

대규모 언어 모델(LLM)의 기능은 지속적으로 발전하고 있지만, 사실 오류 또는 출력물에서 원본 텍스트와 무관한 정보가 '착각'되는 현상은 항상 더 널리 사용되고 더 깊은 신뢰를 얻지 못하게 하는 주요 과제였습니다. 이 문제를 정량적으로 평가하기 위해휴즈 환각 평가 모델(HHEM) 순위는 문서 요약 생성 시 주류 LLM에서 발생하는 팬텀의 빈도를 측정하는 데 초점을 맞춰 탄생했습니다.
'착각'이라는 용어는 모델이 원본 문서에 포함되지 않거나 심지어 모순되는 '사실'을 요약에 도입한다는 사실을 의미합니다. 이는 LLM에 의존하는 정보 처리 시나리오, 특히 검색 증강 생성(RAG)에 기반한 시나리오에서 중요한 품질 병목 현상입니다. 결국, 모델이 주어진 정보에 충실하지 않으면 결과물의 신뢰도가 크게 떨어집니다.
HHEM은 어떻게 작동하나요?
이 순위는 벡타라에서 개발한 HHEM-2.1 환각 평가 모델을 사용합니다. 작동 방식은 소스 문서와 특정 LLM에 의해 생성된 요약에 대해 HHEM 모델이 0에서 1 사이의 환각 점수를 출력하는 것입니다. 점수가 1에 가까울수록 요약본과 소스 문서의 사실적 일관성이 높고, 0에 가까울수록 환각이 더 심하거나 완전히 조작된 내용일 수 있으며, 벡타라는 연구자와 개발자가 현지에서 평가를 수행할 수 있도록 오픈 소스 버전인 HHEM-2.1-Open을 제공하며, 모델 카드도 Hugging Face 플랫폼에 공개하고 있습니다.
평가 벤치마크
평가에는 1006개의 문서로 구성된 데이터 세트가 사용되었으며, 주로 클래식 CNN/Daily Mail 코퍼스와 같은 공개적으로 사용 가능한 데이터 세트가 사용되었습니다. 프로젝트 팀은 평가에 관련된 개별 LLM을 사용하여 각 문서에 대한 요약을 생성한 다음 각 쌍(소스 문서, 생성된 요약)에 대한 HHEM 점수를 계산했습니다. 평가의 표준화를 보장하기 위해 모든 모델 호출은 다음과 같이 설정되었습니다. temperature 이 매개변수는 0이며 모델의 가장 결정적인 출력을 얻기 위한 것입니다.
평가 지표에는 특히 다음이 포함됩니다:
- 환각률. HHEM 점수가 0.5 미만인 초록의 백분율입니다. 값이 낮을수록 좋습니다.
- 사실 일관성 비율. 100%에서 원본에 충실한 초록의 비율을 반영하는 착시 비율을 뺀 값입니다.
- 응답률. 비어 있지 않은 요약을 성공적으로 생성한 모델의 백분율입니다. 일부 모델은 콘텐츠 보안 정책 또는 기타 이유로 인해 답변을 거부하거나 오류를 일으킬 수 있습니다.
- 평균 요약 길이. 생성된 요약의 평균 단어 수는 모델의 출력 스타일을 옆에서 볼 수 있도록 해줍니다.
LLM 일루전 랭킹 설명
아래는 HHEM-2.1 모델 평가에 따른 LLM 환각 순위입니다(2025년 3월 25일 기준 데이터, 실제 업데이트 참조):
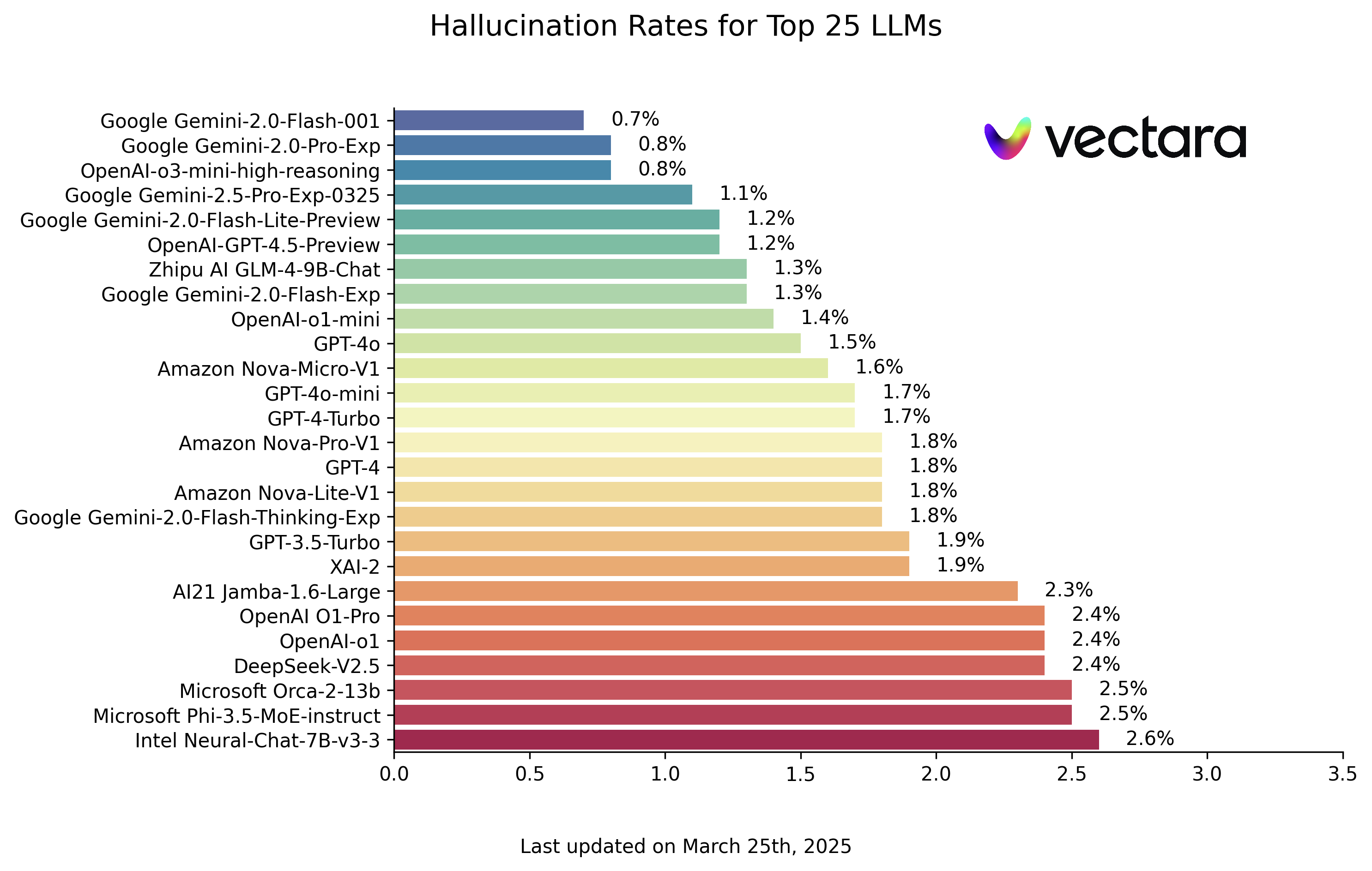
| 모델 | 환각 비율 | 사실 일관성 비율 | 응답률 | 평균 요약 길이(단어) |
|---|---|---|---|---|
| 구글 제미니-2.0-플래시-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| 구글 제미니 2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-고수준 추론 | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| 구글 제미니-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| 구글 제미니-2.0-플래시-라이트-프리뷰 | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-프리뷰 | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| 구글 제미니-2.0-플래시-익스프레스 | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazon Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| 구글 제미니 2.0-플래시-사고력-체험판 | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazon Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 잠바-1.6-대형 | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-인스트럭트 | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| 인텔 뉴럴-챗-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Instruct | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 잠바-1.5-미니 | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-Vision | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| 눈송이-북극-인스트럭트 | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| 미스트랄 Small3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| 구글 제미니-1.5-플래시-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4 미니 인스트럭트 | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| 인턴LM3-8B-인스트럭트 | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5 미니 인스트럭트 | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| 미스트랄-라지2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instruct | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| 클로드-3.7-소네트 | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Claude-3.7-Sonnet-Think | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohere Command-A | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 잠바-1.6-미니 | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| 인류학 클로드-3-5-소네트 | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| 인류학적 클로드-3-5-하이쿠 | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Instruct | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| 코히어 명령-R-플러스 | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| 미스트랄-소형-3.1-24B-인스트럭트 | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| 구글 제미니-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| 구글 제미니-1.5-플래시 | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| 미스트랄-픽스트랄 | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instruct | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| 미스트랄-미니스트랄-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instruct | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| 미스트랄-미니스트랄-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| 데이터브릭 DBRX-인스트럭트 | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| 코히어 아야 익스팬스 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| 미스트랄-스몰2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granite-3.2-8B-Instruct | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instruct-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| 구글 제미니-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| 인류학 클로드-3-옵스 | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| 미스트랄-네모-인스트럭트 | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft WizardLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| 코히어 아야 익스팬스 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| 아마존 타이탄-익스프레스 | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instruct | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-프리뷰 | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| 인류학 클로드-3-소네트 | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instruct | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| 구글 젬마-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| 인류학 클로드-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google 플랜-T5-대형 | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instruct-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instruct | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-인스트럭트 | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII falcon-7B-instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
참고: 모델은 팬텀 비율에 따라 내림차순으로 순위가 매겨집니다. 전체 목록과 모델 액세스 세부 정보는 원래 HHEM 리더보드 GitHub 리포지토리에서 확인할 수 있습니다.
순위표를 살펴보면 Google의 Gemini 시리즈 모델과 OpenAI의 최신 모델 중 일부(예 o3-mini-high-reasoning)는 매우 낮은 수준의 환각률을 유지하며 인상적인 성과를 거두었습니다. 이는 헤드 벤더가 모델의 팩토리얼리티를 개선하는 데 있어 얼마나 많은 진전을 이루었는지 보여줍니다. 동시에 크기와 아키텍처가 다른 모델 간에 상당한 차이를 볼 수 있습니다. Microsoft의 Phi 시리즈 또는 Google의 Gemma 시리즈도 좋은 결과를 얻었는데, 이는 모델 파라미터의 수가 사실의 일관성을 결정하는 유일한 요인이 아니라는 것을 의미합니다. 그러나 일부 초기 모델이나 특별히 최적화된 모델은 상대적으로 착시 비율이 높았습니다.
강력한 추론 모델과 지식 기반 간의 불일치: DeepSeek-R1의 사례
차트(베스트셀러) DeepSeek-R1 상대적으로 높은 환각 비율(14.31 TP3T)은 추론 과제에서 잘 수행되는 일부 모델이 사실 기반 요약 과제에서는 왜 환각에 취약한지 살펴볼 만한 의문을 제기합니다.
DeepSeek-R1 이러한 모델은 복잡한 논리적 추론, 명령 추종 및 다단계 사고를 처리하도록 설계되는 경우가 많습니다. 이들의 핵심 강점은 단순한 '반복'이나 '의역'이 아닌 '추론'과 '연역'에 있습니다. 그러나 지식 기반(특히 RAG (시나리오의 지식 기반), 핵심 요구 사항은 바로 후자입니다. 모델은 외부 지식의 도입이나 과도한 발췌를 최소화하면서 제공된 텍스트 정보를 기반으로 엄격하게 답변하거나 요약해야 합니다.
강력한 추론 모델이 주어진 문서로만 요약하는 것으로 제한되면 '추론' 본능은 양날의 검이 될 수 있습니다. 그럴 수도 있습니다:
- 과잉 해석. 원문의 정보를 불필요하게 깊게 추정하거나 원문에 명시적으로 언급되지 않은 결론을 도출하는 행위.
- 스티칭 정보. 원본 텍스트에서 지원되지 않을 수 있는 "합리적인" 논리 체인을 통해 원본 텍스트의 단편적인 정보를 연결하려고 시도합니다.
- 기본 외부 지식. 원문에만 의존하라고 해도 훈련 과정에서 습득한 방대한 세계 지식이 무의식적으로 스며들어 원문의 사실과 다른 해석이 나올 수 있습니다.
간단히 말해, 이러한 모델은 "너무 많이 생각할 수 있으며", 정보를 정확하고 충실하게 재현해야 하는 시나리오에서는 "너무 똑똑해서" 합리적으로 보이지만 실제로는 착각에 불과한 콘텐츠를 만드는 경향이 있습니다. 이는 모델의 추론 능력과 사실의 일관성(특히 제한된 정보 출처의 경우)이 서로 다른 두 가지 능력 차원임을 보여줍니다. 지식 기반 및 RAG와 같은 시나리오의 경우 단순히 추론 점수를 추구하는 것보다 입력 정보를 충실히 반영하는 환각률이 낮은 모델을 선택하는 것이 더 중요할 수 있습니다.
방법론 및 배경
HHEM 순위는 갑자기 나온 것이 아니며, 다음과 같은 사실 일관성 연구 분야의 여러 이전 노력을 기반으로 하고 있다. SUMMAC, TRUE, TrueTeacher 의 논문에서 확립된 방법론입니다. 핵심 아이디어는 요약과 원본 텍스트의 일관성을 판단하는 측면에서 인간 평가자와 높은 수준의 상관관계를 달성하는 환각 탐지 전용 모델을 훈련하는 것입니다.
요약 작업은 평가 프로세스에서 LLM의 사실성을 대신하는 것으로 선정되었습니다. 이는 요약 작업 자체가 높은 수준의 사실적 일관성을 요구할 뿐만 아니라 RAG 시스템의 작업 모델과 매우 유사하기 때문인데, RAG에서 검색된 정보를 통합하고 요약하는 역할을 하는 것은 LLM입니다. 따라서 이 순위의 결과는 RAG 애플리케이션에서 모델의 신뢰성을 평가하는 데 유용한 정보를 제공합니다.
평가팀은 공정성을 보장하기 위해 모델이 답변을 거부하거나 매우 짧고 잘못된 답변을 제공한 문서는 제외했으며, 최종적으로 모든 모델이 성공적으로 요약을 생성할 수 있었던 831개 문서(원래 1006개)를 최종 순위 계산에 사용했습니다. 정답률과 평균 요약 길이 메트릭은 이러한 요청을 처리할 때 모델의 행동 패턴도 반영합니다.
평가에 사용되는 프롬프트 템플릿은 다음과 같습니다:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
실제 통화 시에는<PASSAGE> 는 특정 소스 문서 콘텐츠로 대체됩니다.
기대
HHEM 순위 프로그램은 향후 평가 범위를 확대할 계획이라고 밝혔습니다:
- 인용 정확도. RAG 시나리오에서 출처 인용에 대한 LLM의 정확성에 대한 평가를 추가합니다.
- 기타 RAG 작업. 다중 문서 요약과 같은 더 많은 RAG 관련 작업을 처리할 수 있습니다.
- 다국어 지원. 영어 이외의 언어로 평가를 확장합니다.
HHEM 순위는 일루전을 제어하고 사실의 일관성을 유지하는 여러 LLM의 능력을 관찰하고 비교할 수 있는 유용한 창구를 제공합니다. 모델 품질을 측정하는 유일한 척도는 아니며 모든 유형의 일루전을 포괄하지는 않지만, 확실히 LLM 신뢰성 문제에 대한 업계의 관심을 이끌어냈고 개발자가 모델을 선택하고 최적화하는 데 중요한 기준점을 제공합니다. 모델과 평가 방법이 계속 개선됨에 따라 LLM의 정확하고 신뢰할 수 있는 정보 제공이 더욱 발전할 것으로 기대할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...