


1. 개요
음성 합성 기술은 최근 몇 년 동안 특히 자연스럽고 부드러운 실시간 음성 생성을 가능하게 하는 데 있어 상당한 발전을 이루었습니다. 그러나 지연 시간, 발음 정확도, 화자 일관성 등의 문제는 여전히 실제 애플리케이션, 특히 빠른 응답성이 요구되는 스트리밍 애플리케이션에서 업계를 괴롭히고 있습니다. 이러한 기술적 과제는 특히 기존 모델의 처리 능력을 넘어서는 혀 꼬임이나 다의성 단어와 같은 복잡한 언어 입력을 처리할 때 더욱 심각합니다. 이러한 문제를 해결하기 위해 알리바바 연구진은 음성 합성 기술 문제를 효과적으로 해결하기 위해 업그레이드된 모델인 CosyVoice 2를 출시했습니다.
2. 코지보이스 2 데뷔: 기본부터 혁신까지
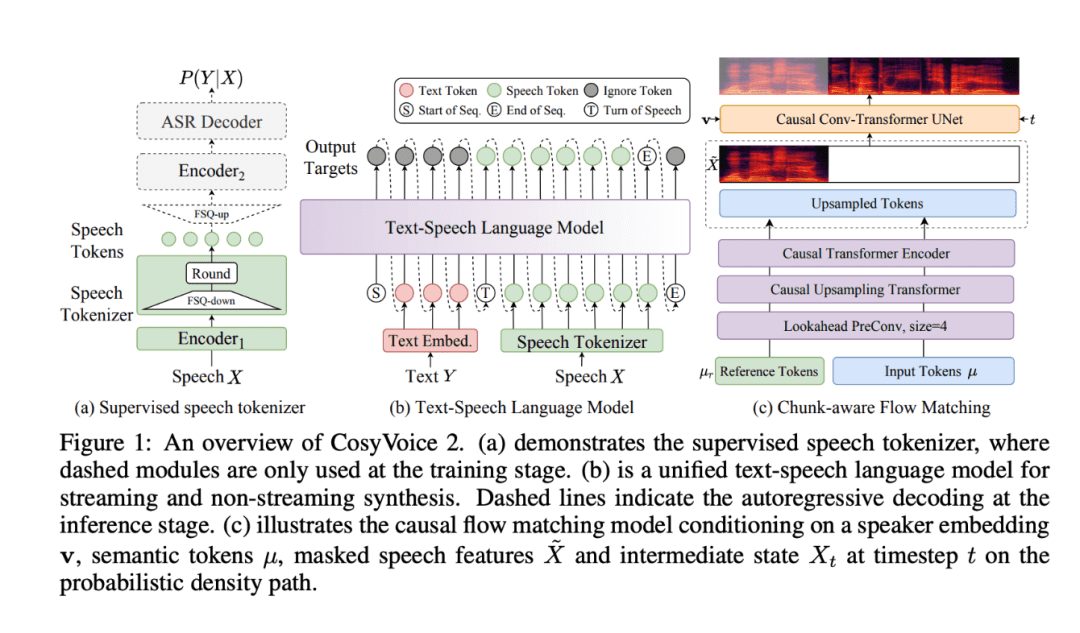 CosyVoice 2는 기존 CosyVoice의 기반 위에 구축되었으며 음성 합성 기술이 크게 업그레이드되었습니다. 이 향상된 모델은 스트리밍 애플리케이션에 최적화되었을 뿐만 아니라 오프라인 애플리케이션에서도 상당한 진전을 이루었습니다. 특히 텍스트 음성 변환 및 대화형 음성 시스템에서 다양한 애플리케이션 시나리오에 대한 적응성, 유연성 및 정확성이 향상되었습니다.
CosyVoice 2는 기존 CosyVoice의 기반 위에 구축되었으며 음성 합성 기술이 크게 업그레이드되었습니다. 이 향상된 모델은 스트리밍 애플리케이션에 최적화되었을 뿐만 아니라 오프라인 애플리케이션에서도 상당한 진전을 이루었습니다. 특히 텍스트 음성 변환 및 대화형 음성 시스템에서 다양한 애플리케이션 시나리오에 대한 적응성, 유연성 및 정확성이 향상되었습니다.
CosyVoice 2의 주요 특징:
- 통합 스트리밍 및 비스트리밍 모드CosyVoice 2는 실시간 생성 또는 오프라인 처리 등 다양한 애플리케이션 시나리오에 성능 저하 없이 원활하게 적응할 수 있습니다.
- 더 높은 발음 정확도복잡한 언어 환경에서 CosyVoice 2는 특히 다음절 단어나 혀가 꼬이는 단어를 다룰 때 30%-50%의 발음 오류를 줄이고 음성 명료도를 크게 향상시킵니다.
- 향상된 스피커 일치성제로 샷 합성이든 교차 언어 합성이든, CosyVoice 2는 모든 합성이 자연스럽고 매끄럽게 이루어질 수 있도록 일관된 출력을 보장합니다.
- 더욱 정밀한 명령 제어사용자는 자연어 명령을 통해 목소리의 톤, 스타일, 억양을 정밀하게 제어하고 감정적 필요에 따라 음성 성능을 조정할 수도 있습니다.
3. 혁신의 기반이 되는 기술 및 강점
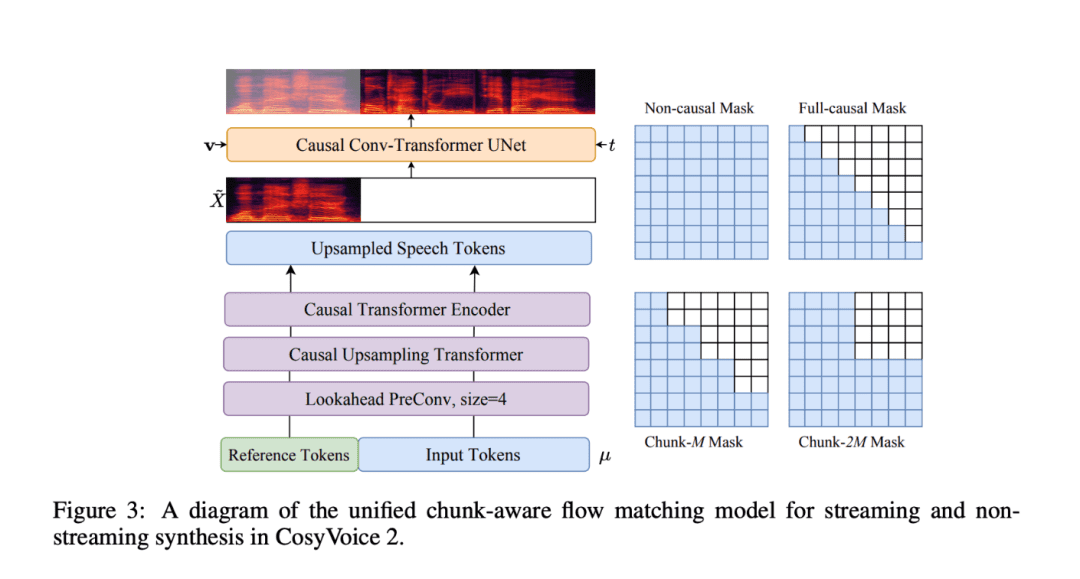
CosyVoice 2는 기술 혁신 덕분에 음성 합성 분야의 여러 과제를 해결할 수 있었습니다.
- 유한 스칼라 양자화(FSQ) 기술: FSQ는 기존의 벡터 양자화 방식을 대체하고 음성 태그 어휘의 사용을 최적화하여 의미 표현 능력과 합성 품질을 향상시킵니다. 이 기술 혁신은 모델의 표현력을 향상시킬 뿐만 아니라 데이터 처리의 복잡성을 효과적으로 줄여줍니다.
- 간소화된 텍스트 음성 변환 아키텍처: CosyVoice 2는 사전 학습된 대규모 언어 모델(LLM)을 기반으로 하므로 추가 텍스트 인코더가 필요하지 않으며 모델 아키텍처를 간소화하여 다국어 성능을 향상시킵니다. 이러한 아키텍처 설계 덕분에 CosyVoice 2는 여러 언어를 처리할 때 훨씬 더 효율적이고 정확합니다.
- 블록 인식 인과적 흐름 매칭: 이 혁신적인 기술을 통해 의미 및 음향 기능을 최소한의 지연 시간으로 조정할 수 있으므로 CosyVoice 2는 특히 실시간 음성 상호작용 및 스트리밍 애플리케이션에서 실시간 음성 생성에 탁월한 성능을 발휘할 수 있습니다.
- 확장된 명령 데이터 세트: 1,500시간 이상의 학습 데이터를 통해 다양한 억양, 감정, 음성 스타일에 대한 세분화된 제어 기능을 추가하여 음성 합성을 더욱 유연하고 표현력 있게 만들어주는 CosyVoice 2. 따뜻한 목소리 톤이든 긴장된 감정이든, CosyVoice 2는 이를 정확하게 포착하고 표현할 수 있습니다.
CosyVoice 2의 성능: 실제 문제를 해결하는 방법
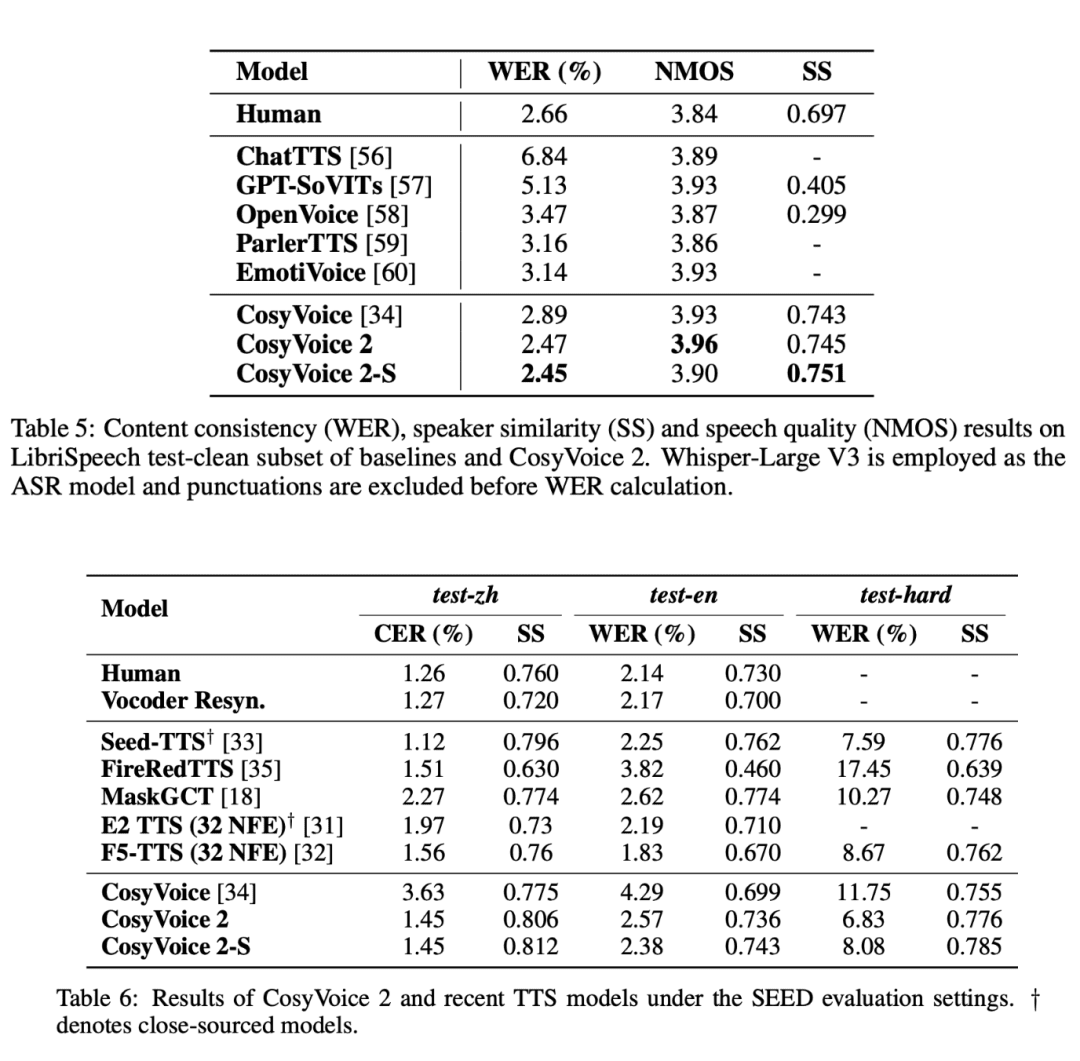
일련의 엄격한 평가 테스트에서 CosyVoice 2는 특히 짧은 지연 시간, 높은 정확도 및 음성 일관성 측면에서 부인할 수 없는 이점을 보여주었습니다.
- 짧은 지연 시간 및 높은 효율성CosyVoice 2는 음성 생성 시 응답 시간이 150밀리초로 매우 짧아 음성 채팅 및 스트리밍 상호작용과 같은 실시간 음성 애플리케이션에 이상적입니다.
- 발음 정확도 향상CosyVoice 2는 복잡한 언어 구조(예: 다음절, 혀 꼬임 등)를 크게 개선하여 발음 정확도를 크게 향상시키고 일상적인 음성 합성에서 오류를 줄입니다.
- 일관된 스피커 성능코지보이스 2는 언어 간 합성이나 제로 샷 합성 등 다양한 합성 작업에서 높은 수준의 일관성을 유지할 수 있으며, 음성의 자연스러움과 안정성이 크게 보장됩니다.
- 다국어 지원CosyVoice 2는 일본어와 한국어와 같은 언어에 대한 벤치마크에서도 우수한 성능을 보였으며, 일부 겹치는 문자 집합에 대한 문제에도 불구하고 여전히 교차 언어 합성의 힘을 보여주었습니다.
- 까다로운 시나리오에서의 복원력코지보이스 2는 일부 까다로운 음성 시나리오(예: 혀 꼬는 소리)에서 이전 모델보다 더 나은 선명도와 정확도를 보여주며 이전의 기술적 한계를 뛰어넘었습니다.
5. 결론
CosyVoice 2의 출시는 음성 합성 기술의 중요한 발전입니다. 지연 시간, 정확도 및 화자 일관성과 같은 주요 문제를 해결하여 더욱 성숙하고 안정적인 솔루션을 제공하며, FSQ 및 블록 인식 인과 흐름 매칭과 같은 혁신적인 기술은 모델의 성능과 사용 편의성을 강력하게 지원하며, 대규모 학습 데이터 세트와 음성 스타일의 정밀한 제어로 다양하고 복잡한 음성 애플리케이션 시나리오에 대응할 수 있습니다.
CosyVoice 2는 다국어 지원과 복잡한 언어 시나리오 처리 측면에서 여전히 개선이 필요하지만, 특히 스트리밍 미디어 및 실시간 음성 생성 응용 분야에서 향후 음성 합성 기술을 위한 견고한 기반을 마련하여 광범위한 발전 전망을 가지고 있습니다. AI 음성 비서, 지능형 고객 서비스 또는 실시간 번역 분야에서 CosyVoice 2는 강력한 잠재력을 입증하고 음성 합성 기술의 획기적인 발전을 위한 길을 열어줍니다.
참조:
- https://arxiv.org/abs/2412.10117
- https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
- https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...