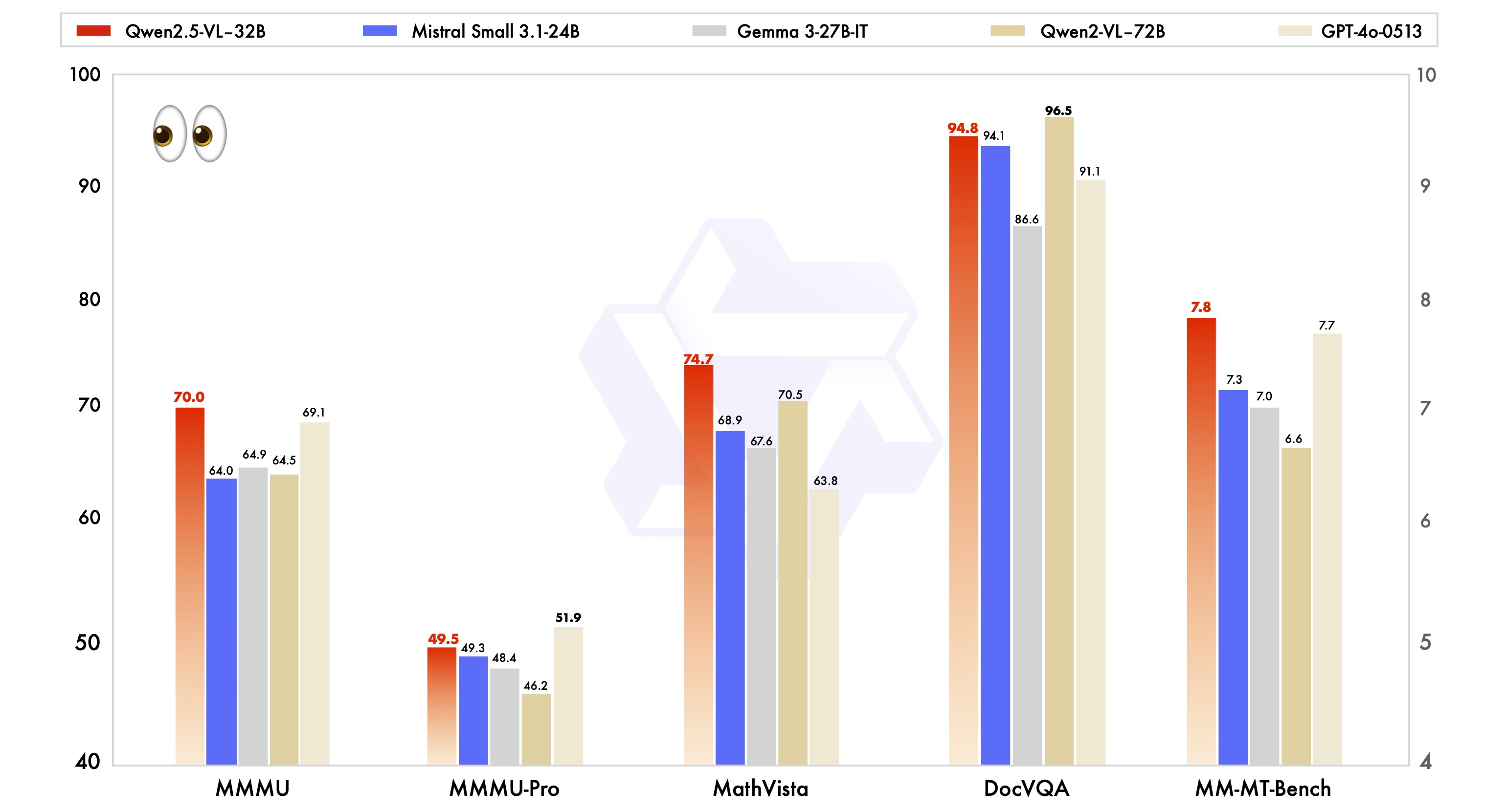

언어 모델(LM)은 AI 기술 혁신의 핵심 동력이 되었습니다. 사전 학습부터 실제 애플리케이션에 이르기까지 언어 모델은 일반 텍스트 데이터에 의존하여 작동합니다. 수조 건에 달하는 작업을 수행하든 토큰 수준의 학습을 수행하거나 데이터 집약적인 AI 애플리케이션을 지원하려면 텍스트 데이터의 품질이 매우 중요합니다. 품질이 낮은 텍스트 데이터는 학습 프로세스가 불안정하고 모델 성능이 저하될 뿐만 아니라 사용자가 요청할 때 최적의 결과물이 나오지 않을 수 있습니다.
그러나 언어 모델링에 필요한 모든 데이터가 웹 페이지와 같이 쉽게 구문 분석할 수 있는 형식으로 존재하는 것은 아닙니다. 실제로 많은 도메인에서 중요한 정보는 전자 문서 파일, 특히 PDF 형식에 저장되는데, 이는 원래 텍스트의 논리적 구조를 보존하기보다는 고정된 크기의 페이지에 콘텐츠를 표시하도록 설계되었기 때문에 데이터 처리에서 고유한 문제를 제기합니다. 예를 들어 PDF 형식은 텍스트를 일련의 문자 코드로 저장하고 페이지에서 각 문자의 위치 및 서식에 대한 정보를 기록합니다. 이 저장 방식은 매우 효율적이지만 제목, 단락, 표, 수식 등의 텍스트 단위를 복구하고 올바른 읽기 순서로 정렬하기가 매우 어렵습니다.

전자 문서를 더 잘 처리할 수 있도록 다음과 같은 기능을 소개합니다. olmOCRolmOCR은 PDF와 문서 이미지를 선명하고 구조화된 일반 텍스트로 변환하도록 설계된 고성능 툴킷으로, 다음과 같은 점에서 차별화됩니다:
뛰어난 성능
다음을 보장하기 위해 olmOCR 광범위한 문서에서 텍스트를 정확하게 추출하기 위해 개발팀은 다양한 출처의 250,000개의 PDF 페이지를 사용하여 모델을 미세 조정했습니다. 이러한 PDF 문서는 원본 디지털 문서와 공개 도메인 서적의 스캔 사본 등 다양한 출처에서 가져온 것입니다. 이렇게 다양한 데이터 세트 덕분에 olmOCR은 다양한 문서에서 뛰어난 성능을 유지할 수 있습니다.
매우 비용 효율적
PDF 문서 100만 페이지를 처리하는 데 드는 olmOCR 툴킷의 비용은 약 190달러로, GPT-4o API를 사용하여 같은 수의 페이지를 일괄 처리하는 비용의 약 1/32 수준입니다. 문서 처리에 대한 경제적 장벽을 크게 낮춥니다.
마크다운 형식 출력
olmOCR은 텍스트를 파싱 및 처리가 용이한 마크다운 형식으로 출력합니다. 수식, 표, 심지어 손글씨 콘텐츠까지 처리할 수 있으며 가장 복잡한 다중 열 문서 레이아웃도 올바른 읽기 순서로 출력됩니다.
즉시 사용 가능한 완벽한 기능
olmOCR은 완전히 최적화된 파이프라인으로 SGLang과 vLLM 추론 엔진은 함께 작동합니다. 단일 GPU에서 수백 개의 GPU로 확장할 수 있으며 일반적인 구문 분석 실패와 메타데이터 오류를 처리하는 휴리스틱이 내장되어 있습니다.
완전한 오픈 소스
olmOCR은 Qwen2-VL-7B-Instruct를 기반으로 구축되었습니다. 개발팀은 모델 가중치, 미세 조정된 데이터 세트, 학습 및 추론 코드 등 툴킷의 모든 구성 요소를 오픈 소스화했습니다.
다른 주요 문서 추출 도구와 olmOCR을 비교하고, olmOCR 빌드 프로세스에 대해 자세히 알아보려면 링크를 따라가세요. olmOCR을 사용해 볼 준비가 되셨다면, GitHub 리포지토리를 방문하여 프로젝트에서 olmOCR을 사용해 보세요!
대화형 도구 비교
샘플 문서를 비교함으로써 다른 주요 문서 추출 도구와 비교하여 olmOCR의 성능을 시각화할 수 있습니다. 아래 탭을 사용하여 다양한 도구의 출력을 확인하고 처리 품질의 주요 차이점에 대한 통찰력을 얻을 수 있습니다.



olmOCR 구축의 여정
기존의 OCR 기술은 레이아웃이 복잡한 PDF 문서를 처리할 때 많은 어려움을 겪습니다. 개발팀은 olmOCR을 학습시킬 고품질 데이터를 얻기 위해 다음과 같은 방법을 혁신적으로 개발했습니다. 문서 앵커링 PDF 파일에서 텍스트를 추출하는 기술입니다. 이 방법은 PDF 파일의 기존 텍스트와 메타데이터를 최대한 활용하여 텍스트 추출 품질을 크게 향상시킵니다.

그림 1: 일반적인 페이지에서 문서 앵커링 기법이 어떻게 작동하는지 보여줍니다. 관련 이미지 위치와 텍스트 블록이 추출되어 서로 연결되고 모델 프롬프트에 삽입됩니다. 앵커링된 텍스트는 VLM(시각 언어 모델) 다운로드에서 문서의 일반 텍스트 버전을 요청할 때 페이지의 래스터화된 이미지와 함께 사용됩니다.
개발팀은 문서 앵커링 기술의 도움으로 GPT-4o를 사용하여 250,000페이지를 마크업했습니다. 이 데이터 세트는 웹에서 크롤링한 공개적으로 사용 가능한 PDF 문서와 인터넷 아카이브에서 스캔한 공개 도메인 서적 등 다양한 출처에서 가져온 것입니다. 데이터 세트는 학술 논문 60%, 브로셔 12%, 법률 문서 11%, 차트 및 그래프 6%, 슬라이드 5%, 기타 문서 유형 4% 등 다양한 유형으로 구성되어 있습니다.
모델 학습을 위해 olmOCR 팀은 대규모 일괄 처리를 달성하고 추론 파이프라인을 최적화하기 위해 Qwen2-VL-7B-Instruct 체크포인트를 미세 조정하고 SGLang을 사용했습니다. 대규모 일괄 처리와 추론 파이프라인 최적화를 위해 SGLang을 사용했습니다. olmOCR은 GPT-4o API 비용의 1/32에 불과한 190달러로 100만 PDF 페이지를 변환할 수 있었습니다. 실험 결과에 따르면 olmOCR은 다른 유명 OCR 툴에 비해 비용을 크게 절감할 뿐만 아니라 수동 평가에서도 우수한 성능을 보여줍니다. 실험 결과에 따르면 olmOCR은 다른 인기 있는 OCR 도구에 비해 비용을 크게 절감할 뿐만 아니라 수동 평가에서도 우수한 성능을 보여줍니다.

그림 2: 다른 인기 도구와 비교한 olmOCR의 ELO 순위 박스 플롯.
연구팀은 olmOCR의 성능을 완전히 평가하기 위해 11명의 연구원을 초대하여 Marker, MinerU, GOT-OCR 2.0 등 다른 인기 있는 PDF 추출 도구와 비교했습니다. 2017년 PDF 문서에서 452개의 의미 있는 비교 세트를 수집하고 ELO 점수를 계산하여 성능을 정량화했습니다. 그 결과, olmOCR은 1800점 이상의 ELO 점수를 기록해 모든 경쟁 제품을 크게 앞질렀습니다. 다른 도구와 직접 비교한 결과, olmOCR은 61.3%를 기록했습니다. 마커 58.6%와 GOT-OCR의 비교에서, 그리고 MinerU 이 비율은 71.4%와 비교하면 훨씬 더 높은 수치로, 명확하고 잘 구조화된 텍스트를 생성하는 olmOCR의 탁월한 능력을 충분히 보여줍니다.
자세한 정보 및 기타 평가 결과는 기술 보고서에서 확인할 수 있습니다.
olmOCR 사용 방법
olmOCR의 첫 번째 버전에는 데모, 모델 가중치, 미세 조정된 데이터 세트, 간단한 기술 보고서, 그리고 가장 중요한 것은 효율적인 추론 파이프라인이 포함되어 있습니다.
GitHub 리포지토리를 방문하여 olmOCR을 설치하고 설명서를 검토하세요. 그런 다음 GPU가 있는 컴퓨터에서 다음 명령을 실행하기만 하면 됩니다:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf
개발팀은 조만간 더 나은 PDF 추출 모델을 개발하고 그 성능을 보다 효과적으로 평가할 수 있도록 더 많은 정량적 벤치마크를 공개할 예정입니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...