Unlimited-OCR - 百度开源的端到端长文档 OCR 模型

Unlimited-OCR是什么
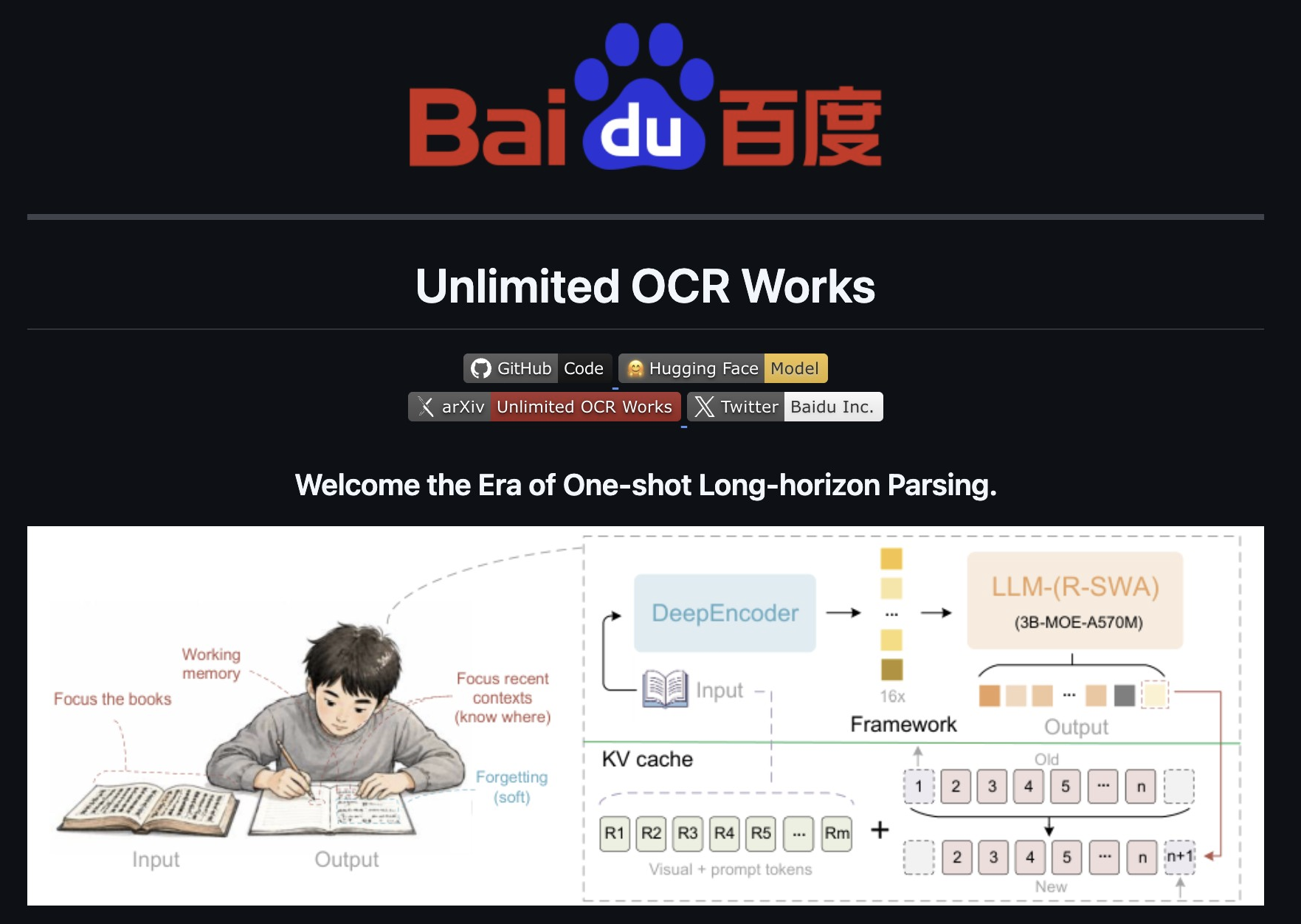
Unlimited-OCR 是百度开源的端到端长文档 OCR 模型,采用 3B 参数 MoE 架构(每 トークン 仅激活约 500M 参数),核心创新在于将标准注意力替换为 R-SWA(参考滑动窗口注意力)——让生成 token 始终全量关注视觉参考 token,同时只对最近 128 个输出 token 进行滑动窗口计算,从而将 KV 缓存控制在恒定大小,彻底解决了长文档解析中的内存爆炸与速度衰减问题。在 OmniDocBench v1.5 上达到 93% 的准确率,较 DeepSeek-OCR 基线提升 6%,支持 20 页以上文档一次性解析且推理速度稳定。
Unlimited-OCR的功能特色
- 端到端长文档解析:支持多页 PDF 一次性输入并输出完整格式化文本,无需手动分页拼接后处理
- R-SWA 注意力机制:将标准全注意力替换为参考滑动窗口注意力,生成 token 始终全量关注视觉参考 token,同时仅滑动关注最近 128 个输出 token
- 恒定 KV 缓存:解码过程中 KV 缓存大小保持不变,彻底避免长文档处理时的内存爆炸和生成速度衰减
- 3B MoE 轻量架构:总参数 3B,每 token 仅激活约 500M 参数,兼顾性能与推理效率
- 効率的なビジュアル・コーディング:采用 SAM-ViT + CLIP-ViT 级联的 DeepEncoder,支持 16× token 压缩,单页 1024×1024 图像可压缩至约 256 个视觉 token
- 双模式推理部署:支持 Transformers 本地推理(单图/多页),以及 SGLang 远程服务提供 OpenAI-compatible API
- 高准确率输出:OmniDocBench v1.5 准确率达 93%,较 DeepSeek-OCR 基线提升 6%
- 长文档连贯性保持:20 页以上文档编辑距离低于 0.11,能准确保留章节结构、表格续页与跨页引用关系
- 稳定推理速度:输出长度增加时 TPS 保持稳定(约 7,800+),不因文档变长而显著下降
- 开源可商用:基于 MIT 协议发布,模型权重和代码均已在 Hugging Face 与 GitHub 公开
Unlimited-OCR的核心优势
- 恒定 KV 缓存,突破长文档瓶颈:R-SWA 机制将 KV 缓存控制在固定大小,无论文档多少页,内存占用和计算复杂度均保持常数级别,彻底告别传统 OCR 随输出长度线性增长的内存爆炸与速度衰减问题
- 端到端整书级解析:无需分页、分块、拼接等后处理,可直接一次性处理 20 页乃至 40 页以上的完整文档,保持章节结构、表格续页和跨页引用的连贯性
- 轻量高效,推理成本低:3B 总参数 MoE 架构,每 token 仅激活约 500M 参数,配合 16× 视觉 token 压缩,在消费级 GPU 上即可高效运行
- 准确率领先:OmniDocBench v1.5 达 93%,较 DeepSeek-OCR 基线提升 6%,长文档编辑距离和文本重复率指标均表现优异
- 推理速度不随长度衰减:输出 token 增加时 TPS 稳定维持在 7,800+,远优于传统全注意力模型随长度增加而显著下降的表现
- 双模式灵活部署:既支持 Transformers 本地离线推理,也支持通过 SGLang 提供 OpenAI-compatible API 远程服务,适配不同业务场景
Unlimited-OCR官网是什么
- GitHubリポジトリ:https://github.com/baidu/Unlimited-OCR
- HuggingFaceモデルライブラリ:https://github.com/baidu/Unlimited-OCR
Unlimited-OCR的操作步骤
- 環境準備:确保本地或服务器配备 NVIDIA GPU(当前实现硬编码 CUDA 调用,CPU/MPS 支持需等待上游更新),安装 Python 3.8+ 及 CUDA 环境
- 获取模型与代码:从 Hugging Face 下载
baidu/Unlimited-OCR模型权重,从 GitHub 克隆baidu/Unlimited-OCR官方仓库到本地 - 依存関係のインストール:进入项目目录,根据 requirements 安装 Transformers、Torch、SGLang 等必要依赖包
- 本地单图推理(Transformers):加载模型并选择
gundamもしかしたらbase配置,将单张图片输入模型,获取格式化 OCR 文本输出 - 本地多页 PDF 推理使用
infer_multi接口,将多页 PDF 一次性输入,模型自动处理整份文档并输出连贯的格式化结果 - 部署远程 API 服务(SGLang):通过 SGLang 启动 Unlimited-OCR 服务,暴露 OpenAI-compatible API 端点,供多客户端远程调用
- API 调用识别:向服务端点发送图像或 PDF 文件,接收返回的结构化 OCR 文本,可集成到自有业务系统或文档处理流水线中
Unlimited-OCR的适用人群
- 文档数字化团队:需要将大量多页扫描件、PDF 档案批量转换为可编辑结构化文本的企事业单位
- AIアプリケーション開発者:正在构建 RAG、知识库、智能文档问答等系统,需要高准确率长文档 OCR 作为前置解析模块的开发者
- 学术与科研人员:需要一次性解析长篇论文、技术手册、实验报告,并保持公式、表格、章节结构连贯性的研究者
- 法律与金融行业从业者:处理合同 bundle、诉讼卷宗、审计报告等超长文档,追求整份文档统一格式化解析的法律及金融团队
- 出版与内容运营团队:从事书籍、期刊、教材等长文档电子化排版与内容提取的出版机构
- 替代传统 OCR 流水线的技术团队:希望用单一端到端模型取代"分页识别+后处理拼接"复杂架构,降低系统维护成本的工程团队
Unlimited-OCR的常见问题
Q:它的核心创新 R-SWA 是什么?
A:R-SWA(Reference Sliding Window Attention) 是一种注意力机制:每个生成 token 始终全量关注所有视觉参考 token,同时仅对最近 128 个输出 token 进行滑动窗口计算。这相当于人类抄写时的"工作记忆"模式——始终看着原稿(参考 token),但只记住刚写的几句话(滑动窗口)。
Q:相比传统 OCR 解决了什么问题?
A:传统端到端 OCR 的 KV 缓存随输出长度线性增长,导致处理长文档时内存爆炸、生成速度越来越慢。R-SWA 将 KV 缓存控制在恒定大小,无论文档多长,内存占用和推理速度都保持稳定。
Q:需要什么硬件配置?
A:当前实现硬编码 CUDA 调用,需要 NVIDIA GPU 支持。CPU 和 Apple MPS 支持需等待上游更新。3B MoE 架构每 token 仅激活约 500M 参数,对显存要求相对友好。
Q:最大支持多长的文档?
A:标准最大输出上下文为 32,768 tokens。超出后仍需分块处理。在 32K 范围内,20 页乃至 40 页以上文档均可一次性解析。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません