
DeepSeek-OCR이란 무엇인가요?
DeepSeek-OCR은 DeepSeek 이 팀의 오픈소스 고급 광학 문자 인식(OCR) 모델은 '문맥 광학 압축' 기술을 사용하여 텍스트를 이미지로 변환합니다. 토큰 효율적인 긴 텍스트 처리를 위한 압축 및 디코딩이 가능합니다. 높은 압축률(10배 압축 시 최대 97%의 정확도), 시각-언어 공동 이해, 다중 구조 및 다중 형식 지원(JPG, PNG, PDF 등 및 다국어 인식), 엔드투엔드 VLM 아키텍처 등의 기술적 특징으로 긴 텍스트, 복잡한 문서, 다국어 배포 등 광범위한 애플리케이션 시나리오에서 사용할 수 있습니다. 긴 텍스트, 복잡한 문서, 다국어 지원, 현지화된 배포 등 광범위한 애플리케이션 시나리오에서 사용할 수 있습니다. 높은 효율성(단일 A100-40G 그래픽 카드로 하루에 20만 페이지 이상의 훈련 데이터 생성 지원), 짧은 지연 시간(모바일 장치에서 초당 15프레임의 실시간 인식, 100밀리초 미만의 지연 시간), 높은 적응성(복잡한 시나리오에서 최대 98.7%의 인식 정확도) 등 상당한 성능 이점이 있습니다. 개발자의 편의를 위해 오픈 소스 코드와 모델 가중치가 공개되었습니다.
DeepSeek-OCR의 특징
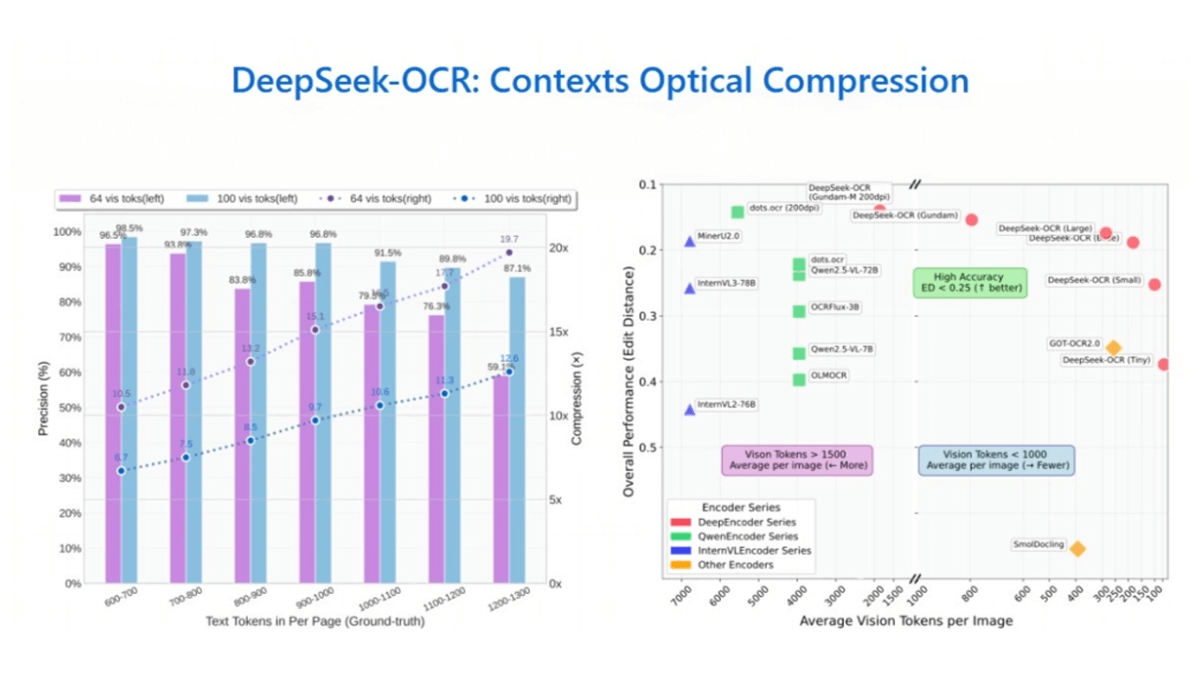
- 컨텍스트별 광학 압축텍스트를 이미지로 변환하고, 비주얼 토큰으로 압축 및 디코딩하여 10배 압축 시 최대 97%의 정확도로 긴 텍스트를 효율적으로 처리할 수 있습니다.
- 시각적-언어적 공동 이해이미지의 시각적 정보와 언어 모델을 이해하는 능력을 결합하여 텍스트의 의미와 레이아웃 구조를 정확하게 파악합니다.
- 다중 구조, 다중 형식 지원다국어 인식은 물론 다양한 이미지 형식(JPG, PNG, PDF)을 지원하며 손글씨, 혼합 텍스트, 차트와 텍스트가 혼합된 문서도 잘 처리할 수 있습니다.
- 높은 압축률과 높은 정확도10배 압축 시 OCR 정확도는 97%에 도달할 수 있으며, 압축률을 20배로 높여도 모델 정확도는 약 60%를 유지할 수 있습니다.
- 엔드투엔드 VLM 아키텍처딥엔코더 인코더와 딥시크3B-MoE 디코더가 사용되며, 인코더는 이미지 특징 추출, 토큰화, 시각적 표현의 압축을 담당하고 디코더는 이미지 토큰과 단서를 기반으로 필요한 결과를 생성합니다.
- 광범위한 애플리케이션 시나리오다음은 최신 버전의 TP3T의 일부 기능입니다. 수천 개의 단어로 구성된 문서를 단일 다이어그램으로 '촬영'할 수 있으며, 1/10 미만의 비용으로 97%를 정확하게 줄이고 대규모 언어 모델의 긴 문맥 문제에 대한 효율적인 솔루션을 제공하며, 표 또는 재무제표의 텍스트, 차트 및 다이어그램의 정보를 인식하고 화학 분자 공식, 수학 공식 및 기하학적 도형까지 읽을 수 있으며, 중국어와 영어를 포함한 100개 이상의 언어를 지원하고, 민감한 문서를 타사 클라우드 서비스로 보내지 않도록 로컬 배포를 지원합니다, 화학 분자식, 수학 공식, 기하학적 도형까지 읽을 수 있고, 중국어와 영어를 포함한 100개 이상의 언어를 지원하며, 로컬 배포를 지원하므로 민감한 문서를 타사 클라우드 서비스로 보내지 않아도 됩니다.
- 상당한 성능 이점단일 A100-40G 그래픽 카드는 하루에 20만 페이지 이상의 대용량 언어 모델/시각 언어 모델 학습 데이터 생성을 지원하고, 모바일 장치에서 100밀리초 미만의 지연 시간으로 초당 15프레임의 실시간 인식이 가능하며, 멀티스케일 동적 특징 융합 모듈과 상황 인식 디코더를 통해 복잡한 장면에서 모델의 인식 정확도가 98.7%로 급증하여 업계보다 6.4% 포인트 더 높습니다. 업계 평균보다 6.4% 포인트 더 높습니다.
DeepSeek-OCR의 핵심 이점
- 효율적인 컨텍스트 기반 옵티컬 압축텍스트를 이미지로 변환하고 압축 및 디코딩에 비주얼 토큰을 사용하여 높은 정확도를 유지하면서도 높은 압축률을 달성하며, 10배 압축 시 최대 97%, 20배 압축 시 약 60%의 정확도로 긴 텍스트 처리의 문제를 효과적으로 해결합니다.
- 비전과 언어의 깊은 융합이미지의 시각적 정보(예: 위치, 레이아웃, 그래픽, 표 경계)와 언어 모델의 이해력을 결합하여 텍스트 내용을 인식할 뿐만 아니라 의미와 레이아웃 구조를 정확하게 파악하여 복잡한 문서 처리를 향상시킵니다.
- 광범위한 형식 및 언어 지원다양한 이미지 형식(JPG, PNG, PDF)과 100개 이상의 언어를 지원하며, 손글씨, 혼합 텍스트, 차트와 텍스트가 혼합된 문서도 처리할 수 있어 다양한 시나리오에 적합합니다.
- 강력한 성능단일 A100-40G 그래픽 카드는 하루에 20만 페이지 이상의 대용량 언어 모델 학습 데이터 생성, 모바일 장치에서 100밀리초 미만의 지연 시간으로 초당 15프레임의 실시간 인식, 복잡한 장면에서 업계 평균보다 훨씬 뛰어난 최대 98.71 TP3T의 인식 정확도를 지원할 수 있습니다.
- 유연한 배포민감한 문서를 타사 클라우드 서비스로 전송하지 않고, 데이터 보안을 보호하며, 배포 환경에 대한 다양한 사용자의 요구를 충족할 수 있도록 현지화된 배포를 지원합니다.
DeepSeek-OCR의 공식 웹사이트는 무엇인가요?
- GitHub 리포지토리:: https://github.com/deepseek-ai/DeepSeek-OCR
- 허깅페이스 모델 라이브러리:: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- 기술 문서:: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
DeepSeek-OCR은 누구를 위한 서비스인가요?
- 비즈니스 사용자재무제표, 계약서, 기술 문서 등 대량의 문서를 처리해야 하는 경우 효율적인 긴 텍스트 처리와 복잡한 문서 인식 기능을 바탕으로 업무 효율성을 높이고 인건비를 절감할 수 있습니다.
- (과학) 연구원다국어 문서, 차트, 수식 등 복잡한 콘텐츠를 자주 처리해야 하는 학술 연구 분야에서는 DeepSeek-OCR의 다국어 지원과 정확한 인식 기능이 도움이 될 수 있습니다.
- 교육자코스웨어 제작, 시험지 분석 등 교육 자료의 정리 및 디지털화 등 필기 인식 및 다중 형식 지원 기능으로 교육 요구 사항을 충족할 수 있습니다.
- 개발자오픈 소스 코드와 모델 가중치를 통해 개발자는 자신의 프로젝트에 통합하고 맞춤형 OCR 애플리케이션을 개발하며 애플리케이션 시나리오를 확장할 수 있습니다.
- 개별 사용자DeepSeek-OCR은 문서 콘텐츠 추출, 노트 정리, 외국어 자료 번역 등 개인 업무 및 학습 효율을 향상시키는 편리하고 효율적인 솔루션입니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...