
미다셩LM이란?
MiDashengLM은 오디오 처리 및 이해에 중점을 둔 특정 매개 변수 버전 MiDashengLM-7B와 함께 효율적인 사운드 이해를 위한 Xiaomi의 오픈 소스 대형 모델입니다. 이 모델은 음성, 주변 소리 및 음악 이해를 통합할 수 있는 샤오미 다셩 오디오 인코더와 Qwen2.5-Omni-7B 씽커 디코더를 기반으로 구축되었습니다. 이 모델은 추론 효율성이 뛰어납니다. 토큰 MiDashengLM의 교육 데이터는 완전한 오픈 소스로 학술 및 상업적 사용을 모두 지원하며, 멀티모달 인터랙션 경험을 업그레이드하는 데 강력한 지원을 제공합니다.
미다셩LM의 주요 기능
- 오디오 콘텐츠를 텍스트로 변환이 모델은 말하는 목소리, 자연 소리, 음악 등 다양한 종류의 오디오를 텍스트 설명으로 변환하여 사람들이 오디오에서 실제로 무슨 일이 일어나고 있는지 빠르게 이해할 수 있도록 도와줍니다.
- 오디오 카테고리 식별오디오에 라벨을 붙여 다양한 시나리오에서 쉽게 사용할 수 있도록 하는 것처럼, 이 모델은 오디오가 음성인지, 주변 소리인지, 음악인지 등을 구분할 수 있습니다.
- 음성 인식사람이 말하는 내용을 텍스트로 변환하고 여러 언어를 지원하며 특히 음성 비서나 스마트 기기에서 사용하기에 적합합니다.
- 오디오 Q&A오디오 콘텐츠에 기반한 질문(예: 차 안에서 "방금 무슨 소리였어?"라고 물으면 모델이 응답합니다.
- 멀티모달 상호 작용오디오와 기타 정보(예: 텍스트, 그림)를 함께 이해하는 기능으로 더욱 스마트하고 자연스러운 기기 상호 작용을 가능하게 합니다.
미다셩엘엠의 공식 웹사이트 주소
- GitHub 리포지토리:: https://github.com/xiaomi-research/dasheng-lm
- 허깅페이스 모델 라이브러리:: https://huggingface.co/mispeech/midashenglm-7b
- 기술 문서:: https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- 온라인 경험 데모:: https://huggingface.co/spaces/mispeech/MiDashengLM-7B
미다셩LM 사용 방법
- 온라인 경험미다셩엘엠의 온라인 체험 데모를 살펴보세요.
- 오디오 파일 업로드: 오디오 파일을 업로드합니다(지원되는 형식은 WAV, MP3 등입니다).
- 처리 대기 중오디오를 업로드하면 모델이 자동으로 오디오를 처리하고 결과를 생성합니다.
- 결과 보기처리 완료 후 모델에서 생성된 설명 또는 분류 결과를 확인합니다.
미다셩엘엠의 핵심 강점
- 효율적인 추론 성능미다셩LM의 추론 효율은 매우 높고, 첫 토큰 대기 시간이 매우 짧으며, 처리량이 크게 향상되어 실시간 상호작용 시나리오에 적합합니다.
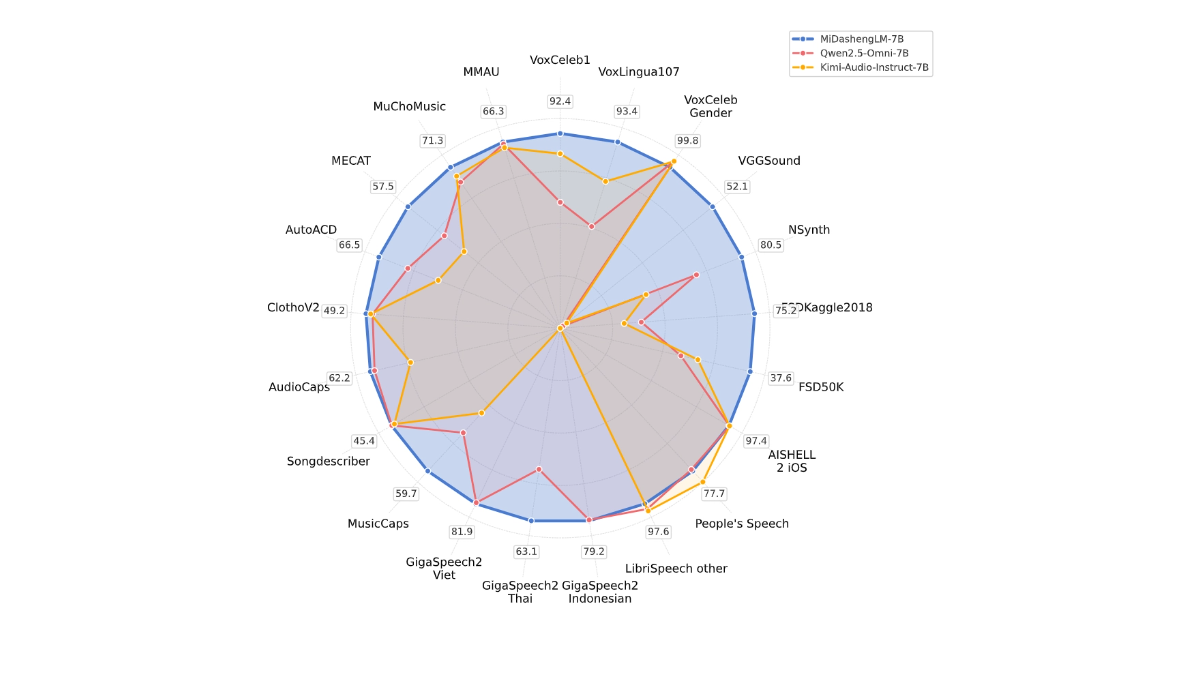
- 강력한 오디오 이해력는 기존 방법의 한계를 벗어나 음성, 주변 소리, 음악 등 다양한 오디오를 통합적으로 이해할 수 있게 해줍니다.
- 데이터 및 모델 오픈 소스학습 데이터와 모델은 완전히 오픈 소스로 제공되어 개발자의 연구와 2차 개발을 촉진하고 학술적 및 상업적 사용을 모두 지원합니다.
- 광범위한 애플리케이션 시나리오스마트 콕핏, 스마트 홈, 음성 비서, 오디오 콘텐츠 제작, 교육 및 학습 등 다양한 분야에 적용할 수 있습니다.
- 기술 최적화최적화된 오디오 인코더 및 디코더 설계를 기반으로 하는 MiDashengLM은 복잡한 오디오 작업을 처리하는 동시에 계산 부하를 줄이는 데 탁월합니다.
- 교육 전략일반 오디오 설명 정렬 및 다중 전문가 분석에 기반한 학습 전략은 모델이 오디오의 심층적인 의미 연관성을 학습하고 일반화를 개선하도록 보장합니다.
미다셩LM의 대상 사용자
- 인공 지능 연구원이 모델은 연구자들에게 오픈 소스 오디오 이해 모델과 학습 데이터를 제공하여 관련 분야의 연구와 혁신을 촉진합니다.
- 스마트 디바이스 개발자스마트 콕핏, 스마트 홈, 음성 비서 등의 제품을 개발하는 팀의 경우 이 모델을 제품에 빠르게 통합하여 상호 작용 경험을 향상시킵니다.
- 오디오 콘텐츠 제작자오디오 제작자는 모델을 사용하여 오디오 설명과 라벨을 자동으로 생성하여 콘텐츠 제작의 효율성을 개선합니다.
- 교육자 및 학습자언어 학습 및 음악 교육 분야에서 학습자가 지식을 더 잘 습득할 수 있도록 발음 피드백 및 이론적 지도를 지원합니다..
- 비즈니스 사용자상업적 사용을 지원하고 제품 개발 및 서비스 최적화에 사용할 수 있는 음성 이해 기능이 필요한 기업을 위한 효율적인 솔루션입니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...