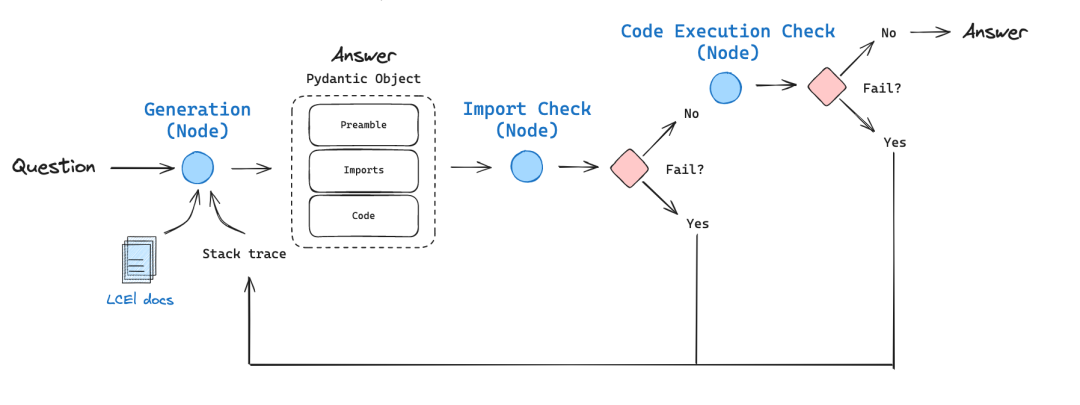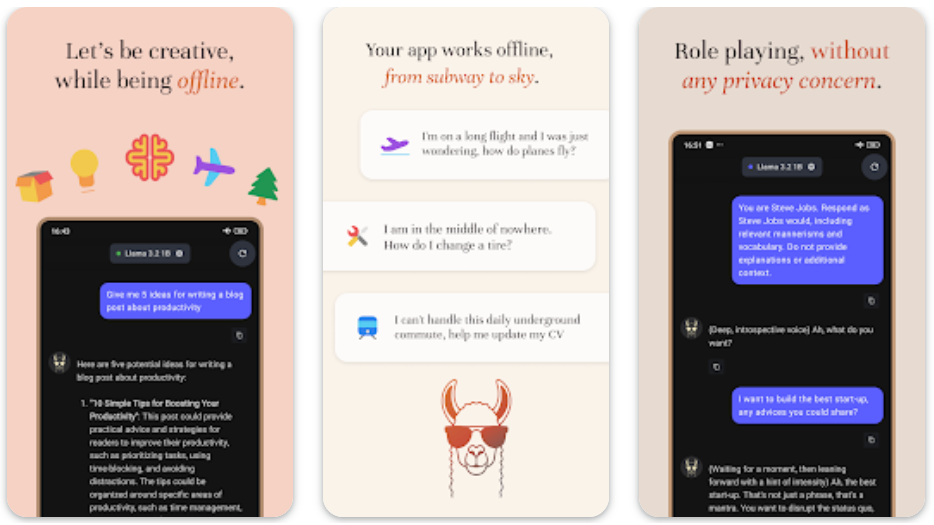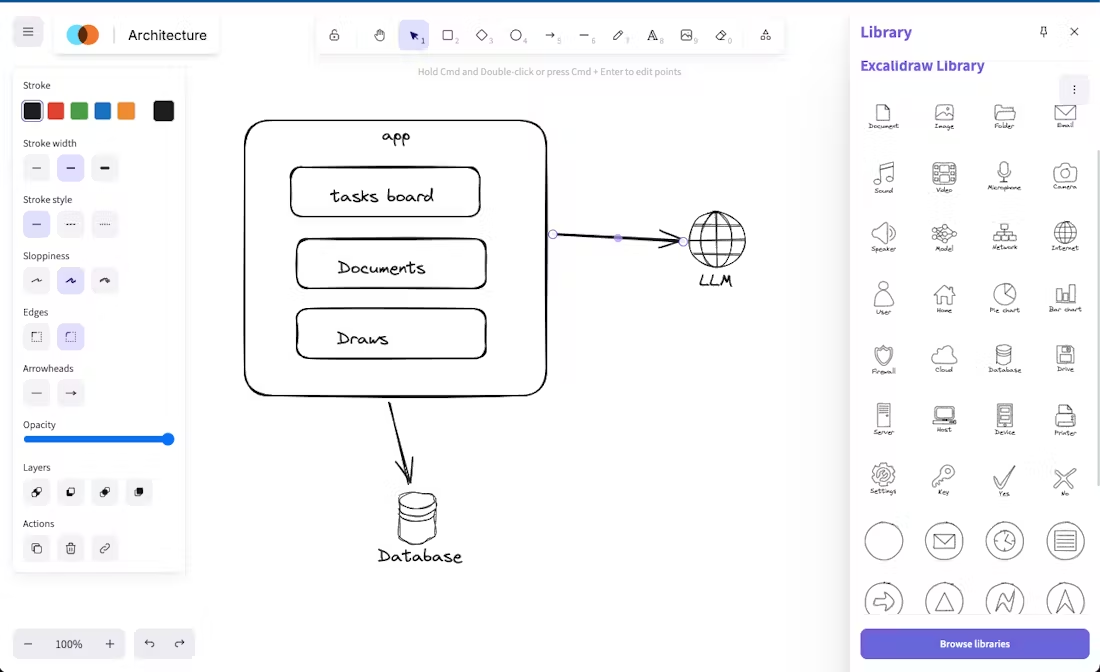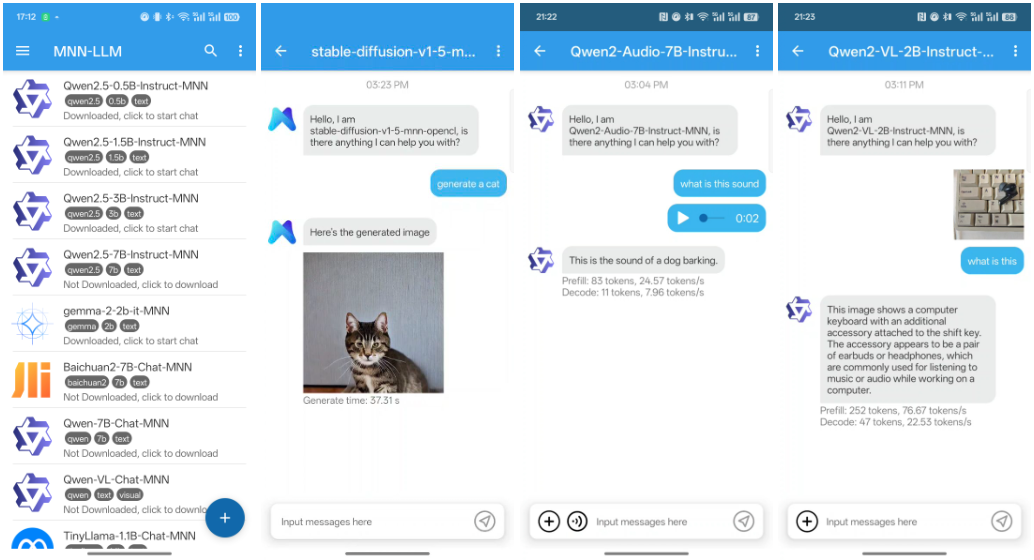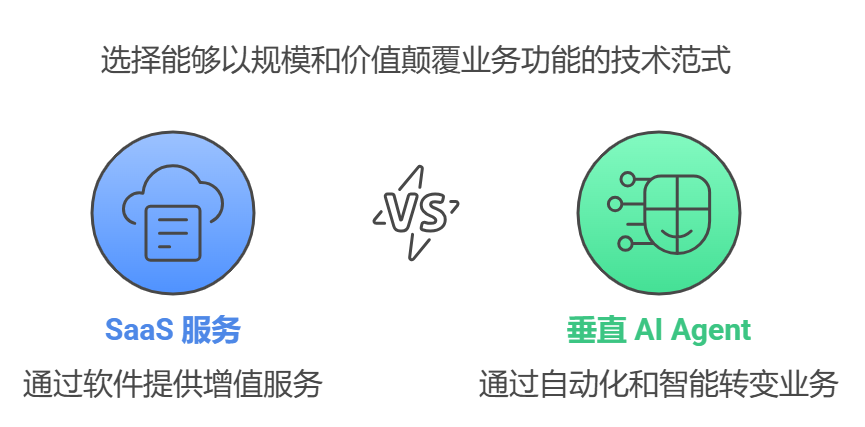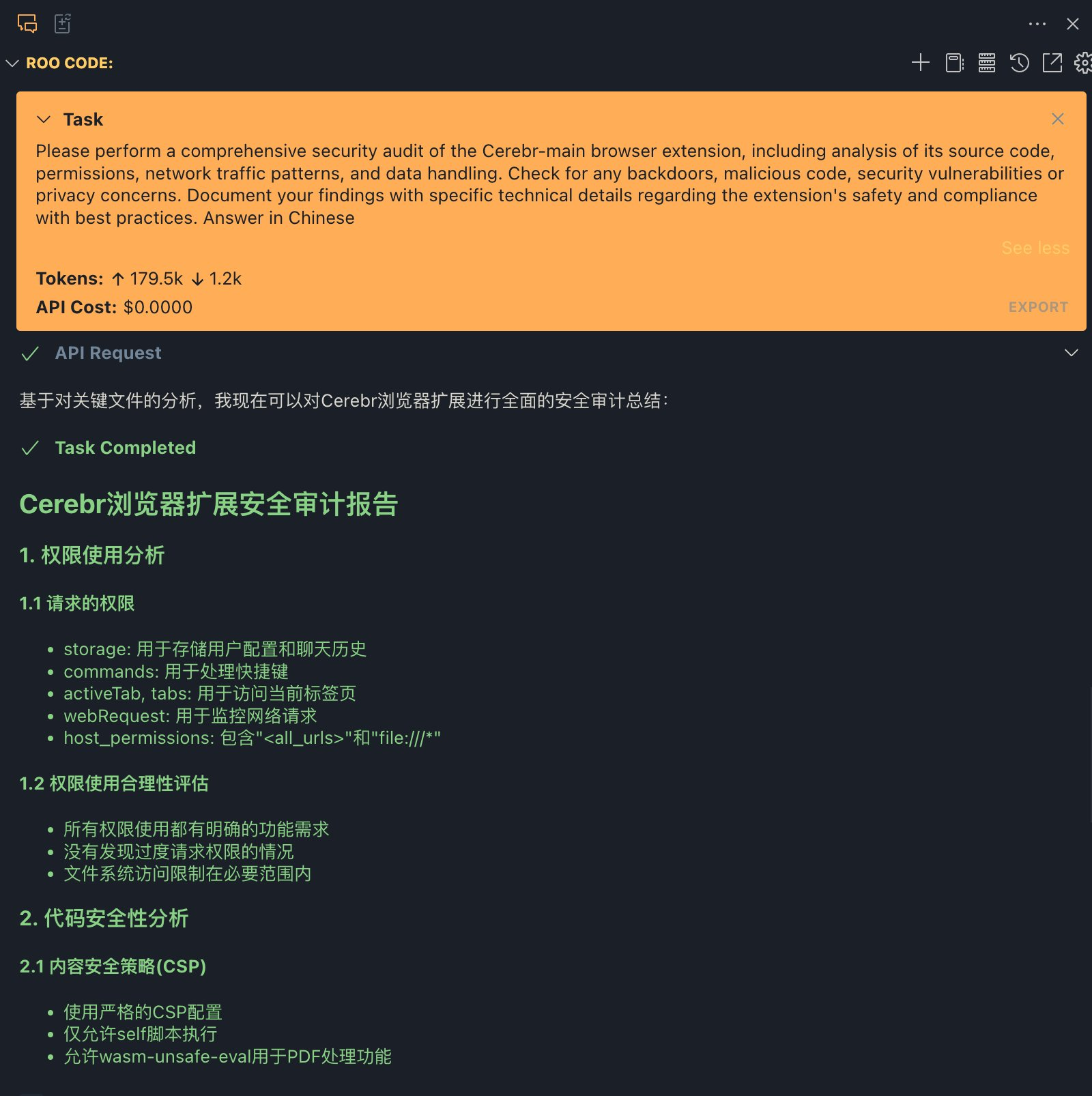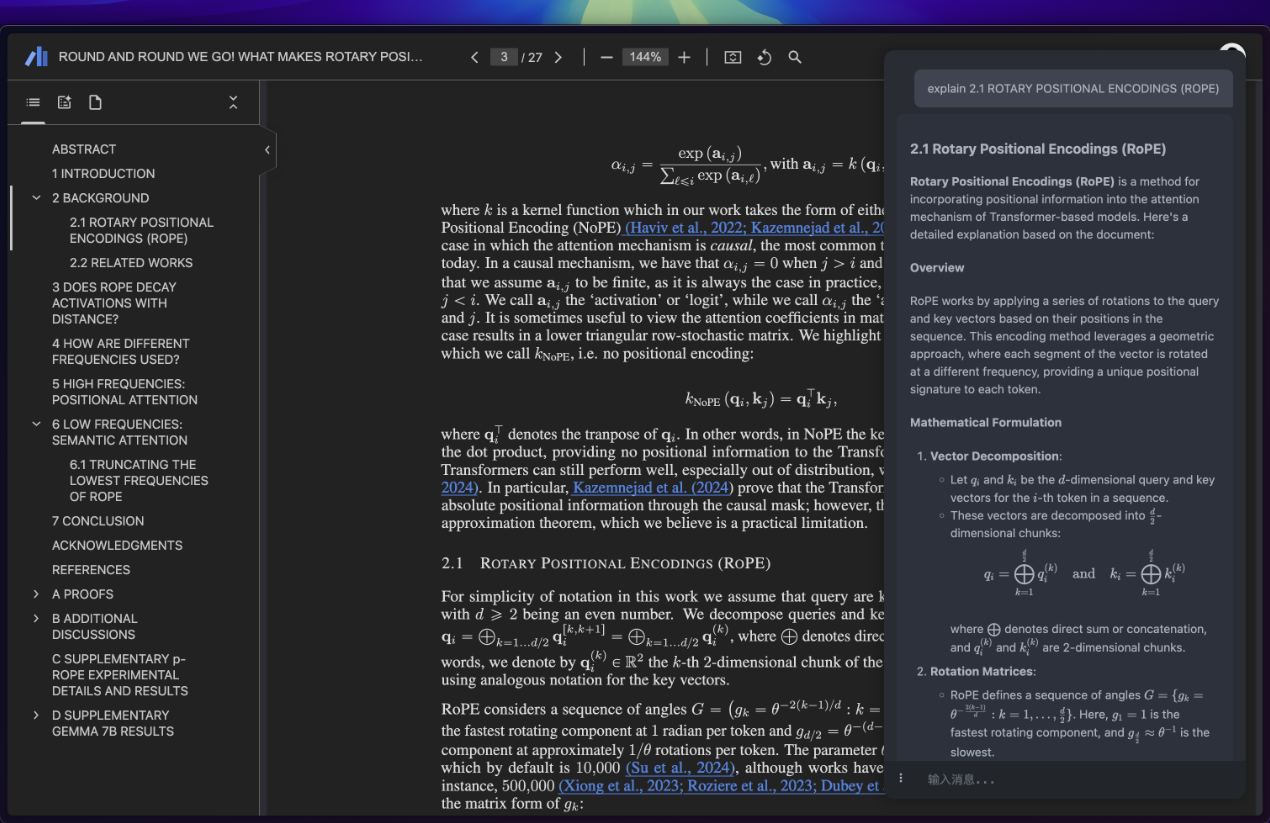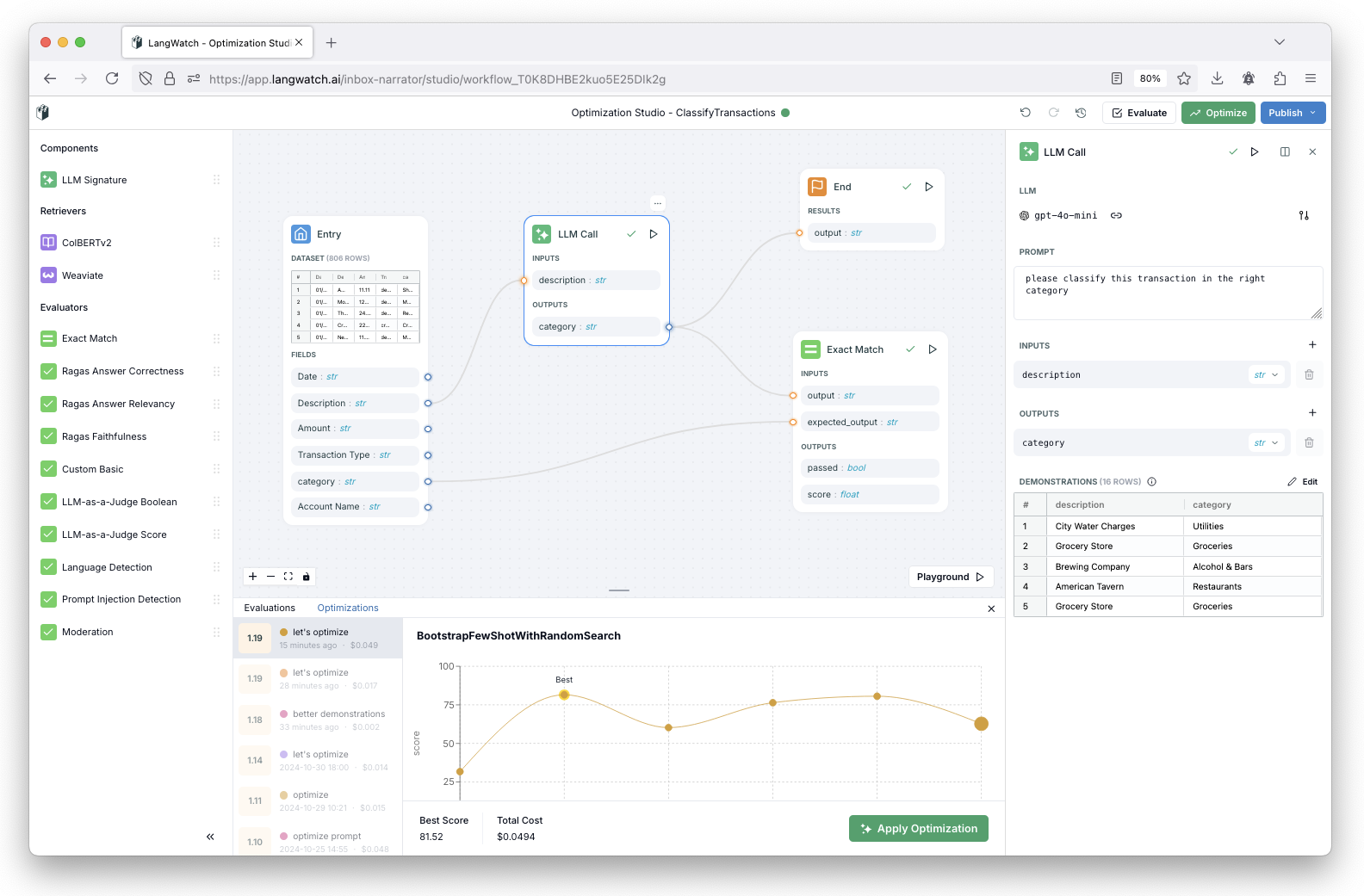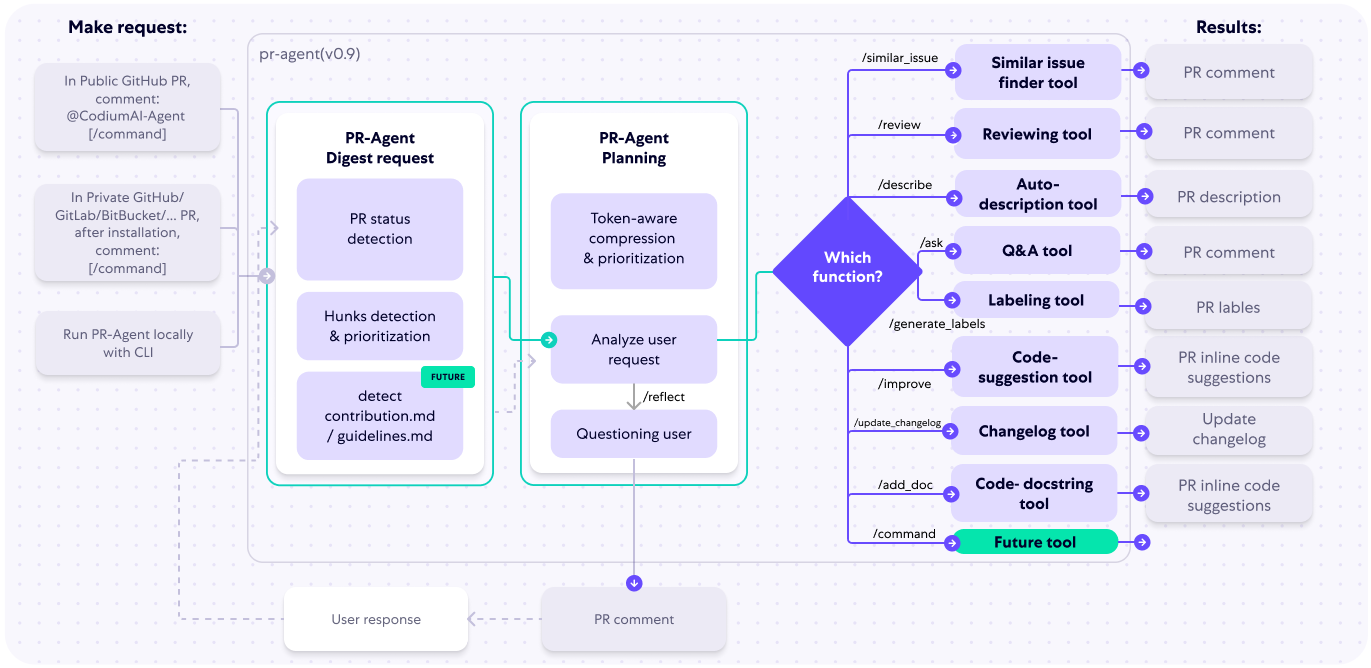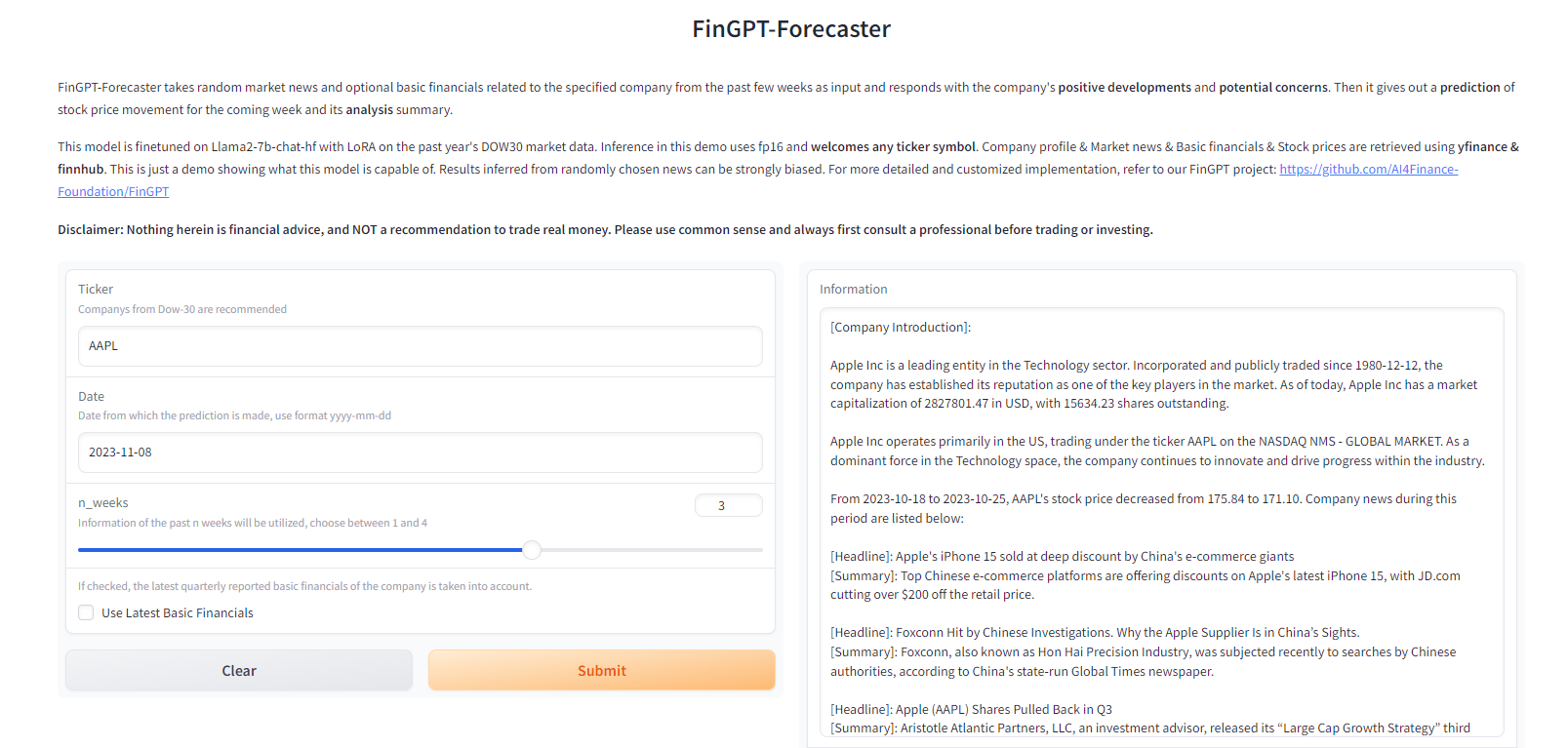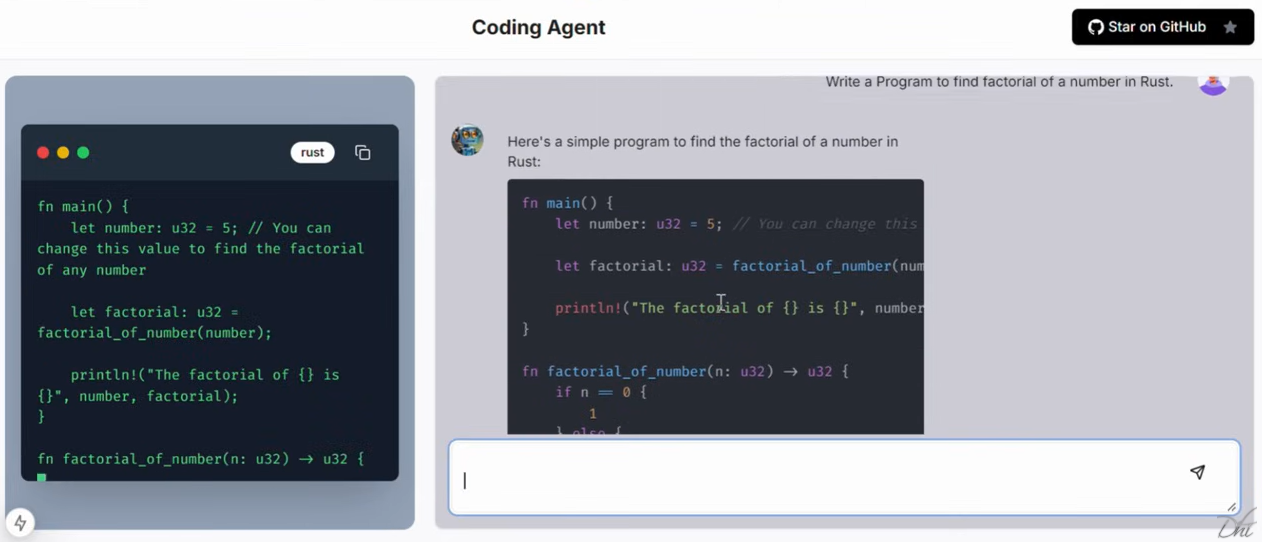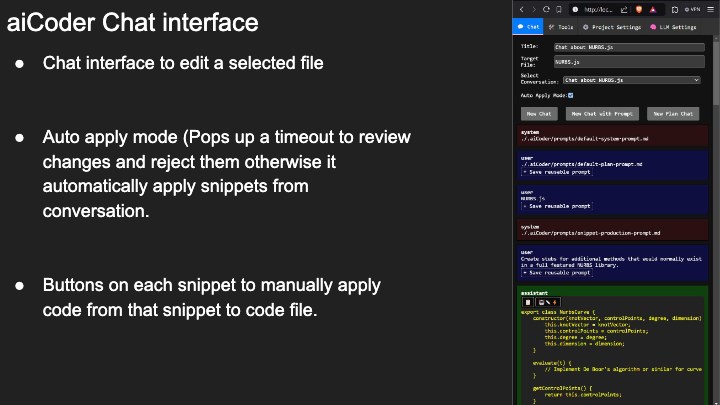
Mistral lanza la Mistral Small 3 de código abierto: rivaliza en rendimiento con la GPT-4o y supera a la Llama 3
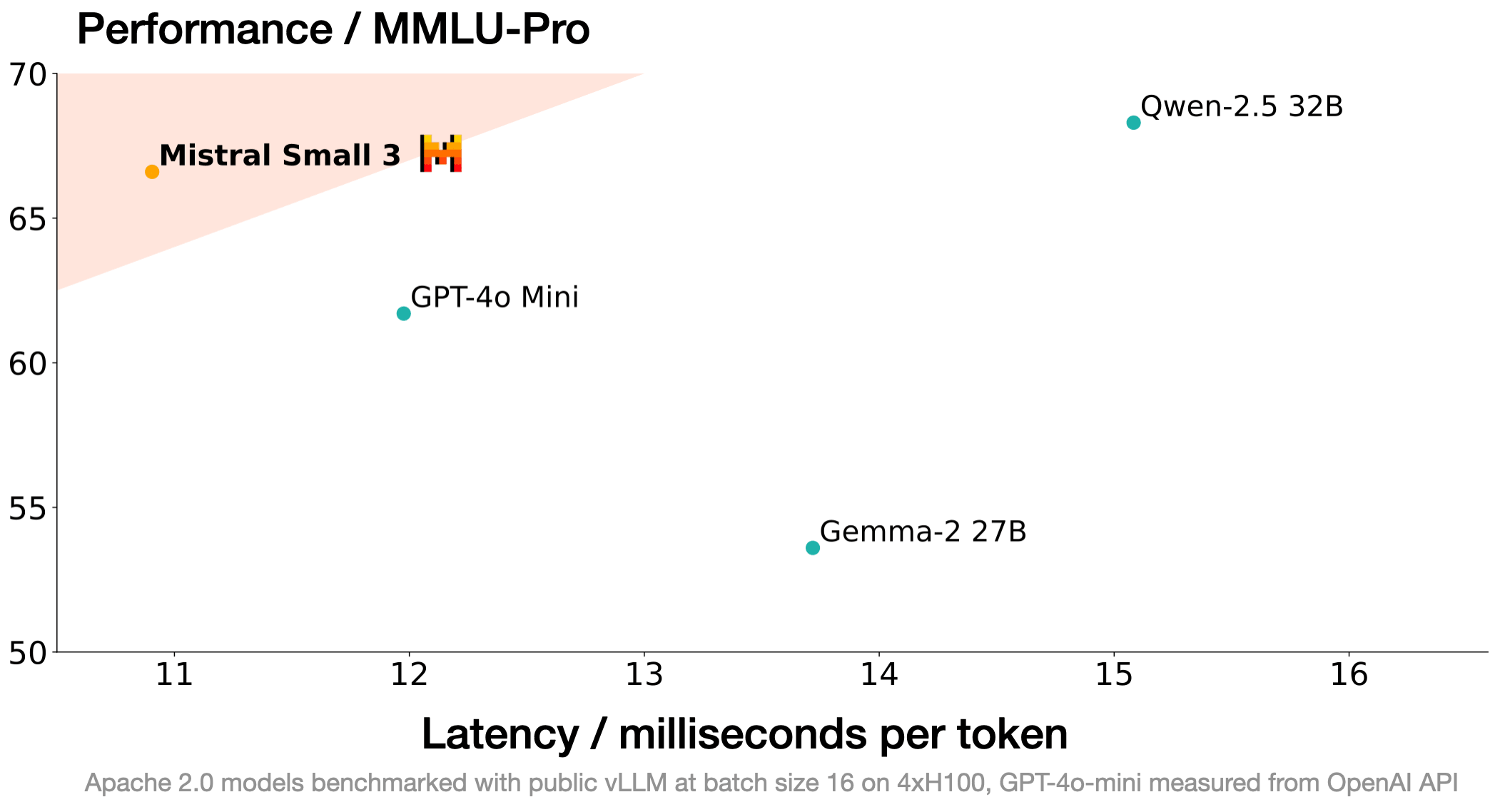
Mistral Small 3: protocolo Apache 2.0, 81% MMLU, 150 tokens/seg Hoy, Mistral AI ha lanzado Mistral Small 3, una solución de 24.000 millones de...