
대규모 언어 모델(LLM)은 빠르게 진화하고 있으며, 추론 능력은 지능 수준을 나타내는 핵심 지표가 되었습니다. 특히, OpenAI의 o1및DeepSeek-R1및QwQ-32B 노래로 응답 Kimi K1.5 이러한 모델은 인간의 심층적인 사고 과정을 시뮬레이션하여 복잡한 문제를 해결하는 능력으로 많은 주목을 받고 있습니다. 이 기능에는 종종 추론 시간 확장이라는 기술이 포함되며, 이를 통해 모델이 답을 생성할 때 더 많은 시간을 탐색하고 수정할 수 있습니다.
그러나 자세히 살펴보면 이러한 모델은 추론에 있어 두 가지 극단으로 나뉘는 경우가 많다는 것을 알 수 있습니다:생각 부족 노래로 응답 지나친 생각.
생각할 음식이 충분하지 않음 이는 모델 추론에서 아이디어가 자주 전환되어 더 깊이 파고들기 위한 유망한 방향에 집중하기 어렵다는 것을 의미합니다. 모델 출력에 "대안", "하지만 잠깐만", "다시 생각해 보겠습니다" 등과 같은 단어로 채워질 수 있습니다. 와 같은 단어로 채워져 잘못된 최종 답변이 나올 수 있습니다. 이러한 현상은 추론의 타당성에 영향을 미치는 인간의 부주의에 비유할 수 있습니다.

지나친 생각 대신, 이 모델은 간단한 문제에 대해 길고 불필요한 '생각의 사슬'을 생성합니다. 예를 들어, "2+3=?"와 같은 기본적인 산술 문제의 경우 다음과 같이 계산합니다. 예를 들어, "2+3=?"와 같은 기본적인 산술 문제의 경우 일부 모델은 수백 시간 또는 수천 시간의 작업이 필요할 수 있습니다. token 를 사용하여 아래와 같이 여러 솔루션을 반복적으로 검증하거나 탐색할 수 있습니다. 복잡한 사고 프로세스는 어려운 문제에는 도움이 되지만, 간단한 시나리오에서는 계산 리소스를 낭비하는 결과를 초래합니다.
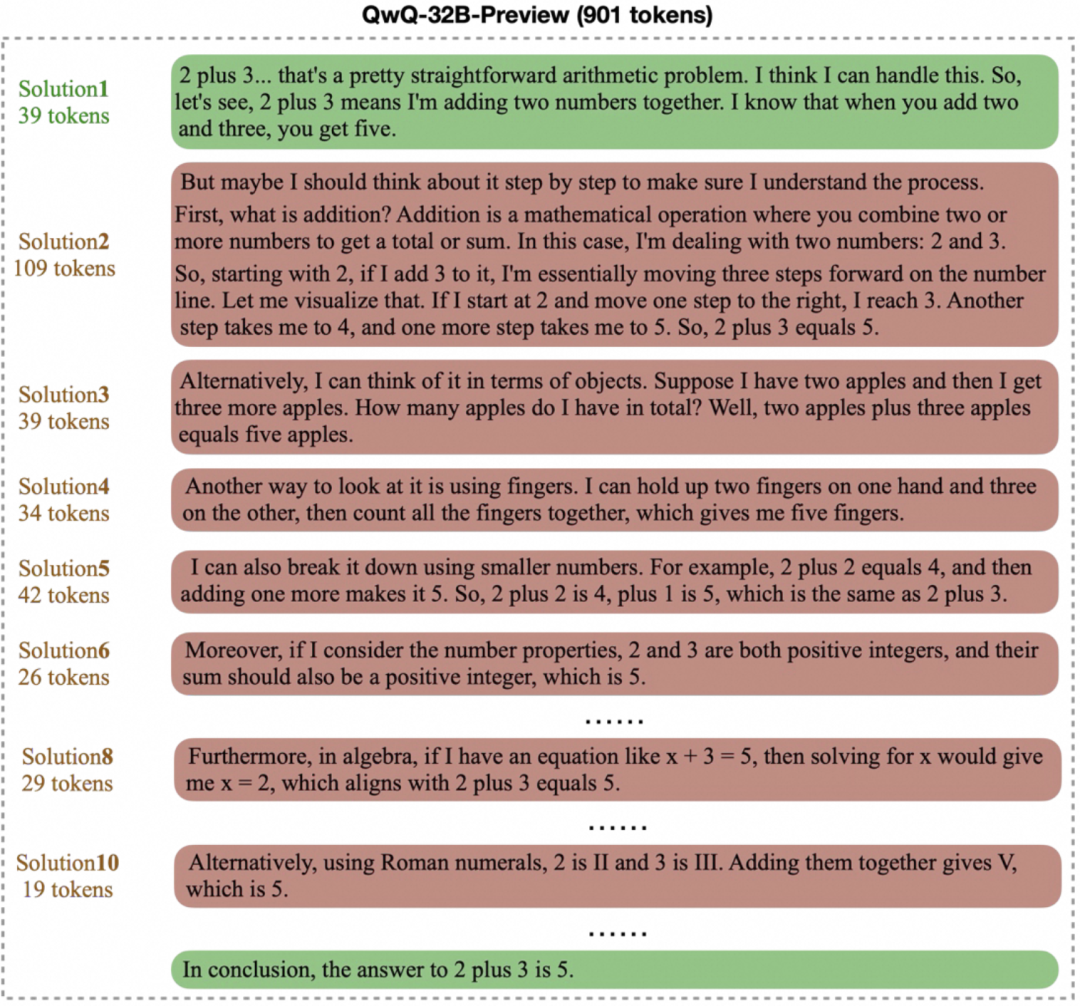
이 두 가지 질문은 함께 정답의 품질을 유지하면서 모델의 사고 효율성을 개선하는 방법이라는 핵심 과제를 가리킵니다. 이상적인 모델은 최단 시간 내에 정답을 찾아서 제공할 수 있어야 합니다.
이 문제를 해결하기 위해EvalScope 이 프로젝트는 다음을 소개합니다. EvalThink 구성 요소를 사용하여 모델의 사고 효율성을 평가할 수 있는 표준화된 도구를 제공하는 것을 목표로 합니다. 이 백서에서는 MATH-500 예를 들어, 데이터 세트의 분석에는 다음이 포함됩니다. DeepSeek-R1-Distill-Qwen-7B 6가지 차원에 초점을 맞춘 추론 모델을 포함한 다양한 추론 모델의 성능: 모델 추론 token 번호, 처음 정답 token 수, 남은 반사 token 숫자,token 효율성, 하위 사고 사슬의 수, 정확성.
평가 방법론 및 프로세스
평가 프로세스는 모델 추론 평가와 모델 사고 효율성 평가의 두 가지 주요 단계로 구성됩니다.
모델 추론 평가
이 단계의 목표는 다음에서 모델을 얻는 것입니다. MATH-500 데이터 세트의 원시 추론 결과 및 기본 정확도.MATH-500 이 데이터 세트에는 다양한 난이도(레벨 1부터 레벨 5까지)의 수학 문제 500개가 포함되어 있습니다.
평가 환경 준비하기
평가는 OpenAI API 호환 추론 서비스에 액세스하여 수행할 수 있습니다.EvalScope 이 프레임워크는 다음과 같은 사용도 지원합니다. transformers 라이브러리는 로컬에서 검토됩니다. 긴 생각의 사슬(아마도 10,000개 이상)을 처리해야 하는 분들을 위해 token)를 사용하여 추론 모델의 vLLM 어쩌면 ollama 이와 같은 효율적인 추론 프레임워크는 평가 프로세스의 속도를 크게 높일 수 있는 모델을 배포합니다.
에 따르면 DeepSeek-R1-Distill-Qwen-7B 예를 들어 vLLM 서비스를 배포하는 샘플 명령은 다음과 같습니다:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
경영진 추론 검토
통과(청구서 또는 검사 등) EvalScope (명목식 형태로 사용됨) TaskConfig 모델 API 주소, 이름, 데이터 세트, 배치 크기, 생성 매개변수를 구성한 다음 평가 작업을 실행합니다. 다음은 Python 코드 샘플입니다:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
평가가 완료되면 모델이 다음 위치로 내보내집니다. MATH-500 난이도별 정확도(AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
모델 사고 효율성 평가
추론 결과를 얻은 후EvalThink 보다 심층적인 효율성 분석을 위한 구성 요소 개입. 핵심 평가 지표는 다음과 같습니다:
- 모델링된 추론
token(추론 토큰)모델 답변 생성 중 사고 사슬(O1/R1 모델에서와 같이)</think>(플래그 앞에 있는 것)에 포함된token총 금액입니다. - 처음부터 바로
token번호(첫 번째 정답 토큰)모델 출력 시작부터 식별 가능한 정답 위치의 첫 번째 발생 시점까지token수량. - 남은 반사
token리플렉션 토큰:: 첫 번째 정답 위치에서 생각의 사슬의 끝까지token수량. 여기에는 모델이 답을 찾은 후에도 계속 검증하거나 탐색하는 데 드는 비용이 부분적으로 반영되어 있습니다. - 생각의 수:: 특정 기호를 계산하여(예
alternatively,but wait,let me reconsider) 발생 횟수를 계산하여 모델이 얼마나 자주 아이디어를 전환하는지 추정합니다. token토큰 효율성:: 효과적인 사고 측정token첫 번째 정답으로 계산된 백분율 표시기token숫자 및 일반 추론token의 비율의 평균입니다(정답이 있는 샘플만 카운트됨):
토큰 효율성 = 1⁄N ∑ 첫 번째 정답 토큰i⁄추론 토큰
여기서 N은 정답을 맞힌 문제의 수입니다. 값이 높을수록 모델의 사고가 더 "효율적"이라는 의미입니다.
'최초 권리'를 결정하기 위한 목적 token 숫자"를 기반으로 하는 평가 프레임워크인 ProcessBench 예를 들어 다음과 같이 별도의 판사 모델을 사용하는 것이 좋습니다. Qwen2.5-72B-Instruct를 사용하여 추론 단계를 검토하고 정답이 가장 빨리 나오는 위치를 찾습니다. 이 구현에는 모델 출력을 단계별로 분해하는 작업이 포함됩니다(전략 선택 사항: 특정 구분 기호로). separator키워드 누르기 keywords의 도움을 받아 재작성 및 슬라이싱을 수행합니다. llm), 그리고 심판 모델이 각각을 판단하게 합니다.
사고 효율성 평가를 수행하기 위한 샘플 코드입니다:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
평가 결과에는 각 난이도에 따른 모델의 6개 차원 메트릭이 자세히 설명되어 있습니다.
결과 분석 및 토론
연구팀은 다음을 사용했습니다. EvalThink 오른쪽 DeepSeek-R1-Distill-Qwen-7B 및 기타 여러 모델(QwQ-32B및QwQ-32B-Preview및DeepSeek-R1및DeepSeek-R1-Distill-Qwen-32B)를 평가하고 비추론적 수학 전문 모델을 추가했습니다. Qwen2.5-Math-7B-Instruct 비교하자면.
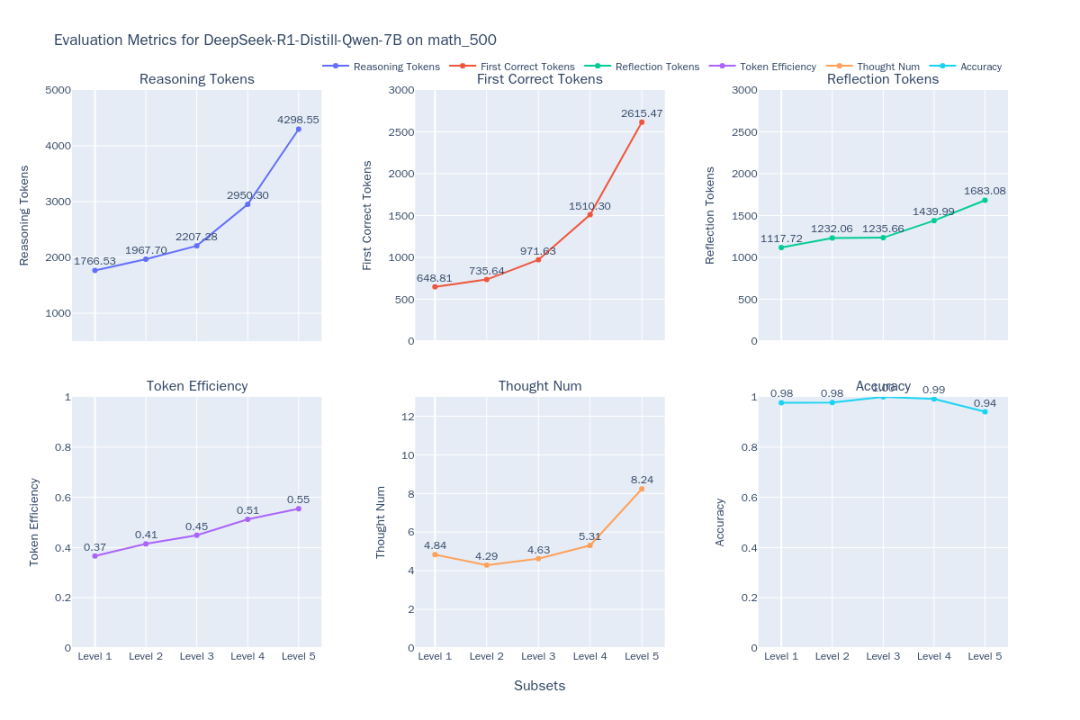
그림 1: DeepSeek-R1-Distill-Qwen-7B 사고 효율성 지표
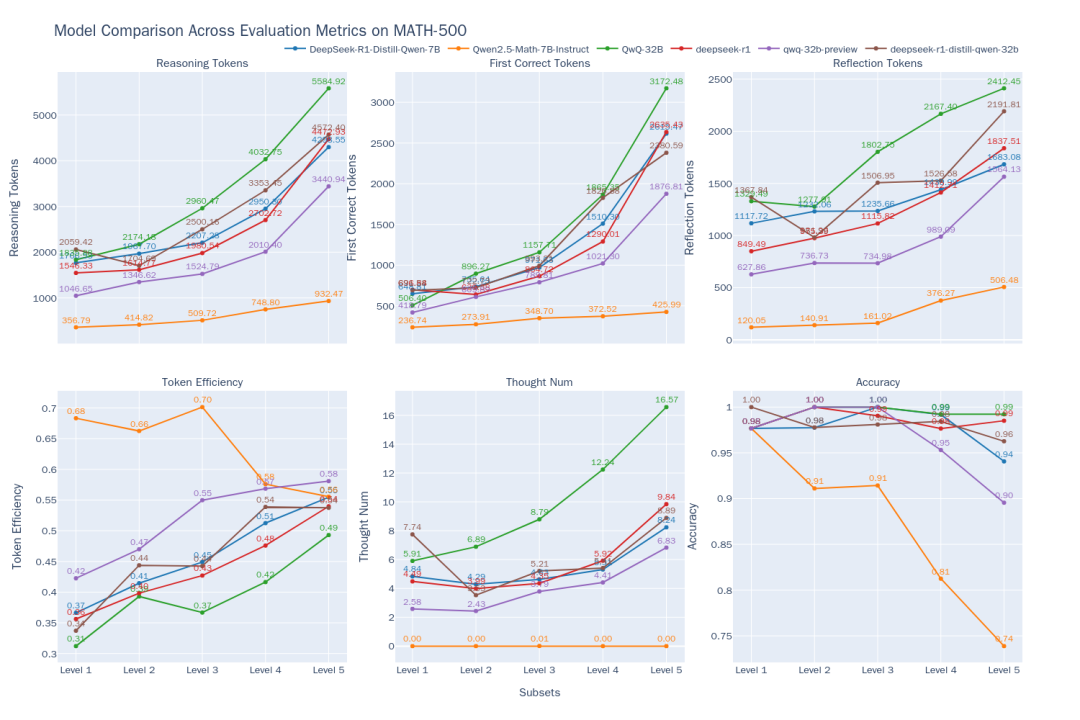
그림 2: MATH-500의 다양한 난이도에 따른 6가지 모델의 사고력 효율성 비교
비교 결과에서 다음과 같은 추세를 관찰할 수 있습니다(그림 2):
- 난이도-성과 상관관계문제의 난이도(레벨 1 ~ 레벨 5)가 높아질수록 대부분의 모델의 정확도가 감소합니다. 하지만.
QwQ-32B노래로 응답DeepSeek-R1어려운 문제에서 탁월한 능력을 발휘합니다.QwQ-32B레벨 5에서 가장 높은 정확도. 동시에 모든 모델의 출력은token난이도가 높아질수록 숫자는 모두 길어지는데, 이는 모델이 퍼즐을 풀기 위해 더 많은 '생각'을 해야 하는 '확장 추론'의 기대에 부합하는 것입니다. - O1/R1 클래스 추론 모델 속성:
- 효율성 향상:: 흥미롭게도
DeepSeek-R1노래로 응답QwQ-32B이 유형의 추론 모델은 출력이 길어지지만token효율성(효과)token백분율)도 난이도에 따라 증가합니다(DeepSeek-R136%에서 54%로.QwQ-32B(31%에서 49%로). 이는 어려운 문제에 대한 추가 사고가 더 '비용 효율적'인 반면, 간단한 문제에서는 불필요한 반복 검증과 같은 '과도한 사고'가 어느 정도 있을 수 있음을 시사합니다.QwQ-32B(명목식 형태로 사용됨)token전반적으로 소비량이 많기 때문에 레벨 5에서 높은 정확도를 유지할 수 있는 이유 중 하나일 수 있지만, 지나치게 많은 생각을 하는 경향이 있음을 암시하기도 합니다. - 생각의 경로:
DeepSeek시리즈 모델의 하위 사고 사슬의 수는 레벨 1~4에서는 비교적 안정적이지만 가장 어려운 레벨 5에서 급격히 증가하여 레벨 5가 이 모델에 상당한 도전이 되고 여러 번의 시도가 필요하다는 것을 시사합니다. 반대로QwQ-32B시리즈 모델은 다양한 대처 전략을 반영하여 생각의 사슬의 수가 더 부드럽게 증가합니다.
- 효율성 향상:: 흥미롭게도
- 비추론적 모델의 한계수학 전문 모델 :: 수학 전문 모델
Qwen2.5-Math-7B-Instruct어려운 문제를 처리할 때 정확도가 급격히 떨어집니다.token이 수치는 추론 모델(약 1/3)에 비해 훨씬 낮습니다. 이는 이러한 모델이 일반적인 문제에서는 더 빠르고 리소스 집약적일 수 있지만, 더 깊은 사고 과정이 부족하기 때문에 복잡한 추론 작업에서는 상당한 성능 '한계'를 보인다는 것을 시사합니다.
방법론적 고려 사항 및 제한 사항
애플리케이션에서 EvalThink 평가를 수행할 때 염두에 두어야 할 몇 가지 사항이 있습니다:
- 지표의 정의:
- 이 백서에서 제안한
token효율성 지표는 문헌에서 "과잉 사고"와 "과소 사고"의 개념을 바탕으로 주로 다음 사항에 중점을 둡니다.token사고 과정을 단순화한 척도인 양은 사고의 질에 대한 모든 세부 사항을 포착하지 못합니다. - 하위 사고 사슬의 수 계산은 미리 정의된 키워드에 의존하며, 사고 패턴을 정확하게 반영하기 위해 모델마다 키워드 목록을 조정해야 할 수도 있습니다.
- 이 백서에서 제안한
- 적용 범위:
- 현재 지표는 주로 수학적 추론 데이터 세트에 대해 검증되었으며, 공개 퀴즈나 아이디어 생성 등 다른 시나리오에서의 효과는 아직 테스트되지 않았습니다.
- cater
DeepSeek-R1-Distill-Qwen-7B의 수학적 증류 모델을 기반으로 합니다.MATH-500데이터 세트의 성능에 자연스러운 이점이 있을 수 있습니다. 평가 결과는 모델의 맥락에서 해석해야 합니다.
- 심사 모델 종속성:
token효율성 계산은 추론 단계의 정확성을 정확하게 판단하기 위해 판사 모델(JM)에 의존합니다. AsProcessBench4연구 결과에서 알 수 있듯이 이는 기존 모델로는 어려운 작업이며, 일반적으로 이 작업을 수행하기 위해서는 고도의 역량을 갖춘 모델이 필요합니다.- 심판 모델의 오판은 다음에 직접적인 영향을 미칠 수 있습니다.
token효율성 지표의 정확성을 높이기 위해 올바른 심판 모델을 선택하는 것이 중요합니다.
간단히 말해서EvalThink LLM 사고의 효율성을 정량적으로 평가하기 위한 일련의 프레임워크와 메트릭이 제공되어 다양한 모델이 정확도 측면에서 얼마나 잘 수행되는지 보여줍니다,token 소비와 사고의 깊이 사이의 절충점입니다. 이러한 결과는 모델 트레이닝을 안내하는 데 유용합니다(예 GRPO 및 SFT), 보다 효율적이고 문제의 난이도에 따라 사고의 깊이를 적응적으로 조정할 수 있는 차세대 모델을 개발하는 것이 유익합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...