

Doubao-1.5-pro
🌟 모델 프로필
Doubao-1.5-pro는 매우 드물게 MoE 아키텍처프리필/디코드 및 주의/FFN의 네 사분면에서는 계산 및 액세스 특성이 크게 다릅니다. 네 개의 다른 사분면에 대해 서로 다른 저정밀 최적화 전략과 결합된 이기종 하드웨어를 채택하여 낮은 지연 시간을 보장하면서 처리량을 크게 늘리고, TTFT 및 TPOT의 최적화 목표를 고려하면서 총 비용을 절감하여 성능과 추론 효율성 간의 궁극적인 균형을 달성합니다.
- 부 활성화 매개변수매우 큰 고밀도 모델의 성능을 능가합니다.
- 멀티 씬 적응여러 리뷰 벤치마크에서 우수한 성능을 발휘합니다.
📊 성능 평가
여러 벤치마크에서의 Doubao-1.5-pro 결과
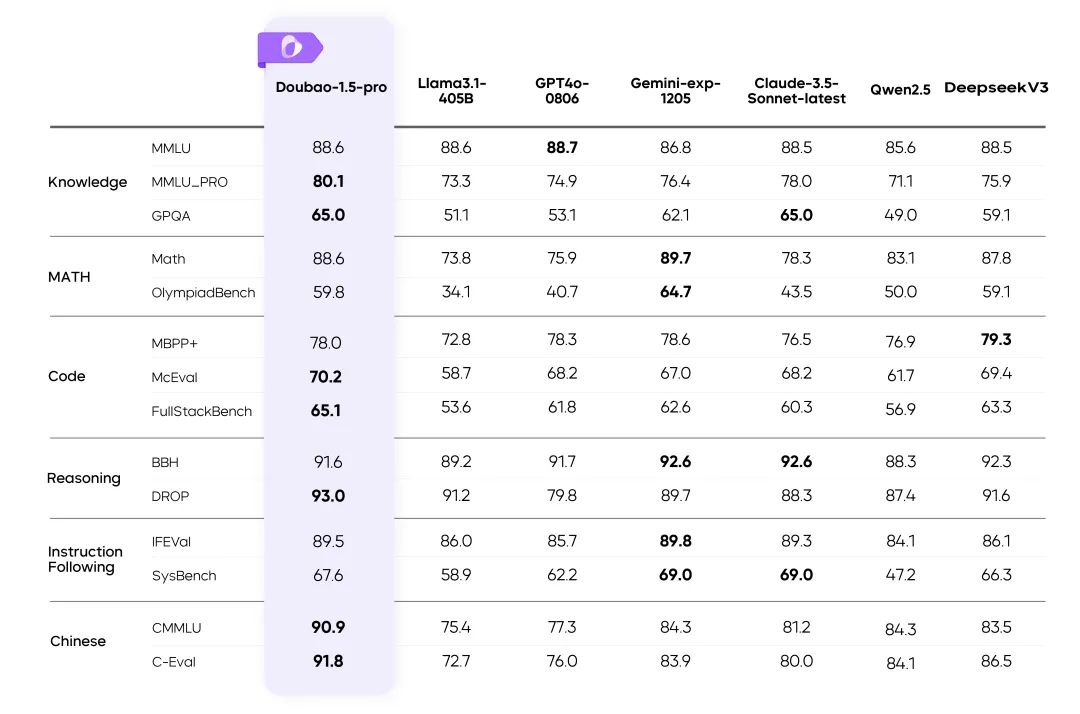
지침::
- 표의 나머지 모델에 대한 지표는 공식 결과에서 가져온 것이며, 공개되지 않은 부분은 내부 평가 플랫폼에서 수행한 것입니다.
- GPT4o-0806 언어 모델에 대한 공개 리뷰에서 우수한 성능은 간단한 평가를 참조하세요.
⚙️ 성능과 추론의 균형 맞추기
효율적인 MoE 아키텍처
- 활용 스파스 MoE 아키텍처 교육과 추론 효율의 이중 최적화를 달성합니다.
- 연구 하이라이트희소성 스케일링 법칙을 통해 성능과 효율성의 최적 균형 비율을 결정합니다.
교육 손실 대

모델 성능 비교
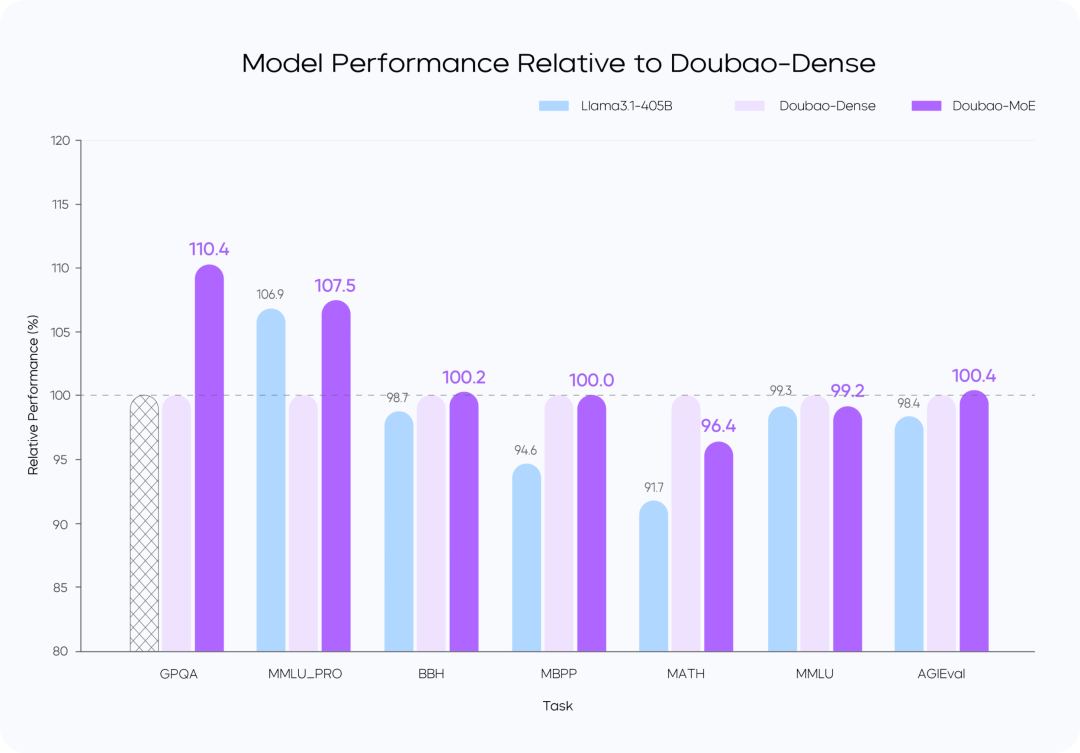
지침::
- Doubao-MoE 모델은 활성화된 매개변수 수가 7배 더 많은 밀도 모델(Doubao-Dense)보다 성능이 뛰어납니다.
- Doubao 고밀도 모델 트레이닝은 다음보다 더 효율적입니다. Llama 3.1-405B데이터 품질과 하이퍼레퍼런스 최적화가 핵심입니다.
🚀 고성능 추론
계산 및 액세스 기능 최적화
Doubao-1.5-pro는 프리필, 디코드, 어텐션, FFN의 네 가지 계산 쿼드런트에서 우수한 성능을 발휘합니다.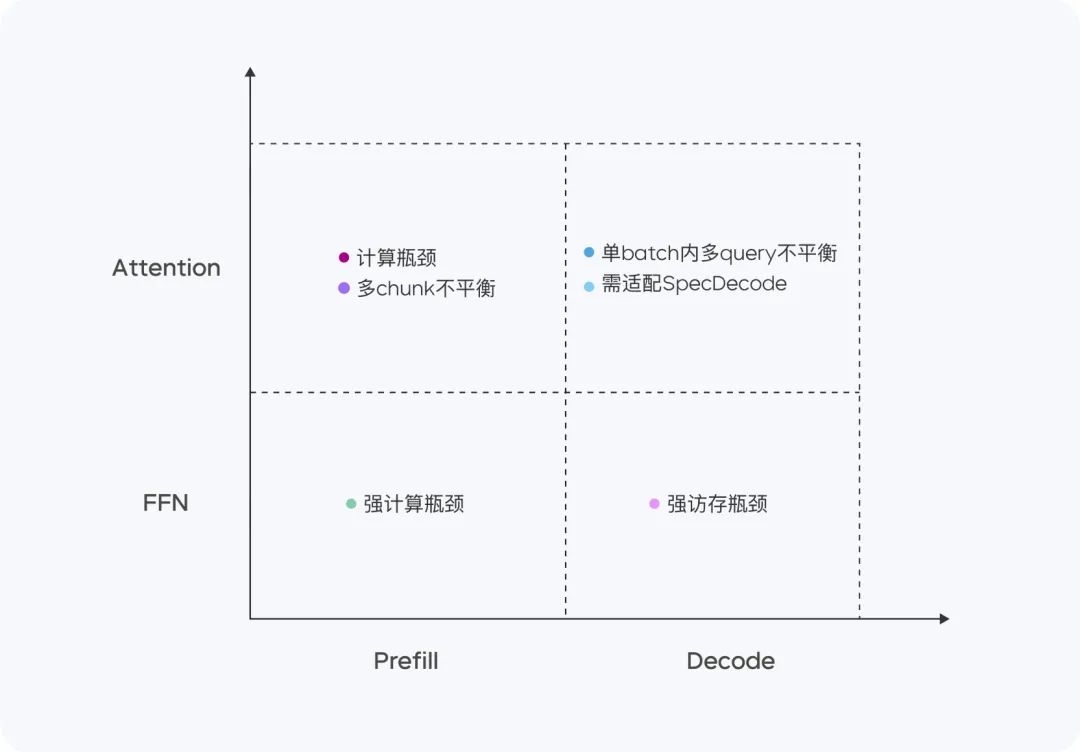
프리필 단계에서는 통신 및 액세스 병목현상이 뚜렷하지 않지만 계산 병목현상에 쉽게 도달합니다. LLM 단방향 주의의 특성을 고려하여 계산 액세스 비율이 높은 여러 장치에서 청크-PP 프리필 서비스를 수행하여 온라인 시스템에서 텐서 코어의 사용률이 60%에 가깝도록 합니다.
- 프리필 어텐션: 오픈 소스 플래시어텐션 8비트 구현을 MMA/WGMMA와 같은 명령어와 Per N과 결합하여 확장합니다. 토큰 시퀀스별 양자화 전략은 이 단계가 서로 다른 아키텍처의 GPU에서 무손실로 실행될 수 있도록 보장합니다. 한편, 길이가 다른 슬라이스의 주의 소비를 모델링하고 동적 교차 쿼리 배치 전략과 결합하여 청크-PP 서버링 중에 카드 간 밸런싱을 달성함으로써 부하 불균형으로 인한 빈 실행을 효과적으로 제거합니다;
- FFN 미리 채우기: W4A8 정량화는 희소한 MoE 전문가의 액세스 오버헤드를 효과적으로 줄이고 교차 쿼리 배치 전략을 통해 FFN 단계에 더 많은 입력을 제공하여 MFU를 0.8로 향상시킵니다.
디코딩 단계에서는 계산 병목 현상이 뚜렷하지 않지만 통신 및 메모리 요구량이 상대적으로 높습니다. 우리는 더 높은 ROI를 달성하기 위해 연산 및 액세스 메모리가 적은 장치인 Serving을 사용하며, 동시에 매우 저렴한 샘플링 및 추측 디코딩 전략을 사용하여 TPOT 지표를 줄입니다.
- 디코딩 어텐션: TP는 휴리스틱 검색과 공격적인 긴 문장 분할 전략을 통해 단일 배치 내에서 서로 다른 쿼리의 KV 길이가 크게 차이가 나는 일반적인 시나리오를 최적화하기 위해 배포되며, 정확도 측면에서는 여전히 N 토큰당 시퀀스 정량화를 채택하고, 무작위 샘플링 중 어텐션 계산을 최적화하여 KV 캐시에 한 번만 액세스하도록 보장합니다. 또한 무작위 샘플링 과정 중 Attention 계산을 최적화하여 KV 캐시가 한 번만 액세스되도록 합니다.
- FFN 디코딩: EP를 사용하여 W4A8을 정량화하여 배포합니다.
전반적으로 PD 분리 서빙 시스템에서 다음과 같은 최적화를 구현했습니다:
- 텐서 전송을 위한 맞춤형 RPC 백엔드, 제로 카피, 멀티 스트림 병렬 처리 등을 통해 TCP/RDMA 네트워크를 통한 텐서 전송 효율을 최적화하여 PD 분리 하에서 KV 캐시 전송 효율을 향상시켰습니다.
- 프리필 및 디코드 클러스터의 유연한 할당과 동적 확장 및 축소를 지원하고, 각 역할에 대해 독립적으로 HPA 탄력 확장을 수행하여 프리필과 디코드 모두 중복 산술이 없고 양측의 산술 할당이 실제 온라인 트래픽 패턴과 일치하도록 보장합니다.
- GPU 컴퓨팅과 CPU 전처리 및 후처리를 비동기식으로 처리하는 프레임워크에서 CPU가 N + 1 단계 커널을 조기 실행할 때 GPU 추론 단계 N이 GPU를 항상 가득 채우도록 하여 GPU 추론의 전체 프레임워크 처리 작업을 오버헤드 제로로 유지합니다. 또한 자체 개발한 서버 클러스터 솔루션과 저가 칩에 대한 유연한 지원으로 하드웨어 비용이 업계 솔루션보다 현저히 낮습니다. 또한 맞춤형 NIC와 자체 개발한 네트워크 프로토콜을 통해 패킷 통신의 효율성을 크게 최적화했습니다. 산술 수준에서는 연산과 통신 간의 효율적인 중첩(오버랩)을 달성하여 다중 컴퓨터 분산 추론의 안정성과 효율성을 보장합니다.
🎯 데이터 라벨링: 바로 가기 없음
- 다음을 결합한 효율적인 데이터 생산 시스템 구축 라벨링 팀 노래로 응답 셀프 리프팅 기술 모델링데이터의 품질이 크게 향상되었습니다.
🖼️ 멀티모달 기능
시각적 멀티모달리티: 복잡한 장면을 쉽게 촬영하기
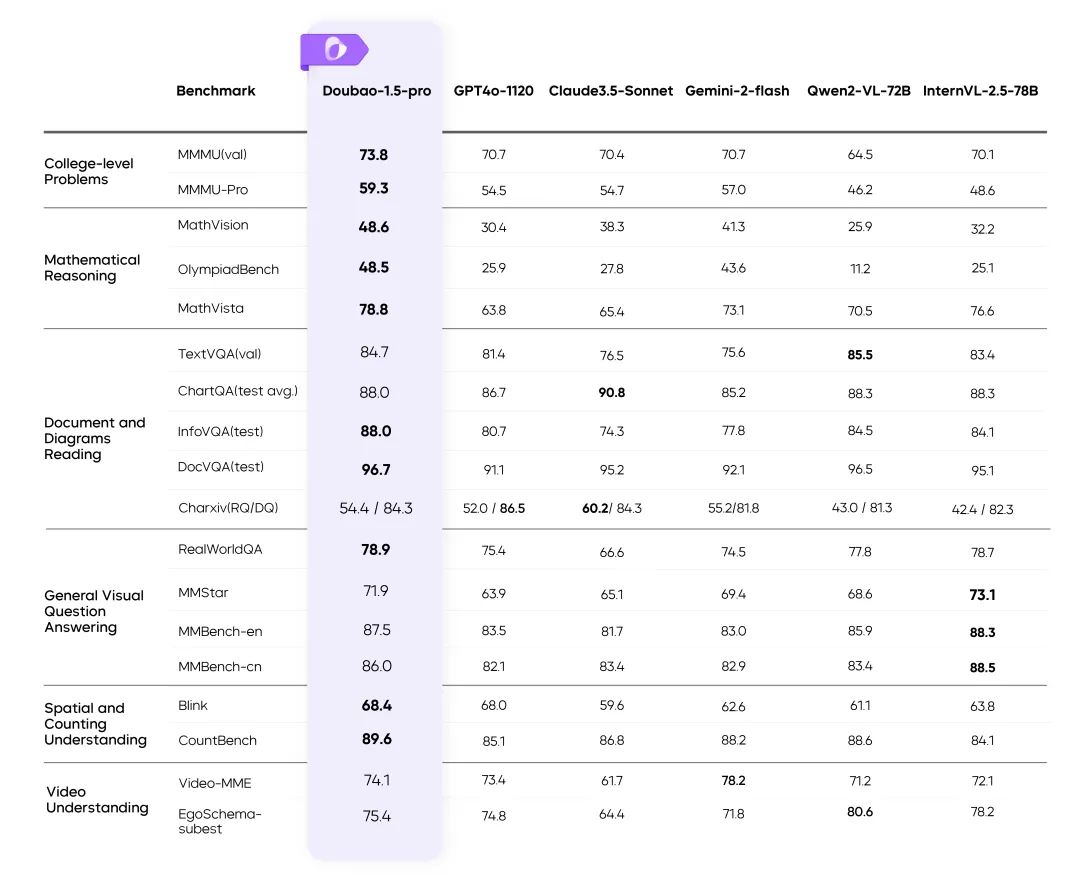
동적 해상도 교육: 처리량 향상 60%
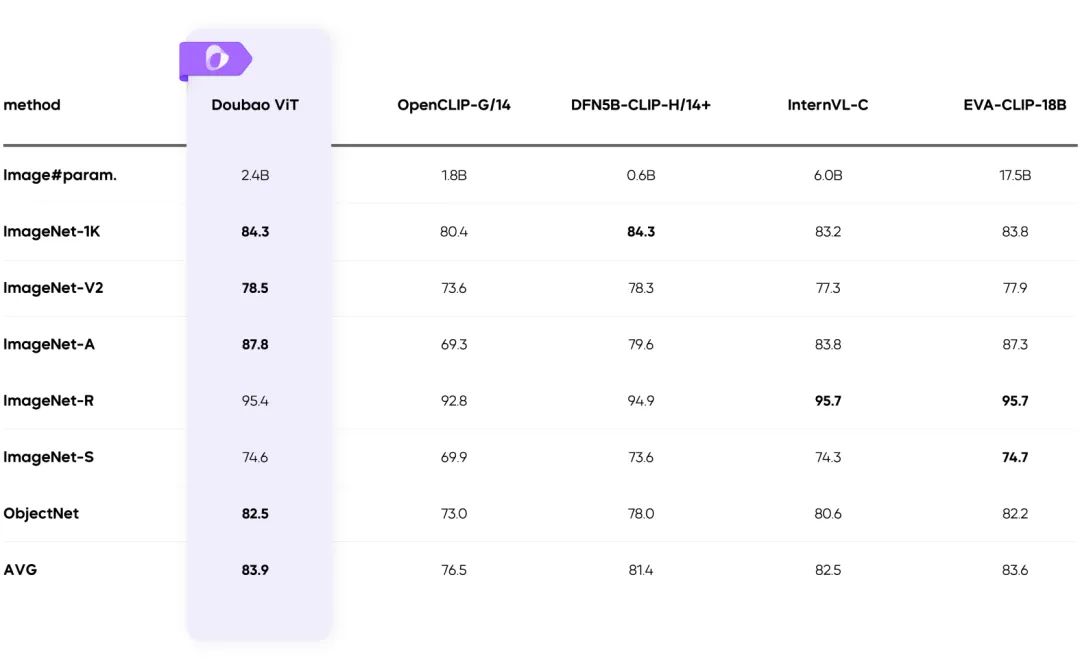
- 비주얼 인코더의 고르지 않은 부하 문제를 해결하고 효율성을 크게 개선하세요.
✅ 요약
Doubao-1.5-pro는 고성능과 낮은 추론 비용 사이에서 최적의 균형을 찾고, 멀티모달 시나리오에서 획기적인 발전을 이룹니다:
- 혁신적인 스파스 아키텍처 설계.
- 고품질 교육 데이터 및 최적화 시스템.
- 멀티모달 기술의 새로운 벤치마크를 주도합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...