
PP-OCRv5란?
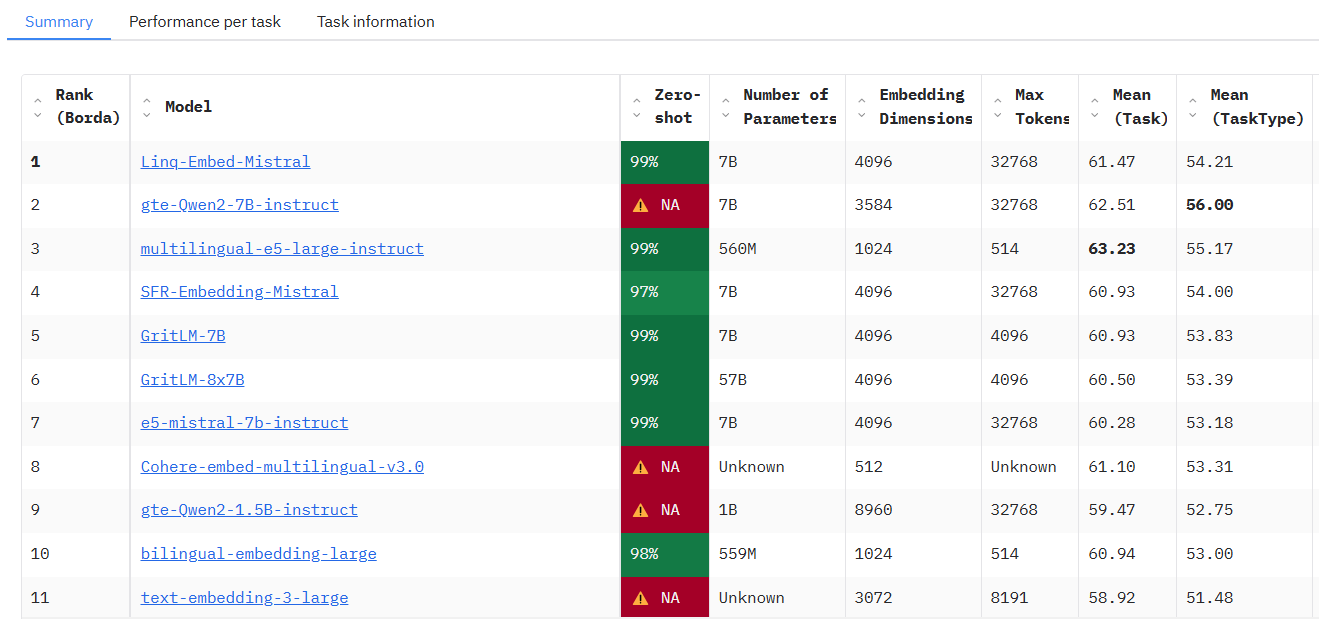
PP-OCRv5는 바이두에서 출시한 최신 세대의 텍스트 인식 AI 모델입니다. 경량 설계와 0.07B에 불과한 레퍼런스 카운트로 CPU와 엣지 디바이스에서 효율적으로 실행하기에 적합하며 초당 370개 이상의 문자를 처리할 수 있습니다. 중국어 간체, 중국어 번체, 영어, 일본어, 병음 등 5가지 텍스트 유형을 지원하고 40개 이상의 언어를 인식할 수 있어 다국어 문서 처리에 적합하며, PP-OCRv5는 이미지 전처리, 텍스트 감지, 텍스트 선 방향 분류, 텍스트 인식의 4가지 핵심 구성 요소를 포함한 모듈식 2단계 프로세스를 채택하고 있습니다. 중국어와 영어의 복잡한 필기, 세로 텍스트, 외딴 문자 등 복잡한 시나리오에서 우수한 성능을 발휘합니다. PP-OCRv4에 비해 중국어 필기 감지, 고풍스러운 텍스트 감지, 세로 텍스트 인식, 외딴 문자 인식, 영어 필기 인식 등 시나리오의 정확도가 각각 13.8%, 43%, 71%, 96%, 118% 향상되었으며, 이미지 사전 처리, 텍스트 선 방향 분류, 텍스트 인식의 4가지 핵심 구성 요소를 포함하는 이미지 사전 처리 프로세스의 백본을 업그레이드했습니다. OCRv5는 백본 네트워크를 업그레이드하고 이중 분기 아키텍처를 채택했으며 주의 메커니즘과 CTC 손실을 결합하여 데이터 구축 전략을 최적화하여 PDF 및 전자책과 같은 문서에서 고품질 주석 데이터를 얻었습니다.
PP-OCRv5의 특징
- 경량 설계레퍼런스 수가 0.07B에 불과해 CPU 및 엣지 디바이스에서 효율적으로 운영하기에 적합하며, 모바일 버전은 인텔 제온 골드 6271C CPU에서 초당 370자 이상을 처리할 수 있어 대량의 텍스트 데이터도 빠르게 처리할 수 있습니다.
- 다국어 지원중국어 간체, 중국어 번체, 영어, 일본어, 병음의 5가지 텍스트 유형을 지원하며 40개 이상의 언어를 인식할 수 있어 다국어 문서 처리에 적합하고 다양한 언어 환경의 텍스트 인식 요구를 충족합니다.
- 매우 정확한 인식중국어와 영어의 복잡한 필기, 세로 텍스트, 외딴 문자 등 복잡한 시나리오에서 우수한 성능을 발휘합니다. PP-OCRv4와 비교하여 중국어 필기 감지, 고풍스러운 텍스트 감지, 세로 텍스트 인식, 외딴 문자 인식, 영어 필기 인식 등의 시나리오에서 각각 13.81 TP3T, 431 TP3T, 711 TP3T, 961 TP3T, 1,181 TP3T의 정확도가 향상되었으며, 다음과 같은 기능을 수행할 수 있습니다. 다양한 유형의 텍스트를 더 정확하게 인식할 수 있습니다.
- 정확한 텍스트 위치 지정정확한 텍스트 라인 경계 상자 좌표를 제공하는 것은 구조화된 데이터 추출 및 콘텐츠 분석의 핵심 요구 사항이며, 후속 텍스트 처리 및 분석 작업에 도움이 됩니다.
- 단일 모델 다국어 인식단일 모델에서 5가지 텍스트 유형을 지원하는 업계 최초의 초경량(1억 미만) 오픈소스 모델로, 통합 모델 아키텍처를 통해 5가지 텍스트 유형을 원활하게 인식하여 텍스트 유형별로 독립적인 모델을 배포할 필요가 없어 배포 프로세스를 간소화하고 전반적인 인식 정확도와 속도를 향상시킵니다.
- 복잡한 시나리오에 대한 높은 적응성중국어와 영어의 복잡한 필기체, 세로 텍스트, 희귀 문자 등 다양하고 까다로운 시나리오의 인식을 지원하고, 복잡한 텍스트 형식과 내용에 대응할 수 있어 모델의 범용성과 실용성을 향상시킵니다.
- 백본 네트워크 업그레이드한 브랜치는 주의 기반 훈련을 사용하여 시퀀스 모델링을 향상시키고, 다른 브랜치는 CTC 손실을 사용하여 효율적인 추론에 집중하는 PP-HGNetV2를 백본으로 하는 두 개의 브랜치 아키텍처가 사용됩니다. 두 브랜치는 훈련 중에는 서로 협력하지만 예측 중에는 경량 브랜치만 사용하므로 정확도와 속도가 보장됩니다.
- 데이터 구축 전략 최적화기존 모델과 ERNIE - 4.5 - VL - 424B - A47B를 결합하여 합성을 통해 생성된 희귀 문자를 포함한 고품질 손글씨 샘플에 자동으로 주석을 달고 필터링합니다. 자동 구문 분석 및 편집 거리 필터링을 통해 PDF 및 전자책과 같은 문서에서 대규모 주석이 달린 데이터를 확보하여 모델의 전반적인 성능을 위한 견고한 데이터 기반을 마련합니다.
PP-OCRv5의 핵심 이점
- 경량 설계모델 매개변수 수가 0.07B에 불과하여 CPU 및 엣지 디바이스에서 더 높은 성능을 구현할 수 있습니다. 모바일 버전은 인텔 제온 골드 6271C CPU에서 초당 370개 이상의 문자를 처리할 수 있습니다.
- 매우 정확한 인식손글씨 및 인쇄된 중국어와 영어, 병음 텍스트를 포함한 OCR 관련 벤치마킹에서 Gemini 2.5 Pro, Qwen2.5-VL, GPT-4o와 같은 범용 시각 언어 모델보다 뛰어난 성능을 발휘합니다.
- 다국어 지원중국어 간체, 중국어 번체, 영어, 일본어, 병음 등 5가지 텍스트 유형을 지원하며 40개 이상의 언어를 인식할 수 있습니다.
- 정확한 텍스트 위치 지정정확한 텍스트 라인 경계 상자 좌표를 제공하는 것은 구조화된 데이터 추출 및 콘텐츠 분석을 위한 핵심 요구 사항입니다.
PP-OCRv5 공식 웹사이트는 무엇인가요?
- 프로젝트 웹사이트:: https://huggingface.co/blog/baidu/ppocrv5
- 허깅페이스 모델 라이브러리:: https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
PP-OCRv5는 누구를 위한 것인가요?
- 엔터프라이즈 개발자금융, 의료, 교육 산업 등 비즈니스 시스템에 고효율 텍스트 인식 기능을 통합해야 하는 기업에서 계약서 파싱, 의료 기록의 디지털화, 시험지 수정 등의 시나리오에 사용할 수 있습니다.
- (과학) 연구원컴퓨터 비전, 자연어 처리 및 기타 인공 지능 분야에 종사하는 연구자들은 학술 연구 및 모델 비교에 PP-OCRv5를 사용할 수 있습니다.
- 소프트웨어 개발자모바일 애플리케이션, 데스크톱 소프트웨어 등 텍스트 인식 기능이 필요한 애플리케이션 개발자는 PP-OCRv5를 빠르게 통합하여 기능을 구현할 수 있습니다.
- 데이터 분석가텍스트 데이터의 신속한 처리 및 분석을 위해 수많은 문서에서 구조화된 데이터를 추출해야 하는 데이터 분석가.
- 교육자학생의 과제, 시험지 등 손으로 쓴 텍스트를 처리하고 분석해야 하는 교사는 자동 교정 및 내용 분석에 사용할 수 있습니다.
- 파일 관리자대량의 종이 문서를 관리하고 디지털화하는 업무를 담당하는 아카이브 전문가로, 문서를 빠르게 식별하고 분류하는 데 사용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...