


아직 2월에 불과하지만 딥 검색은 이미 2025년의 새로운 검색 표준으로 떠오르고 있습니다. Google과 OpenAI 같은 거대 기업들은 이 기술 물결에 앞서 나가기 위해 '딥 리서치' 제품을 공개했습니다. (저희도 오픈 소스를 공개하게 된 것을 자랑스럽게 생각합니다.node-deepresearch).
당혹감 는 딥 리서치로 그 뒤를 이었고, 머스크의 X AI는 딥 검색 기능을 직접 통합하여 한 단계 더 나아갔습니다. Grok 3 모델은 본질적으로 딥 리서치의 변형입니다.
솔직히 딥 검색이라는 개념은 작년에는 RAG(검색 증강 세대) 또는 멀티홉 퀴즈라고 불렀던 것과 같은 개념으로, 그다지 혁신적이라고 할 수 없습니다. 하지만 올해 1월 말에는 Deepseek-r1 의 출시 이후 전례 없는 관심과 성장세를 보이고 있습니다.
지난 주말, 바이두 검색과 텐센트 위챗 검색은 모두 딥시크-r1을 검색 엔진에 통합했습니다.장기적인 사고와 추론 과정을 검색 시스템에 통합함으로써 이전보다 더 정확하고 심층적인 검색이 가능해졌습니다.
그렇다면 왜 지금 이런 변화가 일어나고 있을까요? 2024년 내내 '딥(재)검색'은 큰 관심을 끌지 못했던 것 같습니다. 2024년 초, 스탠퍼드 NLP 연구소에서 다음과 같은 보고서를 발표한 것을 기억해야 합니다. STORM 프로젝트, 웹 기반의 긴 형식의 보고서 생성. '심층 검색'이라는 이름이 QA, RAG, STORM보다 더 멋지게 들리기 때문일까요? 솔직히 말해서, 때로는 성공적인 리브랜딩만으로 업계가 이미 존재하는 것을 갑자기 수용하는 데 필요한 것은 없습니다.
진정한 티핑 포인트는 2024년 9월에 출시될 OpenAI의o1-preview'테스트 타임 컴퓨팅'이라는 개념을 도입하여 업계의 인식을 미묘하게 변화시켰습니다.'추론하면서 계산'이라는 용어는 학습 전이나 학습 후 단계에 집중하기보다는 추론 단계(즉, 대규모 언어 모델이 최종 결과를 생성하는 단계)에 더 많은 계산 리소스를 투자하는 것을 의미합니다. 대표적인 예로는 생각의 연쇄(CoT) 추론과 다음과 같은 접근 방식이 있습니다."Wait" 인젝션(예산 제어라고도 함)과 같은 기법은 모델에 여러 가지 잠재적 답변 평가, 심층적인 계획, 최종 답변을 제공하기 전 자기 성찰 등 내부 성찰을 위한 더 넓은 범위를 제공합니다.
이러한 '추론하면서 계산하기' 철학과 추론에 초점을 맞춘 모델은 사용자가 '지연된 만족'이라는 개념을 받아들이도록 유도합니다:대기 시간이 길어지는 대신 더 높은 품질과 유용한 결과를 얻을 수 있습니다. 유명한 스탠포드 마시멜로 실험처럼, 마시멜로 하나를 바로 먹고 싶은 유혹을 뿌리치고 나중에 마시멜로 두 개를 먹을 수 있는 아이들이 장기적으로 더 나은 성공을 거두는 경향이 있습니다. deepseek-r1은 대부분의 사용자가 좋든 싫든 암묵적으로 받아들였던 이러한 사용자 경험을 더욱 견고하게 만듭니다.
이는 기존의 검색 요구사항에서 크게 벗어난 것입니다. 과거에는 솔루션이 200밀리초 이내에 응답을 제공하지 못하면 거의 실패나 다름없었습니다. 하지만 2025년에는 숙련된 검색 개발자와 RAG 엔지니어, 지연 시간보다 최고의 정확도와 회수율을 우선시하세요. 사용자들은 처리 시간이 길어지는 것에 익숙해졌습니다.<thinking>.
2025년에는 추론 과정을 표시하는 것이 표준 관행이 되어 많은 채팅 인터페이스가 전용 UI 영역에 렌더링됩니다. <think> 콘텐츠.
이 백서에서는 오픈 소스 구현을 살펴봄으로써 DeepSearch와 DeepResearch의 원리에 대해 논의합니다. 주요 설계 결정 사항을 제시하고 잠재적인 주의 사항을 지적할 것입니다.
심층 검색이란 무엇인가요?
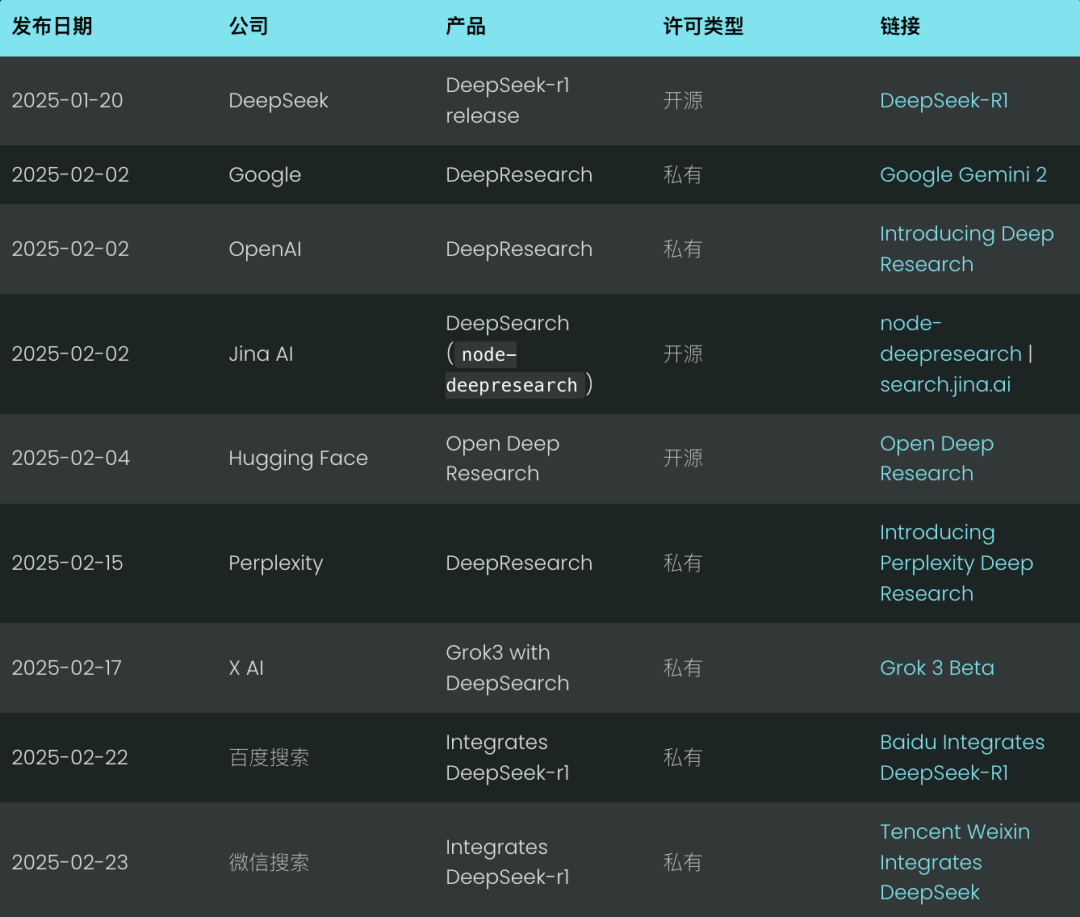
딥서치의 핵심 아이디어는 최적의 답을 찾을 때까지 검색, 읽기, 추론의 세 단계를 반복하여 최적의 답을 찾는 것입니다. 검색 세션에서는 검색 엔진을 사용하여 인터넷을 탐색하고, 읽기 세션에서는 특정 웹 페이지를 철저하게 분석하는 데 중점을 둡니다(예: Jina Reader 사용). 추론 세션은 현재 상태를 평가하고 원래 문제를 더 작은 하위 문제로 나눌지 아니면 다른 검색 전략을 시도할지 결정하는 역할을 합니다.
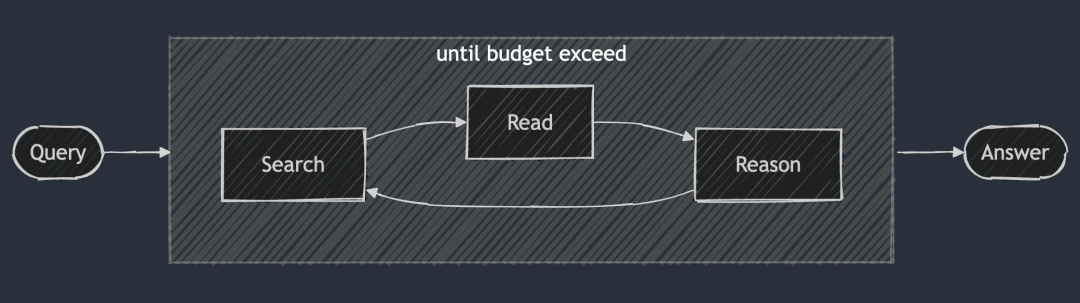 DeepSearch - 답을 찾을 때까지(또는 그 이상) 지속적으로 검색하고, 웹 페이지를 읽고, 추론합니다. 토큰 (예산).
DeepSearch - 답을 찾을 때까지(또는 그 이상) 지속적으로 검색하고, 웹 페이지를 읽고, 추론합니다. 토큰 (예산).
일반적으로 단일 검색 생성 프로세스를 실행하는 2024 RAG 시스템과 달리, 딥서치는 명시적인 중지 조건이 필요한 여러 번의 반복을 수행합니다. 이러한 조건은 토큰 사용 한도 또는 실패한 시도 횟수를 기반으로 할 수 있습니다.
search.jina.ai에서 DeepSearch를 사용해 보시고 <thinking>를 입력하여 루프가 발생하는 위치를 찾을 수 있는지 확인하세요.
다시 말해딥서치는 검색 엔진, 웹 리더 등 다양한 웹 도구를 탑재한 LLM 에이전트라고 볼 수 있습니다.에이전트는 현재 관찰 사항과 과거 행동을 분석하여 다음 작업 과정, 즉 직접 답을 제공할지 아니면 네트워크를 계속 탐색할지 여부를 결정합니다. 이를 통해 상태 머신 아키텍처가 구축되며, LLM은 상태 간 전환을 제어합니다.
각 의사 결정 지점에는 두 가지 옵션이 있습니다. 표준 생성 모델이 특정 작업 지침을 생성할 수 있도록 단서를 만들거나, Deepseek-r1과 같은 특수 추론 모델을 사용하여 자연스럽게 다음 작업을 도출할 수 있습니다. 그러나 r1을 사용하더라도 주기적으로 생성 프로세스를 중단하여 도구의 출력(예: 검색 결과, 웹 페이지 콘텐츠)을 컨텍스트에 주입하고 추론 프로세스를 계속 진행하라는 메시지를 표시해야 합니다.
궁극적으로 이는 구현 세부 사항일 뿐입니다. 단서 단어를 만들든 추론 모델을 사용하든 관계없이모두 검색, 읽기, 추론이라는 DeepSearch의 핵심 설계 원칙을 따릅니다.계속되는 사이클의 일부입니다.
딥리서치란 무엇인가요?
딥리서치는 긴 형식의 연구 보고서를 생성하기 위한 구조화된 프레임워크를 딥서치에 추가합니다. 워크플로는 일반적으로 목차를 생성하는 것으로 시작하여 서론, 관련 작업, 방법론, 최종 결론에 이르기까지 보고서의 각 필수 섹션에 체계적으로 DeepSearch를 적용합니다. 보고서의 각 섹션은 특정 연구 질문을 DeepSearch에 입력해 생성됩니다. 마지막으로, 모든 섹션을 하나의 단서로 통합하여 보고서의 전체 서술의 일관성을 향상시켰습니다.
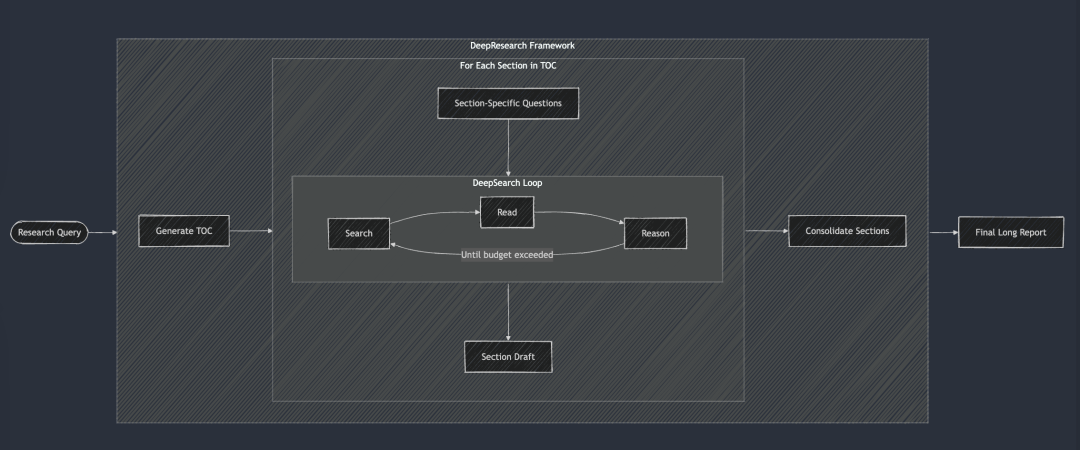 딥서치는 딥리서치의 기본 빌딩 블록 역할을 합니다. 각 챕터는 DeepSearch를 통해 반복적으로 구축되며, 최종 긴 보고서가 생성되기 전에 전체적인 일관성을 개선합니다.
딥서치는 딥리서치의 기본 빌딩 블록 역할을 합니다. 각 챕터는 DeepSearch를 통해 반복적으로 구축되며, 최종 긴 보고서가 생성되기 전에 전체적인 일관성을 개선합니다.
2024년에도 내부적으로 '연구' 프로젝트를 진행했는데, 당시에는 보고서의 일관성을 보장하기 위해 각 반복에서 모든 챕터를 고려하고 여러 차례 일관성을 개선하는 다소 어리석은 접근 방식을 채택했습니다. 하지만 오늘날의 대규모 언어 모델은 컨텍스트 창이 매우 길고 일관된 수정을 한 번에 완료하는 것이 훨씬 더 효과적이기 때문에 이제는 이 접근 방식이 너무 어려운 것 같습니다.
하지만 몇 가지 이유로 '연구' 프로젝트는 공개하지 않았습니다:
가장 주목할 만한 점은 보고 품질이 지속적으로 내부 기준에 미치지 못했다는 점입니다. "Jina AI의 경쟁사 분석"과 "Jina AI의 제품 전략"이라는 두 가지 익숙한 내부 쿼리로 테스트해 보았습니다. 결과는 실망스러웠고, 보고서는 평범하고 부족했으며 "아하" 하는 놀라움을 주지 못했습니다. 둘째, 검색 결과의 신뢰성이 떨어지고 착시 현상도 심각한 문제입니다. 마지막으로, 섹션 간 반복과 중복이 많아 전반적인 가독성이 떨어집니다. 요컨대, 쓸모가 없습니다. 그리고 보고서가 너무 길어서 시간 낭비일 뿐만 아니라 읽기에 비생산적입니다.
하지만 이 프로젝트를 통해 소중한 경험을 쌓고 여러 하위 제품을 탄생시켰습니다:
예를 들어검색 결과의 신뢰성과 문단 및 문장 수준에서의 팩트 체킹의 중요성에 대한 깊은 이해가 g.jina.ai 엔드포인트의 후속 개발로 이어졌습니다.또한 쿼리 확장의 가치를 깨닫고 쿼리 확장을 위한 소규모 언어 모델(SLM)을 훈련하는 데 노력을 투자하기 시작했습니다. 마지막으로, 검색을 재창조한다는 아이디어를 영리하게 표현한 동시에 말장난을 한 ReSearch라는 이름이 정말 마음에 들었습니다. 사용하지 않는 것이 아쉬워서 결국 2024년 연감에도 이 이름을 사용하게 되었습니다.
2024년 여름, '연구' 프로젝트는 '점진적' 접근 방식을 채택하여 더 긴 보고서를 생성하는 데 중점을 두었습니다. 보고서의 목차(TOC)를 동시에 생성하는 것으로 시작하여 모든 챕터의 내용을 동시에 생성합니다. 마지막으로 각 챕터는 비동기 방식으로 점진적으로 수정되며, 각 수정은 보고서의 전체 내용을 고려하여 이루어집니다. 위의 데모 동영상에서 사용한 쿼리는 "Jina AI의 경쟁사 분석"이었습니다.
딥서치와 딥리서치
많은 사람들이 딥서치와 딥리서치를 혼동하는 경향이 있습니다. 하지만 저희는 이 두 가지가 완전히 다른 문제를 해결한다고 생각합니다.딥서치는 딥리서치가 실행되는 핵심 엔진인 딥리서치의 빌딩 블록입니다.
DeepResearch는 고품질의 가독성 높은 긴 형식의 연구 보고서를 작성하는 데 중점을 둡니다.단순한 정보 검색이 아니라 체계적인 프로젝트입니다.딥서치 프로젝트는 검색 기능을 위한 매우 효과적인 도구로 설계되었으며, 효과적인 시각화 요소(예: 차트, 표)의 통합, 하위 장이 논리적으로 흐르도록 하는 논리적 장 구조, 텍스트 전체의 일관된 용어, 정보의 중복 방지, 문맥을 연결하는 부드러운 전환 사용 등이 필요했습니다. 이러한 요소는 기본 검색 기능과 직접적으로 관련이 없기 때문에 저희는 딥서치에 더욱 중점을 두었습니다.
딥서치와 딥리서치의 차이점을 요약하면 아래 표를 참조하세요. 한 가지 언급할 가치가 있는 것은딥서치와 딥리서치는 모두 긴 컨텍스트 및 추론 모델과 분리할 수 없지만, 그 이유는 약간 다릅니다.
딥리서치는 긴 보고서를 생성하기 위해 긴 컨텍스트가 필요하며, 이는 이해할 수 있는 일입니다. 그리고 딥서치는 검색 도구로 보이지만, 후속 작업을 계획하기 위해 이전 검색 시도와 웹 페이지 콘텐츠를 기억해야 하므로 긴 컨텍스트도 마찬가지로 필수적입니다.

딥서치 구현에 대해 알아보기
오픈 소스 링크: https://github.com/jina-ai/node-DeepResearch
딥리서치의 핵심은 순환 추론 메커니즘에 있습니다. 한 단계로 질문에 답하려고 하는 대부분의 RAG 시스템과 달리 반복적인 루프를 사용합니다. 답을 찾거나 토큰 예산이 소진될 때까지 계속해서 정보를 검색하고, 관련 소스를 읽고, 추론합니다. 다음은 이 큰 동안 루프의 압축된 골격입니다:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// 갭 대기열에서 현재 이슈를 가져오거나 사용할 수 없는 경우 원본 이슈를 사용합니다.
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/?
/ 현재 컨텍스트 및 허용된 작업을 기반으로 프롬프트 생성하기
system = getPrompt(diaryContext, allQuestions, allKeywords.
허용반영, 허용응답, 허용읽기, 허용검색, 허용코딩.
badContext, allKnowledge, unvisitedURLs);/
/ LLM이 다음에 수행할 작업을 결정하도록 합니다.
const result = await LLM.generateStructuredResponse(시스템, 메시지, 스키마);
thisStep = result.object;/
/ 선택한 작업 수행(답변, 반영, 검색, 방문, 코딩)
if (thisStep.action === 'answer') {
// 응답 작업 처리...
} else if (thisStep.action === '반영') {
// 반사 액션 처리 중...
} // ... 다른 작업도 마찬가지입니다.
출력의 안정성과 구조를 보장하기 위해 중요한 조치를 취했습니다:각 단계에서 특정 작업을 선택적으로 비활성화할 수 있습니다.
예를 들어 메모리에 URL이 없는 경우 '방문' 작업을 비활성화하고, 마지막 응답이 거부된 경우 에이전트가 즉시 '응답' 작업을 반복하지 못하도록 합니다. 이러한 제약 메커니즘은 에이전트를 올바른 방향으로 안내하고 같은 곳을 맴돌지 않도록 방지합니다.
시스템 큐
시스템 프롬프트의 설계를 위해 XML 태그를 사용하여 다양한 부분을 정의함으로써 보다 강력한 시스템 프롬프트와 생성된 콘텐츠를 생성할 수 있습니다. 동시에 JSON 스키마의 description 필드에 필드 제약 조건을 추가하면 더 나은 결과를 얻을 수 있습니다. DeepSeek-R1과 같은 추론 모델이 이론적으로 대부분의 단서 단어를 자동으로 생성할 수 있는 것은 사실입니다. 그러나 컨텍스트 길이의 제약과 에이전트 동작을 세밀하게 제어해야 하는 필요성을 고려할 때, 실제로는 단서를 명시적으로 작성하는 이 방법이 더 안정적입니다.
function getPrompt(params...) {
const sections = [];// 시스템 명령이 포함된 헤더 추가
sections.push("당신은 다단계 추론을 전문으로 하는 선임 AI 연구 조교입니다...") ;
// 축적된 지식 조각 추가(있는 경우)
if (지식?.길이) {
sections.push("[지식 항목]");;
}// 이전 작업에 대한 컨텍스트 정보 추가
if (context?.length) {
sections.push("[작업 기록]");;
}
// 실패한 시도 및 학습한 전략 추가하기
if (badContext?.length) {
sections.push("[실패한 시도]");;
sections.push("[개선된 전략]");;
}
// 현재 상태에 따라 사용 가능한 작업 옵션을 정의합니다.
sections.push("[사용 가능한 액션 정의]");;
// 응답 서식 지정 지침 추가
sections.push("유효한 JSON 형식으로 응답하고 JSON 스키마와 엄격하게 일치해야 합니다.");;
반환 섹션.조인("nn");
}
지식 격차 문제 해결
딥서치에서는"지식 격차 질문"이란 상담원이 핵심 질문에 답하기 전에 채워야 하는 지식 격차를 말합니다.상담원은 원래 질문에 직접 답하는 대신 필요한 지식창고를 구축하는 하위 질문을 식별하고 해결합니다.
이것은 매우 우아한 처리 방법입니다.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// 항상 대기열 끝에 원래 질문을 추가합니다.
gaps.push(originalQuestion);
}
다음 규칙을 따르는 순환 메커니즘을 사용하여 FIFO(선입선출) 대기열을 생성합니다:
- 새로운 지식 격차 질문은 우선순위가 지정되어 대기열의 맨 위로 밀려납니다.
- 원래 질문은 항상 대기열의 마지막에 있습니다.
- 시스템은 처리를 위해 각 단계에서 대기열 헤더에서 이슈를 추출합니다.
이 설계의 미묘한 점은 모든 문제에 대해 공유된 맥락을 유지한다는 것입니다. 즉, 지식 격차 문제를 해결하면 얻은 지식은 이후의 모든 문제에 즉시 적용될 수 있으며, 결국 원래의 원래 문제 해결에도 도움이 됩니다.
FIFO 대기열과 재귀
FIFO 대기열 외에도 깊이 우선 검색 전략에 해당하는 재귀를 사용할 수도 있습니다. 각 "지식 격차" 문제에 대해 재귀는 별도의 컨텍스트를 가진 완전히 새로운 호출 스택을 생성합니다. 시스템은 상위 문제로 돌아가기 전에 각 지식 격차 문제(및 모든 잠재적 하위 문제)를 완전히 해결해야 합니다.
예를 들어, 간단한 3단계 심층 지식 격차 문제 재귀의 경우, 원 안의 숫자는 문제가 해결되는 순서를 나타냅니다.
재귀 모드에서는 시스템이 다른 문제로 넘어가기 전에 Q1(및 파생 가능한 하위 문제)을 완전히 해결해야 합니다! 이는 3개의 지식 격차 문제를 처리한 후 Q1로 돌아가는 큐 접근 방식과 대조적입니다.
실제로 재귀적 방법은 예산을 통제하기 어렵다는 것을 알게 되었습니다. 하위 문제가 계속해서 새로운 하위 문제를 생성할 수 있기 때문에 명확한 가이드라인 없이는 토큰 예산을 얼마나 할당해야 할지 결정하기 어렵습니다. 명확한 맥락적 고립이라는 측면에서 재귀의 장점은 예산 제어의 복잡성과 수익률 지연 가능성에 비해 상대적으로 작습니다. 반면, FIFO 대기열의 설계는 깊이와 폭의 균형을 잘 유지하여 시스템이 잠재적으로 무한한 재귀의 수렁에 빠지지 않고 계속해서 지식을 쌓고 점진적으로 개선하며 궁극적으로 원래 문제로 돌아갈 수 있도록 보장합니다.
쿼리 재작성
다소 흥미로운 도전 과제 중 하나는 사용자의 검색 쿼리를 효과적으로 재작성하는 방법이었습니다:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// 자연어 쿼리를 보다 효율적인 검색 표현식으로 재작성하기
const optimisedQueries = await rewriteQuery(uniqueRequests);
// 이전 검색과 중복되지 않도록 하기
const newQueries = await dedupQueries(optimisedQueries, allKeywords);
// 검색을 수행하고 결과를 저장합니다.
for (newQueries의 const 쿼리) {
const results = await searchEngine(query);
if (results.length > 0) {
storeResults(results);
모든키워드.푸시(쿼리);
}
}
}
다음과 같은 사실을 발견했습니다.쿼리 재작성은 예상보다 훨씬 더 중요하며 검색 결과의 품질을 결정하는 가장 중요한 요소 중 하나라고 할 수 있습니다.좋은 쿼리 재작성기는 사용자의 자연어를 더 적합한 것으로 변환할 뿐만 아니라 BM25 알고리즘은 다양한 언어, 어조 및 콘텐츠 형식으로 더 많은 잠재적 답변을 포함하도록 쿼리를 확장하는 키워드 형태를 처리합니다.
쿼리 중복 제거 측면에서 처음에는 LLM 기반 방식을 시도했지만 유사도 임계값을 정확하게 제어하기 어렵고 결과가 만족스럽지 않다는 것을 알게 되었습니다. 결국, 저희는 jina-embeddings-v3. 시맨틱 텍스트 유사성 작업에서 뛰어난 성능을 발휘하는 이 모델을 통해 비영어 쿼리가 오탐으로 필터링될 걱정 없이 쉽게 언어 간 중복 제거를 달성할 수 있었습니다. 공교롭게도 궁극적으로 핵심적인 역할을 한 것은 임베딩 모델이었습니다. 처음에는 이 모델을 인메모리 검색에 사용할 생각이 없었지만 중복 제거 작업에서 매우 효율적으로 작동한다는 사실에 놀랐습니다.
웹 콘텐츠 크롤링
웹 크롤링 및 콘텐츠 처리도 이 프로세스의 중요한 부분으로, 당사는 이 프로세스에서 지나 리더 전체 웹 페이지 콘텐츠 외에도 검색 엔진이 반환한 요약 스니펫을 수집하여 추후 추론을 위한 보조 정보로 사용합니다. 이러한 스니펫은 웹 페이지 콘텐츠의 간결한 요약본으로 볼 수 있습니다.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// 각 URL을 병렬로 처리
const results = await Promise.all(uniqueURLs.map(async url => {
시도 {
// 콘텐츠 가져오기 및 추출
const content = await readUrl(url);
// 지식으로 저장
addToKnowledge(`${url}에 무엇이 있나요? ', content, [url], 'url');
반환 {URL, 성공: true};
} catch (error) {
반환 {URL, 성공: false};
} 마지막으로 {
visitedURLs.push(url);
}
}));
// 결과에 따라 로그 업데이트
updateDiaryWithVisitResults(results).
}
추적을 용이하게 하기 위해 URL을 정규화하고 단계당 액세스하는 URL 수를 제한하여 에이전트의 메모리 사용량을 제어합니다.
메모리 관리
다단계 추론의 핵심 과제는 에이전트 메모리를 효율적으로 관리하는 것입니다. 우리가 설계한 메모리 시스템은 '메모리'로 간주되는 것과 '지식'으로 간주되는 것을 구분합니다. 하지만 어쨌든 이들은 모두 서로 다른 XML 태그로 구분되는 LLM 큐의 컨텍스트의 일부입니다:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// 로그에 단계 기록
함수 addToDiary(step, action, question, result, evaluation) {
diaryContext.push(`
${단계}에서 "${질문}" 문제에 대해 **${행동}**을 수행했습니다.
[세부 정보 및 결과] [평가(있는 경우)] `); 그리고
}
LLM 2025에서는 매우 긴 컨텍스트의 추세를 고려하여 벡터 데이터베이스를 버리고 컨텍스트 메모리 접근 방식을 선택했습니다. 에이전트의 메모리는 컨텍스트 창 내에서 획득한 지식, 방문한 웹사이트, 실패한 시도 로그의 세 가지 부분으로 구성됩니다. 이 접근 방식을 사용하면 에이전트가 추론 과정에서 추가 검색 단계 없이 지식의 전체 기록과 상태에 직접 액세스할 수 있습니다.
답안 평가
또한 답변 생성 및 평가는 다른 단서 단어에 배치할 때 더 잘 수행된다는 사실도 발견했습니다.저희는 새로운 질문이 접수되면 먼저 평가 기준을 파악한 다음 사례별로 평가합니다. 평가자는 소수의 사례를 참조하여 일관성을 평가하므로 자체 평가보다 더 신뢰할 수 있습니다.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// 각 기준을 개별적으로 평가합니다.
const results = [];
for (const criterion of evaluationCriteria) {
const result = await evaluateSingleCriteria(criterion, question, answer, context);
results.push(결과);
}
// 답변이 전체 평가를 통과했는지 확인합니다.
반환 {
pass: results.every(r => r.pass),
생각: results.map(r => r.reasoning).join('n')
};
}
예산 관리
예산 관리는 단순히 비용을 절감하는 것뿐만 아니라 예산이 소진되기 전에 시스템이 문제를 적절히 해결하고 조기에 답변을 반환하는 것을 방지하는 것입니다.DeepSeek-R1 출시 이후, 예산 관리에 대한 우리의 생각은 단순히 예산을 절약하는 것에서 더 깊은 사고를 장려하고 고품질의 답변을 얻기 위해 노력하는 것으로 바뀌었습니다.
저희의 구현에서는 시스템이 답변을 시도하기 전에 지식 격차를 식별하도록 명시적으로 요구합니다.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
특정 작업을 활성화 및 비활성화할 수 있는 유연성을 확보함으로써 시스템이 추론을 심화시키는 도구를 사용하도록 지시할 수 있습니다.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
유효하지 않은 경로에 토큰이 낭비되는 것을 방지하기 위해 실패 횟수를 제한합니다. 예산 한도에 가까워지면 "야수 모드"를 활성화하여 어떻게든 답을 제시하고 빈손으로 돌아가는 것을 방지합니다.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// 결정적인 답변을 안내하는 프롬프트 구성하기
system = getPrompt(
diaryContext, allQuestions, allKeywords.
거짓, 거짓, 거짓, 거짓, 거짓, 거짓, 거짓, // 다른 작업 비활성화
나쁜 컨텍스트, 모든 지식, 방문하지 않은 URL.
true // 비스트 모드 활성화
);
// 강제 답변 생성
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
thisStep = result.object;
thisStep.isFinal = true;
}
비스트 모드 프롬프트 메시지는 의도적으로 과장되어 있으며, 이제 사용 가능한 정보를 바탕으로 LLM이 결정적인 결정을 내려야 한다는 것을 분명히 알려줍니다!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥프라임 지시문:
- 모든 망설임을 없애세요! 침묵하는 것보다 대답하는 것이 낫습니다!
- 알려진 모든 정보를 사용하여 현지화된 전략을 채택할 수 있습니다!
- 이전에 실패한 시도를 재사용할 수 있습니다!
- 결정을 내릴 수 없을 때: 이용 가능한 정보를 바탕으로 과감하게 결정하세요!
실패는 선택 사항이 아닙니다! 반드시 목표를 달성하세요! ⚡️
</action-answer>
이를 통해 어렵거나 모호한 질문에 직면했을 때에도 무응답이 아닌 유용한 답변을 제공할 수 있습니다.
평결에 도달하기
딥서치는 복잡한 쿼리를 처리하는 검색 기술의 중요한 돌파구라고 할 수 있습니다. 전체 프로세스를 독립적인 검색, 읽기 및 추론 단계로 세분화하여 기존의 단일 라운드 RAG 또는 멀티홉 퀴즈 시스템의 많은 한계를 극복합니다.
개발 과정에서 딥서치-R1 출시 이후 검색 산업 전반의 급격한 변화 속에서 2025년 미래 검색 기술 기반이 어떤 모습이어야 할지 끊임없이 고민해왔습니다. 어떤 새로운 니즈가 등장할까요? 어떤 니즈가 사라질까요? 어떤 니즈가 실제로는 의사 니즈일까요?
딥서치 구현을 돌이켜보면, 무엇이 예상되고 필수적이었는지, 당연하게 생각했지만 실제로는 필요하지 않았던 것은 무엇인지, 전혀 예상하지 못했지만 중요한 것으로 판명된 것은 무엇인지 신중하게 파악할 수 있었습니다.
첫째.표준 형식(예: JSON 스키마)으로 출력을 생성하는 긴 컨텍스트 LLM은 필수입니다!. 작업 추론과 쿼리 확장을 향상시키기 위해 추론 모델도 필요할 수 있습니다.
쿼리 확장도 반드시 필요합니다.SLM, LLM 또는 특수 추론 모델을 사용하여 구현하든, 쿼리 확장은 프로세스에서 피할 수 없는 부분입니다. 하지만 이 프로젝트를 수행한 후, 쿼리 확장은 본질적으로 다국어여야 하고 단순한 동의어 대체나 키워드 추출에 국한될 수 없기 때문에 SLM이 이 작업에 적합하지 않을 수 있다는 사실을 깨달았습니다. 여러 언어를 포괄하는 토큰 기반(3억 개의 매개변수에 쉽게 도달할 수 있도록)을 가질 수 있을 만큼 포괄적이어야 하며, 상자 밖에서 생각할 수 있을 만큼 스마트해야 합니다. 따라서 SLM만으로는 쿼리 확장이 작동하지 않을 수 있습니다.
웹 검색과 웹 읽기 능력은 의심할 여지 없이 최우선 순위입니다!다행히도 [Reader(r.jina.ai)]는 성능이 매우 우수하고 강력할 뿐만 아니라 확장성도 좋아서 검색 엔드포인트를 개선할 수 있는 방법을 생각하게 되었습니다(s.jina.ai)는 다음 반복 작업에서 최적화에 집중할 수 있는 많은 영감을 줍니다.
벡터 모델은 유용하지만 전혀 예상치 못한 곳에서 사용됩니다. 원래는 인메모리 검색에 사용하거나 벡터 데이터베이스와 함께 컨텍스트를 압축하는 데 사용할 것이라고 생각했지만, 둘 다 필요하지 않은 것으로 판명되었습니다. 결국, 벡터 모델을 중복 제거, 즉 STS(의미론적 텍스트 유사성) 작업에 사용하는 것이 가장 효과적이라는 것을 알게 되었습니다. 쿼리 수와 지식 갭은 일반적으로 수백 개에 달하기 때문에 벡터 데이터베이스를 사용하지 않고 인메모리에서 직접 코사인 유사도를 계산하는 것으로 충분합니다.
리랭커 모델을 사용하지 않았습니다.임베딩 및 리랭크 모델은 이론적으로 쿼리, URL 제목 및 요약 스니펫을 기반으로 액세스 우선순위를 정해야 하는 URL을 결정하는 데 도움이 되는 도구로 사용할 수 있습니다. 임베딩 및 리랭커 모델의 경우 쿼리 및 질문이 다국어이므로 다국어 기능은 기본 요구 사항입니다. 긴 컨텍스트 처리는 임베딩 및 리랭커 모델에 도움이 되지만 결정적인 요소는 아닙니다. 벡터 사용으로 인한 문제가 발생하지 않은 이유는 아마도 jina-embeddings-v3 (8192 토큰의 우수한 컨텍스트 길이). 이를 종합하면jina-embeddings-v3 노래로 응답 jina-reranker-v2-base-multilingual 여전히 제가 가장 먼저 선택하는 서비스로 다국어 지원, SOTA 성능, 긴 컨텍스트 처리가 우수합니다.
에이전트 프레임워크는 궁극적으로 불필요한 것으로 판명되었습니다. 시스템 설계 측면에서 우리는 LLM의 기본 기능에 가깝게 유지하는 것을 선호했고 불필요한 추상화 계층을 도입하는 것을 피했습니다. Vercel AI SDK는 다른 LLM 공급업체에 적응하는 데 매우 편리하며, 코드 한 줄만 변경하면 새로운 LLM을 만들 수 있으므로 개발 노력을 크게 줄일 수 있습니다. 쌍둥이자리 Studio, OpenAI, Google Vertex AI 간 전환. 프록시 메모리 관리는 의미가 있지만 이를 위한 전문 프레임워크를 도입하는 것은 의문입니다. 개인적으로 저는 프레임워크에 지나치게 의존하면 LLM과 개발자 사이에 장벽이 생길 수 있고, 프레임워크가 제공하는 구문 설탕이 개발자에게 부담이 될 수 있다고 생각합니다. 이미 많은 LLM/RAG 프레임워크가 이를 검증했습니다. LLM의 기본 기능을 수용하고 프레임워크에 얽매이지 않는 것이 현명합니다.
이 게시물은 위챗: Jina AI에서 가져온 것입니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...