
일반 소개
Spark-TTS는 사용자가 텍스트를 자연스럽고 부드러운 음성으로 효율적으로 변환할 수 있도록 설계된 오픈 소스 텍스트 음성 변환(TTS) 도구로, SparkAudio 팀이 개발하여 GitHub에서 호스팅하고 있습니다. 고급 딥러닝 기술을 기반으로 하며 여러 언어와 음성 스타일을 지원하며 개발자, 연구원 또는 콘텐츠 크리에이터에게 적합합니다. 사용 편의성과 고품질 음성 출력에 중점을 둔 이 프로젝트는 사전 학습된 모델과 사용자 지정 학습 옵션을 제공하여 사용자가 필요에 따라 음성 특성을 조정할 수 있습니다. 자세한 공식 문서는 없지만 GitHub 저장소의 코드와 커뮤니티 지원을 통해 사용자는 빠르게 시작하고 기능을 탐색할 수 있으며, 오픈 소스인 Spark-TTS의 특성상 음성 합성 분야, 특히 개인화된 음성 솔루션이 필요한 시나리오에서 유용한 리소스가 될 수 있습니다.

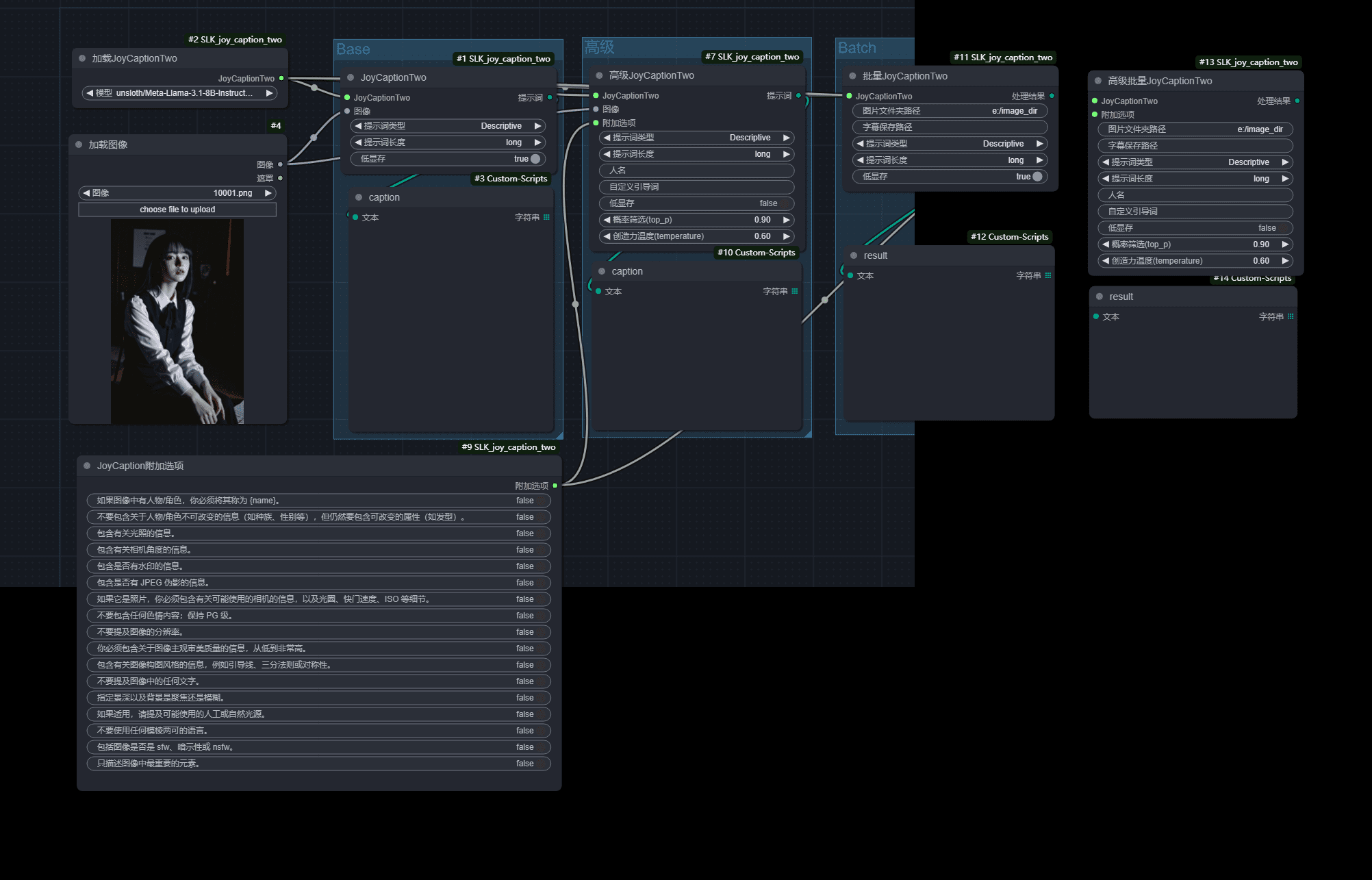
Spark-TTS 음성 생성 인터페이스

Spark-TTS 음성 복제 인터페이스
기능 목록
- 텍스트 음성 변환여러 언어를 지원하여 입력 텍스트를 자연스러운 음성으로 빠르게 변환합니다.
- 사전 학습된 모델 지원기성 모델이 제공되므로 사용자가 처음부터 학습할 필요 없이 음성을 생성할 수 있습니다.
- 맞춤형 음성 트레이닝사용자가 자신의 데이터 세트를 사용하여 음성 스타일이나 억양을 조정하여 모델을 훈련할 수 있습니다.
- 다양한 음성 스타일다양한 성별, 속도 및 음조의 음성 출력을 지원합니다.
- 오픈 소스 액세스사용자는 각자의 필요에 맞게 코드를 자유롭게 다운로드, 수정 및 최적화할 수 있습니다.
- 플랫폼 간 호환성범용 프로그래밍 환경을 기반으로 다양한 운영 체제에서 작동할 수 있도록 지원합니다.
도움말 사용
GitHub의 오픈 소스 프로젝트인 Spark-TTS는 독립형 설치 프로그램이나 그래픽 인터페이스가 없으며, 주로 특정 프로그래밍 기초가 있는 사용자를 대상으로 합니다. 다음은 처음부터 시작하여 기능을 최대한 활용할 수 있도록 도와주는 자세한 가이드입니다.
설치 프로세스
Spark-TTS는 GitHub 기반 코드 리포지토리이므로 리포지토리를 복제하고 환경을 구성하여 사용해야 합니다. 단계는 다음과 같습니다:
- 환경 준비
- 컴퓨터에 Python이 설치되어 있는지 확인합니다(권장 버전 3.8 이상).
- GitHub에서 코드를 다운로드하려면 Git을 설치합니다. Git 웹사이트에서 다운로드하여 설치할 수 있습니다.
- (선택 사항) 다음과 같은 가상 환경 도구 설치
virtualenv를 사용하여 프로젝트 종속성을 분리합니다.
- 클론 창고
- 터미널을 엽니다(Windows의 경우 CMD 또는 PowerShell, Mac/Linux의 경우 터미널).
- 다음 명령을 입력하여 Spark-TTS 리포지토리를 로컬로 복제합니다:
git clone https://github.com/SparkAudio/Spark-TTS.git - 복제가 완료되면 프로젝트 디렉토리로 이동합니다:
cd Spark-TTS
- 종속성 설치
- Spark-TTS는 일반적으로 딥 러닝 프레임워크(예: PyTorch 또는 TensorFlow)와 오디오 처리 라이브러리에 의존합니다. 다음에 대한 리포지토리를 확인하세요.
requirements.txt파일(있는 경우)을 열고 다음 명령을 실행하여 종속성을 설치합니다:pip install -r requirements.txt - 그렇지 않은 경우
requirements.txt일반적인 종속성에는 다음이 포함될 수 있습니다:pip install torch torchaudio numpy - 사용 중인 하드웨어(CPU 또는 GPU)에 따라 해당 버전의 PyTorch를 설치해야 하며, 공식 PyTorch 웹사이트를 참조하세요.
- Spark-TTS는 일반적으로 딥 러닝 프레임워크(예: PyTorch 또는 TensorFlow)와 오디오 처리 라이브러리에 의존합니다. 다음에 대한 리포지토리를 확인하세요.
- 설치 확인
- 프로젝트 디렉토리에 들어가면 간단한 테스트 스크립트를 실행합니다(리포지토리에서 제공한 경우). 예시:
python test.py - 오류가 보고되지 않으면 환경이 성공적으로 구성된 것입니다.
- 프로젝트 디렉토리에 들어가면 간단한 테스트 스크립트를 실행합니다(리포지토리에서 제공한 경우). 예시:
주요 기능
Spark-TTS의 핵심 기능은 텍스트를 음성으로 변환하는 것으로, 구체적인 작동 절차는 다음과 같습니다:
1. 사전 학습된 모델을 사용한 음성 생성
- 준비된 텍스트: 간단한 텍스트 파일을 만듭니다(예
input.txt), 변환할 텍스트를 입력합니다(예: "안녕하세요, 테스트 음성입니다."). - 스크립트 실행리포지토리가 다음과 같이 제공한다고 가정합니다.
generate.py스크립트(정확한 파일 이름은 실제 리포지토리를 기반으로 함)를 터미널에 입력합니다:python generate.py --input input.txt --output output.wav
- 매개변수 설명::
--input: 입력 텍스트 파일 경로를 지정합니다.--output: 생성된 음성 파일을 저장할 경로를 지정합니다(예output.wav).- 스크립트에서 지원하는 경우 다음을 추가합니다.
--model매개 변수는 사전 학습된 모델을 선택하거나--voice매개변수를 사용하여 사운드 스타일을 조정할 수 있습니다.
- 결국실행 후, 생성된 것을 찾을 수 있습니다.
output.wav파일을 오디오 플레이어로 열어 효과를 들어보세요.
2. 맞춤형 모델 교육
- 데이터 집합 준비하기텍스트와 해당 오디오 데이터를 제공해야 합니다. 데이터 형식은 일반적으로
.txt문서(텍스트) 및.wav파일(오디오)에 대한 저장소를 참조하는 것이 좋습니다.README.md또는 예제 폴더로 이동합니다. - 구성 매개변수구성 파일 편집 (아마도
config.json또는 유사한 파일)에서 학습 속도, 배치 크기 등과 같은 학습 파라미터를 설정합니다. 구성 파일이 없는 경우 스크립트에서 직접 파라미터를 수정합니다. - 프라이밍 교육: 예를 들어 교육 스크립트를 실행합니다:
python train.py --data_path ./dataset --output_model my_model - 교육 과정데이터의 양과 하드웨어 성능에 따라 훈련에는 몇 시간 또는 며칠이 걸릴 수 있습니다. 학습이 완료되면 새 모델 파일(예
my_model.pth). - 새 모델 사용: 학습된 모델 경로를 생성 스크립트에 전달합니다:
python generate.py --input input.txt --model my_model.pth --output custom_output.wav
3. 음성 스타일 조정
- Spark-TTS가 다중 스타일 출력을 지원하는 경우(코드나 설명서를 확인해야 함) 매개변수를 통해 말하기 속도, 피치 등을 조정할 수 있습니다. 예시:
python generate.py --input input.txt --speed 1.2 --pitch 0.8 --output styled_output.wav - 매개변수 설명::
--speed말하기 속도, 1.0은 정상, 1.0보다 크면 빠름, 1.0보다 작으면 느림.--pitch피치, 값이 높을수록 피치가 높아지고 그 반대도 마찬가지입니다.
- 효과 검증생성 후 오디션을 보고 만족할 때까지 점차적으로 매개변수를 조정합니다.
운영 프로세스 예시
중국어 텍스트를 여성 음성으로 변환하고 싶다고 가정해 보겠습니다:
- 설정
test.txt"날씨가 좋으니 공원에 산책하러 가자"라는 글을 남겼습니다. - 실행 명령을 실행합니다:
python generate.py --input test.txt --voice female --output park.wav - 프로브
park.wav를 클릭하고 음성이 자연스럽고 부드러운지 확인합니다. - 만족스럽지 않은 경우 매개변수를 조정하거나 새 모델을 학습시키세요.
주의
- 문서 참조창고의 우선 순위 보기
README.md설치 및 사용 지침은 내부에 더 구체적으로 나와 있을 수 있습니다. - 하드웨어 요구 사항생성 및 학습에는 GPU 가속이 필요할 수 있으며, GPU를 사용할 수 없는 경우 CPU에서 실행할 수 있지만 속도가 느립니다.
- 커뮤니티 지원문제가 발생하면 GitHub 이슈 페이지에서 질문하거나 Coqui TTS와 같은 유사한 TTS 프로젝트에서 해결 방법을 검색하세요.
위의 단계를 통해 음성 생성이나 전용 모델 커스터마이징 등 Spark-TTS를 쉽게 시작할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...