

문서 이미지 이해 기술은 컴퓨터가 문서 이미지의 내용을 사람처럼 이해할 수 있도록 하는 것을 목표로 합니다. 주로 스캔 또는 사진 촬영을 통해 얻은 문서 이미지(예: 종이 계약서, 책 페이지, 송장 등)를 분석, 처리, 이해하여 텍스트, 표, 차트 등의 중요한 정보를 추출하고 이 정보를 구조화하는 작업을 포함합니다. 오늘날 디지털 혁신의 물결 속에서 문서 이미지 이해 기술은 비즈니스, 학계, 일상 생활에서 문서 처리 효율성과 정확성을 높이기 위해 널리 사용되고 있습니다.
이전에 페이패들은 웬신 빅 모델과 결합하여 먼저 OCR 기술을 사용하여 이미지의 텍스트를 추출한 다음 이를 웬신 빅 모델에 입력하여 퀴즈를 분석하는 PP-ChatOCRv3 크기 모델 융합 솔루션을 출시하여 궁극적으로 텍스트-이미지 레이아웃 파싱 및 정보 추출 효과를 크게 향상시켰습니다. 이 방식은 텍스트와 표에 대해서는 매우 정확하지만 문서의 이미지와 차트를 이해하는 능력은 더 개선되어야 합니다. 따라서 복잡하고 다양한 문서 이미지 이해 작업에 대한 사용자의 요구를 더 잘 충족시키기 위해 멀티모달 대형 모델을 기반으로 엔드투엔드 문서 이미지 이해를 달성하는 새로운 체계인 PP-DocBee를 제안합니다. 문서 이해, 문서 Q&A 등 모든 종류의 시나리오에 효율적으로 적용할 수 있으며 특히 재무 보고서, 법률 및 규정, 논문, 매뉴얼, 계약서, 연구 보고서 등과 같은 중국어 문서 이해 시나리오에서 성능이 매우 우수합니다.
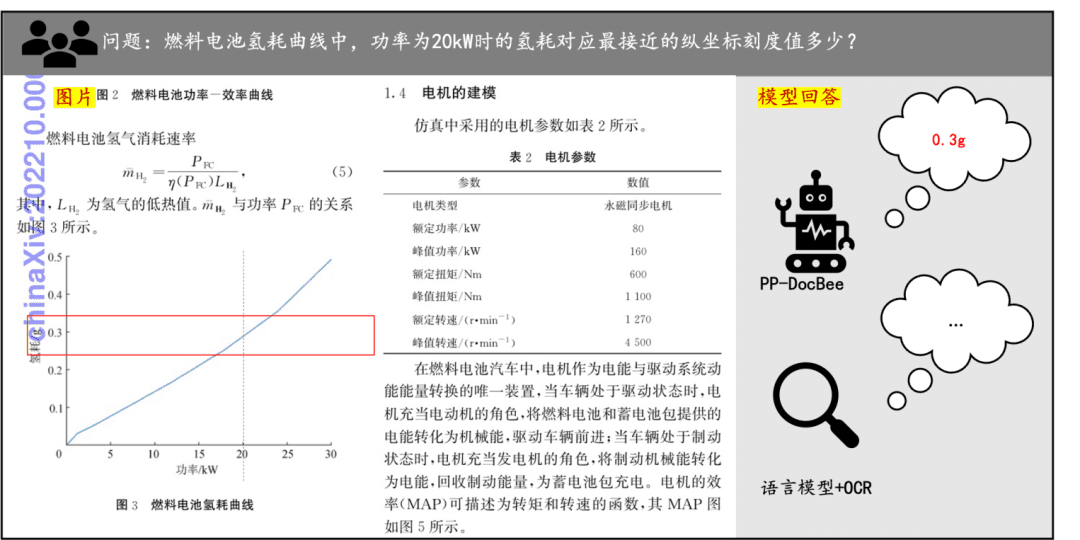
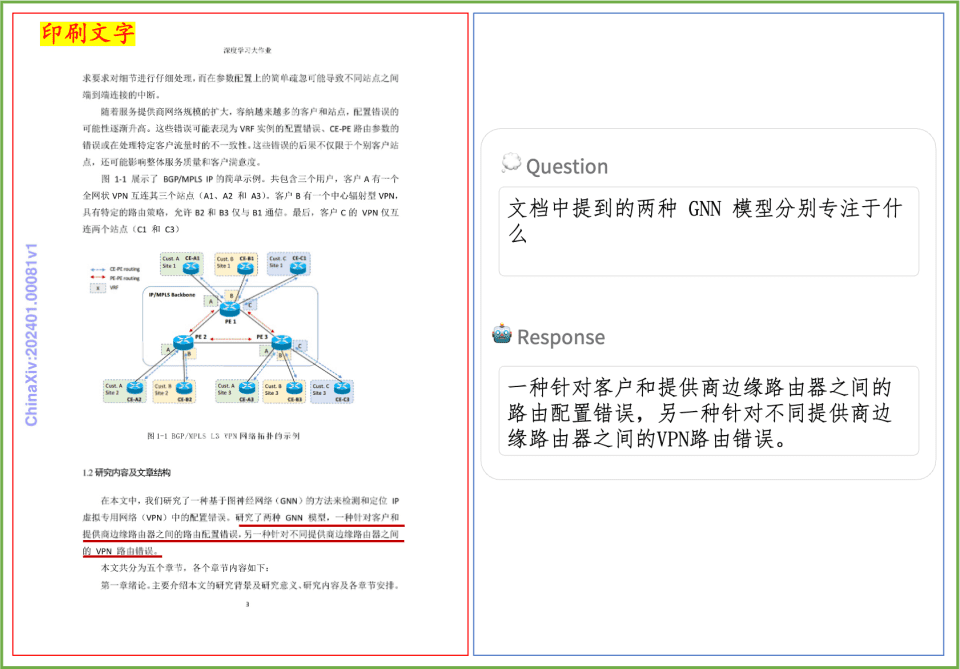
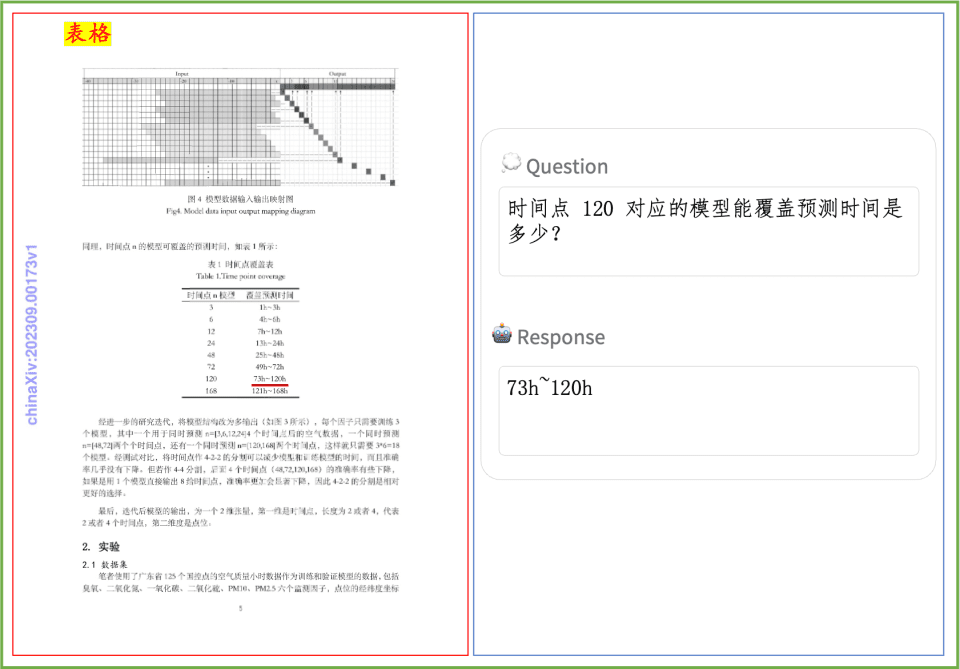
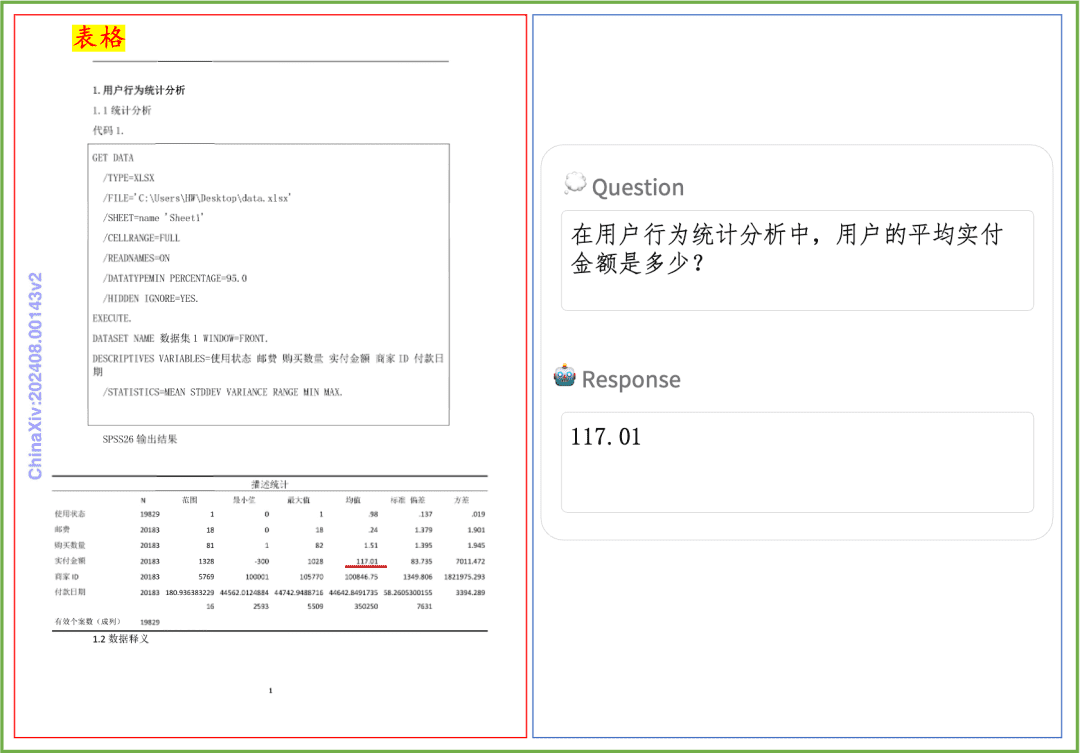
문서 이해 예제 인쇄된 텍스트, 표, 차트 및 기타 문서의 문서 이해에 대한 PP-DocBee의 효과를 간단히 살펴봅니다:


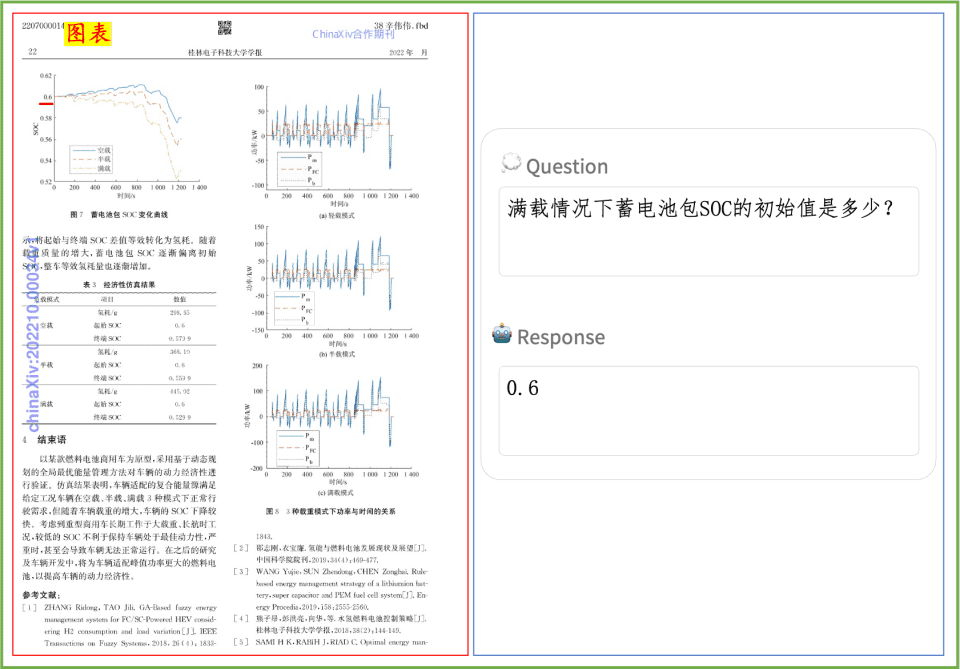
PP-DocBee는 기본적으로 학계의 권위 있는 여러 영어 문서 이해력 평가 목록에서 동일한 매개변수 볼륨 수준의 모델에 대해 SOTA를 달성했습니다.
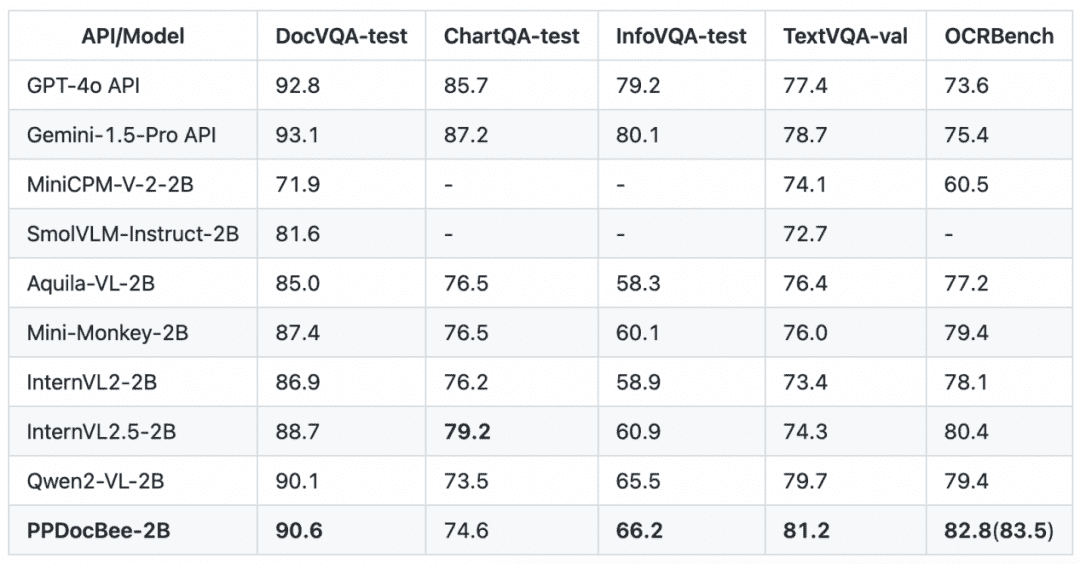
영어 문서 이해력 검토 목록 경쟁사 비교
참고: OCRBench 지표는 100점 척도로 정규화되었으며, PPDocBee-2B의 OCRBench 지표는 엔드투엔드 평가의 경우 82.8점, OCR 후처리 지원 평가의 경우 83.5점을 받았습니다. 또한 PP-DocBee는 내부 비즈니스 중국어 시나리오 지표 카테고리에서 현재 널리 사용되는 오픈 소스 및 폐쇄 소스 모델보다 높습니다.
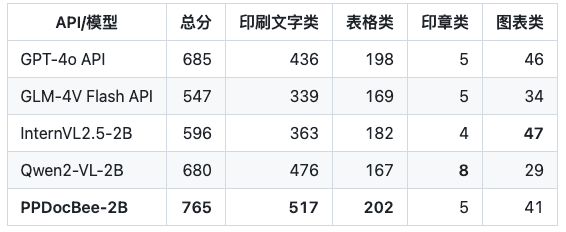
비즈니스 중국어 시나리오 경쟁사 비교
참고: 내부 업무용 중국어 시나리오 평가 세트에는 재무 보고서, 법률 및 규정, 과학 및 기술 논문, 매뉴얼, 교양 논문, 계약서, 연구 논문 등의 시나리오가 포함되어 있으며 인쇄 텍스트, 양식, 인장 및 도표의 4가지 주요 범주로 나뉩니다.
다음 표와 같이 PP-DocBee 추론 성능을 더욱 향상시키기 위해 연산자 융합 최적화를 통해 추론 경과 시간 51.51 TP3T, 총 엔드투엔드 경과 시간 41.91 TP3T 단축을 달성했습니다.
| PP-DocBee | 평균 엔드 투 엔드 시간 | 평균 사전 처리 시간(초) | 추론에 소요되는 평균 시간(초) |
| 기본 버전 | 1.60 | 0.29 | 1.30 |
| 고성능 에디션 | 0.93 | 0.29 | 0.63 |
참고: 고성능 버전은 기본적으로 기본 버전과 동일한 양의 입력 토큰과 동일한 양의 출력 토큰을 가지고 있습니다. 플라잉 패들 고성능 최적화 덕분에 PP-DocBee는 답변의 품질을 유지하면서 더 빠르게 응답합니다. 이 고성능 추론 버전에 대한 자세한 내용은 https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee 에서 확인할 수 있습니다.
또한 플라잉 패들 스타 리버 커뮤니티를 위한 온라인 체험 환경을 제공하고 있으며, 플라잉 패들 스타 리버 커뮤니티 신청 센터(https://aistudio.baidu.com/application/detail/60135)를 통해 PP-DocBee의 기능을 빠르게 체험해 볼 수 있습니다.
또한 로컬 그라디오 배포, OpenAI 서비스 배포 및 자세한 지침도 제공하고 있으며, 사용자 및 애호가들은 프로젝트 홈페이지(https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/)를 방문하시기 바랍니다. examples/ppdocbee
PP-DocBee 프로그램 소개
PP-DocBee 모델 구조는 ViT+MLP+LLM 아키텍처를 사용하여 다음 그림에 나와 있습니다. 문서 이해 시나리오에 대한 최적화 아이디어는 다음과 같습니다.데이터 합성 전략, 데이터 전처리, 교육 방법 및 OCR 후처리 지원결국 이 모델은 일반적인 문서 이해와 중국어 시나리오의 강력한 문서 구문 분석이 모두 가능합니다.

PP-DocBee 모델 구조
특히 PP-DocBee에는 다음과 같은 주요 개선 사항이 포함되어 있습니다:
1. 데이터 종합 전략
부족한 중국어 능력과 장면 데이터 부족 문제를 해결하기 위해 문서 유형 데이터를 위한 지능형 생산 솔루션을 설계하고, 문서, 표, 차트 등 세 가지 주요 데이터 세트 유형별로 다른 데이터 생성 링크를 설계했으며, OCR 소형 모델과 LLM 대형 모델의 조합, 렌더링 엔진 기반 이미지 데이터 생산, 문서 유형별 맞춤형 데이터 생산 등 다양한 전략을 채택했습니다. 프롬프트 템플릿 등을 통해 Q&A 품질을 높이고 생성 비용을 통제할 수 있게 되었습니다. 자세한 내용은 아래 그림에서 확인할 수 있습니다:
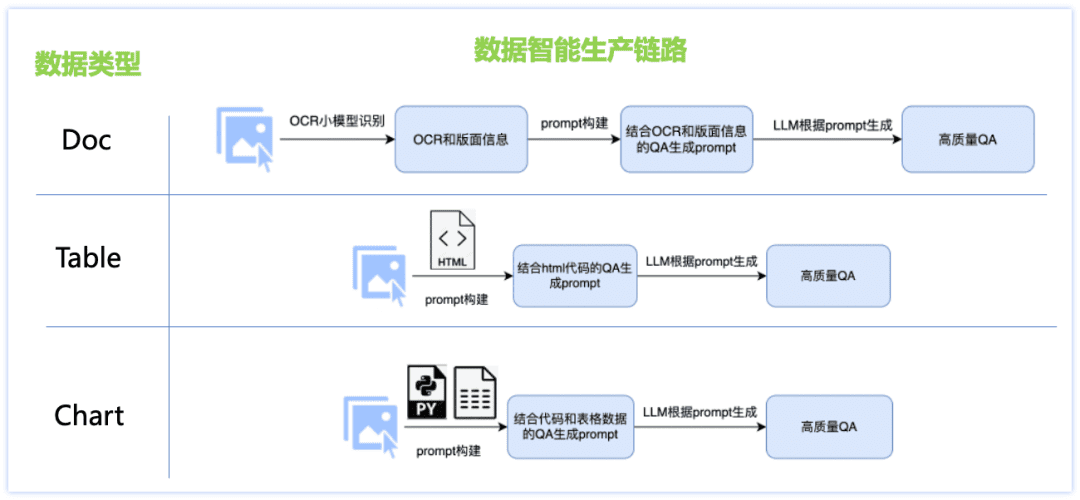
문서 클래스 데이터:
사진: 논문, 재무 보고서, 연구 논문 및 기타 PDF 파일을 수집하고 정리하고, PDF 분석 도구와 결합하여 방대한 단일 페이지 문서 사진 데이터를 생성합니다;
Q&A: ocr 소형 모델은 상세한 그림 레이아웃 정보를 추출하여 대형 모델의 시각적 인식의 단점을 보완하는 동시에 대형 언어 모델의 강력한 텍스트 이해 능력을 사용하여 ocr 소형 모델의 개별 문자 인식의 부정확성을 수정함으로써 이 둘을 결합하여 고품질의 유형 제어 가능한 Q&A를 생성할 수 있습니다.
테이블 클래스 데이터:
이미지: HTML 텍스트 정보가 포함된 표 이미지를 기반으로 빅 언어 모델을 통해 텍스트의 값, 제목 및 기타 정보를 변경하고 표 렌더링 도구를 통해 콘텐츠가 풍부한 고품질 표 이미지를 얻습니다.
Q&A: 답변의 정확성을 보장하기 위해 표 이미지에 해당하는 HTML 형식의 텍스트를 GT 보조 정보로 사용하고, 대규모 언어 모델을 통해 고품질의 Q&A를 생성하기 위해 미세 조정된 프롬프트를 디자인했습니다.
차트 클래스 데이터:
이미지: 크라우드 테스트를 거친 고품질 차트 소스 데이터(이미지-코드-테이블 데이터)를 기반으로 차트의 숫자 값, 축, 범례, 테마 등 세분화된 정보를 대규모 언어 모델을 통해 코드에 임의로 변경하고 다양한 내용의 소스 코드를 가져와 차트 렌더링 도구(Matplotlib, Seaborn, Vega-Lite등)를 사용하여 고품질 차트 이미지 데이터를 얻습니다;
Q&A: 차트 이미지와 표 데이터에 해당하는 코드를 GT 보조 정보로 사용하여 답변의 정확성을 보장하고, 해당 유형의 질문은 다양한 유형의 차트에 맞게 설계되었으며, 미세 조정 된 프롬프트는 대규모 언어 모델을 통해 고품질의 Q&A를 생성하도록 설계되었습니다. 위의 문서 유형 데이터 지능형 생산 체계를 통해 방대한 양의 합성 데이터를 확보하고 그중 일부를 PP-DocBee 학습 데이터 중 하나로 필터링하여 (데이터 분포는 아래 그림 참조) 모델 기능을 효과적으로 향상시킵니다.
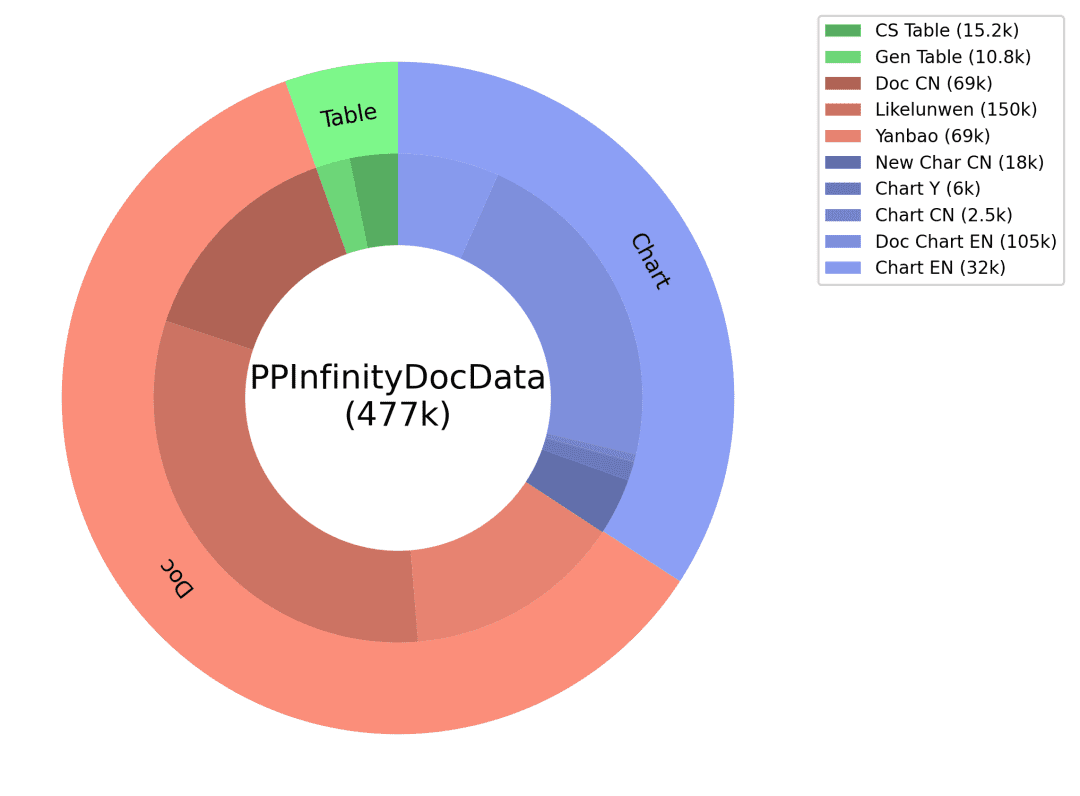
합성 데이터 배포
2. 데이터 전처리
하나는 훈련 중에 더 큰 크기 조정 임계값을 설정하여 데이터 세트의 전체 해상도 분포를 높이는 것이고, 다른 하나는 추론 중에 대부분의 일반 이미지에 대해 1.1~1.3배의 동일한 배율을 설정하고 저해상도 이미지의 경우 원본 데이터 전처리 전략을 변경하지 않는 것입니다. 이 두 가지 전략은 보다 적절하고 포괄적인 시각적 특징을 생성하여 최종 이해도를 향상시켰습니다.
3. 교육 방법
주로 다양한 문서 이해 클래스의 데이터가 혼합되어 있으며 데이터 매칭 메커니즘이 설정되어 있습니다. 다양한 데이터 세트에는 일반 VQA 클래스, OCR 클래스, 다이어그램 클래스, 텍스트가 풍부한 문서 클래스, 수학 및 복잡한 추론 클래스, 합성 데이터 클래스, 일반 텍스트 데이터 등이 포함됩니다. 데이터 매칭 메커니즘은 여러 클래스 및 클래스 간 서로 다른 데이터 소스에 대한 샘플링 비율을 설정하여 이득이 큰 여러 클래스 데이터의 샘플링 가중치를 높이고 다양한 데이터 세트 간의 양적 차이의 균형을 맞추기 위해 설정합니다.
4.OCR 후처리 지원
주로 텍스트 결과를 미리 OCR 툴이나 모델을 통해 OCR 인식을 한 다음 그림 퀴즈 문항에서 제공되는 보조 선험적 정보로 PP-DocBee 모델 추론에 텍스트가 많지 않고 선명한 그림이 개선에 어느 정도 영향을 줄 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...