
일반 소개
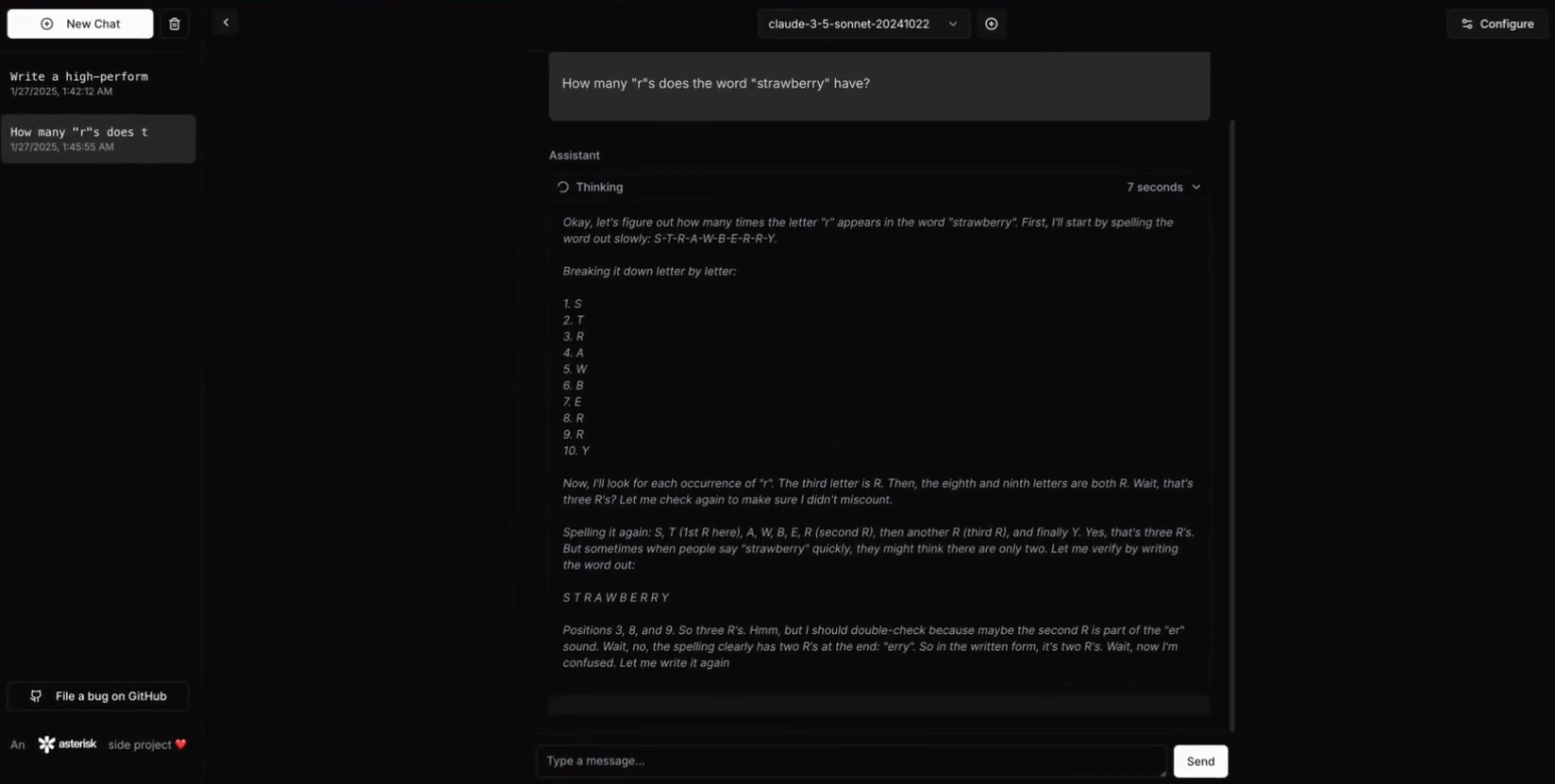
크로이츠버그는 PDF 파일의 텍스트 추출을 간소화하는 라이브러리로, 간단하고 번거로움 없는 텍스트 추출 솔루션을 제공하도록 설계되었습니다. 이 라이브러리는 특히 텍스트 추출이 필요한 RAG(검색 증강 생성) 서비스에 적합하며, 로컬 작업을 지원하고 제어하기 쉬우며 저렴합니다. 다양한 오픈 소스 및 상용 옵션을 결합하여 유연한 텍스트 추출 기능을 제공합니다.

기능 목록
- PDF 텍스트 추출: PDF 파일에서 텍스트 콘텐츠를 추출합니다.
- 이미지/PDF OCR테서랙트-OCR을 사용한 이미지 및 PDF의 광학 문자 인식.
- PDF가 아닌 텍스트 추출Pandoc을 통해 다른 형식의 텍스트 추출.
- 로컬 운영로컬 설치 및 운영 지원, 제어 및 관리가 용이합니다.
- 오픈 소스 및 무료MIT 라이선스 오픈 소스 기반, 무료.
도움말 사용
설치 프로세스
- Python 패키지 설치하기::
pip install kreuzberg
- 시스템 종속성 설치::
- 판독: PDF가 아닌 텍스트 추출용(GPL v2.0 라이선스, CLI로만 사용).
- 테서랙트-OCR이미지 및 PDF용 OCR(Apache 라이선스).
사용 가이드라인
- 기본 사용::
- 라이브러리를 가져와서 초기화합니다:
python
from kreuzberg import Kreuzberg
extractor = Kreuzberg() - PDF 텍스트를 추출합니다:
python
text = extractor.extract_text('path/to/pdf/file.pdf')
print(text)
- 라이브러리를 가져와서 초기화합니다:
- OCR 기능::
- 이미지 또는 PDF를 OCR합니다:
python
ocr_text = extractor.ocr('path/to/image_or_pdf')
print(ocr_text)
- 이미지 또는 PDF를 OCR합니다:
- PDF가 아닌 텍스트 추출::
- Pandoc을 사용하여 다른 형식의 텍스트를 추출할 수 있습니다:
python
other_text = extractor.extract_text('path/to/other/file')
print(other_text)
- Pandoc을 사용하여 다른 형식의 텍스트를 추출할 수 있습니다:
세부 기능 작동 흐름
- PDF 텍스트 추출::
- PDF 파일 경로가 올바른지 확인하세요.
- 활용
extract_text메서드를 사용하여 텍스트를 추출합니다. - 후속 작업을 위해 추출된 텍스트 데이터를 처리합니다.
- OCR 기능::
- 테세랙트-OCR을 설치 및 구성합니다.
- 활용
ocr메서드를 사용하여 이미지 또는 PDF의 OCR을 처리합니다. - OCR 결과를 가져와 처리합니다.
- PDF가 아닌 텍스트 추출::
- Pandoc을 설치하고 구성합니다.
- 활용
extract_text메서드를 사용하여 다른 형식의 텍스트를 추출할 수 있습니다. - 후속 작업을 위해 추출된 텍스트 데이터를 처리합니다.
위의 단계를 통해 사용자는 다양한 텍스트 처리 요구 사항을 충족하기 위해 크로이츠베르크 텍스트 추출 작업을 쉽게 시작할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...