
일반 소개
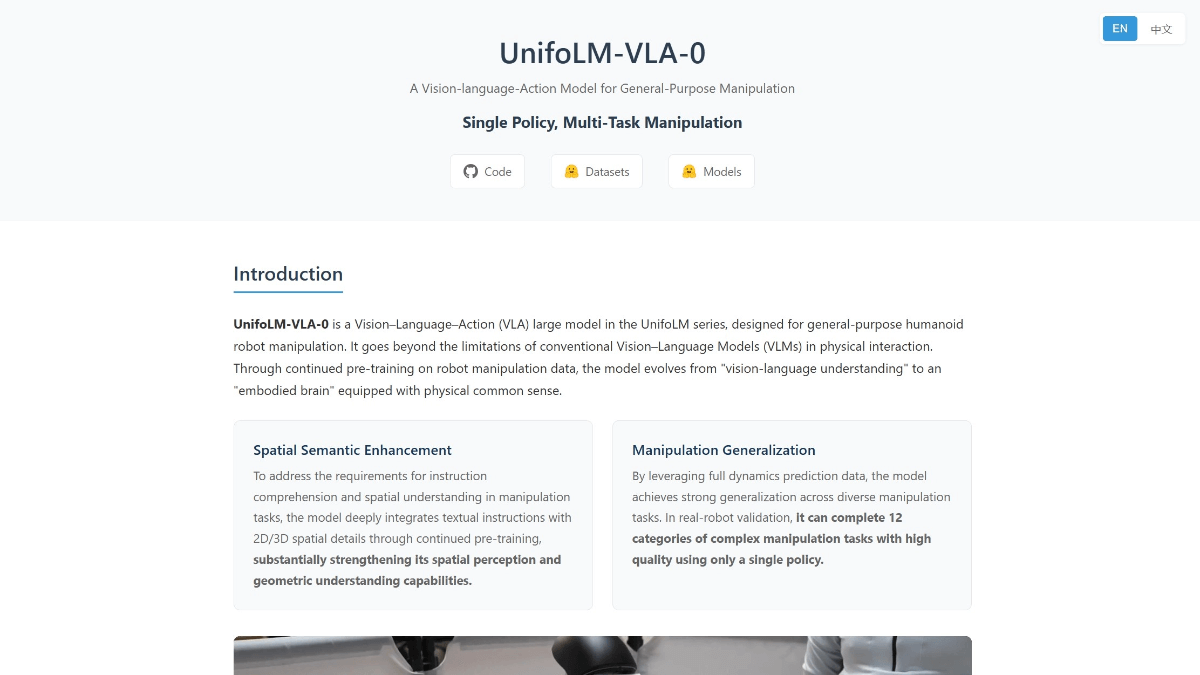
Search-R1은 피터 그리핀 진이 GitHub에서 개발한 오픈 소스 프로젝트로, veRL 프레임워크를 기반으로 구축되었습니다. 이 프로젝트는 강화 학습(RL) 기법을 사용하여 대규모 언어 모델(LLM)을 학습시켜 모델이 자율적으로 추론하고 검색 엔진을 호출하여 문제를 해결할 수 있도록 합니다. 이 프로젝트는 Qwen2.5-3B 및 Llama3.2-3B와 같은 기본 모델을 지원하여 DeepSeek-R1 및 TinyZero 메서드를 지원합니다. 사용자는 코드, 데이터 세트 및 실험 로그가 제공되어 단일 또는 다중 작업을 처리하도록 모델을 훈련하는 데 사용할 수 있습니다. 공식논문 또는 논문 토론(이전)2025년 3월에 공개된 프로젝트 모델과 데이터는 연구자와 개발자를 위해 허깅 페이스에서 다운로드할 수 있습니다.

기능 목록
- 강화 학습을 통해 대규모 모델을 학습하여 추론과 검색을 개선합니다.
- 구글, 빙, 브레이브 및 기타 검색 엔진 API 호출을 지원합니다.
- 모델 성능을 최적화하기 위한 LoRA 튜닝 및 감독 미세 조정 기능을 제공합니다.
- 검색 결과 정확도를 높이기 위한 기본 제공 재정렬기가 내장되어 있습니다.
- 결과 재현을 지원하는 자세한 실험실 로그와 논문이 포함되어 있습니다.
- 검색을 쉽게 사용자 지정할 수 있는 로컬 검색 서버 기능을 제공합니다.
- 사용자 지정 데이터 세트 및 말뭉치의 사용자 업로드를 지원합니다.
도움말 사용
Search-R1은 프로그래밍과 머신러닝에 대한 기본 지식이 있는 사용자를 대상으로 합니다. 아래는 빠르게 시작할 수 있도록 자세한 설치 및 사용 가이드를 제공합니다.
설치 프로세스
Search-R1을 사용하려면 먼저 환경을 설정해야 합니다. 단계는 다음과 같습니다:
- Search-R1 환경 만들기
터미널에서 실행됩니다:
conda create -n searchr1 python=3.9
conda activate searchr1
이렇게 하면 Python 3.9 가상 환경이 생성됩니다.
- PyTorch 설치
다음 명령을 입력하여 PyTorch 2.4.0(CUDA 12.1 지원)을 설치합니다:
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
- vLLM 설치
vLLM 는 대형 모델을 실행하기 위한 핵심 라이브러리로, 버전 0.6.3을 설치하세요:
pip3 install vllm==0.6.3
0.5.4, 0.4.2 또는 0.3.1 버전도 사용할 수 있습니다.
- veRL 설치
프로젝트 루트 디렉토리에서 실행합니다:
pip install -e .
그러면 veRL 프레임워크가 설치됩니다.
- 선택적 종속성 설치
성능을 향상시키려면 플래시 어텐션과 Wandb를 설치하세요:
pip3 install flash-attn --no-build-isolation
pip install wandb
- 리트리버 환경 설치(선택 사항)
로컬 검색 서버가 필요한 경우 다른 환경을 만드세요:
conda create -n retriever python=3.10
conda activate retriever
conda install pytorch==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
빠른 시작
다음은 NQ 데이터 세트를 기반으로 모델을 학습시키는 단계입니다:
- 색인 및 말뭉치 다운로드
저장 경로를 설정하고 실행합니다:
save_path=/你的保存路径
python scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gz
- NQ 데이터 처리
스크립트를 실행하여 학습 데이터를 생성합니다:
python scripts/data_process/nq_search.py
- 검색 서버 시작
리트리버 환경에서 실행됩니다:
conda activate retriever
bash retrieval_launch.sh
- RL 교육 실행
Search-R1 환경에서 실행합니다:
conda activate searchr1
bash train_ppo.sh
PPO 교육에는 Llama-3.2-3B 기본 모델을 사용합니다.
사용자 지정 데이터 집합 사용
- QA 데이터 준비
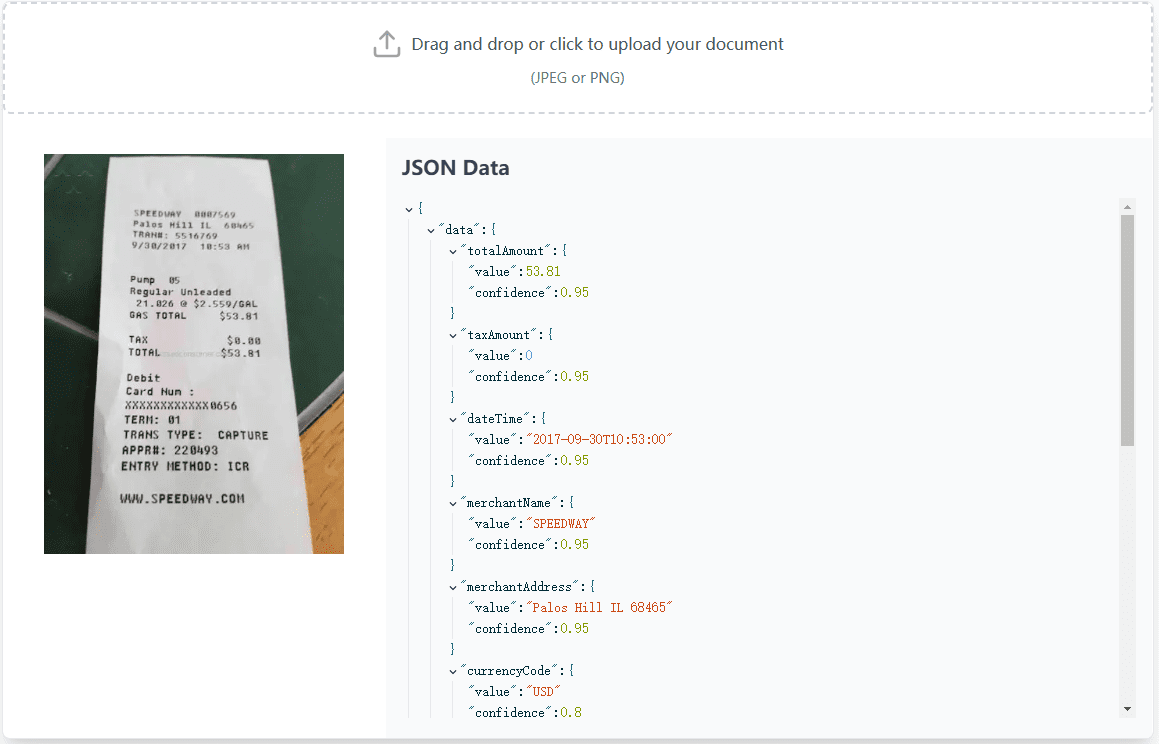
데이터는 JSONL 형식이어야 하며 각 행에는 다음 필드가 포함되어야 합니다:
{
"data_source": "web",
"prompt": [{"role": "user", "content": "问题"}],
"ability": "fact-reasoning",
"reward_model": {"style": "rule", "ground_truth": "答案"},
"extra_info": {"split": "train", "index": 1}
}
상담 <scripts/data_process/nq_search.py>.
- 말뭉치 준비하기
말뭉치는 JSONL 형식이어야 하며, 각 줄에는 다음이 포함되어야 합니다.id노래로 응답contentsAs:{"id": "0", "contents": "文本内容"}참조 가능
<example/corpus.jsonl>. - 말뭉치 색인화(선택 사항)
로컬 검색을 사용하는 경우 실행합니다:bash search_r1/search/build_index.sh
사용자 지정 검색 엔진 호출
- 수정
<search_r1/search/retriever_server.py>를 클릭하고 API를 구성합니다. - 서버를 시작합니다:
python search_r1/search/retriever_server.py - 모델은
http://127.0.0.1:8000/retrieve통화 검색.
추론 연산
- 검색 서버를 시작합니다:
bash retrieval_launch.sh - 추론 실행:
python infer.py - 수정
<infer.py>7호선question를 클릭하고 질문하려는 질문을 입력합니다.
주의
- 교육에는 최소 24GB의 비디오 메모리가 있는 GPU(예: NVIDIA A100)가 필요합니다.
- API 키가 유효하고 네트워크 연결이 안정적인지 확인하세요.
- 공식 논문 및 연구실 저널(
<Full experiment log 1>노래로 응답<Full experiment log 2>) 자세한 내용을 입력하세요.
이러한 단계를 통해 Search-R1을 사용하여 다양한 작업을 처리하기 위해 추론하고 검색할 수 있는 모델을 훈련할 수 있습니다.
애플리케이션 시나리오
- 연구 실험
연구자들은 Search-R1을 사용하여 논문 결과를 재현하고 모델 훈련에서 강화 학습의 적용을 탐색할 수 있습니다. - 지능형 어시스턴트 개발
개발자는 검색 및 추론 기능을 제공하기 위해 채팅 도구에 통합할 모델을 훈련시킬 수 있습니다. - 지식 쿼리
사용자는 검색을 통해 복잡한 질문에 빠르게 답하고 최신 정보를 얻을 수 있습니다.
QA
- Search-R1은 어떤 모델을 지원하나요?
현재 Qwen2.5-3B 및 Llama3 2-3B 기본 모델만 지원되며, 다른 모델은 직접 조정해야 합니다. - 교육은 얼마나 걸리나요?
데이터 세트와 하드웨어에 따라 다르지만, NQ 데이터 세트는 24GB 그래픽 GPU에서 학습하는 데 약 몇 시간이 걸립니다. - 교육 효과를 확인하려면 어떻게 해야 하나요?
체크 아웃<Preliminary results>를 클릭하거나 Wandb 로그를 확인하세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...