

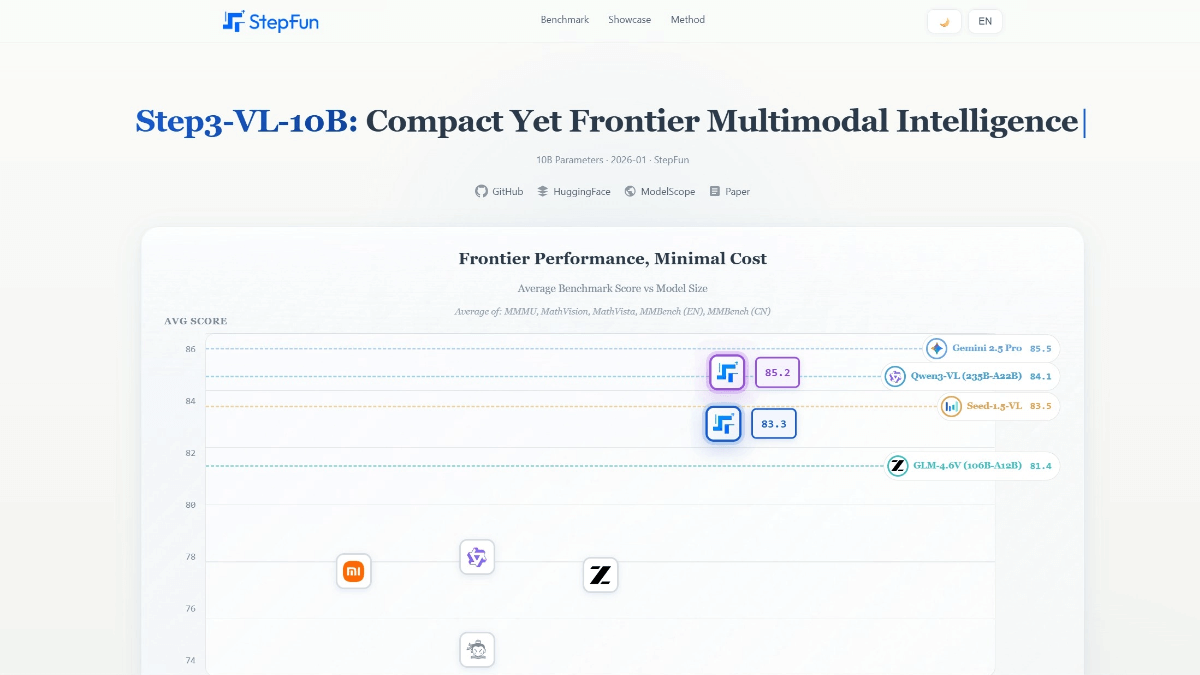
일반 소개
DeepSeek-R1-FP4는 NVIDIA에서 오픈 소스화하여 최적화한 정량화된 언어 모델입니다. DeepSeek AI의 DeepSeek-R1 개발. 이 모델은 TensorRT 모델 옵티마이저를 사용해 가중치와 활성화 값을 FP4 데이터 유형으로 정량화하여 고성능을 유지하면서 리소스 요구 사항을 크게 줄일 수 있습니다. 원래 모델에 비해 디스크 공간과 GPU 메모리가 약 1.6배 더 적기 때문에 프로덕션 환경에서 효율적인 추론에 이상적입니다. NVIDIA의 블랙웰 아키텍처에 특별히 최적화된 이 모델은 추론 당 최대 25배 빠른 속도를 제공한다고 합니다. 토큰 20배 더 저렴하고 강력한 성능 잠재력을 보여줍니다. 최대 128K의 컨텍스트 길이를 지원하므로 복잡한 텍스트 작업을 처리하는 데 적합하며 상업적 및 비상업적 용도로 모두 사용할 수 있어 개발자에게 비용 효율적인 AI 솔루션을 제공합니다.

기능 목록
- 효율적인 추론FP4 정량화를 사용하여 추론 속도를 획기적으로 개선하고 리소스 사용을 최적화합니다.
- 긴 컨텍스트 지원: 긴 텍스트 생성 작업을 처리하는 데 적합한 최대 128K의 컨텍스트 길이를 지원합니다.
- TensorRT-LLM 배포TensorRT-LLM 프레임워크를 사용하여 NVIDIA GPU에서 실행되도록 신속하게 배포할 수 있습니다.
- 오픈 소스 사용:: 상업적 및 비상업적 시나리오를 지원하여 자유로운 수정 및 파생 상품 개발이 가능합니다.
- 성능 최적화블랙웰 아키텍처용으로 설계되어 매우 높은 추론 효율성과 비용 효율성을 제공합니다.
도움말 사용
설치 및 배포 프로세스
DeepSeek-R1-FP4를 배포하려면 특정 하드웨어 및 소프트웨어 환경, 특히 NVIDIA GPU 및 TensorRT-LLM 프레임워크 지원이 필요합니다. 아래는 사용자가 빠르게 시작하는 데 도움이 되는 자세한 설치 및 사용 가이드입니다.
1. 환경 준비
- 하드웨어 요구 사항모델 요구 사항을 충족하기 위해 최소 8개의 GPU(각각 ~336GB의 VRAM 비정량화, ~1342GB의 정량화 후)가 필요한 NVIDIA Blackwell 아키텍처 GPU(예: B200)가 권장됩니다. 소규모 테스트의 경우 최소 1개의 고성능 GPU(예: A100/H100)가 권장됩니다.
- 소프트웨어 종속성:
- 운영 체제: Linux(예: Ubuntu 20.04 이상).
- NVIDIA 드라이버: 최신 버전(CUDA 12.4 이상 지원).
- TensorRT-LLM: 최신 마스터 브랜치 버전은 GitHub 소스에서 컴파일해야 합니다.
- Python: 3.11 이상.
- 기타 라이브러리:
tensorrt_llm및torch등
2. 모델 다운로드
- 인터뷰 허깅 페이스 페이지'파일 및 버전' 탭을 클릭합니다.
- 모델 파일 다운로드(예
model-00001-of-00080.safetensors(등, 총 80개 슬라이스, 총 용량 400GB 이상). - 파일을 로컬 디렉터리에 저장합니다(예
/path/to/model/.
3. TensorRT-LLM 설치하기
- GitHub에서 최신 TensorRT-LLM 리포지토리를 복제합니다:
git clone https://github.com/NVIDIA/TensorRT-LLM.git cd TensorRT-LLM
- 컴파일하고 설치합니다:
make build pip install -r requirements.txt - 설치를 확인합니다:
python -c "import tensorrt_llm; print(tensorrt_llm.__version__)"
4. 배포 모델
- 제공된 예제 코드를 사용하여 모델을 로드하고 실행합니다:
from tensorrt_llm import SamplingParams, LLM # 初始化模型 llm = LLM( model="/path/to/model/nvidia/DeepSeek-R1-FP4", tensor_parallel_size=8, # 根据 GPU 数量调整 enable_attention_dp=True ) # 设置采样参数 sampling_params = SamplingParams(max_tokens=32) # 输入提示 prompts = [ "你好,我的名字是", "美国总统是", "法国的首都是", "AI的未来是" ] # 生成输出 outputs = llm.generate(prompts, sampling_params) for output in outputs: print(output) - 위의 코드를 실행하기 전에 GPU 리소스가 올바르게 할당되었는지 확인하세요. 리소스가 부족한 경우, 리소스가 부족한 경우
tensor_parallel_size매개변수.
5. 기능별 작동 가이드
효율적인 추론
- DeepSeek-R1-FP4의 핵심 강점은 FP4 양자화 기술입니다. 사용자는 모델 파라미터를 수동으로 조정하는 대신 하드웨어가 블랙웰 아키텍처를 지원하는지 확인하기만 하면 추론 속도가 향상되는 것을 경험할 수 있습니다. 런타임에 다음을 설정하는 것이 좋습니다.
max_tokens매개변수는 리소스 낭비를 방지하기 위해 출력 길이를 제어합니다. - 수행 방법의 예: 터미널에서 Python 스크립트를 실행하고 다양한 프롬프트를 입력한 후 출력 속도와 품질을 관찰합니다.
긴 컨텍스트 처리
- 이 모델은 최대 128K의 컨텍스트 길이를 지원하므로 긴 글을 생성하거나 복잡한 대화를 처리하는 데 적합합니다.
- 작동: 다음에서
prompts5,000단어짜리 글의 시작 부분과 같이 긴 문맥을 입력한 다음max_tokens=1000텍스트는 다음 텍스트와 동일한 방식으로 생성됩니다. 실행 후 생성된 텍스트의 일관성을 확인합니다. - 주의: 컨텍스트가 길면 메모리 사용량이 증가할 수 있으므로 GPU 메모리 사용량을 모니터링하는 것이 좋습니다.
성능 최적화
- Blackwell GPU를 사용하는 경우, 추론 속도가 25배 빨라지는 직접적인 이점을 누릴 수 있습니다. 다른 아키텍처(예: A100)를 사용하는 경우, 성능 향상은 약간 낮을 수 있지만 여전히 정량화되지 않은 모델보다 훨씬 우수합니다.
- 운영 제안: 멀티 GPU 환경에서는 다음과 같이 조정하세요.
tensor_parallel_size매개변수를 설정하여 하드웨어 리소스를 최대한 활용할 수 있습니다. 예를 들어 GPU 8개는 8개로 설정하고 GPU 4개는 4개로 설정합니다.
6. 자주 묻는 질문 및 해결 방법
- 비디오 메모리 부족메모리 오버플로우를 묻는 메시지가 표시되면 다음을 줄입니다.
tensor_parallel_size또는 덜 정량화된 버전(예: 커뮤니티에서 제공하는 GGUF 형식)을 사용하세요. - 느린 추론TensorRT-LLM이 올바르게 컴파일되고 GPU 가속이 활성화되었는지 확인하고 드라이버 버전이 일치하는지 확인합니다.
- 출력 이상입력 프롬프트 형식을 확인하여 특수 문자가 모델에 방해가 되지 않도록 합니다.
사용 권장 사항
- 초기 사용간단한 힌트로 시작하여 점차 컨텍스트 길이를 늘려 모델 성능에 익숙해지도록 합니다.
- 프로덕션 환경배포하기 전에 여러 프롬프트 세트를 테스트하여 출력이 기대치를 충족하는지 확인하세요. 로드 밸런싱 도구를 사용하여 다중 사용자 액세스를 최적화하는 것이 좋습니다.
- 개발자 사용자 지정:: 코드 생성이나 Q&A 시스템과 같은 특정 작업에 맞게 오픈 소스 라이선스를 기반으로 모델을 수정할 수 있습니다.
이러한 단계를 통해 사용자는 DeepSeek-R1-FP4를 신속하게 배포하고 사용하여 효율적인 추론의 편리함을 누릴 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...