


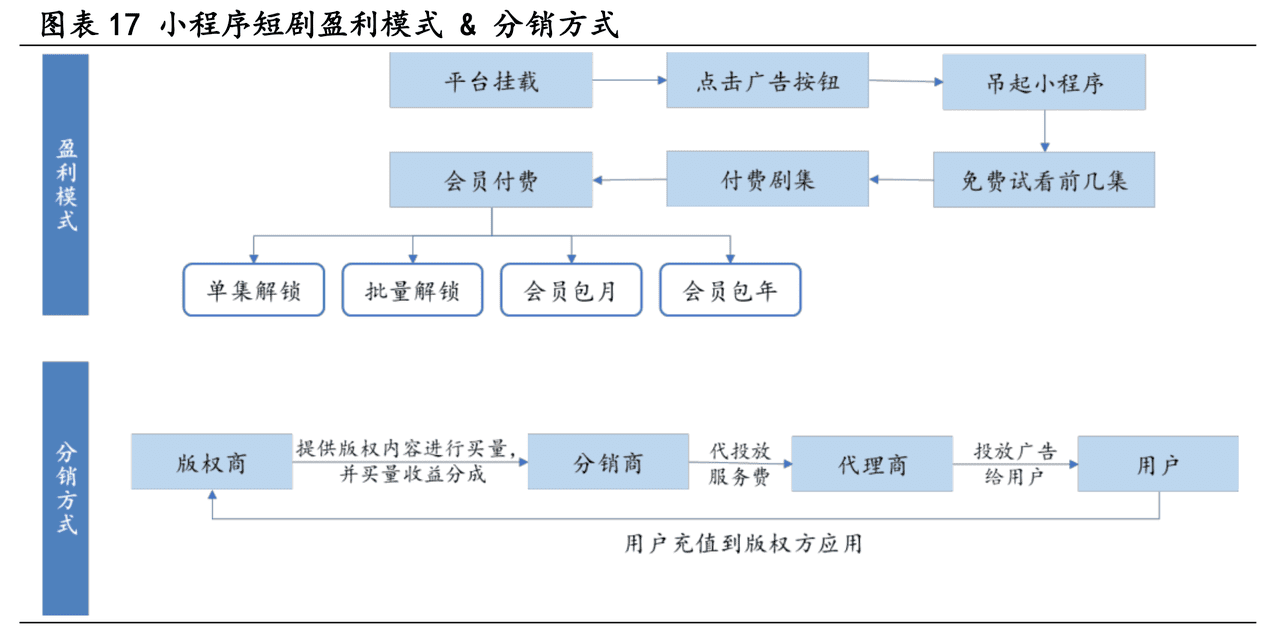
검색 증강 생성(RAG)은 대규모 언어 모델(LLM)과 벡터 데이터베이스의 가장 인기 있는 애플리케이션 중 하나가 되고 있으며, RAG는 다음과 같은 벡터 데이터베이스에서 데이터를 추출하여 만들어집니다. WeaviateRAG 애플리케이션은 일반적으로 챗봇과 질의응답 시스템에서 사용되며, 검색된 컨텍스트를 통해 대규모 언어 모델에 입력을 보강하는 프로세스입니다.
다른 엔지니어링 시스템과 마찬가지로 성능 평가는 다음과 같은 경우에 중요합니다. RAG RAG 파이프라인은 세 가지 구성 요소로 나뉩니다:
- 인덱싱
- 검색(데이터)
- 생성
RAG 평가는 이러한 구성 요소 간의 상호 작용이 복잡하고 테스트 데이터 수집이 어렵기 때문에 까다로운 작업입니다. 이 백서에서는 평가에 LLM을 사용하는 흥미로운 발전과 RAG 구성 요소의 현재 상태에 대해 설명합니다.
간단히 말해서저희는 다음과 같은 파트너십을 통해 영감을 얻었습니다. Ragas 의 제작자인 지틴 제임스와 샤울 에스의 대화는 다음과 같습니다. 이 대담은 Ragas 그리고 ARES가 개척한 RAG 시스템의 LLM 평가에 대한 새로운 발전은 기존 지표를 되돌아보고 조정 가능한 RAG 파라미터를 검토하도록 유도했습니다. 연구 과정에서 저희는 RAG 실험 추적 소프트웨어의 가능한 형태에 대해 더 깊이 생각해보고 RAG 시스템이 에이전트 시스템과 어떻게 다른지, 그리고 어떻게 평가되는지를 더욱 명확히 했습니다.
블로그 게시물은 다음 다섯 가지 주요 섹션으로 구성되어 있습니다:
- LLM 평가제로 샘플, 소수의 샘플, LLM 평가기 크기 미세 조정 등 LLM을 사용하여 RAG 성능을 채점하는 새로운 트렌드입니다.
- RAG 지표생성, 검색 및 인덱싱을 평가하는 데 사용되는 일반적인 메트릭과 이들 간의 상호 작용 방식입니다.
- RAG의 규제 매개변수RAG 시스템의 성능에 크게 다른 방식으로 영향을 미치는 결정에는 어떤 것이 있나요?
- 스케줄링RAG 시스템의 실험 구성 추적은 어떻게 관리하나요?
- RAG에서 에이전트 평가까지RAG를 인덱싱, 검색, 생성의 3단계 프로세스로 정의합니다. 이 섹션에서는 RAG 시스템이 에이전트 시스템으로 변환되는 시점과 그 차이점을 평가하는 방법에 대해 설명합니다.
LLM 평가
가장 새롭고 흥미로운 부분인 LLM 평가부터 시작해 보겠습니다! 머신 러닝의 역사는 Yelp 리뷰가 긍정적인지 부정적인지 또는 기사가 "보스턴 셀틱스의 감독은 누구인가요?"라는 쿼리와 관련이 있는지 판단하는 등 데이터에 수동으로 주석을 다는 수작업에 크게 의존해 왔습니다. LLM은 점차 수작업을 줄이면서 데이터에 주석을 다는 데 더욱 효율적이 되고 있습니다. 이는 RAG 애플리케이션의 성장을 가속화하고 있는 핵심적인 '새로운 트렌드'입니다.
그대로 두세요(SB에게) Ragas 제로 샘플 LLM 평가와 같은 프레임워크가 개척한 가장 일반적인 기법은 제로 샘플 LLM 평가입니다. 제로 샘플 LLM 평가는 대규모 언어 모델에 "이 검색 결과의 관련성을 1부터 10까지의 척도로 평가해 주세요."와 같은 템플릿을 사용하여 메시지를 표시하는 것입니다. 쿼리는 {query}이고 검색 결과는 {search_results}입니다."와 같은 템플릿을 사용합니다. 다음 그림은 LLM을 사용하여 RAG 시스템의 성능을 평가하는 방법을 보여줍니다.

제로 샘플 LLM 평가에는 세 가지 주요 튜닝 기회가 있습니다: 1. 정밀도, 리콜 또는 nDCG와 같은 설계 메트릭, 2. 이러한 단서의 특정 언어, 3. 평가에 사용되는 언어 모델(예: GPT-4, Coral, Llama-2, Mistral 등). 현재 가장 큰 관심사는 평가에 LLM을 사용하는 데 드는 비용입니다. 예를 들어, GPT-4를 사용하여 10개의 검색 결과를 평가하는 경우(결과당 500개의 토큰과 쿼리 및 명령에 100개의 토큰, 총 약 6,000개의 토큰을 사용한다고 가정할 때) 약 $1000의 비용이 듭니다. 토큰 0.005, 즉 100개의 쿼리를 평가하는 데 3달러를 사용합니다.
Ragas와 같은 프레임워크가 제로 샘플 LLM 평가를 장려함에 따라 사람들은 더 적은 샘플의 LLM 평가에 대한 필요성에 의문을 제기하기 시작했습니다. 제로 샘플 LLM 평가는 "충분히 좋은" 평가이므로 RAG 시스템 튜닝의 북극성 역할을 하기에 충분할 수 있습니다. 아래 그림에서 볼 수 있듯이 RAGAS 점수는 생성된 두 가지 메트릭 각각에 대해 4개의 제로 샘플 LLM 프롬프트로 구성됩니다:성실성 노래로 응답 답변 관련성(답변 관련성)와 검색을 위한 두 가지 지표가 있습니다:컨텍스트 정밀도(컨텍스트 정밀도) 노래로 응답 컨텍스트 리콜(컨텍스트 리콜).
제로 샘플에서 적은 샘플의 LLM 평가로의 전환은 간단합니다. 검색 결과와 쿼리의 관련성에 대한 주석이 달린 몇 가지 예시를 명령 템플릿에 포함시켰는데, 이를 컨텍스트 학습이라고도 합니다. 이 기술의 발견은 GPT-3의 핵심적인 혁신 중 하나였습니다.
예를 들어, 예제에 수동 관련성 점수를 5개 추가하면 프롬프트에 30,000 토큰이 추가됩니다. 위와 동일한 비용을 가정하면 100개의 쿼리에 대해 3달러에서 15달러로 인상되는 것으로 평가합니다. 이는 단순한 추정 예시이며 실제 LLM의 가격 책정 모델을 기반으로 한 것이 아닙니다. 주요 고려 사항은 샘플 예제를 더 적게 추가하면 일반적으로 더 작은 입력에 대해 LLM보다 높은 가격이 책정되는 더 긴 컨텍스트 모델이 필요할 수 있다는 점입니다.
제로 샘플 또는 소수의 샘플 추론을 기반으로 하는 이러한 유형의 LLM 평가는 이미 매우 매력적이지만, 추가 연구에 따르면 지식 증류를 통해 알고리즘을 훈련함으로써 LLM 평가 비용을 더욱 절감할 수 있는 것으로 나타났습니다. 이는 평가 작업에 대한 학습 데이터를 생성하고 이를 더 작은 모델로 미세 조정하기 위해 LLM을 사용하는 것을 말합니다.
존재 ARES검색 강화 생성 시스템을 평가하기 위한 자동화된 프레임워크에서 Saad-Falcon 등은 자체 LLM 평가자를 훈련하는 것이 제로 샘플 단서를 능가할 수 있다는 사실을 발견했습니다. 처음에 ARES에는 대상 말뭉치의 단락 모음, 150개 이상의 인간 선호도 검증 데이터 포인트, 도메인 내에서 언더샘플링된 쿼리 예시 5개의 세 가지 입력이 필요합니다. ARES는 이러한 언더샘플링된 예시를 사용하여 대량의 합성 쿼리 데이터를 생성하고, 루프 일관성 원칙(즉, 합성 쿼리로 검색할 때 합성 쿼리를 생성한 문서를 검색할 수 있는가? . 그런 다음 ARES는 문맥 관련성및답변의 신뢰성 노래로 응답 답변의 관련성 경량 분류기 미세 조정.
저자의 실험적 미세 조정 DeBERTa-v3-large이 모델에는 각 분류기 헤드가 기본 언어 모델을 공유하여 총 3개의 분류 헤드를 추가하는 보다 경제적인 4억 3,700만 개의 파라미터가 포함되어 있습니다. 합성 데이터를 훈련 및 테스트 세트로 분할하여 ARES 시스템을 평가한 결과, 미세 조정된 모델이 제로 샘플 및 소수 샘플 GPT-3.5-turbo-16k보다 훨씬 뛰어난 성능을 보였습니다. 자세한 내용(예: 예측 기반 추론(PPI)에서 신뢰 구간을 혁신적으로 사용하는 방법 및 실험의 세부 사항)은 다음을 참조하세요. 사드-팔콘 외논문.
평가에서 LLM의 잠재적 영향을 더 잘 이해하기 위해 기존의 RAG 체계적 벤치마킹 방법론과 LLM 평가의 특정 변형에 대해 계속 설명하겠습니다.
RAG 지표
생성, 검색, 인덱싱이라는 최상위 관점에서 RAG 메트릭을 소개합니다. 그런 다음 인덱스 구축, 검색 방법 조정, 생성 옵션의 하위 수준 관점에서 RAG 조정 매개변수를 제시합니다.
최상위 관점에서 RAG 메트릭을 제시하는 또 다른 이유는 색인 오류는 검색과 생성으로 전달되지만 생성 오류(예: 우리가 정의하는 계층)는 색인 오류에 영향을 미치지 않기 때문입니다. 현재 RAG 평가 상태에서는 RAG 스택에 대한 엔드투엔드 평가가 거의 이루어지지 않으며 종종 오라클 컨텍스트 어쩌면 제어 간섭 용어(CIT)(예: 중간에서 길을 잃다 실험)을 사용하여 생성된 진실성과 답변의 관련성을 결정합니다. 마찬가지로 임베딩은 일반적으로 근사 최인접 이웃 오차를 고려하지 않는 폭력 지수로 평가됩니다. 근사 근사 이웃 오류는 일반적으로 초당 쿼리 수와 리콜 간의 트레이드 오프 측면에서 최적의 정확도 지점을 찾아 측정하며, ANN 리콜은 쿼리와 "관련성"이 있는 것으로 표시된 문서가 아니라 쿼리의 실제 가장 가까운 이웃을 기준으로 합니다.
지표 생성
RAG 애플리케이션의 전반적인 목표는 검색된 문맥을 사용하여 유용한 출력을 생성하는 것입니다. 평가는 출력이 컨텍스트를 사용하고 소스에서 직접 가져온 것이 아니라는 점을 고려하여 중복된 정보를 피하고 불완전한 답변을 방지해야 합니다. 산출물에 점수를 매기려면 각 기준을 포괄하는 지표를 개발해야 합니다.
Ragas LLM(대규모 언어 모델링) 결과의 성능을 측정하기 위해 타당성과 답변 관련성이라는 두 가지 점수가 도입되었습니다.신뢰성 정도 검색의 맥락에 따라 답변의 사실적 정확성을 평가합니다.답변의 관련성 질문에 주어진 답변의 관련성을 결정합니다. 답변의 신뢰도 점수는 높지만 답변 관련성 점수는 낮을 수 있습니다. 예를 들어, 그럴듯한 답변은 문맥을 직접적으로 복제할 수 있지만 답변 관련성이 낮습니다. 답변의 완전성이 부족하거나 중복된 정보를 포함하는 경우 답변 관련성 점수가 감점됩니다.
2020년에 구글은 Meena미나의 목표는 다음을 수행할 수 있다는 것을 보여주는 것입니다. 합리적이고 구체적인 를 측정했습니다. 오픈 도메인 챗봇의 성능을 측정하기 위해 민감도 및 구체성 평균(SSA) 평가 지표를 도입했습니다. 봇의 응답의 합리성은 맥락에서 이해가 되고 구체적이어야 합니다(구체성 평균). 이를 통해 결과물이 포괄적이고 모호하지 않아야 합니다.2020 이를 위해서는 사람이 챗봇과 대화하고 수동으로 점수를 매겨야 합니다.
모호한 답변을 피하는 것도 좋지만, 큰 언어 모델이 나타나지 않도록 하는 것도 마찬가지로 중요합니다. 상상의 산물 . 착각은 빅 언어 모델에서 생성된 답변이 실제 사실이나 제공된 컨텍스트에 기반하지 않는다는 사실을 말합니다.LlamaIndex 활용 FaithfulnessEvaluator 메트릭을 사용하여 이를 측정합니다. 점수는 응답이 검색된 컨텍스트와 일치하는지 여부에 따라 결정됩니다.
생성된 답변의 품질을 평가하는 것은 여러 지표에 따라 달라집니다. 답변이 사실이지만 주어진 질문과 관련이 없을 수 있습니다. 또한 답변이 모호하고 답변을 뒷받침하는 중요한 문맥 정보가 부족할 수도 있습니다. 다음으로 파이프라인의 이전 계층으로 돌아가 검색 메트릭에 대해 논의하겠습니다.
지표 검색
평가 스택의 다음 계층은 정보 검색입니다. 검색 기록을 평가하려면 사람이 쿼리와 관련된 문서에 주석을 달아야 합니다. 따라서 하나의 쿼리 주석을 생성하려면 100개의 문서에 대한 관련성을 주석으로 달아야 할 수도 있습니다. 이는 일반적인 검색 쿼리에서도 이미 매우 어려운 작업이며, 도메인별(예: 법률 계약서, 의료 환자 기록 등) 검색 엔진을 구축할 때는 문제가 더욱 악화됩니다.
주석 비용을 줄이기 위해 휴리스틱을 사용하여 검색 관련성을 판단하는 경우가 많습니다. 가장 일반적인 것은 클릭 로깅으로, 쿼리가 주어졌을 때 클릭한 제목은 관련성이 있지만 클릭하지 않은 제목은 관련성이 없을 수 있습니다. 이를 머신 러닝에서는 약한 감독이라고도 합니다.
데이터 세트가 준비되면 평가에 일반적으로 사용되는 세 가지 메트릭이 있습니다: nDCG 및리콜 노래로 응답 정밀도 NDCG(정규화된 할인 누적 이득)는 여러 관련성 태그를 기준으로 순위를 측정합니다. 예를 들어 비타민 B12에 대한 문서는 비타민 D에 대한 쿼리에 가장 관련성이 높은 결과가 아닐 수 있지만 보스턴 셀틱스에 대한 문서보다는 더 관련성이 높습니다. 상대적 순위의 추가적인 복잡성으로 인해 이진 관련성 레이블(관련성 있는 경우 1, 관련성 없는 경우 0)이 자주 사용됩니다. Recall은 검색 결과에서 얼마나 많은 긍정적인 샘플이 포착되는지를 측정하고, Precision은 관련성 있는 것으로 레이블이 지정된 검색 결과의 비율을 측정합니다.
따라서 빅 언어 모델은 "다음 검색 결과 중 {query} 쿼리와 관련된 검색 결과는 몇 개입니까?"라는 프롬프트를 통해 정확도를 계산할 수 있습니다. {검색_결과}". 빅 언어 모델 프롬프트에서 "이 검색 결과에 {query} 쿼리에 답변하는 데 필요한 모든 정보가 포함되어 있나요?"라는 프롬프트에서 Recall에 대한 프록시를 얻을 수도 있습니다. {검색_결과}". 또한 독자들이 Ragas의 몇 가지 힌트를 확인해 보시기를 권장합니다. 여기(문학).
살펴볼 만한 또 다른 메트릭은 빅 언어 모델링에서 "{query}라는 쿼리를 기준으로 어떤 검색 결과 집합이 더 관련성이 높습니까?"라는 프롬프트가 표시되는 LLM Wins입니다. 세트 A {Set_A} 또는 세트 B {Set_B}. 매우 중요합니다! 출력을 '집합 A' 또는 '집합 B'로 제한하세요."라는 메시지가 표시됩니다.
이제 한 단계 더 깊이 들어가서 벡터 인덱스를 비교하는 방법을 이해해 보겠습니다.
인덱싱된 지표
Weaviate에 익숙한 숙련된 사용자는 다음과 같은 사실을 알고 있을 것입니다. ANN 벤치마크벤치마킹 테스트는 다음과 같은 영감을 주었습니다. Weaviate 버전 1.19의 gRPC API 개발ANN 벤치마크는 초당 쿼리 수(QPS)와 리콜 수를 측정하며 단일 스레드 제한과 같은 세부 사항을 고려합니다. 데이터베이스는 일반적으로 지연 시간과 스토리지 비용을 기준으로 평가되지만, 랜덤 벡터 인덱스는 정밀도 측정에 더 중점을 둡니다. 이는 다음과 대조적입니다. SQL 선택 문의 대략적인 계산 다소 비슷하지만 벡터 인덱싱이 대중화됨에 따라 근사치로 인한 오류가 더 많은 관심을 받을 것으로 예상됩니다.
정확도는 Recall로 측정됩니다. 벡터 인덱싱에서 리콜은 대략적인 인덱싱 알고리즘이 반환한 실측 자료의 가장 가까운 이웃 수와 무차별 대입 검색에 의해 결정된 가장 가까운 이웃 수의 비율을 말합니다. 이는 정보 검색(정보 검색)는 모든 관련 문서 중에서 검색된 관련 문서의 비율을 나타내는 일반적인 '리콜'의 사용과 다릅니다. 둘 다 일반적으로 연결된 @K 매개변수를 사용하여 측정됩니다.
전체 RAG 스택의 맥락에서 흥미로운 질문이 있습니다:ANN 정확도 오류는 언제 정보 검색(IR)의 오류로 이어지나요? 예를 들어, 80%의 리콜로 1,000 QPS를 달성하거나 95%의 리콜로 500 QPS를 달성할 수 있다면 위에서 언급한 검색 지표(예: nDCG 또는 LLM(대규모 언어 모델링) 리콜 점수 검색)에 어떤 영향이 있을까요?
RAG 지표에 대한 요약
요약하면 색인, 검색 및 생성을 평가하기 위한 메트릭이 표시됩니다:
- 생성충실도 및 답변 관련성, 대규모 환각 감지(예: 합리성 및 특이성 평균, 민감도 및 특이성 평균, SSA)와 같은 메트릭의 진화 등입니다.
- 검색(데이터)LLM 점수에서 문맥 정확도 대 문맥 리콜의 새로운 기회, 리콜, 정확도 및 nDCG 측정을 위한 인간 주석에 대한 개요입니다.
- 인덱싱리콜은 벡터 검색 알고리즘이 반환한 가장 가까운 실측 데이터 이웃의 수로 측정됩니다. 여기서 중요한 문제는ANN 오류는 언제 IR 오류로 전환되나요?
모든 구성 요소는 일반적으로 성능과 지연 시간 또는 비용 사이에서 균형을 맞출 수 있습니다. 더 비싼 언어 모델을 사용하면 더 높은 품질의 생성을 얻을 수 있고, 재정렬기로 결과를 필터링하면 더 높은 품질의 검색을 얻을 수 있으며, 더 많은 메모리를 사용하면 더 높은 리콜 인덱싱을 얻을 수 있습니다. 이러한 절충점을 관리하여 성능을 개선하는 방법은 "RAG의 손잡이"를 계속 조사하면서 더 명확해질 수 있습니다. 마지막으로, 평가 시점이 사용자 경험에 더 가깝기 때문에 생성부터 검색 및 색인까지 하향식 관점에서 메트릭을 제시하기로 결정했습니다. 또한 인덱싱에서 검색 및 생성에 이르는 상향식 관점에서 튜닝 노브를 제시하는 것이 RAG 애플리케이션 개발자의 경험과 더 유사하기 때문입니다.
RAG 조정 매개변수
이제 RAG 시스템 비교를 위한 메트릭에 대해 살펴봤으니 성능에 큰 영향을 미칠 수 있는 주요 의사 결정에 대해 자세히 알아보겠습니다.
인덱스 조정 매개변수
RAG 시스템을 설계할 때 가장 중요한 인덱싱 튜닝 파라미터는 벡터 압축 설정으로, 2023년 3월 Weaviate 1.18에서 연속된 벡터 조각을 그룹화하고 집합의 값을 클러스터링한 후 질량 중심으로 정밀도를 낮추는 벡터 압축 알고리즘인 PQ(Product Quantization)로 도입되었습니다. 예를 들어 32비트 부동 소수점 숫자 4개로 구성된 연속된 조각을 표현하는 데 16바이트가 걸리는 반면, 질량 중심이 8개인 길이 4의 조각은 1바이트만 소요되어 메모리 압축률이 16:1에 달합니다. 최근 PQ 재정렬의 발전으로 압축으로 인한 리콜 손실이 크게 줄었지만, 여전히 매우 높은 수준의 압축에서는 신중하게 고려해야 합니다.
다음은 사용되는 라우팅 인덱스입니다. 벡터가 10K 미만인 데이터 세트의 경우, RAG 애플리케이션은 무차별 대입 인덱싱으로 만족할 수 있습니다. 그러나 벡터 수가 증가하면 무차별 인덱싱의 지연 시간은 HNSW와 같은 근접 그래프 알고리즘에 기반한 인덱싱보다 훨씬 더 길어집니다. RAG 메트릭에 설명된 대로, HNSW 성능은 일반적으로 초당 쿼리와 리콜을 비교하는 파레토 최적점으로 측정됩니다. 이는 추론에 사용되는 검색 대기열의 크기를 조정하여 달성할 수 있습니다. ef 를 통해 실현할 수 있습니다. 더 크게 ef 를 사용하면 검색 프로세스 중에 더 많은 거리 비교를 수행하므로 속도가 상당히 느려지지만 더 정확한 결과를 얻을 수 있습니다. 다음 매개변수에는 인덱스 구성에 사용되는 다음과 같은 것들이 포함됩니다. efConstruction (그래프에 데이터를 삽입할 때 대기열의 크기) 및 maxConnections (각 벡터와 함께 저장할 노드당 에지 수).
우리가 탐구하고 있는 또 다른 새로운 방향은 분포 편향이 PQ의 질량 중심에 미치는 영향과 다음과 같은 하이브리드 클러스터링 및 그래프 인덱싱 알고리즘과의 관계입니다. DiskANN 어쩌면 IVFOADC+G+P) 상호작용을 고려합니다. 회상 메트릭을 사용하면 질량 중심을 재적합해야 하는지 여부를 결정하는 데 충분할 수 있지만, 재적합에 사용할 벡터의 하위 집합이 무엇이냐는 문제가 남아 있습니다. 가장 최근의 10만 개의 벡터를 사용하면 회상률이 떨어지므로 새로운 분포에 과적합할 수 있으므로 여러 데이터 분포 타임라인을 혼합하여 샘플링해야 할 수 있습니다. 이 주제는 딥러닝 모델의 지속적인 최적화에 대한 요점과 밀접한 관련이 있으며, '규제 최적화' 섹션에서 자세히 논의할 수 있습니다.
데이터 청크는 Weaviate에 데이터를 삽입하기 전에 중요한 단계입니다. 청킹은 긴 문서를 작은 부분으로 변환합니다. 이렇게 하면 각 청크에 중요한 정보가 포함되어 검색이 향상되고 대규모 언어 모델(LLM)의 토큰 한도 내에서 유지되는 데 도움이 됩니다. 문서 구문 분석에는 여러 가지 전략이 있습니다. 위 그림은 제목을 기준으로 연구 논문을 청크로 분류하는 예시를 보여줍니다. 예를 들어, 청크 1은 초록, 청크 2는 서론 등으로 구분할 수 있습니다. 청크를 결합하고 겹치는 청크를 만드는 방법도 있습니다. 여기에는 이전 블록에서 토큰을 가져와 다음 블록의 시작으로 사용하는 슬라이딩 창이 포함됩니다. 블록이 약간 겹치면 검색자가 이전 컨텍스트/블록을 이해할 수 있기 때문에 검색이 향상됩니다. 다음 이미지는 청크 텍스트의 개략적인 도식입니다.

검색(데이터)
검색에는 임베딩 모델, 하이브리드 검색 가중치, 자동 컷 사용 여부, 재정렬 모델 등 네 가지 주요 조정 가능한 매개변수가 있습니다.
대부분의 RAG 개발자는 사용 중인 임베딩 모델(예: OpenAI, Cohere, Voyager, Jina AI, Sentence Transformers 및 기타 여러 옵션)을 즉시 조정할 가능성이 높습니다! 또한 개발자는 모델의 차원과 PQ 압축에 미치는 영향도 고려해야 합니다.
다음으로 중요한 결정은 하이브리드 검색에서 희소 및 고밀도 검색 방법에 대한 집계 가중치를 조정하는 방법입니다. 가중치는 매개변수 alpha.alpha 0은 순수 bm25 검색.alpha 를 1로 설정하면 순수 벡터 검색이 됩니다. 따라서 alpha 데이터와 애플리케이션에 따라 다릅니다.
또 다른 새로운 발전은 제로 샘플 재주문 모델의 효율성입니다.Weaviate는 현재 2 Cohere의 재주문 모델::rerank-english-v2.0 노래로 응답 rerank-multilingual-v2.0. 이름에서 알 수 있듯이 이러한 모델은 주로 사용되는 학습 데이터와 그에 따른 다국어 기능으로 인해 다릅니다. 향후에는 모델 기능 측면에서 더 많은 옵션을 제공할 예정이며, 여기에는 일부 애플리케이션에는 적합하지만 다른 애플리케이션에는 적합하지 않을 수 있는 성능과 지연 시간 간의 내재적 절충이 포함됩니다. 검색의 매개변수를 조정하는 과정에서 어떤 종류의 재순서가 필요한지, 얼마나 많은 검색 결과를 재순서해야 하는지를 알아내는 것이 어려웠습니다. 이는 또한 RAG 스택에서 사용자 지정 모델을 미세 조정하는 가장 쉬운 진입점 중 하나이며, 이에 대해서는 "규제 최적화"에서 자세히 설명합니다.
또 다른 흥미로운 튜닝 매개변수는 다중 인덱스 검색입니다. 청킹에 대한 논의와 마찬가지로, 여기에는 데이터베이스의 구조적 변경이 수반됩니다. 전체적인 질문은언제 필터 대신 별도의 컬렉션을 사용해야 하나요? 전송해야 합니다. blogs 노래로 응답 documentation 를 두 개의 세트로 나누거나 source 속성 Document 카테고리에서?

필터를 사용하면 각 블록에 여러 개의 레이블을 추가한 다음 제거하여 분류기가 이를 어떻게 사용하는지 분석할 수 있으므로 이러한 레이블의 유용성을 빠르게 테스트할 수 있습니다. LLM에 입력되는 컨텍스트에 컨텍스트의 출처를 명시적으로 라벨링하는 것과 같은 여러 가지 흥미로운 아이디어가 있습니다(예: "다음은 블로그 {search_results}의 검색 결과입니다. 다음은 {문서}의 검색 결과입니다.". LLM이 더 긴 입력을 처리할 수 있게 되면서 여러 데이터 소스 간의 컨텍스트 융합이 더 일반화될 것으로 예상되므로, 각 인덱스 또는 필터에서 검색되는 문서 수라는 또 다른 관련 하이퍼파라미터가 등장하게 될 것입니다.
생성
생성과 관련하여 가장 먼저 집중해야 할 것은 어떤 대규모 언어 모델(LLM)을 선택할 것인가입니다. 예를 들어 OpenAI, Cohere, Facebook 및 여러 오픈 소스 옵션에서 모델을 선택할 수 있습니다. 많은 LLM 프레임워크(예 LangChain및LlamaIndex 노래로 응답 Weaviate의 생성 모듈)는 다양한 모델과 쉽게 통합할 수 있다는 점이 큰 장점입니다. 어떤 모델을 선택할지는 데이터를 비공개로 유지할지 여부, 비용, 리소스 등의 요인에 따라 달라질 수 있습니다.
일반적인 LLM 관련 조절 매개변수는 온도입니다. 온도 설정은 출력의 무작위성을 제어합니다. 온도가 0이면 응답이 더 예측 가능하고 가변성이 적으며, 온도가 1이면 모델에서 응답에 무작위성과 창의성을 도입할 수 있습니다. 따라서 온도를 1로 설정한 상태에서 생성 모델을 여러 번 실행하면 다시 실행할 때마다 응답이 달라질 수 있습니다.
긴 문맥 모델(LCM)은 애플리케이션을 위한 LLM을 선택할 때 새롭게 떠오르는 방향입니다. 더 많은 검색 결과를 입력으로 추가하면 응답 품질이 향상될까요? 로스트 인 더 미들 실험에 대한 연구는 몇 가지 위험 신호를 제기합니다. In "중간에서 길을 잃다" 이 논문에서 스탠포드, UC 버클리, 사마야 AI의 연구원들은 관련 정보가 검색 결과의 시작이나 끝이 아닌 중간에 배치되면 언어 모델이 응답을 생성할 때 이를 통합하지 못할 수 있음을 보여주는 통제된 실험을 수행했습니다. 구글 딥마인드, 도요타, 퍼듀 대학교의 연구진이 작성한 또 다른 논문에서도 이와 같은 사실을 언급했습니다:"대규모 언어 모델은 관련 없는 컨텍스트에 의해 쉽게 산만해집니다.". 이 방향의 잠재력에도 불구하고, 이 글을 쓰는 현재 긴 컨텍스트 RAG는 아직 초기 단계에 머물러 있습니다. 다행히도 Ragas 점수와 같은 메트릭은 새로운 시스템을 빠르게 테스트하는 데 도움이 될 수 있습니다!
앞서 설명한 LLM 평가의 최근 획기적인 발전과 마찬가지로, 튜닝의 생성 측면은 1. 프롬프트 튜닝, 2. 몇 가지 예제, 3. 미세 튜닝의 세 단계로 나뉩니다. 프롬프트 튜닝에는 "제공된 검색 결과에 따라 질문에 답해 주세요."와 같은 특정 언어 표현을 조정하는 작업이 포함됩니다. "질문에 답해 주세요. 중요: 아래 지침을 자세히 따르세요. 질문에 대한 답변은 제공된 검색 결과에 근거해서만 작성해야 합니다!!!" 차이점입니다.
앞서 언급했듯이 샘플 적은 예시란 언어 모델 생성을 안내하기 위해 수동으로 작성된 여러 개의 질문, 문맥 및 답변 쌍을 수집하는 것을 말합니다. 최근 연구(예 "컨텍스트 벡터")는 이러한 방식으로 잠재적 공간을 부트스트랩하는 것이 얼마나 중요한지 잘 보여줍니다. Weaviate Gorilla 프로젝트에서는 GPT-3.5-turbo를 사용하여 Weaviate 쿼리를 생성했으며, 적은 샘플 예제의 쿼리 번역에 자연어를 추가했을 때 성능이 크게 향상되었습니다.
마지막으로 RAG 애플리케이션을 위한 LLM 미세 조정에 대한 관심이 높아지고 있습니다. 다음은 몇 가지 고려해야 할 접근 방식입니다. LLM 평가에 대한 논의로 다시 돌아가서, 더 강력한 LLM을 사용하여 학습 데이터를 생성하여 자체적으로 더 작고 저렴한 모델을 구축할 수 있습니다. 또 다른 아이디어는 응답 품질에 대한 사람의 주석을 제공하여 명령어 추종으로 LLM을 미세 조정할 수 있도록 하는 것입니다. 모델 미세 조정에 관심이 있다면 다음에서 HuggingFace PEFT 라이브러리를 사용하는 방법에 대한 Brev의 기고문을 확인하세요. 튜토리얼.
RAG 튜닝 옵션 요약
지금까지 RAG 시스템에서 사용할 수 있는 주요 튜닝 옵션에 대해 설명했습니다:
- 인덱싱: 가장 높은 수준에서 무차별 대입 검색만 사용할 때와 ANN 인덱싱을 도입할 때를 고려해야 합니다. 이는 특히 신규 사용자와 강력한 사용자로 구성된 멀티테넌트 사용 사례를 조정할 때 유용합니다. ANN 인덱싱에는 PQ(조각화, 질량 중심 및 훈련 한계)에 대한 하이퍼파라미터가 있습니다. hNSW에는 (ef, efConstruction 및 maxConnections)가 포함됩니다.
- 검색: 임베딩 모델 선택, 하이브리드 검색 가중치 조정, 재정렬자 선택, 컬렉션을 여러 인덱스로 분할하기.
- 생성: LLM을 선택하고 큐 튜닝에서 샘플이 적은 예제 또는 미세 튜닝으로 전환할 시기를 결정합니다.
RAG 지표와 튜닝을 통해 성능을 개선하는 방법을 이해했으니 이제 실험적 추적의 가능한 구현에 대해 논의해 보겠습니다.
스케줄링
최근 대규모 언어 모델(LLM) 평가 분야의 발전과 일부 조정 가능한 파라미터에 대한 개요를 고려할 때, 이 모든 것을 실험 추적 프레임워크와 결합할 수 있는 흥미로운 기회가 있습니다. 예를 들어, 사용자는 직관적인 API를 갖춘 간단한 오케스트레이터를 사용해 1. 5개 LLM, 2개 임베디드 모델, 5개 인덱싱 구성에 대한 전체 테스트 요청, 2. 실험 실행, 3. 사용자에게 고품질 보고서 반환 등의 작업을 수행할 수 있습니다.Weights & Biases는 딥러닝 모델 훈련을 위한 놀라운 실험 추적 경로를 개척해왔습니다. 이 백서에서 설명한 조정 가능한 매개변수와 메트릭을 통한 RAG 실험 지원에 대한 관심이 빠르게 증가할 것으로 예상됩니다.
저희는 이 분야에서 두 가지 개발 방향을 따르고 있습니다. 한편으로는 기존의 제로 샘플 LLM(예: GPT-4, Command, Claude, 오픈 소스 옵션인 Llama-2 및 Mistral)은 그다지 효과적이지 않습니다. 오라클 컨텍스트 당시에는 꽤 좋은 성과를 거두었습니다. 따라서 다음과 같은 큰 기회가 있습니다. 검색 부분에 집중 . 이를 위해서는 이 백서의 앞부분에서 설명한 대로 여러 구성에서 ANN 오류, 임베디드 모델, 하이브리드 검색 가중치, PQ 또는 HNSW의 재순서를 절충하는 방법을 찾아야 합니다.
Weaviate 1.22에는 비동기 인덱스와 해당 노드 상태 API가 도입되며, RAG 평가 및 튜닝 오케스트레이션에 중점을 둔 파트너십을 통해 인덱스 구축이 완료된 시점을 결정하고 테스트를 실행하는 데 활용할 수 있기를 기대합니다. 이는 특히 이러한 노드 상태를 기반으로 각 테넌트와의 오케스트레이션 인터페이스 튜닝을 고려할 때, 일부 테넌트는 무차별 검색에 의존하는 반면 다른 테넌트는 데이터에 적합한 임베딩 모델과 HNSW 구성을 찾아야 하는 경우 매우 흥미롭습니다.
또한 리소스 할당을 병렬화하여 테스트 속도를 높이고 싶을 수도 있습니다. 예를 들어 4개의 임베딩 모델을 동시에 평가하는 것입니다. 앞서 언급했듯이 또 다른 흥미로운 부분은 데이터 임포터에서 가져올 수 있는 청크 또는 기타 기호 메타데이터를 조정하는 것입니다. 예를 들어, Weaviate Verba 데이터 세트에는 3개의 폴더로 구성된 Weaviate의 Blogs및Documentation 노래로 응답 Video 전사. 100과 300의 청크 크기를 비교하려는 경우 웹 크롤러를 다시 호출할 필요가 없습니다. S3 스토리지 버킷에 저장된 데이터나 관련 메타데이터와 함께 다른 형식이 필요할 수도 있지만, 더 경제적으로 실험할 수 있는 방법을 제공합니다.
반면에 데이터 삽입이나 업데이트보다는 모델 미세 조정과 그라데이션 기반 연속 학습을 사용합니다. RAG에서 가장 많이 사용되는 모델은 임베디드 모델, 재주문 모델, 그리고 LLM입니다. 머신러닝 모델을 새로운 데이터로 최신 상태로 유지하는 것은 새로운 모델의 재학습, 테스트, 배포를 관리하는 지속적 학습 프레임워크와 MLops 오케스트레이션의 오랜 관심사였습니다. 지속적 학습 LLM의 경우, RAG 시스템의 가장 큰 장점 중 하나는 LLM 지식 베이스의 '마감' 날짜를 연장하여 데이터와 동기화 상태를 유지할 수 있다는 점입니다. LLM이 직접 이 작업을 수행할 수 있나요? RAG를 통해 정보를 최신 상태로 유지하는 것만으로는 지속적인 교육과 얼마나 잘 상호작용하는지는 명확하지 않습니다. 일부 연구(예: MEMIT)에서는 "르브론 제임스는 농구를 한다"와 같은 사실을 "르브론 제임스는 축구를 한다"로 업데이트하여 가중치 귀속의 인과적 매개 분석을 실험한 바 있습니다. "와 같은 식으로요. 이는 상당히 고급 기술이며, 훈련에 사용된 청크에 단순히 라벨을 붙이고(예: "르브론 제임스는 농구를 한다") 새로운 정보가 포함된 검색 강화 훈련 데이터를 사용하여 다시 훈련하는 방법도 있습니다. 이 부분은 저희가 면밀히 주시하고 있는 중요한 영역입니다.
앞서 언급했듯이, 이러한 유형의 지속적인 튜닝을 PQ 프라임 센터를 사용하여 Weaviate에 직접 통합하는 방법도 고려하고 있습니다. Weaviate에 처음 입력되는 첫 번째 K 벡터의 PQ 중심은 데이터 분포의 중대한 변화에 영향을 받을 수 있습니다. 머신 러닝 모델의 지속적인 학습은 최신 데이터 배치에 대한 학습이 이전 배치의 성능을 저하시키는 악명 높은 '치명적 망각' 문제를 겪습니다. 이는 PQ 질량 중심 리핏을 설계할 때 고려한 사항 중 하나입니다.
RAG에서 에이전트 평가까지
이 글에서는 다음과 같은 사항에 중점을 둡니다. RAG 대신 에이전트 평가. 저희의 의견입니다.RAG 인덱싱, 검색 및 생성 프로세스로 정의되고 상담원 시스템의 범위는 더 개방적입니다. 아래 다이어그램은 계획, 메모리 및 도구와 같은 주요 구성 요소가 시스템에 중요한 기능을 제공하지만 평가하기는 더 어렵게 만드는 방식을 보여줍니다.
 RAG 애플리케이션의 일반적인 다음 단계는 고급 쿼리 엔진을 추가하는 것입니다. 이 개념을 처음 접하는 독자는 시작하는 방법에 대한 Python 코드 예제를 제공하는 LlamaIndex 및 Weaviate 시리즈를 참조하세요. 하위 질문 쿼리 엔진, SQL 라우터, 자체 수정 쿼리 엔진 등 다양한 고급 쿼리 엔진이 있습니다. 또한 Weaviate 모듈에서 promptToQuery API 또는 검색 쿼리 추출기의 가능한 형태도 고려하고 있습니다. 각 쿼리 엔진은 정보 검색 프로세스에서 고유한 장점을 가지고 있으므로 몇 가지 쿼리 엔진과 이를 평가하는 방법에 대해 자세히 알아보겠습니다.
RAG 애플리케이션의 일반적인 다음 단계는 고급 쿼리 엔진을 추가하는 것입니다. 이 개념을 처음 접하는 독자는 시작하는 방법에 대한 Python 코드 예제를 제공하는 LlamaIndex 및 Weaviate 시리즈를 참조하세요. 하위 질문 쿼리 엔진, SQL 라우터, 자체 수정 쿼리 엔진 등 다양한 고급 쿼리 엔진이 있습니다. 또한 Weaviate 모듈에서 promptToQuery API 또는 검색 쿼리 추출기의 가능한 형태도 고려하고 있습니다. 각 쿼리 엔진은 정보 검색 프로세스에서 고유한 장점을 가지고 있으므로 몇 가지 쿼리 엔진과 이를 평가하는 방법에 대해 자세히 알아보겠습니다.
 멀티홉 쿼리 엔진(하위 이슈 쿼리 엔진)는 복잡한 문제를 하위 문제로 분해하는 데 적합합니다. 위 다이어그램에는 "Weaviate에서 Ref2Vec은 무엇인가요?"라는 쿼리가 있습니다. 이 질문에 답하려면 Ref2Vec과 Weaviate가 각각 무엇인지 알아야 합니다. 이 질문에 답하려면 Ref2Vec과 Weaviate가 각각 무엇인지 알아야 합니다. 따라서 두 질문에 대해 데이터베이스를 두 번 호출하여 관련 컨텍스트를 검색해야 합니다. 그런 다음 두 개의 답변이 결합되어 단일 출력이 생성됩니다. 멀티홉 쿼리 엔진의 성능 평가는 하위 질문을 살펴봄으로써 수행할 수 있습니다. LLM이 관련성 있는 하위 질문을 생성하고, 각 질문에 정확하게 답변하며, 두 답변을 결합하여 사실에 근거한 정확하고 관련성 있는 출력을 제공하는 것이 중요합니다. 또한 복잡한 질문을 하는 경우에는 멀티홉 쿼리 엔진을 사용하는 것이 가장 좋습니다.
멀티홉 쿼리 엔진(하위 이슈 쿼리 엔진)는 복잡한 문제를 하위 문제로 분해하는 데 적합합니다. 위 다이어그램에는 "Weaviate에서 Ref2Vec은 무엇인가요?"라는 쿼리가 있습니다. 이 질문에 답하려면 Ref2Vec과 Weaviate가 각각 무엇인지 알아야 합니다. 이 질문에 답하려면 Ref2Vec과 Weaviate가 각각 무엇인지 알아야 합니다. 따라서 두 질문에 대해 데이터베이스를 두 번 호출하여 관련 컨텍스트를 검색해야 합니다. 그런 다음 두 개의 답변이 결합되어 단일 출력이 생성됩니다. 멀티홉 쿼리 엔진의 성능 평가는 하위 질문을 살펴봄으로써 수행할 수 있습니다. LLM이 관련성 있는 하위 질문을 생성하고, 각 질문에 정확하게 답변하며, 두 답변을 결합하여 사실에 근거한 정확하고 관련성 있는 출력을 제공하는 것이 중요합니다. 또한 복잡한 질문을 하는 경우에는 멀티홉 쿼리 엔진을 사용하는 것이 가장 좋습니다.
멀티홉 문제는 무엇보다도 하위 질문의 정확성에 달려 있습니다. 여기에서도 유사한 LLM 평가를 사용할 수 있습니다. "주어진 질문: {쿼리}. 시스템은 이 질문을 하위 질문 {sub_question_1}과 {sub_question_2}로 나누기로 결정했습니다. 이 질문의 분해가 합리적입니까?" 그런 다음 각 하위 질문에 대해 두 개의 개별 RAG 평가를 수행하고 LLM이 각 질문에 대한 답변을 결합하여 원래 질문에 답할 수 있는지 평가합니다.
RAG에서 에이전트로 복잡성이 진화하는 또 다른 예로 쿼리 엔진 라우팅을 고려해 보겠습니다. 아래 그림은 에이전트가 쿼리를 SQL 또는 벡터 데이터베이스 쿼리로 라우팅하는 방법을 보여줍니다. 이 시나리오는 다중 인덱스 라우팅에 대한 논의와 매우 유사하며, 생성된 결과를 평가하는 데 유사한 접근 방식을 사용하여 SQL 및 벡터 데이터베이스를 명시한 다음 LLM 라우터가 올바른 결정을 내렸는지 물어볼 수 있습니다. 또한 SQL 쿼리 결과에 대해 RAGAS 컨텍스트 관련성 점수를 사용할 수도 있습니다.
 "RAG에서 에이전트 평가로"의 논의를 요약하자면, 현재로서는 에이전트 사용의 일반적인 패턴이 무엇인지 파악하는 것이 불가능하다고 생각합니다. 의도적으로 멀티홉 쿼리 엔진과 쿼리 라우터를 보여드린 이유는 비교적 이해하기 쉽기 때문입니다. 계획 루프, 도구 사용, 도구 API 요청 형식을 지정하는 모델의 능력을 평가하는 방법, MemGPT와 같은 메타 내부 메모리 관리 힌트와 관련된 개방형 평가를 더 추가하면 에이전트 평가 방법에 대한 일반적인 추상화를 제공하기가 어려워질 것입니다.
"RAG에서 에이전트 평가로"의 논의를 요약하자면, 현재로서는 에이전트 사용의 일반적인 패턴이 무엇인지 파악하는 것이 불가능하다고 생각합니다. 의도적으로 멀티홉 쿼리 엔진과 쿼리 라우터를 보여드린 이유는 비교적 이해하기 쉽기 때문입니다. 계획 루프, 도구 사용, 도구 API 요청 형식을 지정하는 모델의 능력을 평가하는 방법, MemGPT와 같은 메타 내부 메모리 관리 힌트와 관련된 개방형 평가를 더 추가하면 에이전트 평가 방법에 대한 일반적인 추상화를 제공하기가 어려워질 것입니다.
평결에 도달하기
RAG 평가에 대한 개요를 읽어주셔서 대단히 감사합니다! 간단히 요약하자면, 먼저 반복적인 RAG 시스템에서 상당한 비용과 시간을 절약할 수 있는 LLM을 평가에 사용하는 새로운 트렌드를 소개했습니다. 다음으로 생성부터 검색, 인덱싱에 이르기까지 RAG 스택을 평가하는 데 사용되는 기존 메트릭에 대한 자세한 배경 지식을 소개했습니다. 그리고 이러한 메트릭의 성능을 개선하고자 하는 빌더를 위해 색인, 검색, 생성을 위한 몇 가지 조정 가능한 매개변수를 보여드립니다. 또한 이러한 시스템을 실험적으로 추적할 때의 어려움을 제시하고 RAG 평가와 에이전트 평가의 차이점에 대한 저희의 견해를 설명합니다. 이 백서가 도움이 되셨기를 바랍니다!
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...