
웹UI 열기: 로컬에서 호스팅되는 AI 채팅 웹UI
일반 소개 Open WebUI(이전의 Ollama WebUI)는 LLM(대규모 언어 모델)을 위해 설계된 친숙한 AI 대화형 사용자 인터페이스입니다. 확장 가능하고 기능이 풍부하며 완전히 오프라인으로 실행됩니다.Open WebUI의 뛰어난 기능은 다음과 같습니다.
Ollama: 오픈 소스 빅 언어 모델의 원클릭 네이티브 배포
올라마 일반 설명 올라마는 네이티브 언어 모델을 실행하기 위한 경량 프레임워크로, 사용자가 대규모 언어 모델을 쉽게 구축하고 실행할 수 있습니다. 여러 가지 빠른 시작 및 설치 옵션을 제공하고, Docker를 지원하며, 사용자가 선택할 수 있는 다양한 라이브러리 세트를 포함합니다. 사용이 간편합니다...
딥서치 채팅: 2,000억 건의 MoE 채팅에 기반한 딥서치, 코드 빅 모델
일반 설명 딥서치 채팅은 웹사이트에서의 고객 지원, 판매 및 상호작용을 위한 강력한 실시간 채팅 플랫폼입니다. 실시간 메시징, 챗봇, 분석 등의 기능을 통해 고객과의 상호작용 경험을 향상시킵니다. 더 자세한 정보가 필요하거나 딥시크에 관심이 있으시다면...

원리부터 실전까지 알기 쉬운 AI 만화 내레이션 영상(합성 영상)
소설 합성 영상, 작업의 네 부분으로 나뉘어져 있습니다: 소설 생성 그림 소설 생성 오디오 소설 합성 영상 2차 다듬기 영상 이전 강의 "원리부터 실습까지 이해하는 AI 만화책 설명 영상 (소설 대본 제작)"에서 시작하여 소설 대본 제작 마지막으로 접합된...
Dreamina(즉, Dream AI): Shakeology에서 제작한 AI 이미지 제작 플랫폼
종합 소개 드림이나는 사용자가 텍스트 설명을 사용하여 이미지를 생성할 수 있도록 설계된 Jitterbug에서 출시한 AI 이미지 생성 도구입니다. 단순한 텍스트를 멋진 이미지로 변환할 수 있는 ByteDance에서 개발한 대형 멀티모달 모델을 기반으로 하며, 드림이나의 기능에는 텍스트-투-그림 기능이 포함됩니다.

원리부터 실습까지 이해하기 쉬운 AI 만화책 내레이션 동영상(소설 대본 만들기)
AI 만화의 자동 생성, 특수 보조 장치에 의존하려면 정상적인 작동 순서대로 판매 라이선스를받은 후 오디오 생성부터 시작해야하며 소설 하위 스크립트와 해당 화면 큐 단어를 수동으로 만들 필요가 없습니다. 이 튜토리얼은 원리를 배우기 위한 것입니다. 빠르게 연습하고 싶다면 직접 도구를 찾아보세요...
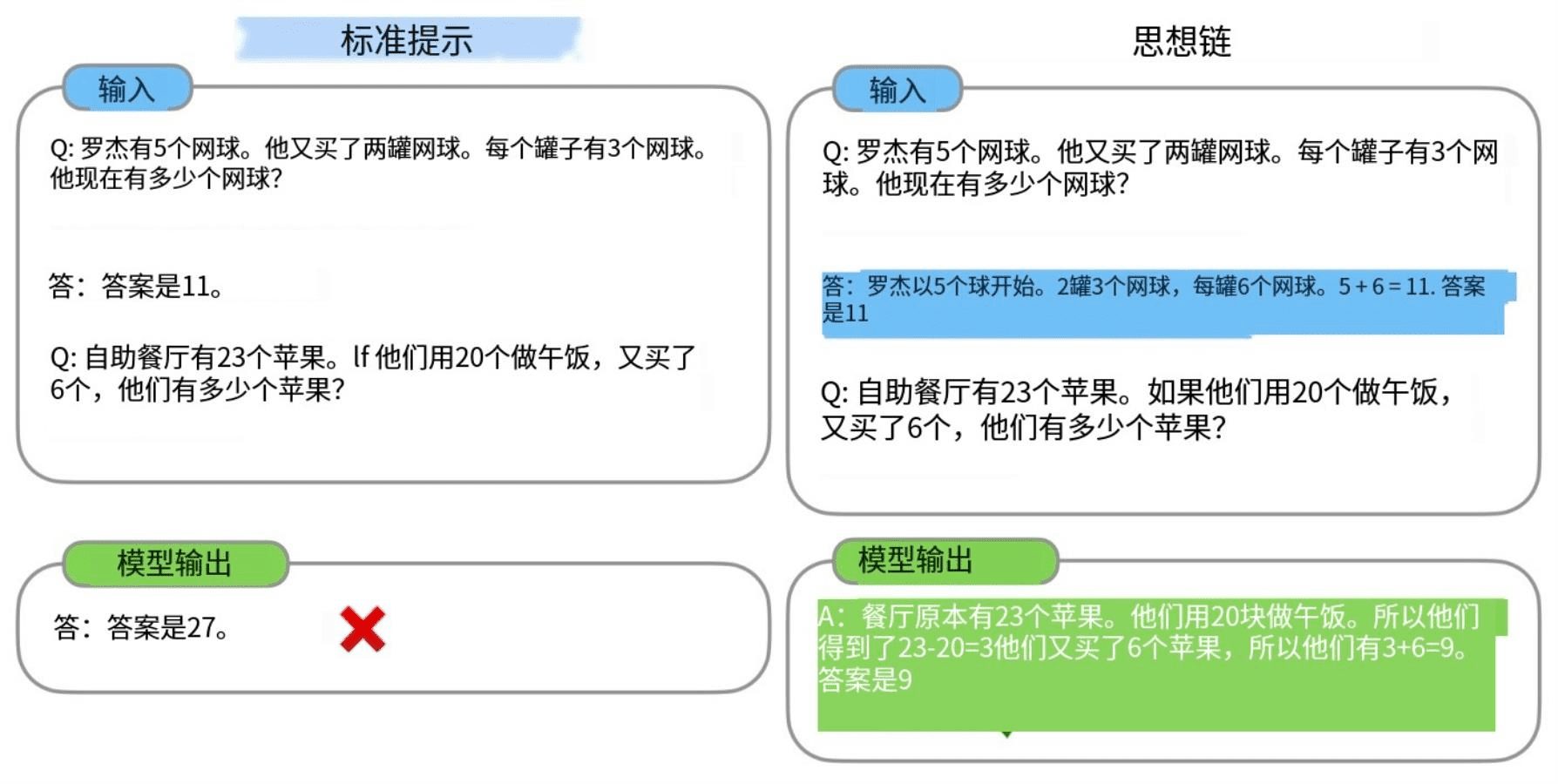
CoT(생각의 사슬) 생각의 사슬
일명: 연쇄 사고의 정의와 원리 "연쇄 사고"(줄여서 CoT)는 일련의 연결된 사고 단계로 구성된 생각의 사슬을 만드는 원리에 기반한 사고 방법입니다. 이 방법은 사고 과정을 다음과 같이 나누어 작동합니다.
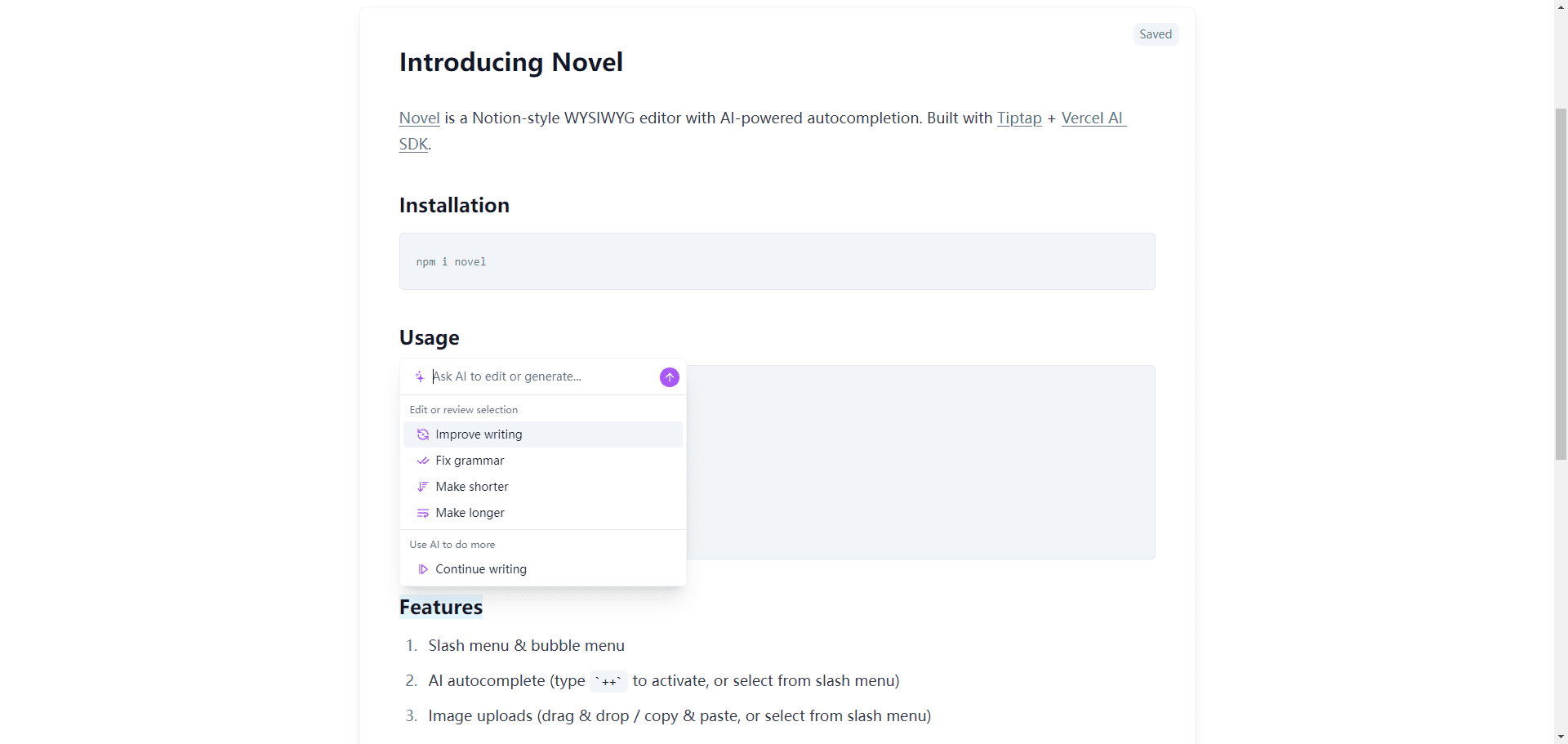
Novel: Notion AI를 모방한 오픈 소스 글쓰기 편집기
포괄적 인 소개 이것은 Novel이라고 불리는 Steven Tey가 개발 한 오픈 소스 프로젝트로, 사용자가 텍스트 입력의 효율성을 향상시키는 데 도움이되는 통합 AI 자동 완성 기능인 Notion 스타일 WYSIWYG 텍스트 편집기입니다. 이 프로젝트는 자세한 문서 및 설치 지침을 제공합니다 ...
버클 튜토리얼: '코드 노드'를 사용하면 텍스트 분할 프로세스가 길어집니다.
소설 생성을 자동화하는 학습 과정에서 긴 텍스트를 세그먼트화한 다음 세그먼트에 대한 샷 스크립트를 생성하는 것은 작업의 중요한 부분입니다. 이 방법을 사용하면 생성되는 그림 이미지의 수를 줄일 수 있지만 문장 단위로 생성되는 음성 해설 도구가 함께 제공되어야 합니다. 이렇게 해야 영상과 사운드가 일관성을 유지할 수 있습니다. 많은 도구가 첫 번째 가져오기를 기반으로 합니다...
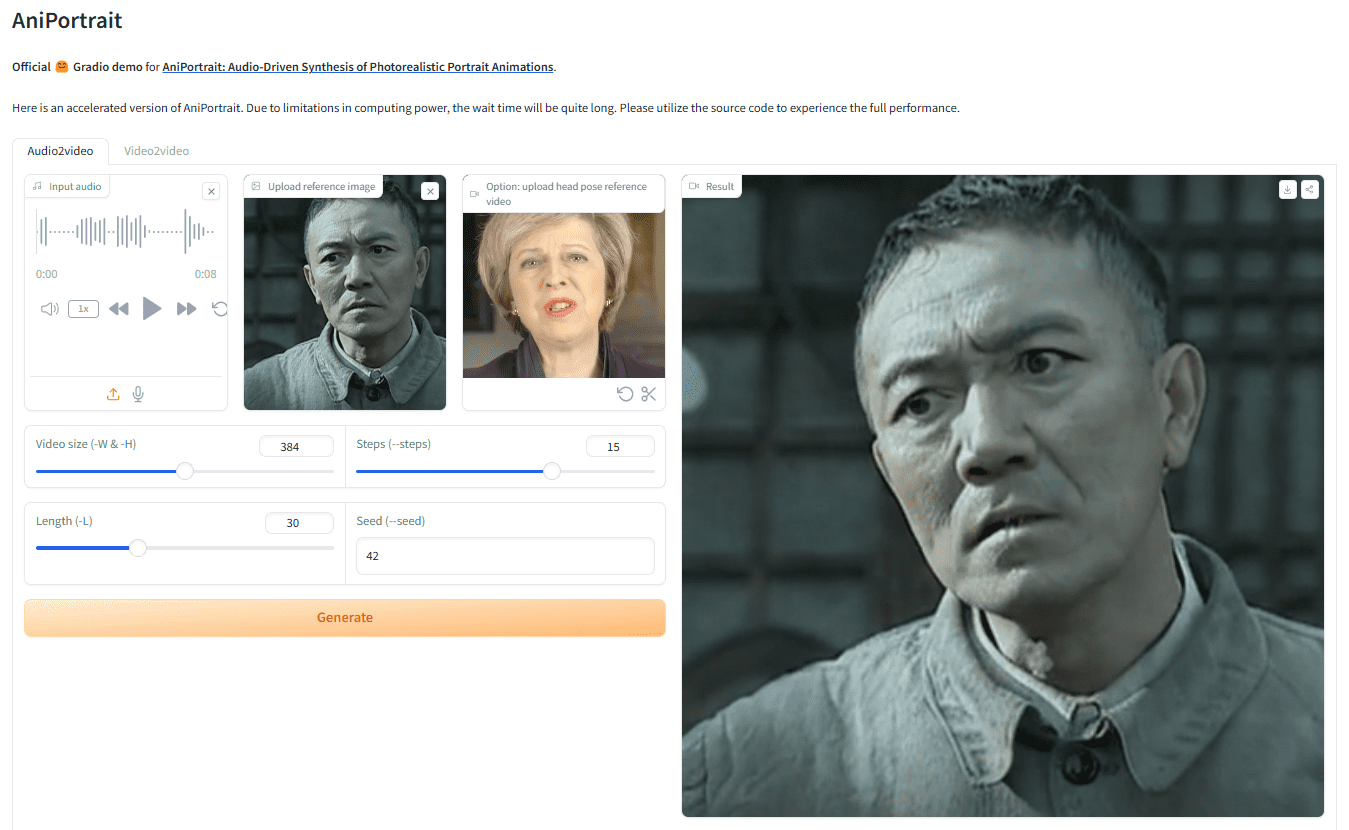
AniPortrait: 오디오 기반 사진 또는 비디오 모션으로 사실적인 디지털 사람 음성 비디오를 생성합니다.
일반 소개 AniPortrait는 오디오를 기반으로 사실적인 인물 애니메이션을 생성하는 혁신적인 프레임워크입니다. 화웨이, 텐센트 게임즈의 Know Yourself Lab의 양제쥔과 왕즈셩이 개발한 AniPortrait는 오디오와 참조 인물 이미지에서 고품질 애니메이션을 생성할 수 있습니다....