


이전 두 세대의 비디오 모델(CogVLM2-Video 및 GLM-4V-PLUS)을 기반으로 GLM-4V-Plus-0111 베타 버전을 출시하면서 비디오 이해 기술을 더욱 최적화했습니다. 이 버전에는 기본 가변 해상도와 같은 기술이 도입되어 다양한 비디오 길이와 해상도에 적응하는 모델의 능력이 향상되었습니다.
- 짧은 동영상에 대한 보다 자세한 이해: 동영상 길이가 짧은 콘텐츠의 경우, 기본 고해상도 동영상을 지원하여 자세한 정보를 정확하게 캡처할 수 있습니다.
- 긴 동영상에 대한 이해도 향상: 최대 2시간 길이의 동영상에 대해 모델은 자동으로 더 작은 해상도로 조정하여 시간 및 공간 정보 캡처의 균형을 효과적으로 유지하여 긴 동영상을 심층적으로 이해할 수 있습니다.
이번 업데이트를 통해 GLM-4V-Plus-0111 베타 버전은 시간적 Q&A 측면에서 이전 2세대 모델의 장점을 이어갈 뿐만 아니라 비디오 길이와 해상도 적응성에서도 상당한 개선을 이루었습니다.
I. 성능 비교
최근 발표된 스마트 스펙트럼 리얼타임, 4V, 에어 새 모델 출시, 새 API와 동기화 기사에서는 이미지 이해 영역의 GLM-4V-Plus-0111(베타) 모델에 대한 검토 결과를 자세히 설명했습니다. 이 모델은 여러 공개 리뷰 목록에서 소타 레벨에 도달했습니다.
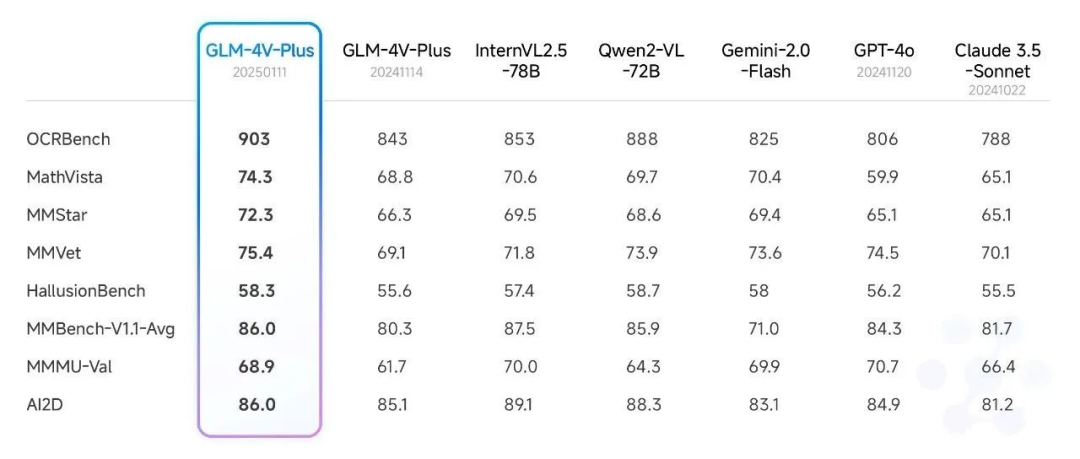
또한 권위 있는 동영상 이해도 평가 세트에 대한 종합 테스트도 실시하여 비교적 우수한 수준을 달성했습니다. 특히 GLM-4V-Plus-0111 베타 모델은 동영상 내 세분화된 동작 이해도와 긴 동영상 이해도 측면에서 동급 동영상 이해도 모델보다 월등히 뛰어난 성능을 보였습니다.
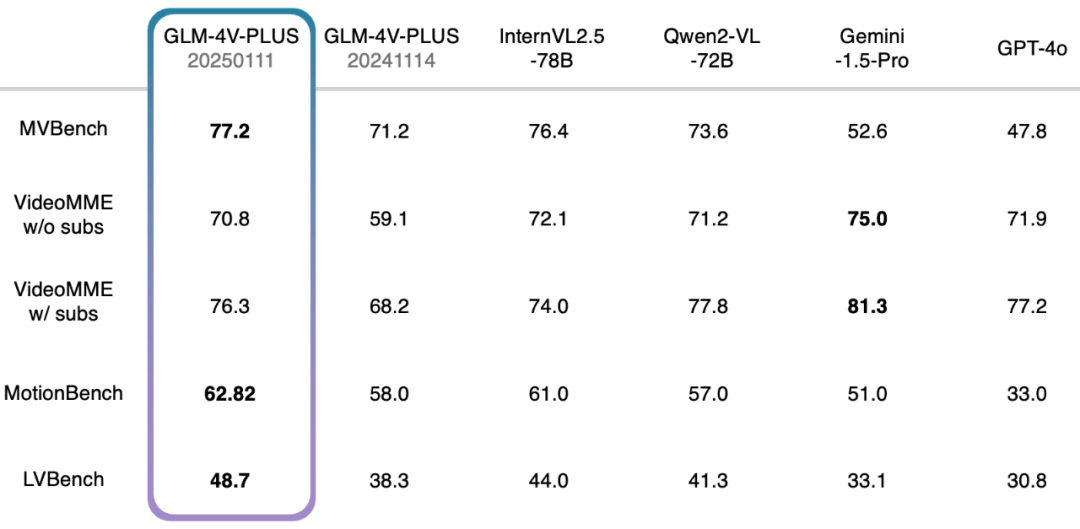
- MVBench: 이 리뷰 세트는 비디오 이해에서 멀티모달 매크로 모델의 결합된 기능을 종합적으로 평가하도록 설계된 20개의 복잡한 비디오 과제로 구성되어 있습니다.
- VideoMME w/o 자막: 멀티모달 평가 벤치마크로서 VideoMME는 대규모 언어 모델의 비디오 분석 기능을 평가하는 데 사용됩니다. 이 경우 자막 없는 버전은 자막이 없는 멀티모달 입력을 의미하며, 비디오 자체의 분석에 중점을 둡니다.
- VideoMME 자막 포함: 자막 제외 버전과 유사하지만, 자막을 멀티모달 입력으로 추가하여 멀티모달 데이터를 처리할 때 모델의 전반적인 성능을 보다 종합적으로 평가할 수 있습니다.
- MotionBench: 세분화된 동작 이해에 중점을 둔 MotionBench는 동작 분석을 위한 동영상 이해 모델의 기능을 평가하기 위한 다양한 동영상 데이터와 고품질 사람의 주석을 포함하는 종합적인 벤치마크 데이터 세트입니다.
- LVBench: 긴 동영상에 대한 모델의 이해 능력을 평가하기 위한 LVBench는 긴 동영상 작업을 처리할 때 멀티모달 모델의 성능을 테스트하고, 긴 시계열 분석에서 모델의 안정성과 정확성을 검증합니다.
II. 시나리오 적용
지난 1년 동안 비디오 이해 모델의 적용 분야가 확대되면서 뉴미디어, 광고, 보안 검토, 산업 제조 등 다양한 산업 분야에서 비디오 설명 생성, 이벤트 세분화, 분류, 라벨링, 이벤트 분석 등 다양한 기능을 제공하고 있습니다. 최신 GLM-4V-Plus-0111 베타 동영상 이해 모델은 이러한 기본 기능을 계승 및 강화하고 동영상 데이터의 처리 및 분석 기능을 더욱 향상시켰습니다.
더욱 정확한 동영상 설명 기능: 기본 해상도 입력과 지속적인 데이터 플라이휠 팬텀 최적화를 통해 새로운 모델은 동영상 설명 생성 시 팬텀 비율을 크게 낮추고 동영상 콘텐츠에 대한 보다 포괄적인 설명을 구현하여 사용자에게 더욱 정확하고 풍부한 동영상 정보를 제공합니다.


효율적인 비디오 데이터 처리: 새로운 모델은 상세한 비디오 설명을 제공할 수 있을 뿐만 아니라 비디오 분류, 제목 생성 및 라벨링 작업을 효율적으로 완료할 수 있습니다. 사용자는 프롬프트를 사용자 지정하여 처리 효율성을 더욱 향상시키거나 지능적인 관리를 위해 자동화된 비디오 데이터 프로세스를 구축할 수 있습니다.

정확한 시간 인식: 동영상 데이터의 시간 차원적 특성에 대응하기 위해 1세대 모델부터 시간 인식 기능을 개선하기 위해 노력해 왔습니다. 이제 새로운 모델은 특정 이벤트의 시점을 보다 정확하게 찾아내고, 의미론적 세분화와 자동화된 동영상 편집을 가능하게 하며, 동영상 편집 및 분석을 강력하게 지원할 수 있습니다.
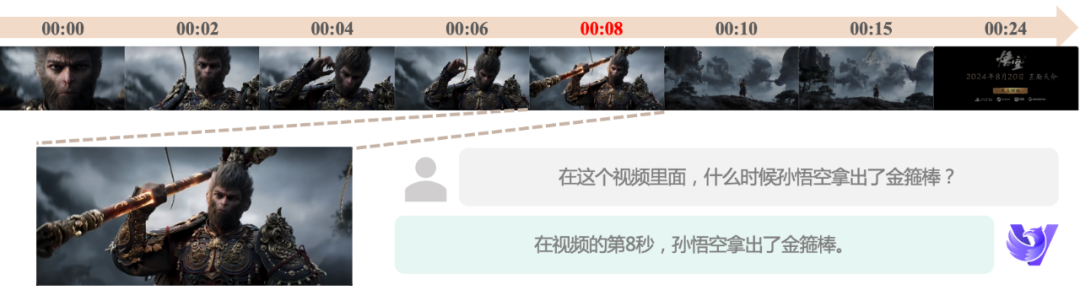
정밀한 모션 이해 기능: 새로운 모델은 더 높은 프레임 속도 입력을 지원하여 비디오 프레임 속도가 낮은 경우에도 작은 움직임 변화를 포착하고 정밀한 모션 이해를 달성할 수 있어 정밀한 모션 분석이 필요한 애플리케이션 시나리오를 강력하게 보장합니다.


초장시간 동영상 이해: 새로운 모델은 혁신적인 가변 해상도 기술을 통해 동영상 처리 시간의 한계를 극복하고 최대 2시간의 동영상 이해를 지원하여 동영상 이해 모델의 비즈니스 적용 시나리오를 크게 확장했으며, 다음은 1시간 수준의 동영상 이해 사례 시연입니다:

실시간 영상 통화 기능: 강력한 영상 이해 모델을 기반으로 실시간 영상 이해 및 Q&A 기능, 최대 2분의 통화 메모리를 갖춘 실시간 영상 통화 모델인 GLM-Realtime을 추가로 개발했습니다. 이 모델은 현재 온라인 상태입니다.스마트 스펙트럼 AI 오픈 플랫폼GLM-Realtime은 고객이 영상 통화 인텔리전스를 구축하는 데 도움을 줄 뿐만 아니라 기존의 네트워크 연결이 가능한 하드웨어와 결합하여 스마트 홈, AI 장난감, AI 안경 및 기타 혁신적인 제품을 쉽게 만들 수 있습니다.
현재 일반 사용자도 스마트 스펙트럼 클리어 스피치 앱에서 AI와 영상 통화를 할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...