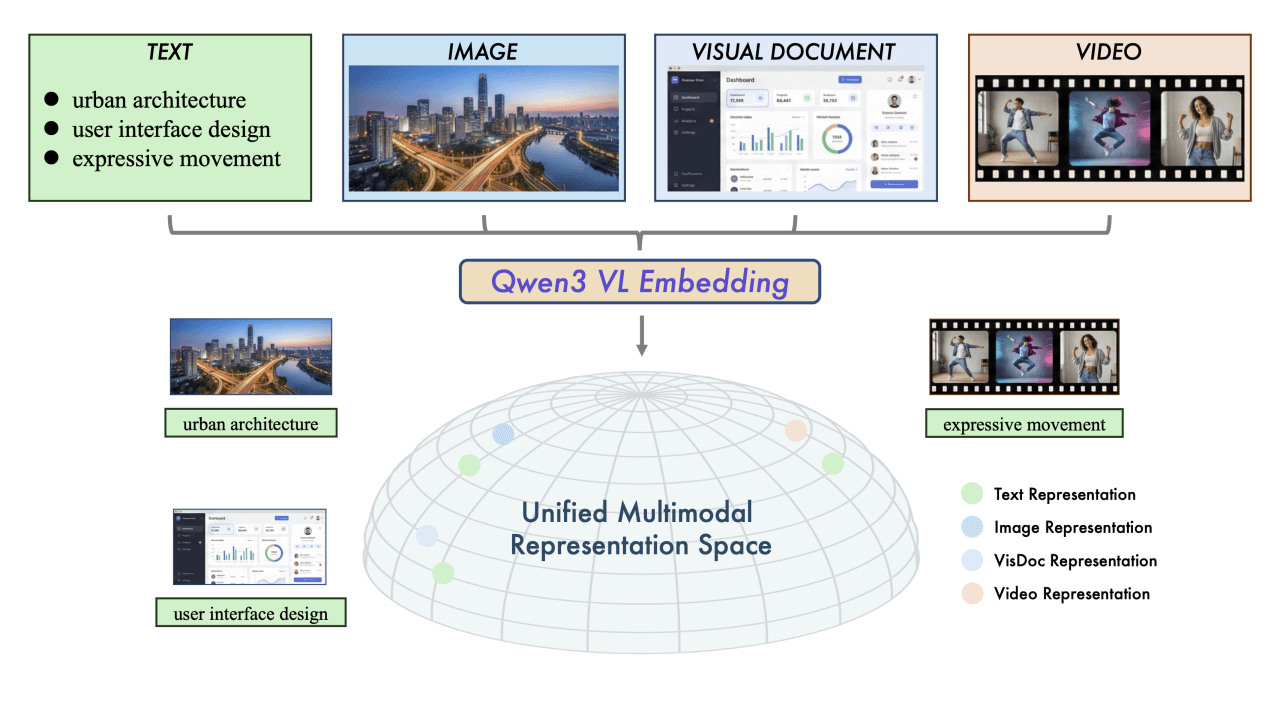
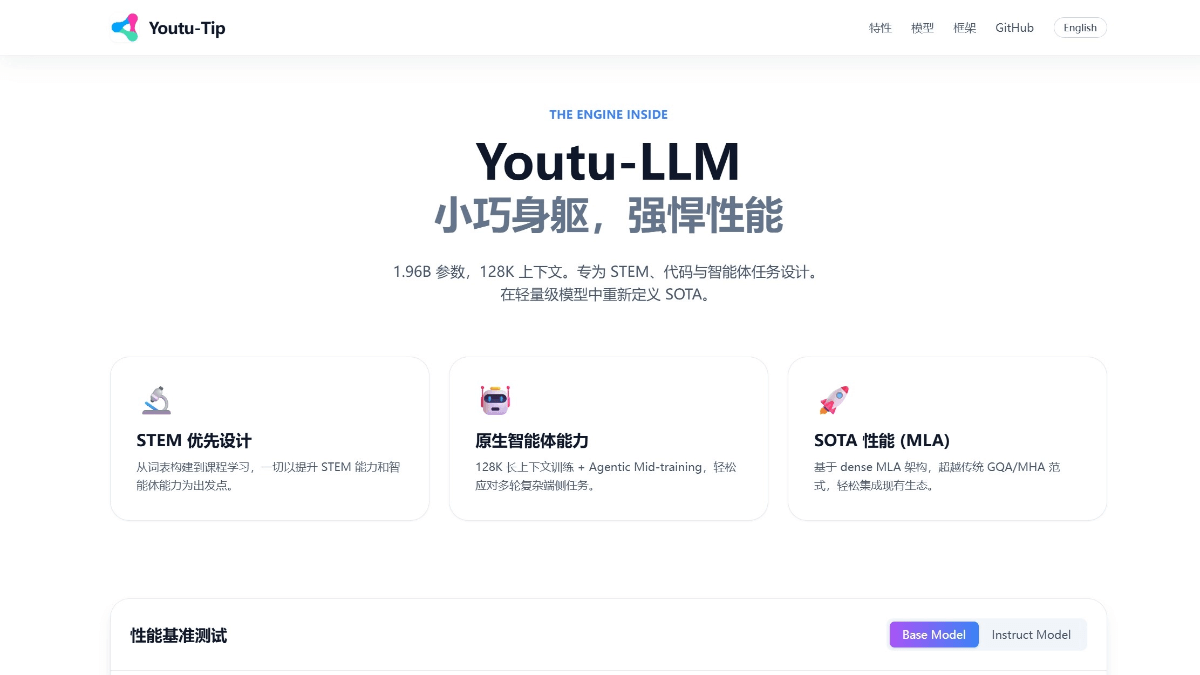
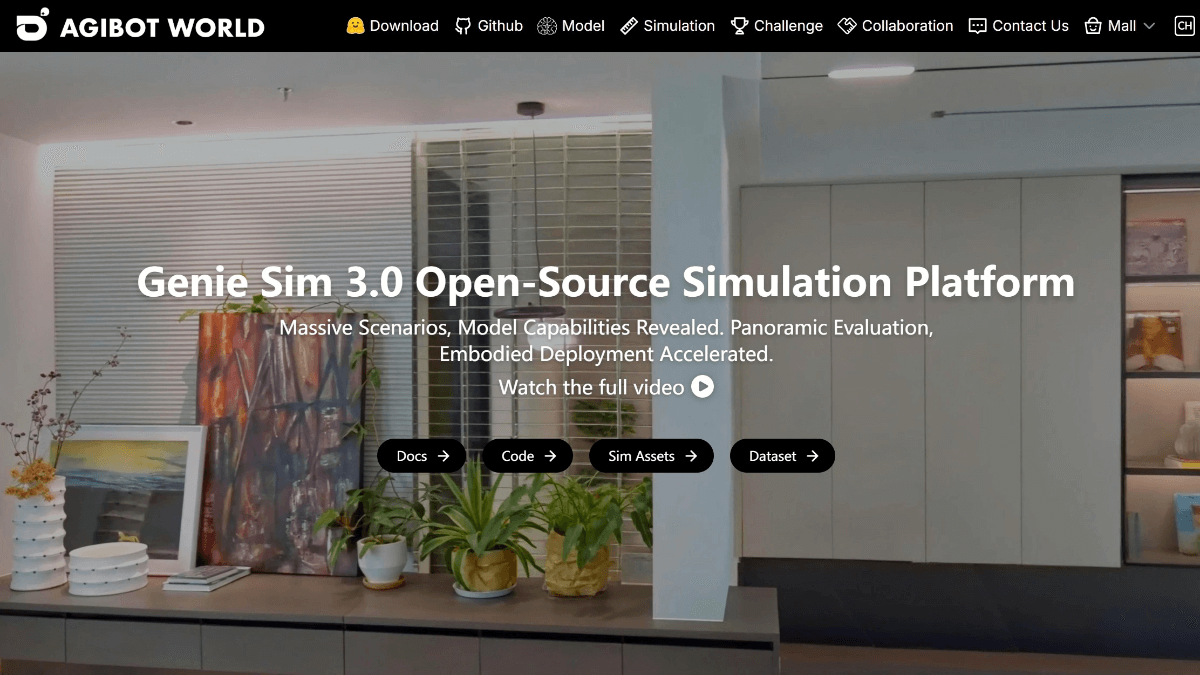
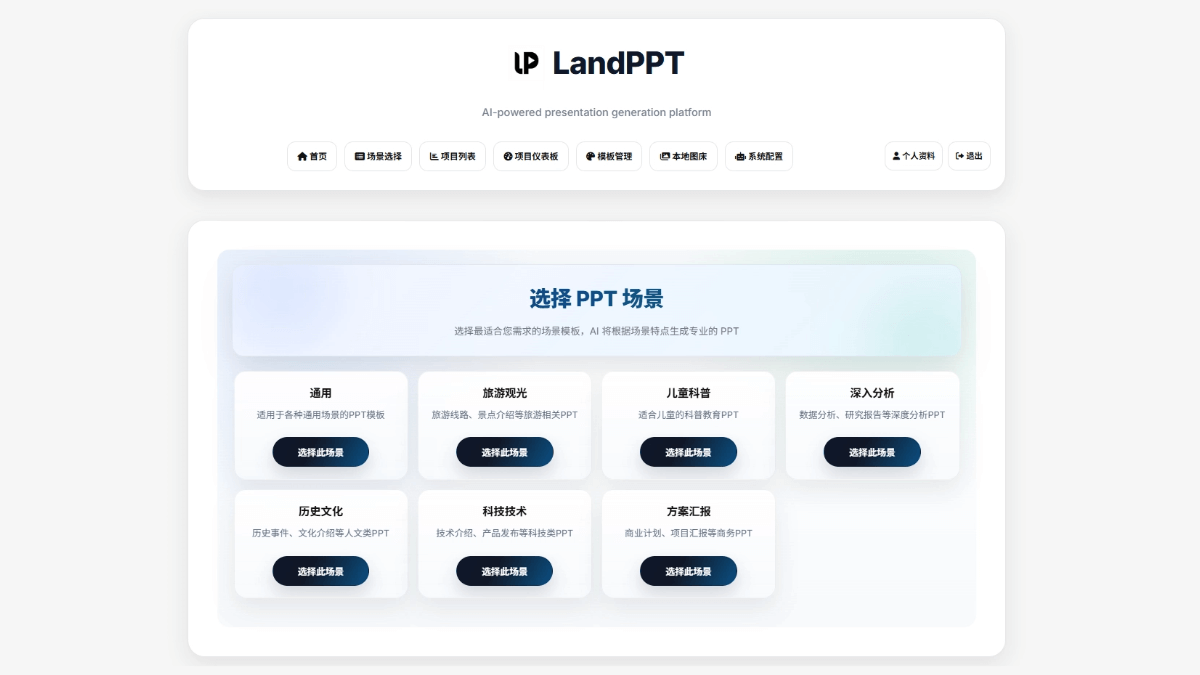
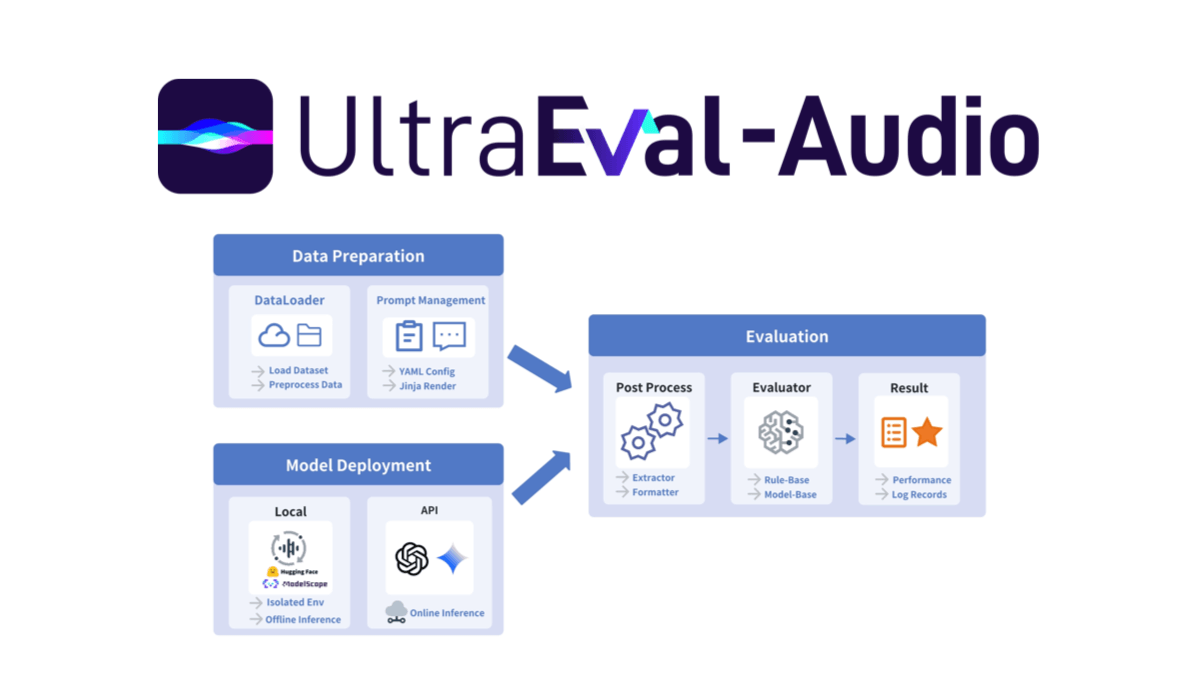
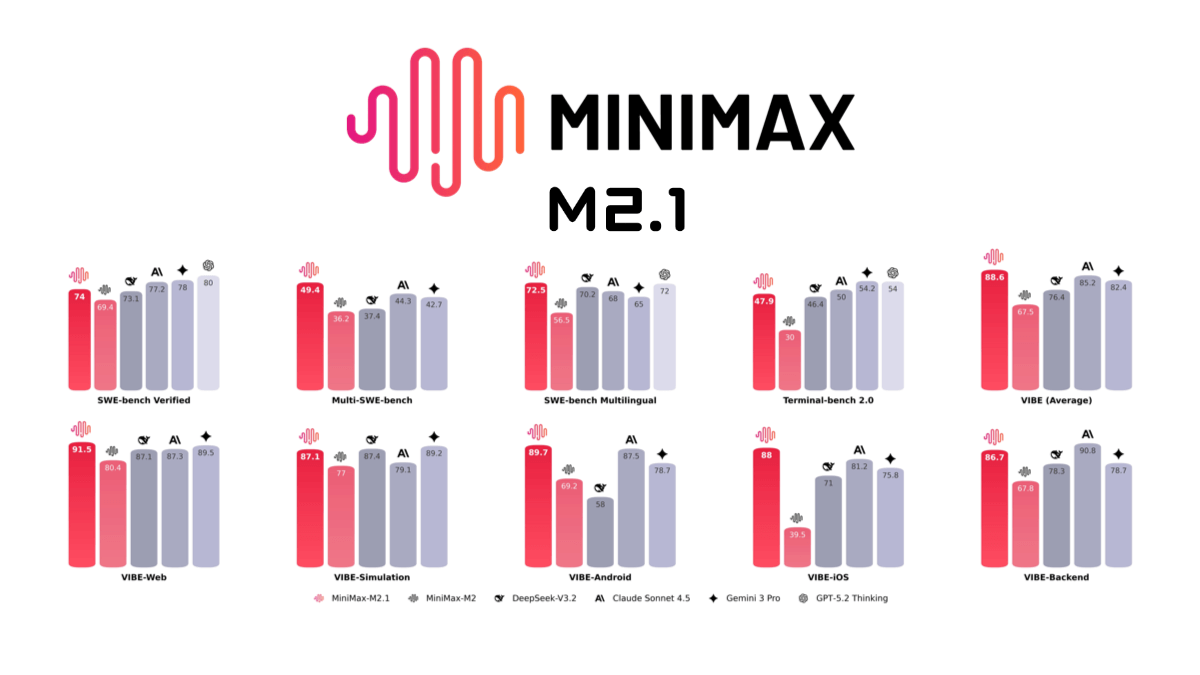
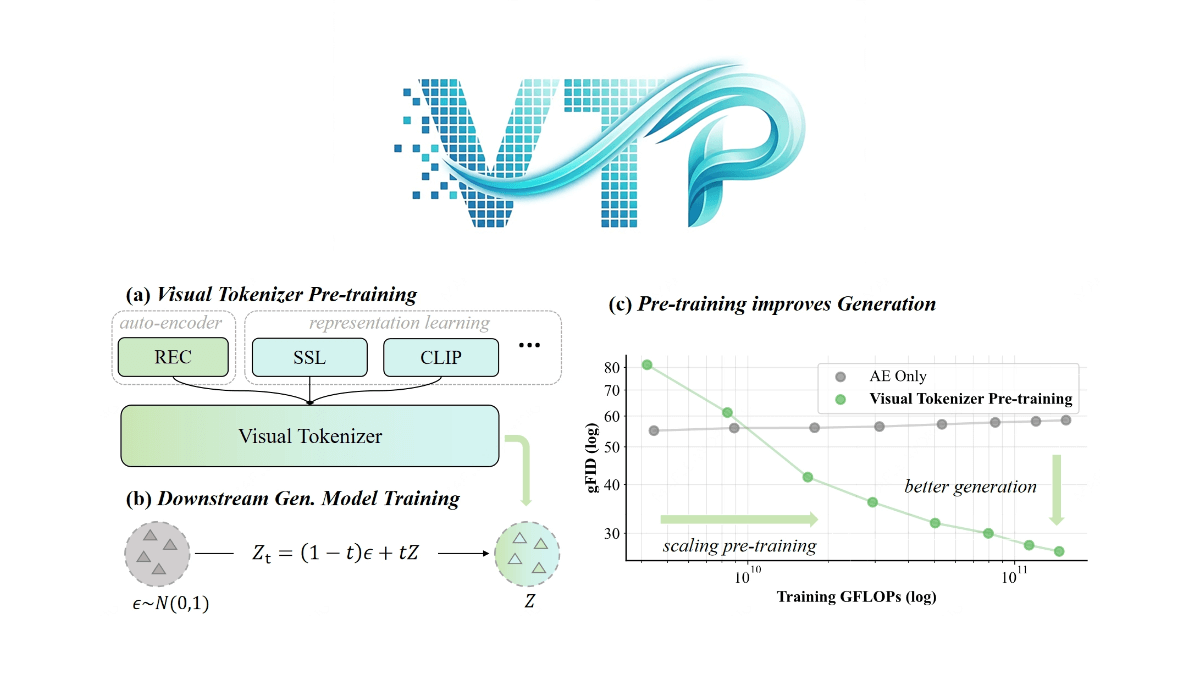
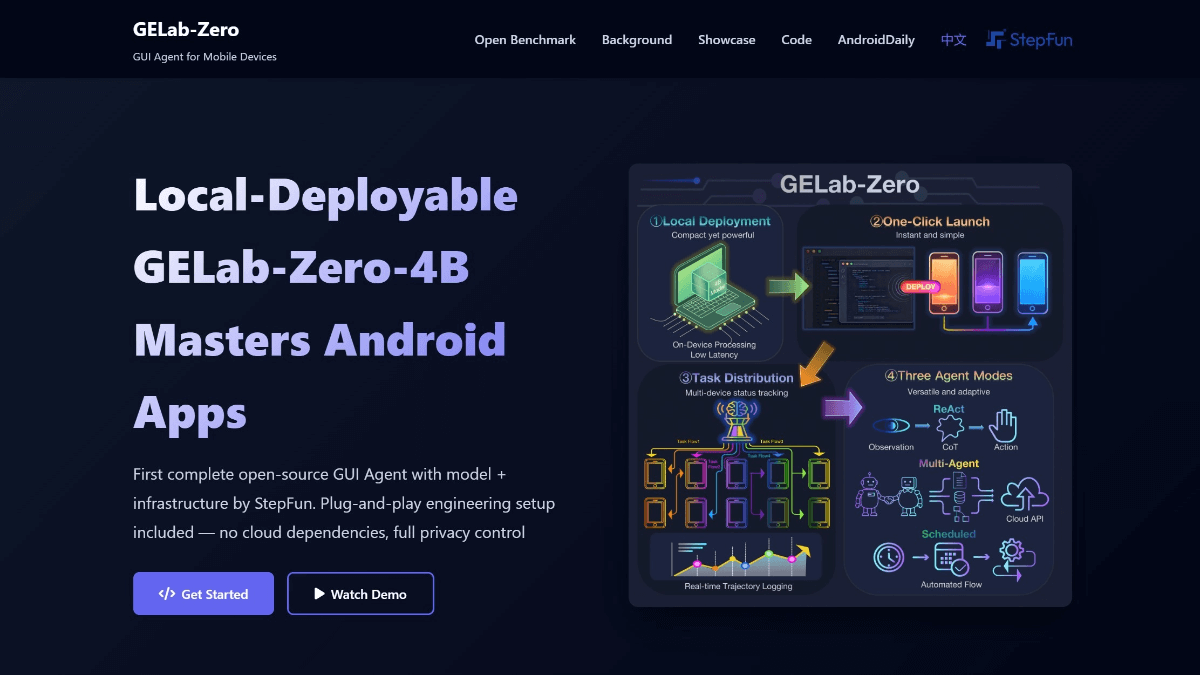
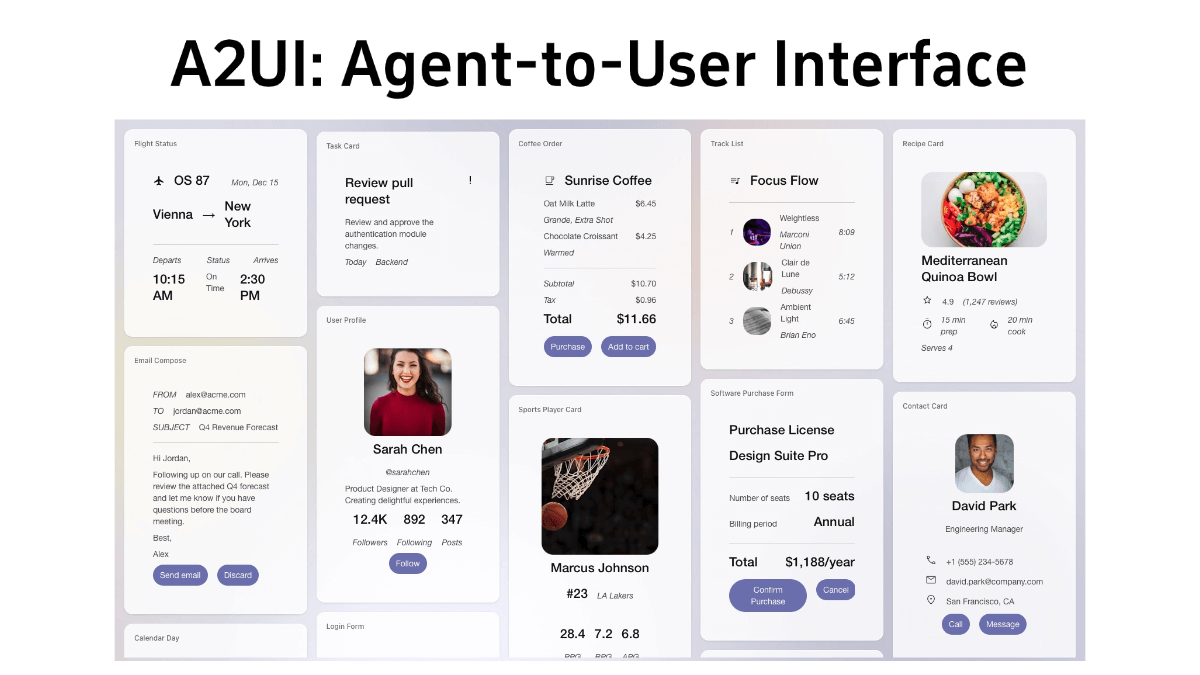
MedASR es un modelo de reconocimiento del habla médica con 105 millones de parámetros, de código abierto de Google, perfeccionado con un corpus clínico desensibilizado de 5.000 horas, optimizado para la terminología de fármacos, dosis y anatomía, con un modelo de lenguaje médico integrado de 6 gramos y una tasa de error de palabra de sólo el 4,6 en el conjunto de datos privados de radiología RAD-DICT...












![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)