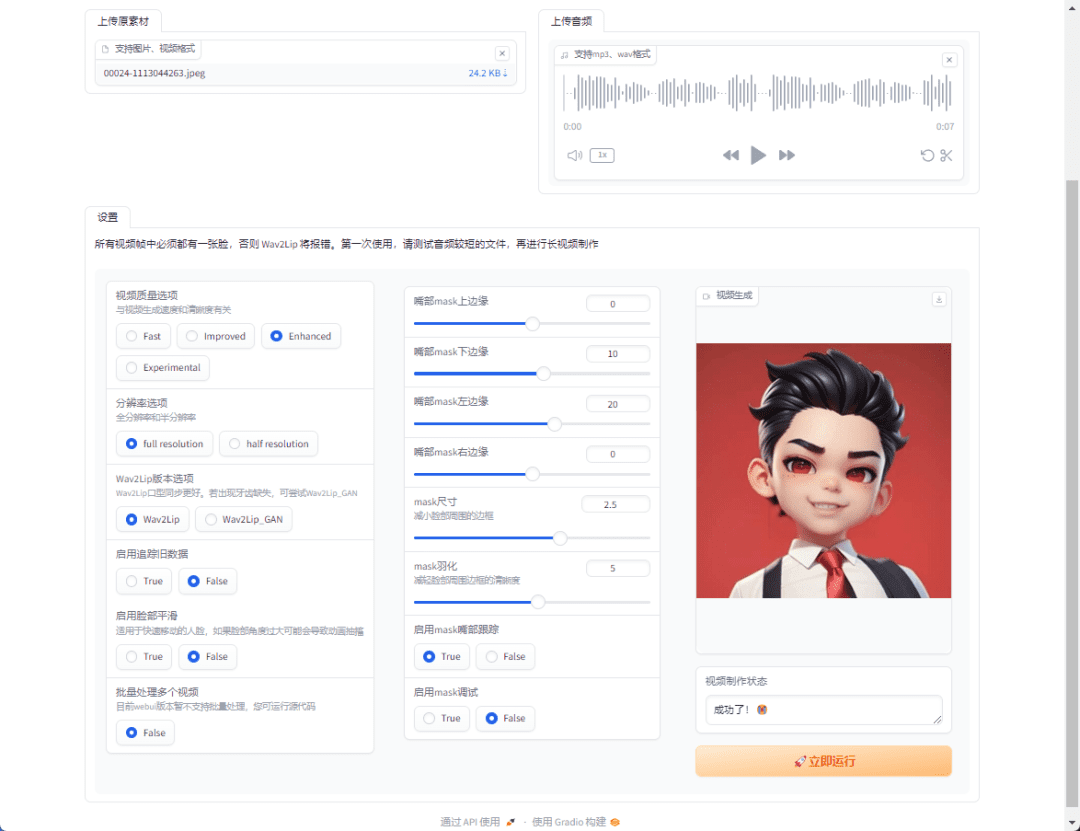
일반 소개 LiteAvatar는 HumanAIGC 팀(Ali의 일부)이 개발한 오픈 소스 도구로, 오디오로 구동되는 2D 아바타에서 실시간으로 얼굴 애니메이션을 생성하는 데 중점을 두고 있습니다. CPU에만 의존하여 초당 30프레임(fps)으로 실행되며, 특히 다음과 같은 경우에 적합합니다.
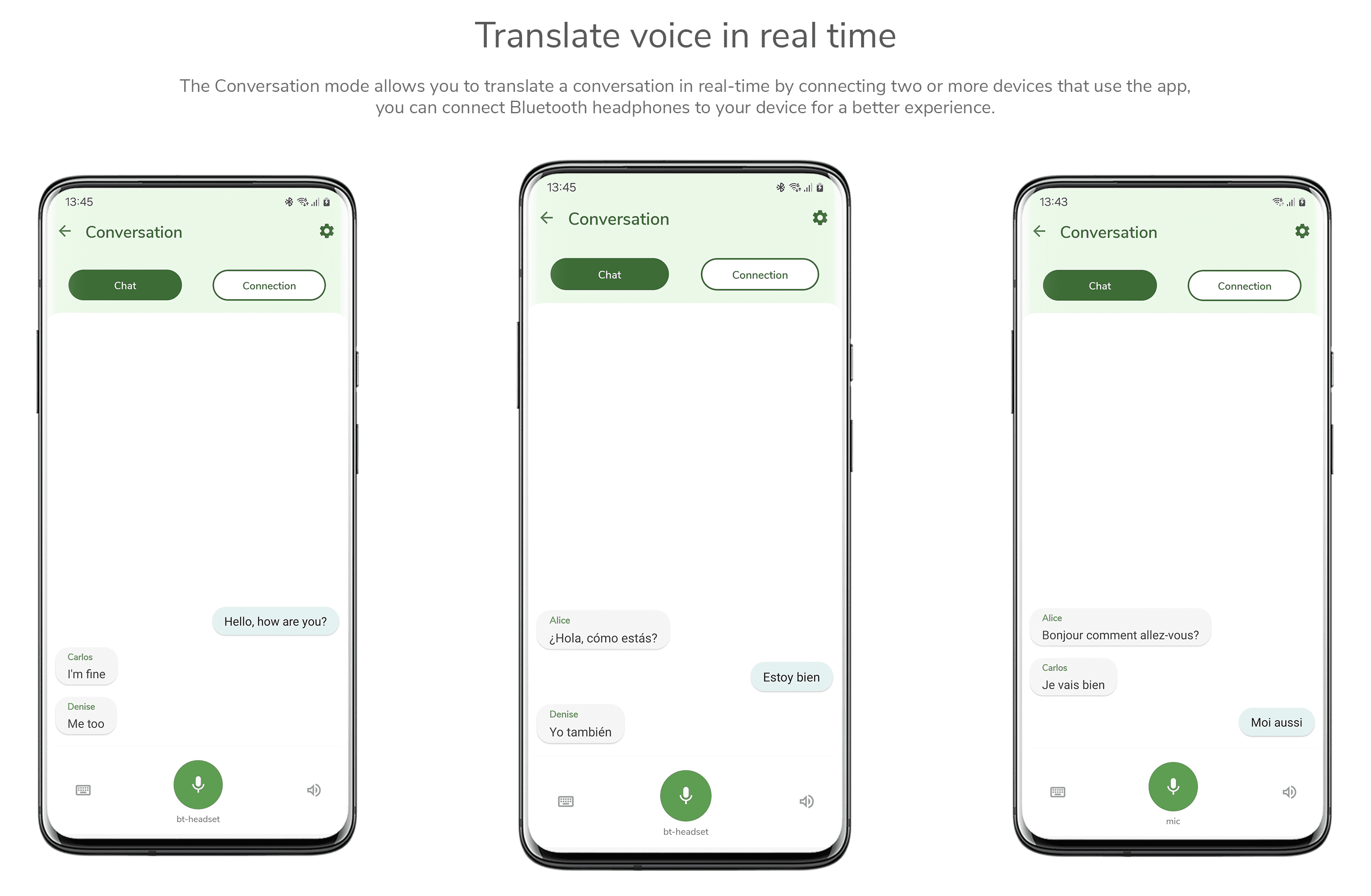
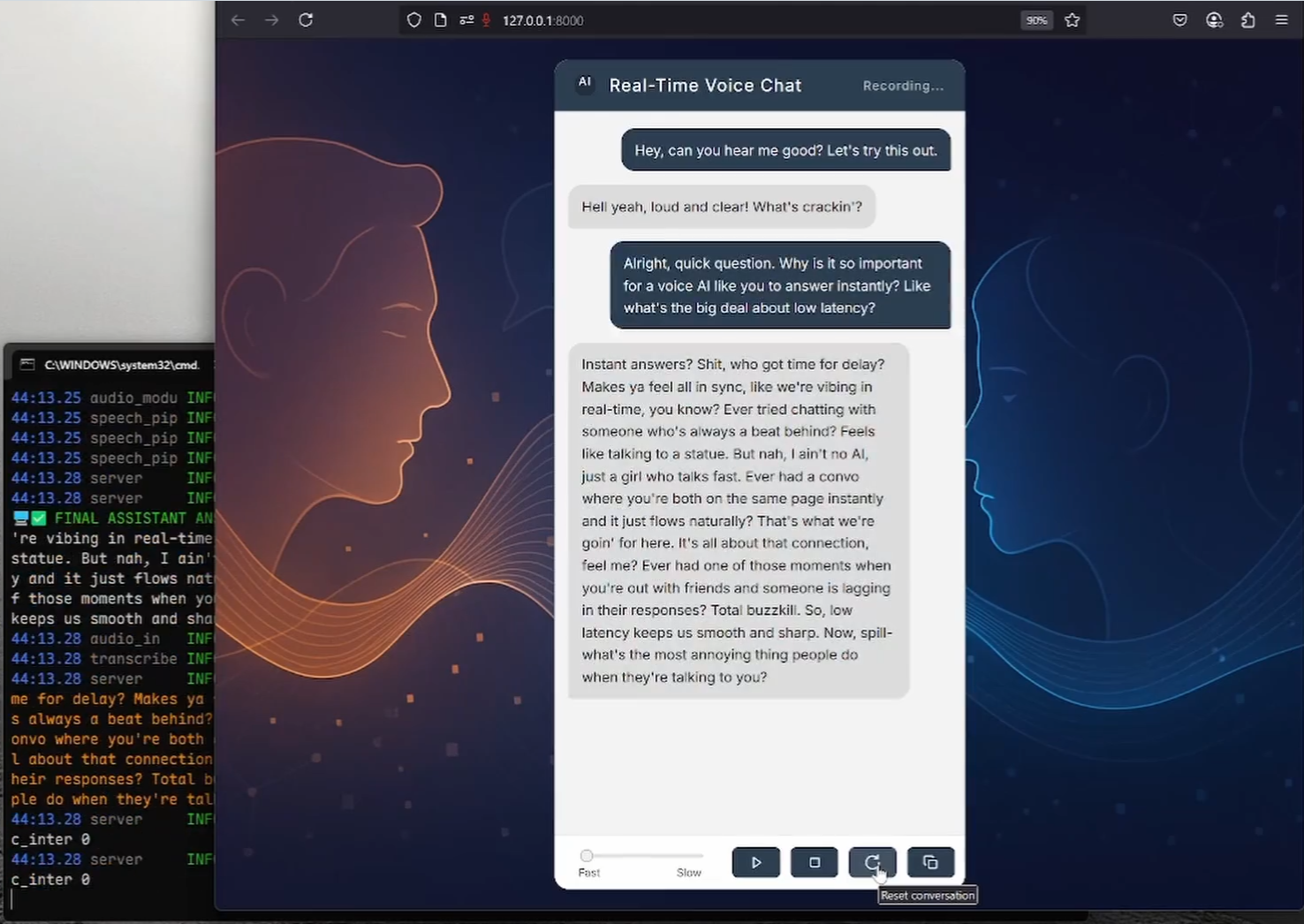
일반 소개 리얼타임보이스챗은 음성을 통한 인공 지능과의 실시간 자연스러운 대화에 초점을 맞춘 오픈 소스 프로젝트입니다. 사용자가 마이크를 사용하여 음성을 입력하면 시스템이 브라우저를 통해 오디오를 캡처하여 텍스트로 빠르게 변환하고 대규모 언어 모델(LLM)을 생성하여 다시 ...
종합 소개 Wan2.1은 Wan-Video 팀이 개발하고 GitHub에서 오픈소스로 제공하는 동영상 생성 도구 모음으로, 인공지능 기술을 통해 동영상 제작의 경계를 넓히는 데 중점을 두고 있습니다. 이 도구는 시간에 따라 변하는 고유한 자기 변환을 통합하는 고급 확산 트랜스포머 아키텍처를 기반으로 합니다.
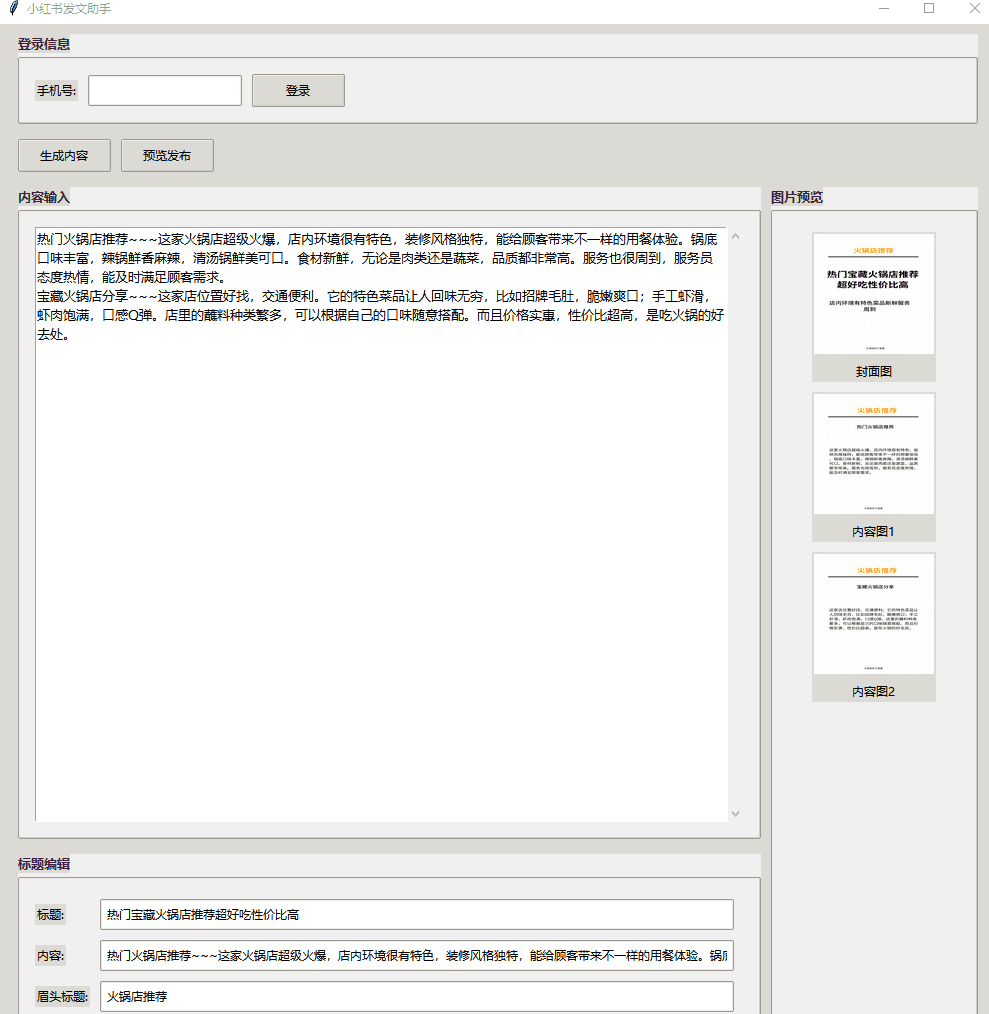
종합 소개 샤오홍슈 AI 운영 도우미(xhsaipublisher)는 샤오홍슈 플랫폼에 기사를 게시하기 위해 설계된 자동화 도구입니다. 이 프로젝트는 그래픽 사용자 인터페이스와 자동화 스크립트를 결합하여 빅 모델 기술을 사용하여 콘텐츠를 생성하고 브라우저를 통해 자동으로 로그인하고 게시할 수 있습니다.
종합 소개 R2R(RAG to Riches)은 프로덕션에 바로 사용할 수 있는 기능을 갖춘 검색 증강 생성(RAG) 기능을 지원하는 고급 AI 검색 시스템입니다. 컨테이너화된 RESTful API를 기반으로 구축된 이 시스템은 멀티모달 콘텐츠 구문 분석, 하이브리드 검색 기능 등을 제공합니다.
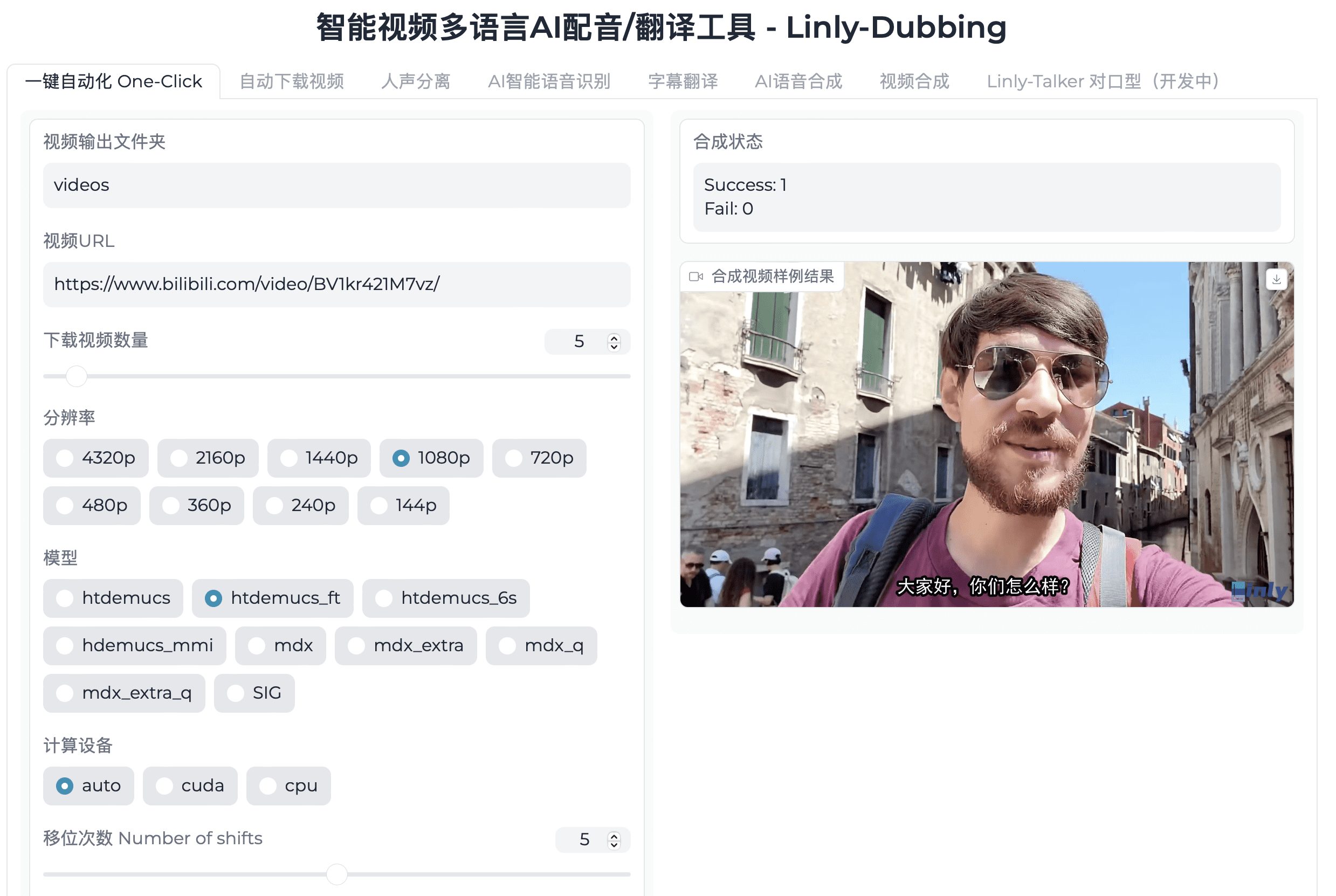
종합 소개 Linly-Dubbing은 고급 AI 기술을 통합하여 사용자에게 고품질의 다국어 동영상 더빙 및 자막 번역 서비스를 제공하도록 설계된 지능형 다국어 AI 더빙 및 번역 도구입니다. 이 도구는 특히 국제 교육, 글로벌 콘텐츠 로컬라이제이션 및 기타 시나리오에 적합하며 다음을 지원합니다.
일반 설명 SynthLight는 확산 모델에 기반한 인물 사진 재조명 도구입니다. 합성 얼굴 이미지를 다시 렌더링하여 실제 인물 사진에 조명 효과를 조정하는 방법을 학습합니다. 이 도구는 물리적 렌더링 엔진을 사용하여 다양한 조명 조건에서 조명 변환을 시뮬레이션하는 데이터 세트를 생성합니다....
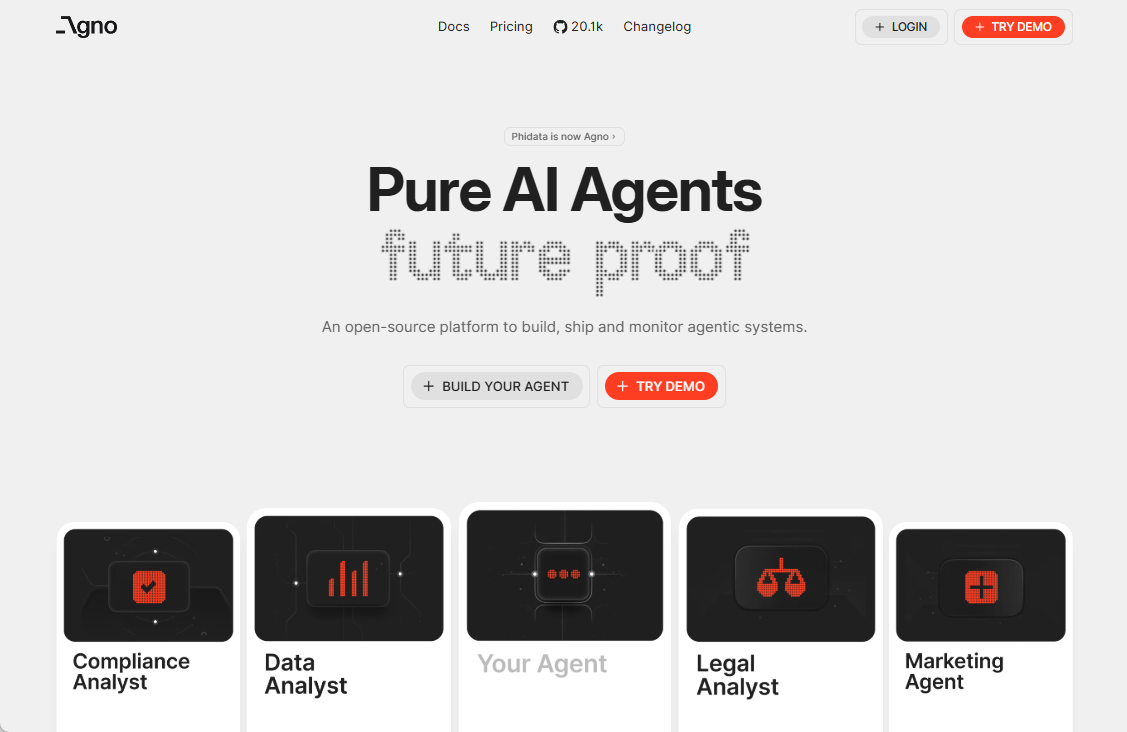
일반 소개 Agno는 개발자가 메모리, 지식 및 도구를 사용하여 AI 인텔리전스를 쉽게 구축할 수 있도록 지원하기 위해 agno-agi 팀이 개발하고 GitHub에서 호스팅하는 오픈 소스 Python 라이브러리입니다. 멀티모달 텍스트, 이미지, 오디오, 비디오를 지원합니다.
포괄적인 소개 n8n 셀프 호스팅 AI 스타터 키트는 포괄적인 로컬 AI 및 로우코드 개발 환경을 빠르게 초기화하도록 설계된 오픈 소스 Docker Compose 템플릿입니다. n8n 팀에서 제작한 이 제품군은 자체 호스팅 n8n 플랫폼과 다양한 호환 가능한 AI를 결합합니다.
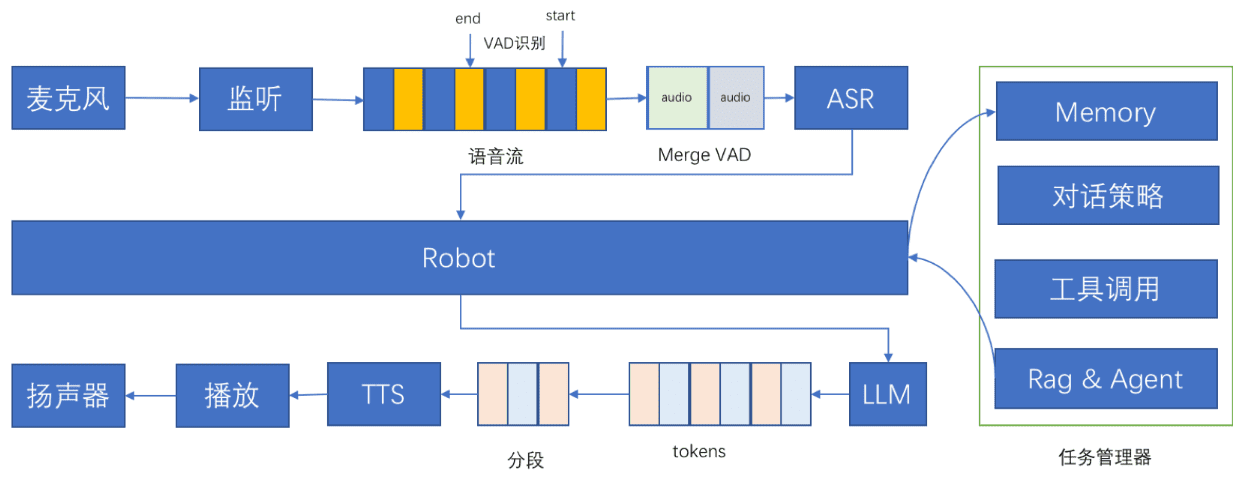
개요 Bailing(베일링)은 음성을 통해 사용자와 자연스럽게 대화할 수 있도록 설계된 오픈 소스 음성 대화 어시스턴트입니다. 이 프로젝트는 음성 인식(ASR), 음성 활동 감지(VAD), 대규모 언어 모델링(LLM) 및 음성 합성(TTS) 기술을 결합하여 다음과 같은 목표를 달성합니다.
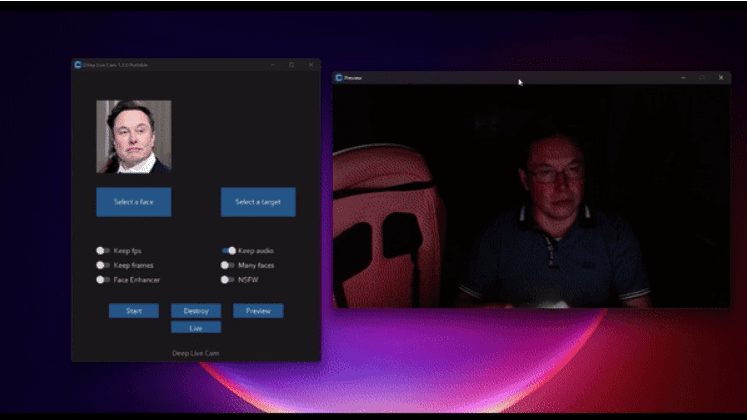
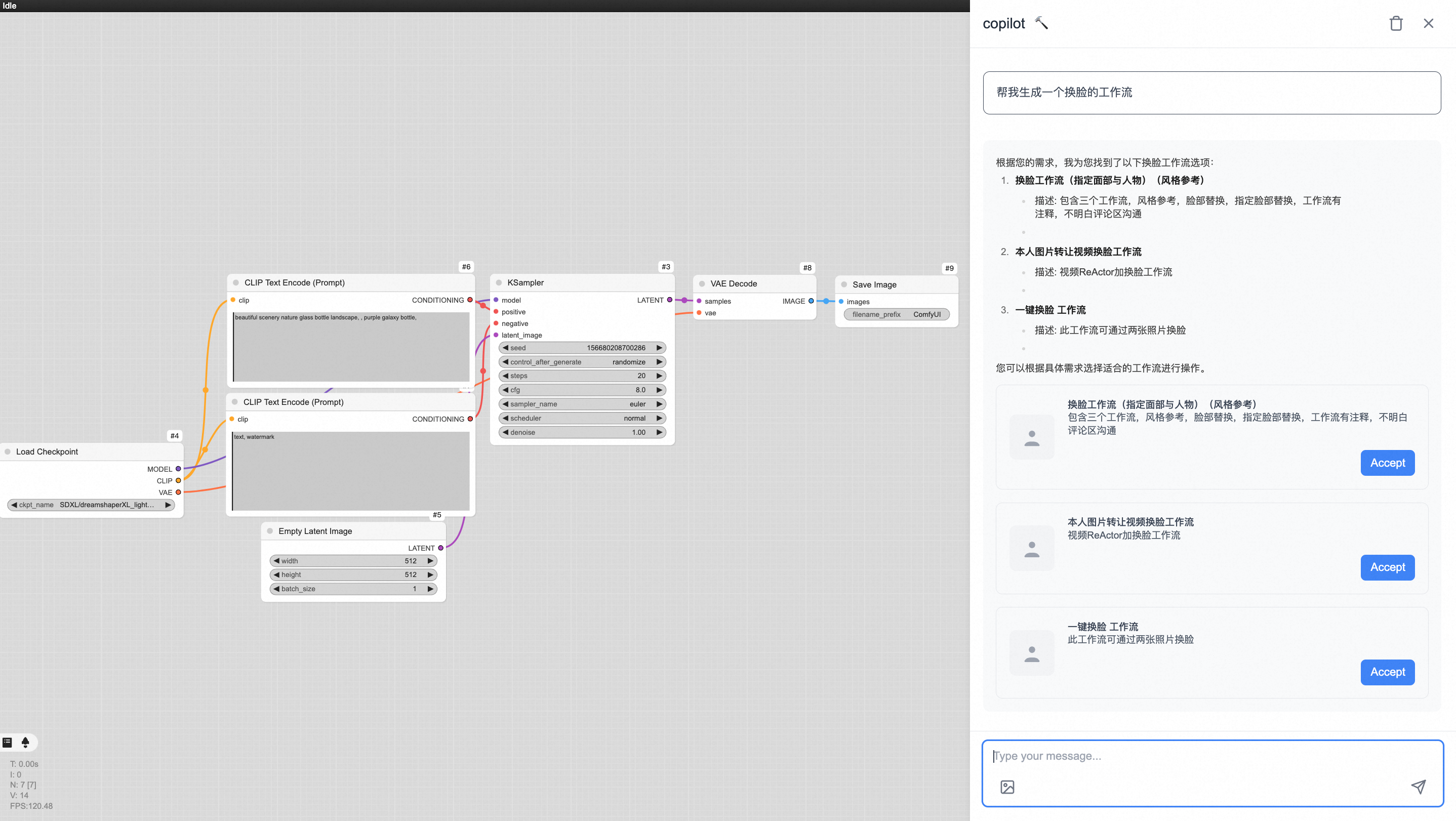
일반 소개 딥 라이브 캠은 한 장의 사진으로 실시간 얼굴 교체 및 딥 페이크 비디오 생성을 가능하게 하는 오픈 소스 인공 지능 도구입니다. 이 도구는 고급 딥러닝 알고리즘을 사용하여 라이브 스트리밍 또는 영상 통화 중에 실시간으로 얼굴을 교체하여 사용자의 개인 정보를 보호하고 재미를 더할 수 있습니다.
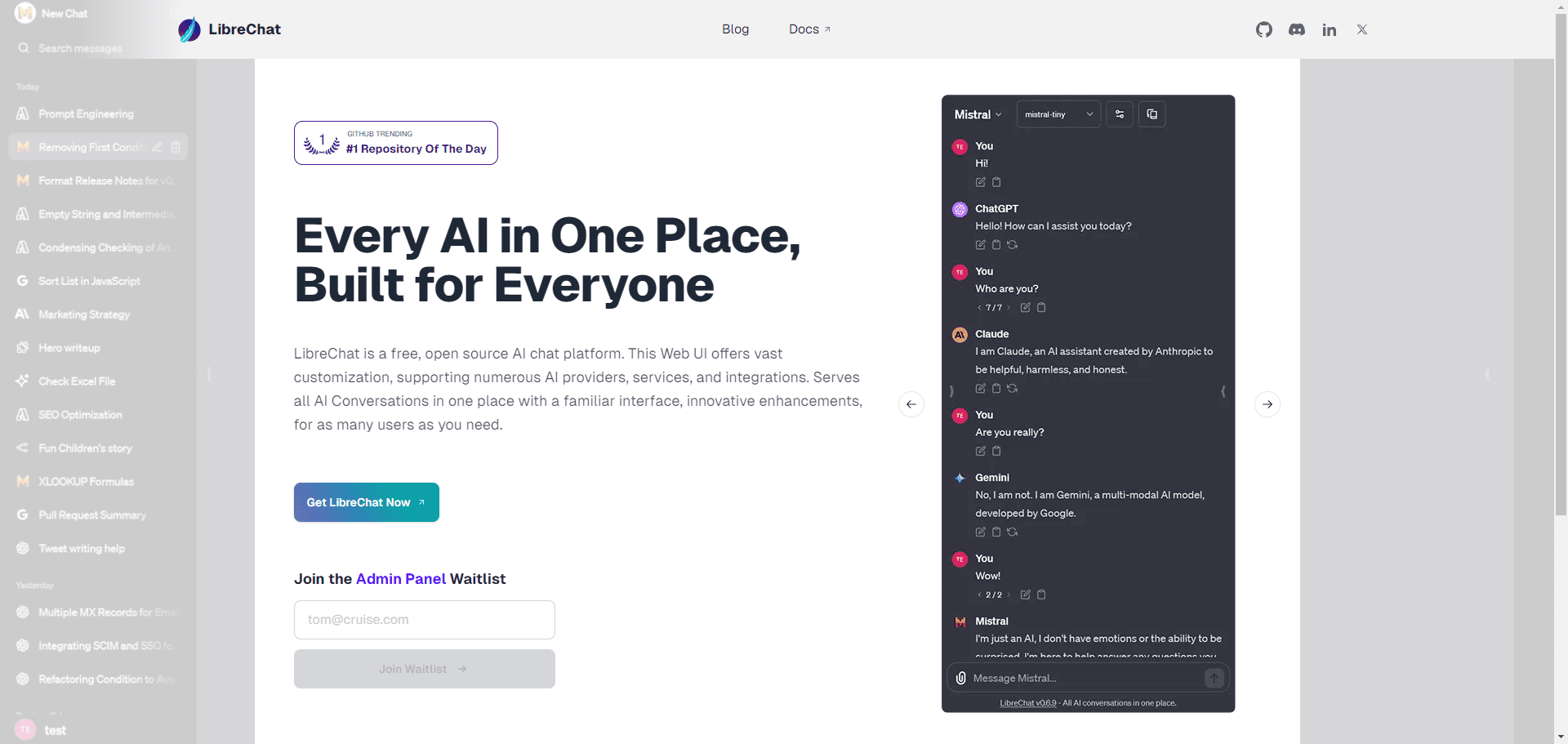
일반 소개 LibreChat은 다양한 사용자 지정 옵션과 여러 AI 제공업체, 서비스 및 통합을 지원하는 무료 오픈 소스 AI 채팅 플랫폼입니다. 친숙한 인터페이스와 혁신적인 기능으로 모든 AI 대화를 한곳에 모아 여러 AI 모델, 플러그인 및 여러 언어를 지원합니다. 작성자...
개요 스몰에이전트는 HuggingFace에서 개발한 경량 지능형 에이전트 라이브러리로, AI 에이전트 시스템의 개발 프로세스를 간소화하는 데 중점을 두고 있습니다. 이 프로젝트는 핵심 코드가 약 1000줄에 불과할 정도로 설계 철학이 단순하면서도 강력한 기능 통합 기능을 제공하는 것으로 유명합니다. 그것은 가장 ...
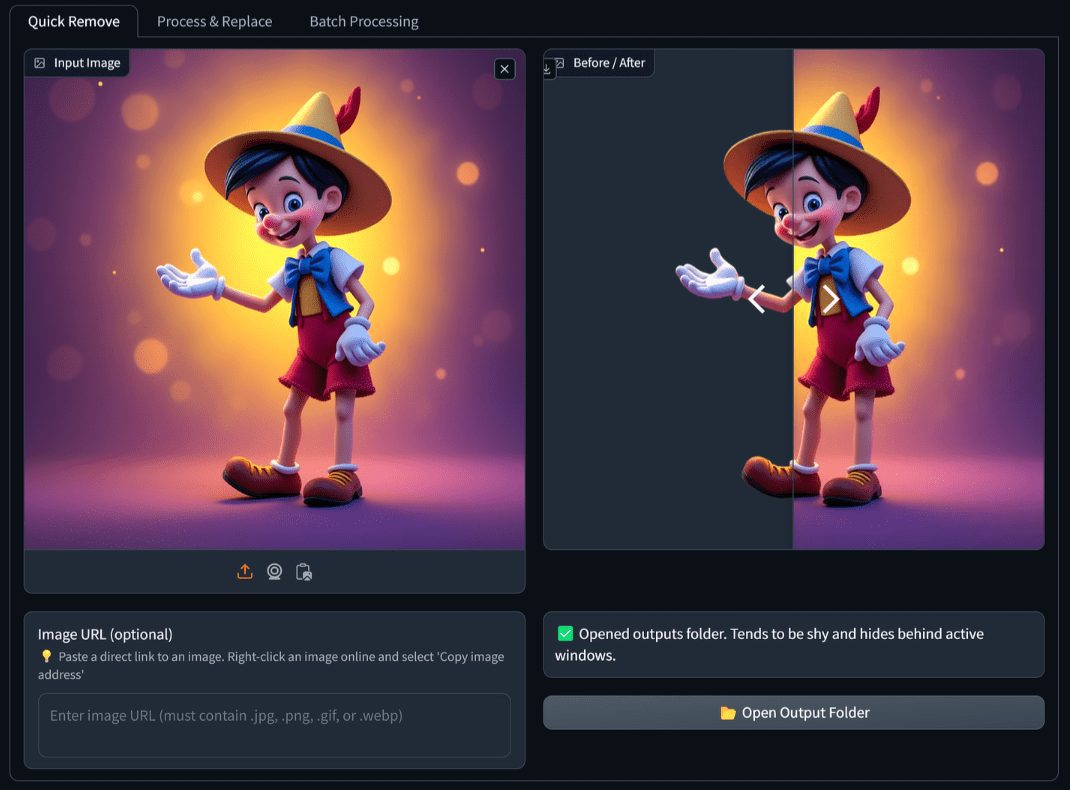
일반 소개 RMBG-2-Studio는 BRIA-RMBG-2.0 모델을 기반으로 개발된 향상된 배경 제거 및 교체 애플리케이션입니다. 이 애플리케이션은 사용자에게 전자상거래, 게임 등 다양한 이미지 유형에 대한 효율적이고 정확한 이미지 배경 처리 기능을 제공하도록 설계되었습니다.
포괄적인 소개 ComfyUI-Copilot은 자연어 상호 작용을 통해 AI 알고리즘 디버깅 및 배포의 효율성을 개선하는 것을 목표로 ComfyUI 프레임워크용으로 설계된 AI 기반 사용자 지정 노드입니다. AIDC-AI 팀(알리바바)이 개발했으며 GitHu에서 파생되었습니다.
일반 소개 CAD-MCP는 사용자가 도면 작업을 위한 자연어 명령을 통해 CAD 소프트웨어를 제어할 수 있는 오픈 소스 프로젝트입니다. 자연어 처리와 CAD 자동화 기술을 결합하여 사용자가 CAD 인터페이스를 수동으로 조작할 필요 없이 간단한 텍스트 명령어를 입력하기만 하면 됩니다.
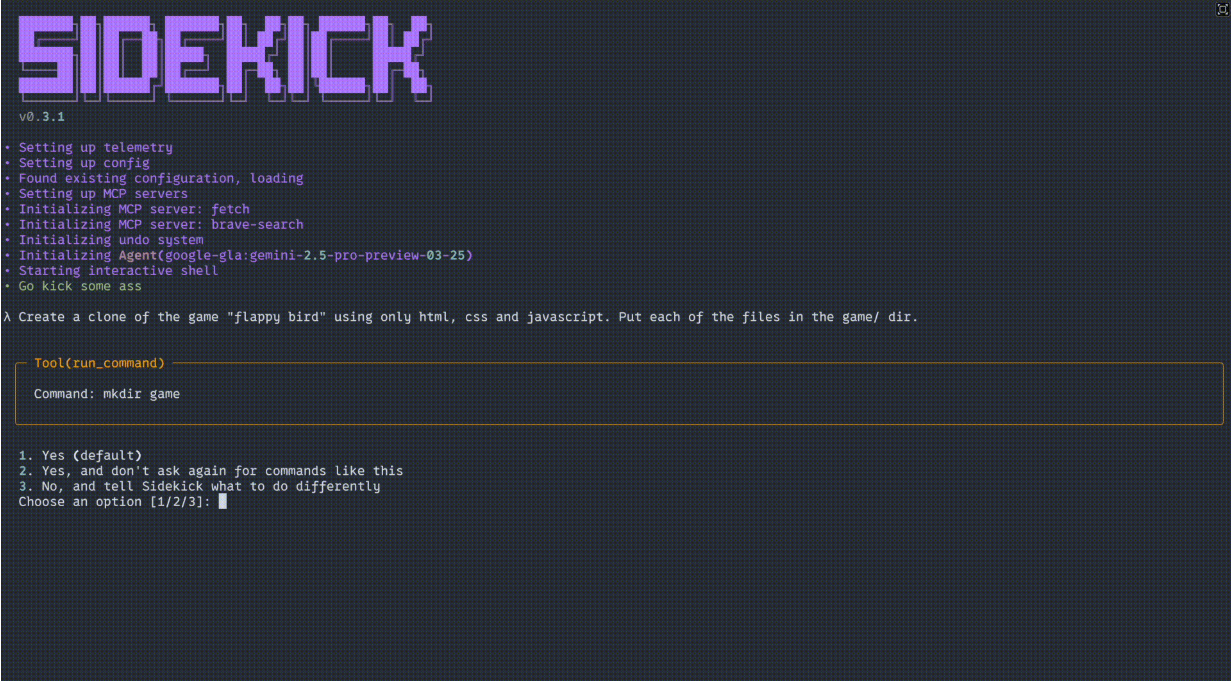
일반 소개 Goose는 개발자가 일상적인 개발 작업을 자동화할 수 있도록 설계된 블록에서 개발한 오픈 소스 AI 에이전트 도구입니다. 광범위한 LLM(대규모 언어 모델)을 지원하며 명령줄 또는 데스크톱 애플리케이션 인터페이스를 통해 사용자와 상호 작용하며, 에이전트에서 다양한 작업을 수행할 수 있습니다.
일반 소개 OpenAI Edge TTS는 OpenAI와 호환되는 네이티브 TTS(텍스트 음성 변환) API를 제공하는 오픈 소스 프로젝트로, 이 프로젝트는 Microsoft Edge의 온라인 텍스트 음성 변환 서비스를 사용하여 사용자가 고품질의 음성 변환을 생성할 수 있도록 합니다.
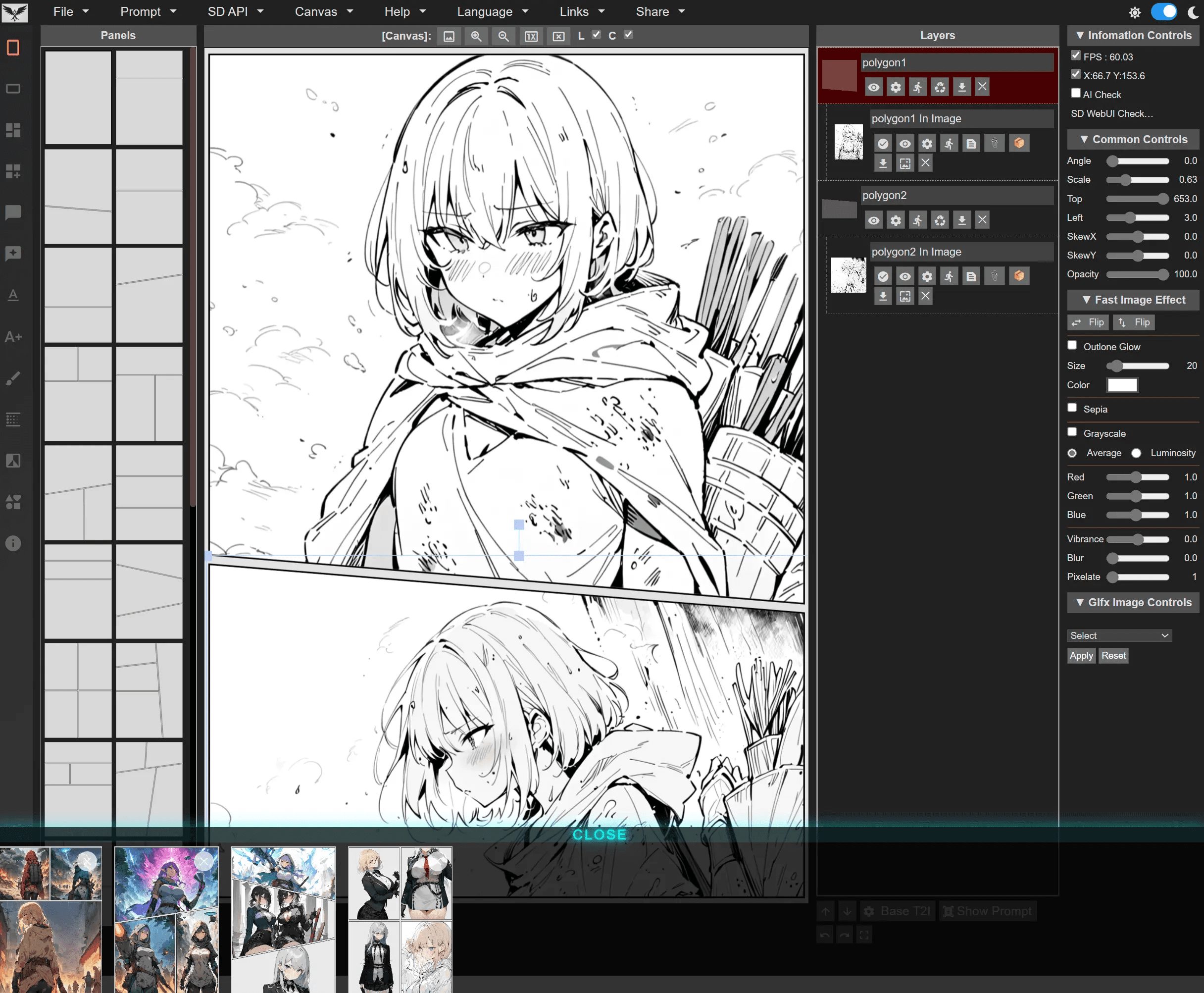
일반 소개 SP-MangaEditer는 만화 창작자를 위해 설계된 독립적인 만화 편집 플랫폼입니다. 이 플랫폼은 이미지 생성, 레이어 편집, 이미지 조정, 필터 적용 및 기타 여러 기능을 지원하여 사용자가 고품질의 만화 일러스트를 쉽게 만들 수 있도록 도와줍니다. 사용자는 간단하게 조작할 수 있습니다.
종합 소개 Dify-WebUI는 기업에 강력한 AI 대화 기능을 제공하도록 설계된 Dify API 기반의 최신 데스크톱 지능형 대화 애플리케이션입니다. 이 애플리케이션은 기업의 개별 요구 사항을 충족하기 위해 다양한 사전 설정 테마 색상을 지원하며 지식 기반 관리 기능을 통해 다음을 지원합니다.
종합 소개 로컬에서 실행되는 지능형 문서 처리 및 콘텐츠 생성 도구를 제공하는 것을 목표로 하는 오픈 소스 프로젝트인 Local-NotebookLM입니다. 이 프로젝트는 사용자가 PDF 및 기타 문서를 다양한 형태로 변환할 수 있도록 돕는 데 중점을 두고 있는 Google NotebookLM에서 영감을 받았습니다.
종합 소개 bilive는 B 방송국 라이브 녹화를 위해 설계된 도구로, 매우 빠른 라이브 녹화, 자동 슬라이싱, 팝업 렌더링 및 자막 생성을 제공합니다. 이 도구는 초저사양 머신과 호환되며, 7x24시간 무인 녹화를 지원하고, 팝업과 자막을 자동으로 식별하고 렌더링하며, 자동으로 슬라이싱하고...
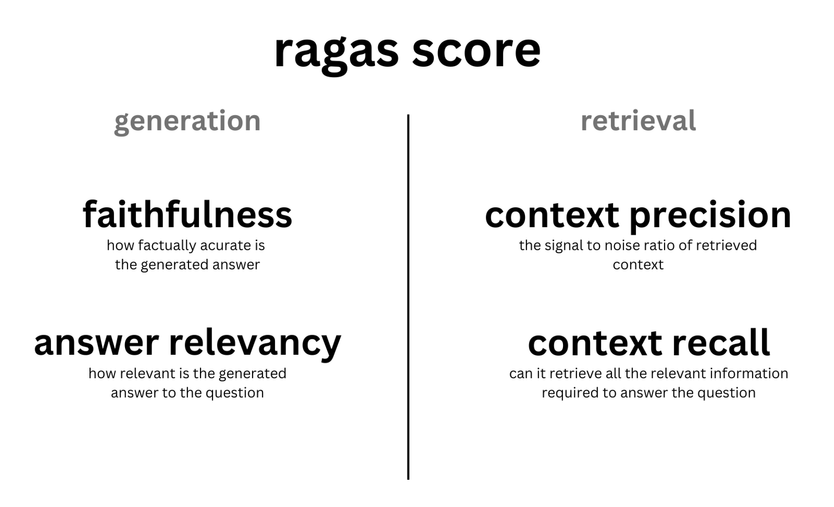
종합 소개 Ragas는 검색 증강 생성(RAG) 시스템을 평가하고 최적화하기 위해 특별히 고안된 도구입니다. 쿼리, 검색 컨텍스트, 생성된 답변 간의 관계를 분석하여 종합적인 평가 메트릭 세트를 제공합니다. 이러한 메트릭에는 충실도, 답변 관련성, 문맥 관련성 등이 포함됩니다.