
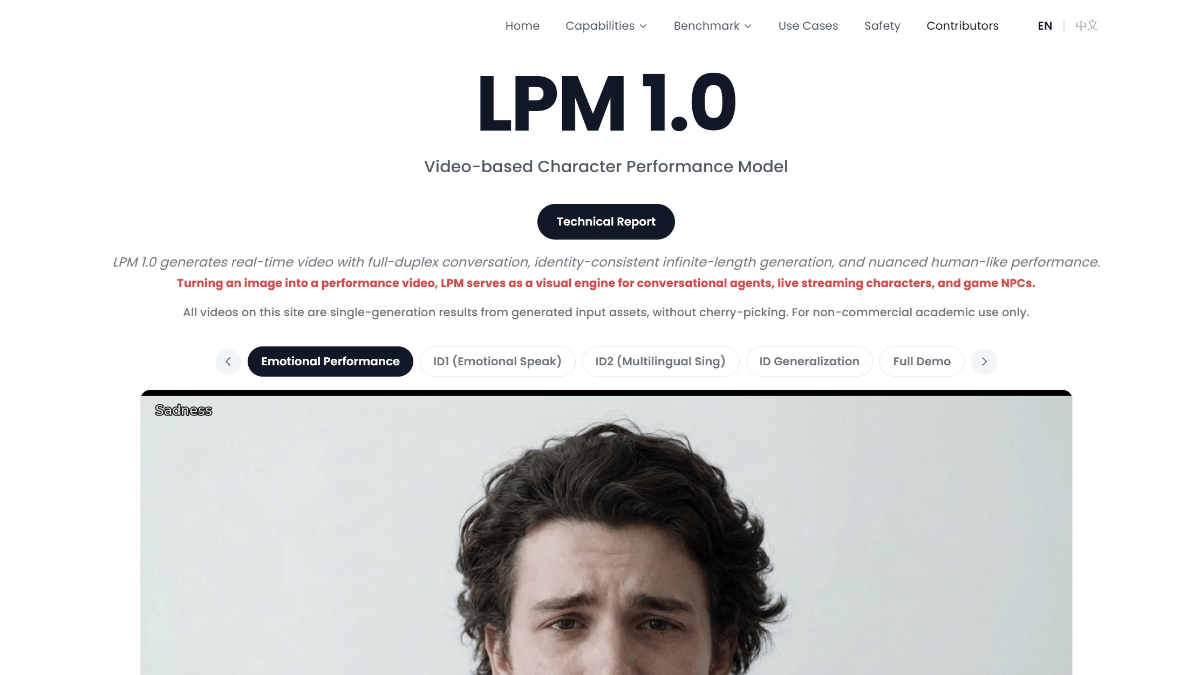
LPM 1.0是什么
LPM 1.0(Large Performance Model)是米哈游创始人蔡浩宇创立的AI公司Anuttacon发布的首个视频角色表演生成模型,采用17亿参数扩散Transformer架构,专注于解决AI角色表演中的"三难困境",同时实现高表现力、实时推理与长时身份稳定性。模型创新性地采用双模型架构:Base LPM负责高质量离线生成,Online LPM则通过蒸馏实现0.35秒延迟的实时流式生成,支持长达45分钟的零身份漂移。LPM 1.0支持全双工音视频对话,能同时处理说话与倾听状态,实现情感、微表情及肢体动作的自然同步,具备零样本泛化能力,适用于写实、动漫、3D游戏及非人类角色等多种风格,目标应用于对话式智能体、虚拟直播及游戏NPC等领域。
LPM 1.0的功能特色
- 全双工音视频对话表演:支持说话与倾听状态的同时处理,角色能在对话中自然切换,实时生成倾听时的点头、眼神交流等反应,以及说话时的唇形同步和情感表达。
- 双模型架构设计:包含Base LPM(17B参数,高质量离线生成720P视频)和Online LPM(经蒸馏的因果流式生成器,低延迟实时推理480P),兼顾质量与实时性。
- 超长时身份稳定性:通过多粒度身份参考机制(表情参考图+多视角身体参考),实现长达45分钟以上的零身份漂移视频生成。
- - 多模态统一控制:支持文本提示(动作控制)、音频驱动、图像参考(角色身份)三种驱动方式,可任意组合或单独使用。
- - 제로 샘플 일반화 기능:无需针对特定角色微调,即可支持写实、2D动漫、3D游戏及非人类角色(如狮子、狐狸)等多种风格。
- - 실시간 스트리밍 생성:Online LPM支持无限时长、低延迟(0.35秒)的实时视频生成,可与ChatGPT、豆包等音频对话模型无缝集成。
- - 多样化动作控制:涵盖眼神控制(注视、回避、上下看)、情感强度调节、头部微运动、身体微运动等精细表演动作。
LPM 1.0的核心优势
- 突破"表演三难困境":首创性解决了AI角色表演中长期存在的三大矛盾,高表现力、实时推理与长时身份一致性难以兼得的问题,实现了三者的统一。
- 双模型架构协同:通过Base LPM与Online LPM的分工设计,保证了离线生成的高质量(720P),实现了在线实时推理的低延迟(0.35秒),兼顾视觉质量与交互体验。
- 超长时身份一致性:采用多粒度身份参考机制,支持长达45分钟以上的连续视频生成,实现零身份漂移,远超市面上大多数视频生成模型的稳定性。
- 真正的全双工交互:区别于传统单工对话模型,可同时处理说话与倾听状态,在倾听时实时生成点头、眼神交流等反应,在说话时精准同步唇形与情感,交互更加自然真实。
- 零样本风格泛化:无需针对特定角色进行微调训练,支持写实人像、2D动漫、3D游戏角色乃至非人类生物(如狮子、狐狸)等多种风格的表演生成,大幅降低使用门槛。
LPM 1.0官网是什么
- 프로젝트 웹사이트:https://large-performance-model.github.io/
- arXiv 기술 논문:https://arxiv.org/pdf/2604.07823
使用LPM 1.0的操作步骤
目前仅用于学术交流不对外开放。
LPM 1.0的适用人群
- 游戏开发者与工作室:适用于需要为游戏创建智能NPC的开发者,可为角色赋予实时对话能力和自然表演,提升游戏沉浸感。
- AI应用开发者:专注于构建对话式AI智能体、虚拟助手或客服机器人的开发者,用LPM 1.0为现有音频对话模型(如ChatGPT、豆包)添加视觉表现层。
- 虚拟主播与内容创作者:从事虚拟直播、短视频创作的个人或MCN机构,可通过该模型快速生成具有情感表达和动作反应的数字人内容。
- 影视动画制作人员:需要高效生成长时角色表演动画的动画师和制作团队,用45分钟以上的身份稳定性减少重复建模工作。
- 数字人技术公司:开发数字员工、虚拟品牌代言人或智能客服的企业,可借助实时流式生成能力实现低延迟交互体验。
- 多风格角色设计师:需要创作写实、2D动漫、3D游戏角色或非人类形象(如动物角色)的概念艺术家,用零样本泛化能力快速验证不同风格的表演效果。
LPM 1.0的常见问题
Q:LPM 1.0是否开源?如何获取?
A:目前LPM 1.0仅用于学术研究交流,模型权重不开源,也不提供商业API。相关论文已发布在arXiv,项目主页提供技术介绍和演示视频。
Q:LPM 1.0支持多长时间的视频生成?
A:通过多粒度身份参考机制,LPM 1.0可实现长达45分钟以上的连续视频生成,且保持零身份漂移 。
Q:LPM 1.0的生成延迟是多少?是否支持实时交互?
A:Online LPM支持实时流式生成,延迟仅为0.35秒,可实现无限时长的实时视频生成,适合对话交互场景。
Q:LPM 1.0支持哪些角色风格?
A:具备零样本泛化能力,无需微调即可支持写实人像、2D动漫、3D游戏角色以及非人类形象(如狮子、狐狸等动物角色)。
Q:LPM 1.0如何驱动角色表演?
A:支持三种模态的灵活组合:文本提示(控制动作)、音频驱动(语音或音乐)、图像参考(设定角色身份),可单独使用或任意组合。
Q:LPM 1.0能否与现有的对话模型集成?
A:可以。Online LPM可与ChatGPT、豆包等现有音频对话模型无缝集成,无需重构现有系统即可为虚拟角色添加视觉表现。
Q:LPM 1.0与传统视频生成模型有什么区别?
A:传统模型主要关注画面生成,而LPM 1.0专注于角色的"表演",即连续的情感表达、动作反应和交互能力,并解决了高表现力、实时推理、长时身份稳定性三者难以兼得的"表演三难困境" 。
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...