
검색 증강 생성(RAG)은 자체 데이터를 사용하여 LLM 모델(예: ChatGPT)의 지식을 보강할 수 있도록 지원하는 생성 AI(GenAI)의 애플리케이션 클래스입니다.
RAG 일반적으로 임베딩 모델, 리랭크어 모델, 빅 랭귀지 모델 등 세 가지 AI 모델이 사용됩니다. 이 문서에서는 데이터 유형과 언어 또는 특정 도메인(예: 법률)에 따라 적합한 임베딩 모델을 선택하는 방법에 대해 설명합니다.
1. 텍스트 데이터: MTEB 순위
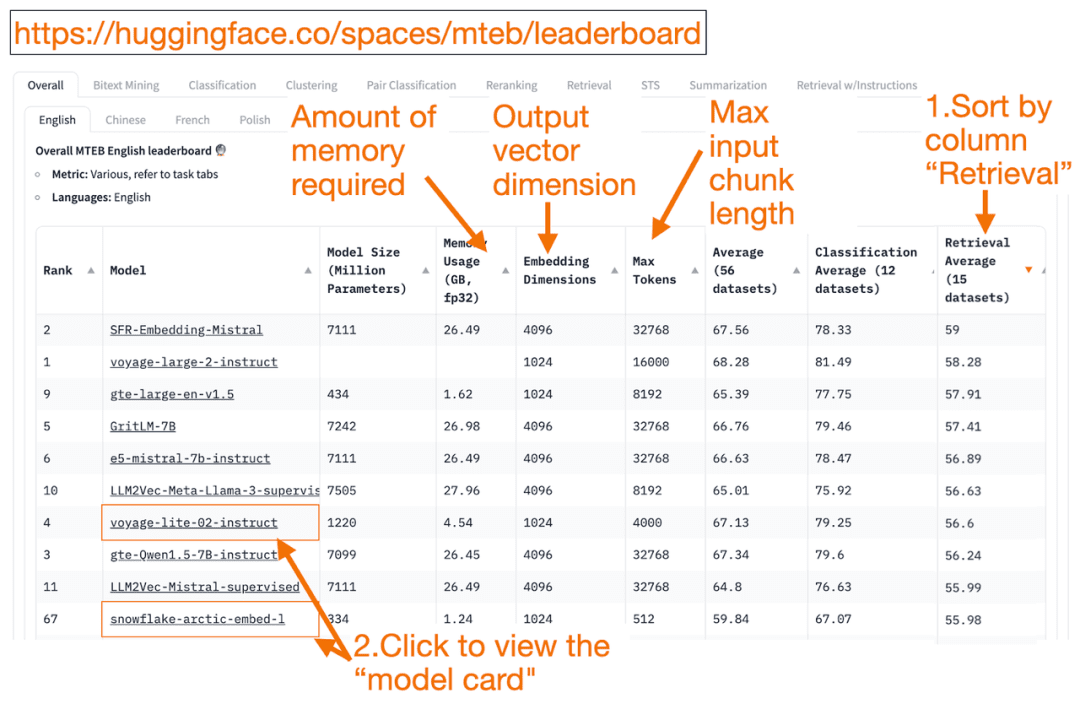
허깅페이스 MTEB 리더보드 텍스트 임베딩 모델의 원스톱 목록입니다! 각 모델의 평균 성능을 확인할 수 있습니다.
'검색 평균' 열을 내림차순으로 정렬하면 벡터 검색 작업에 가장 적합하므로 내림차순으로 정렬할 수 있습니다. 그런 다음 메모리 사용량이 가장 작은 가장 높은 순위의 모델을 찾습니다.
- 임베딩 벡터 차원은 모델이 출력할 벡터의 길이, 즉 f(x)=y에서 y입니다.
- 가장 큰 토큰 숫자는 모델에 입력할 수 있는 입력 텍스트 블록의 길이(예: f(x)=y에서 x)입니다.
통과하는 것 외에도 검색 작업을 정렬하는 것 외에도 다음 기준으로 필터링할 수도 있습니다:
- 언어: 프랑스어, 영어, 중국어, 폴란드어가 지원됩니다. (예: task=검색.
언어=중국어)
- 법률 분야의 텍스트.
(예: task=검색, 언어=법률)
일부 훈련 데이터는 최근에야 공개되었기 때문에 MTEB의 일부 임베딩 모델은 다음과 같을 수 있다는 점에 유의할 필요가 있습니다.겉보기에 적합해 보이는그러나 순위가 부풀려진 부적합한 모델의 실제 성적은 실제로 다를 수 있습니다. 그 결과 HuggingFace는블로그(외래어)모델의 순위를 신뢰할 수 있는지 판단하기 위한 핵심 사항을 설명합니다. 모델 링크('모델 카드'라고 함)를 클릭합니다:
- 모델이 어떻게 학습되고 평가되는지 설명하는 블로그와 논문을 찾아보세요. 모델 학습에 사용되는 언어, 데이터, 작업을 자세히 살펴보세요. 또한 잘 알려진 회사에서 만든 모델도 찾아보세요. 예를 들어, voyage-lite-02-instruct 모델 카드에는 이 모델이 아닌 다른 VoyageAI 모델이 나열되어 있을 것입니다. 이것이 힌트입니다! 이 모델은 과적합 모델이므로 사용해서는 안 됩니다!
- 아래 스크린샷에서는 순위가 높고 노트북에서 실행할 수 있을 만큼 작으며 모델 카드에 블로그와 논문 링크가 있는 Snowflake의 새 모델 'snowflake-arctic-embed-1'을 사용해 보겠습니다.
허깅페이스 사용의 장점은 임베딩 모델을 선택한 후 모델을 변경해야 하는 경우 코드에서 model_name만 변경하면 된다는 것입니다!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2. 이미지 데이터: ResNet50
입력한 이미지와 유사한 이미지를 검색하고 싶을 때가 있습니다. 예를 들어 스코티시 폴드 고양이의 이미지를 더 많이 찾고 싶을 수 있습니다. 이 경우 스코티시 폴드 고양이 사진을 업로드하고 검색 엔진에 비슷한 이미지를 찾도록 요청할 수 있습니다.
ResNet50 는 2015년에 Microsoft에서 ImageNet 데이터를 사용하여 학습한 인기 있는 CNN 모델입니다.
마찬가지로동영상 검색이 경우에도 ResNet50은 동영상을 임베딩 벡터로 변환할 수 있습니다. 그런 다음 정적 비디오 프레임에 대해 유사도 검색을 수행하여 가장 유사한 비디오가 가장 잘 일치하는 것으로 사용자에게 반환됩니다.
3. 오디오 데이터: PANN
이미지 검색과 마찬가지로 입력된 오디오 클립을 기반으로 유사한 오디오를 검색할 수도 있습니다.
PANN(사전 학습된 오디오 신경망)은 대규모 오디오 데이터 세트에 대해 사전 학습되고 오디오 분류 및 라벨링과 같은 작업에 탁월하기 때문에 일반적으로 오디오 검색을 위한 임베딩 모델로 사용됩니다.
4. 멀티모달 이미지 및 텍스트 데이터:
SigLIP 또는 Unum
최근에는 텍스트, 이미지, 오디오, 동영상 등 다양한 비정형 데이터에 대해 학습된 임베딩 모델이 많이 등장했습니다. 이러한 모델은 동일한 벡터 공간에서 여러 유형의 비정형 데이터의 의미를 동시에 포착할 수 있습니다.
멀티모달 임베딩 모델은 텍스트를 사용한 이미지 검색, 이미지에 대한 텍스트 설명 생성 또는 이미지 검색을 지원합니다.
2021년 OpenAI 출시 클립 가 표준 임베딩 모델입니다. 하지만 사용자가 직접 미세 조정해야 하기 때문에 사용하기 어려웠기 때문에 2024년에 구글은 SigLIP(시그모이드 클립). 이 모델은 제로 샷 프롬프트를 사용할 때 좋은 성능을 달성했습니다.
오늘날 소형 LLM 모델이 점점 인기를 얻고 있습니다. 이러한 모델은 대규모 클라우드 클러스터가 필요하지 않고 노트북에서 실행할 수 있기 때문입니다. 소형 모델은 대형 모델보다 메모리를 적게 사용하고 지연 시간이 짧으며 실행 속도가 빠릅니다.Unum 멀티모달 미니 임베딩 모델이 제공됩니다.
5. 멀티모달 텍스트, 오디오 및 비디오 데이터
대부분의 멀티모달 텍스트-오디오 RAG 시스템은 먼저 사운드를 텍스트로 변환하고 사운드-텍스트 쌍을 생성한 다음 텍스트를 임베딩 벡터로 변환하는 멀티모달 생성 LLM을 사용합니다. 그런 다음 RAG를 사용하여 평소와 같이 텍스트를 검색할 수 있습니다. 마지막 단계에서는 텍스트를 다시 오디오로 매핑합니다.
OpenAI Whisper 는 음성을 텍스트로 변환할 수 있습니다. 또한 OpenAI의 텍스트 음성 변환(TTS) 모델은 텍스트를 오디오로 변환할 수도 있습니다.
멀티모달 텍스트-비디오 RAG 시스템은 유사한 접근 방식을 사용하여 먼저 비디오를 텍스트에 매핑하고, 임베딩 벡터로 변환하고, 텍스트를 검색한 다음, 검색 결과로 비디오를 반환합니다.
OpenAI Sora 텍스트를 동영상으로 변환할 수 있습니다. Dall-e와 마찬가지로 텍스트 프롬프트를 제공하면 LLM이 동영상을 생성하며, Sora는 정지 이미지나 다른 동영상에서 동영상을 생성할 수도 있습니다.
Milvus는 이제 메인스트림 임베딩 모델을 통합했으며, 이를 경험해 보시기 바랍니다:https://milvus.io/docs/embeddings.md
상담
MTEB 리더보드: https://huggingface.co/spaces/mteb/leaderboard
MTEB 모범 사례: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
유사 이미지 검색: https://milvus.io/docs/image_similarity_search.md
이미지 동영상 검색: https://milvus.io/docs/video_similarity_search.md
유사한 오디오 검색: https://milvus.io/docs/audio_similarity_search.md
텍스트 이미지 검색: https://milvus.io/docs/text_image_search.md
2024 SigLIP(시그모이드 손실 CLIP) 논문: https://arxiv.org/pdf/2401.06167v1
Unum 멀티모달 임베딩 모델:
https://github.com/unum-cloud/uform
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 게시물




댓글 없음...