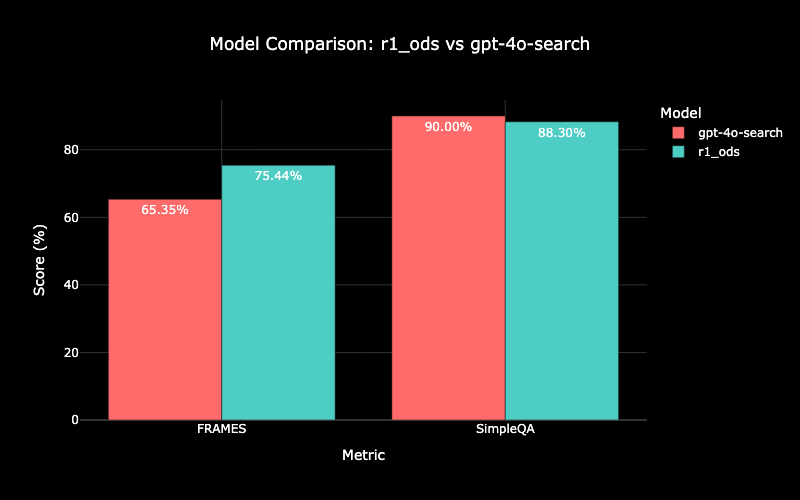

일반 소개
Seed-VC는 Plachtaa에서 개발한 깃허브의 오픈 소스 프로젝트입니다. 1~30초 분량의 레퍼런스 오디오를 사용하여 추가 교육 없이도 음성 또는 노래 변환을 빠르게 수행할 수 있습니다. 이 프로젝트는 실시간 음성 변환을 지원하며 지연 시간이 400밀리초 정도로 짧아 온라인 회의, 게임 또는 라이브 사용에 적합합니다. Seed-VC는 음성 변환(VC), 노래 변환(SVC) 및 실시간 변환의 세 가지 모드를 제공합니다. 그것은 사용합니다 Whisper 및 BigVGAN 등의 기술을 사용하여 선명한 사운드를 보장합니다. 이 코드는 무료로 공개되어 있으며, 사용자는 로컬에서 다운로드하여 빌드할 수 있습니다. 공식 업데이트, 자세한 문서, 활발한 커뮤니티 지원이 제공됩니다.

기능 목록
- 제로 샘플 변환 지원: 짧은 오디오로 대상 음성 또는 노래를 모방합니다.
- 실시간 음성 처리: 마이크 입력 후 음성이 즉시 목표 톤으로 변경됩니다.
- 노래 변환: 모든 노래를 지정된 가수의 목소리로 변환합니다.
- 오디오 길이 조정: 음성의 속도를 높이거나 낮춰 템포를 조절할 수 있습니다.
- 피치 조정: 목표 톤에 맞게 피치를 자동 또는 수동으로 조정합니다.
- 웹 인터페이스 조작: 사용하기 쉬운 간단한 그래픽 인터페이스를 제공합니다.
- 맞춤형 교육 지원: 소량의 데이터로 특정 사운드를 최적화합니다.
- 오픈 소스 코드: 사용자가 수정하거나 업그레이드할 수 있는 기능.
도움말 사용
설치 프로세스
로컬에서 Seed-VC를 사용하려면 먼저 환경을 설치해야 합니다. 다음은 Windows, Mac(M 시리즈 칩 사용) 또는 Linux에 대한 자세한 단계입니다.
- 환경 준비하기
- 파이썬 3.10을 설치하려면 공식 웹사이트에서 다운로드하세요.
- Git을 설치하려면 Windows 사용자의 경우 "Windows용 Git"을 검색하고, Mac 사용자의 경우 brew 설치 git을 검색합니다.
- GPU 사용자는 CUDA 12.4 및 해당 드라이버를 설치해야 하며, CPU도 실행할 수 있지만 속도가 느립니다.
- 오디오 처리용 FFmpeg를 설치하려면 Windows의 경우 공식 웹사이트에서 다운로드하고, Mac의 경우 brew를 사용하여 설치하고, Linux의 경우 패키지 관리자를 사용하여 설치합니다.
- 코드 다운로드
- 명령줄을 엽니다(Windows의 경우 CMD 또는 아나콘다 프롬프트, Mac/Lux의 경우 터미널).
- git clone https://github.com/Plachtaa/seed-vc.git 을 입력하여 프로젝트를 다운로드합니다.
- 디렉토리로 이동: cd seed-vc .
- 가상 환경 설정
- 독립 실행형 환경을 만들려면 python -m venv venv를 입력합니다.
- 환경을 활성화합니다:
- Windows: venv\Scripts\activate
- Mac/Linux: 소스 venv/bin/activate
- 성공하려면 (venv)를 참조하세요.
- 종속성 설치
- Windows/Linux pip 설치 -r 요구 사항.txt를 입력합니다.
- Mac M 시리즈 입력 pip 설치 -r 요구사항-mac.txt .
- 네트워크 문제에 대한 미러링 추가: HF_ENDPOINT=https://hf-mirror.com pip install -r requirements.txt .
- 실행 중인 프로그램
- 음성 변환: python app_vc.py
- 노래 변환: 파이썬 app_svc.py
- 실시간 변환: python real-time-gui.py
- 실행이 완료되면 브라우저는 http://localhost:7860 으로 이동하여 인터페이스를 사용합니다.
주요 기능
1. 음성 변환(VC)
- 이동::
- python app_vc.py를 실행하고 브라우저를 열어 http://localhost:7860.
- 원본 오디오(소스 오디오)와 레퍼런스 오디오(레퍼런스 오디오, 1~30초)를 업로드합니다.
- 확산 단계(기본값 25)를 설정하고 음질을 개선하려면 30~50으로 설정합니다.
- 길이 조정, 1 미만이면 속도가 빨라지고 1 이상이면 속도가 느려집니다.
- 제출을 클릭하고 몇 초간 기다린 후 전환 결과를 다운로드합니다.
- 다음 사항에 유의하십시오.::
- 처음 실행하면 시드-유비트-위스퍼-스몰-웨이브넷 모델이 자동으로 다운로드됩니다.
- 참조 오디오는 30초 후에 끊어집니다.
2. 노래 음성 변환(SVC)
- 이동::
- python app_svc.py를 실행하여 웹 인터페이스를 엽니다.
- 노래 오디오 및 가수 레퍼런스 오디오를 업로드합니다.
- 곡의 음정을 유지하려면 F0 조건을 선택합니다.
- 자동 0-조정 옵션으로 피치를 자동으로 조정합니다.
- 확산 단계 수를 30~50으로 설정하고 제출을 클릭합니다.
- 기교::
- 최상의 결과를 얻으려면 선명하고 배경 소음이 없는 레퍼런스 오디오를 사용하세요.
- 모델은 기본적으로 seed-uvit-whisper-base를 다운로드합니다.
3. 실시간 전환
- 이동::
- 파이썬 real-time-gui.py를 실행하여 인터페이스를 엽니다.
- 레퍼런스 오디오를 업로드하고 마이크를 연결합니다.
- 매개변수 설정: 확산 단계 4-10, 블록 시간 0.18초.
- '시작'을 클릭하면 말하는 동안 음성이 실시간으로 바뀝니다.
- VB-CABLE을 사용하여 출력을 가상 마이크에 라우팅합니다.
- 요청::
- 지연 시간이 약 430ms인 GPU 권장 사항(예: RTX 3060).
- CPU 실행 지연 시간이 더 길어집니다.
4. 명령줄 작업
- 음성 변환 예시::
python inference.py --source input.wav --target ref.wav --output ./out --diffusion-steps 25 --length-adjust 1.0 --fp16 True
- 노래 변환 예시::
python inference.py --source song.wav --target singer.wav --output ./out --diffusion-steps 50 --f0-condition True --semi-tone-shift 0 --fp16 True
5. 맞춤형 교육
- 이동::
- 폴더에 1~30초 분량의 오디오 파일(.wav/.mp3 등)을 준비합니다.
- 교육을 실행합니다:
python train.py --config configs/presets/config_dit_mel_seed_uvit_whisper_base_f0_44k.yml --dataset-dir ./data --run-name myrun --max-steps 1000
- 교육 후 체크포인트 . /runs/myrun/ft_model.pth .
- 사용자 지정 모델을 사용한 추론:
python app_svc.py --checkpoint ./runs/myrun/ft_model.pth --config configs/presets/config_dit_mel_seed_uvit_whisper_base_f0_44k.yml
- 다음 사항에 유의하십시오.학습할 오디오 샘플: 최소 1개, 100단계에 약 2분(T4 GPU).
보충 참고 사항
- 모델 선택::
- seed-uvit-tat-xlsr-tiny(25M 매개변수)로 실시간.
- 시드-우빗-위스퍼-작은 웨이브넷(98M 매개변수)을 사용한 오프라인 음성.
- 보컬의 경우 시드-우빗-위스퍼 베이스(200M 파라미터, 44kHz)를 사용합니다.
- 테스트 중 구성 요소 조정::
- 오류 보고 ModuleNotFoundError , 종속성을 확인합니다.
- Mac에서 실시간 GUI를 실행하려면 Tkinter가 설치된 Python이 필요할 수 있습니다.
애플리케이션 시나리오
- 엔터테인먼트 더빙
음성을 만화 캐릭터로 바꾸어 재미있는 동영상을 만드세요. - 음악 제작
일반 보컬을 전문 가수 톤으로 변환하여 노래 데모를 생성합니다. - 실시간 상호작용
앵커가 실시간으로 목소리를 바꿔가며 쇼의 재미를 더합니다. - 언어 학습
원어민의 말을 따라하며 발음을 연습하세요.
QA
- 많은 데이터가 필요하신가요?
변환에는 1개의 짧은 오디오 클립이 필요하고 교육에는 1개의 샘플만 필요합니다. - 중국어 오디오를 지원하나요?
지원. 참조 오디오가 중국어로 되어 있으면 변환도 명확하게 이루어집니다. - 높은 지연 시간은 어떻게 되나요?
GPU를 사용하고 확산 단계 수를 낮게 설정합니다(4~10). - 음질이 좋지 않으면 어떻게 하나요?
확산 단계를 50으로 늘리거나 깨끗한 레퍼런스 오디오를 사용합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...